Was ist ein Plug-In?
Plug-Ins sind eine Schlüsselkomponente des semantischen Kernels. Wenn Sie bereits Plug-Ins von ChatGPT- oder Copilot-Erweiterungen in Microsoft 365 verwendet haben, sind Sie bereits damit vertraut. Mit Plug-Ins können Sie Ihre vorhandenen APIs in eine Sammlung kapseln, die von einer KI verwendet werden kann. Auf diese Weise können Sie Ihrer KI Die Möglichkeit geben, Aktionen auszuführen, die andernfalls nicht möglich wären.
Hinter den Kulissen nutzt semantischer Kernel Funktionsaufrufe, ein systemeigenes Feature der meisten der neuesten LLMs, um LLMs zu ermöglichen, Planung durchzuführen und Ihre APIs aufzurufen. Mit Funktionsaufrufen können LLMs eine bestimmte Funktion anfordern (d. h. eine bestimmte Funktion aufrufen). Der semantische Kernel leitet dann die Anforderung an die entsprechende Funktion in Ihrer Codebasis weiter und gibt die Ergebnisse an das LLM zurück, damit das LLM eine endgültige Antwort generieren kann.
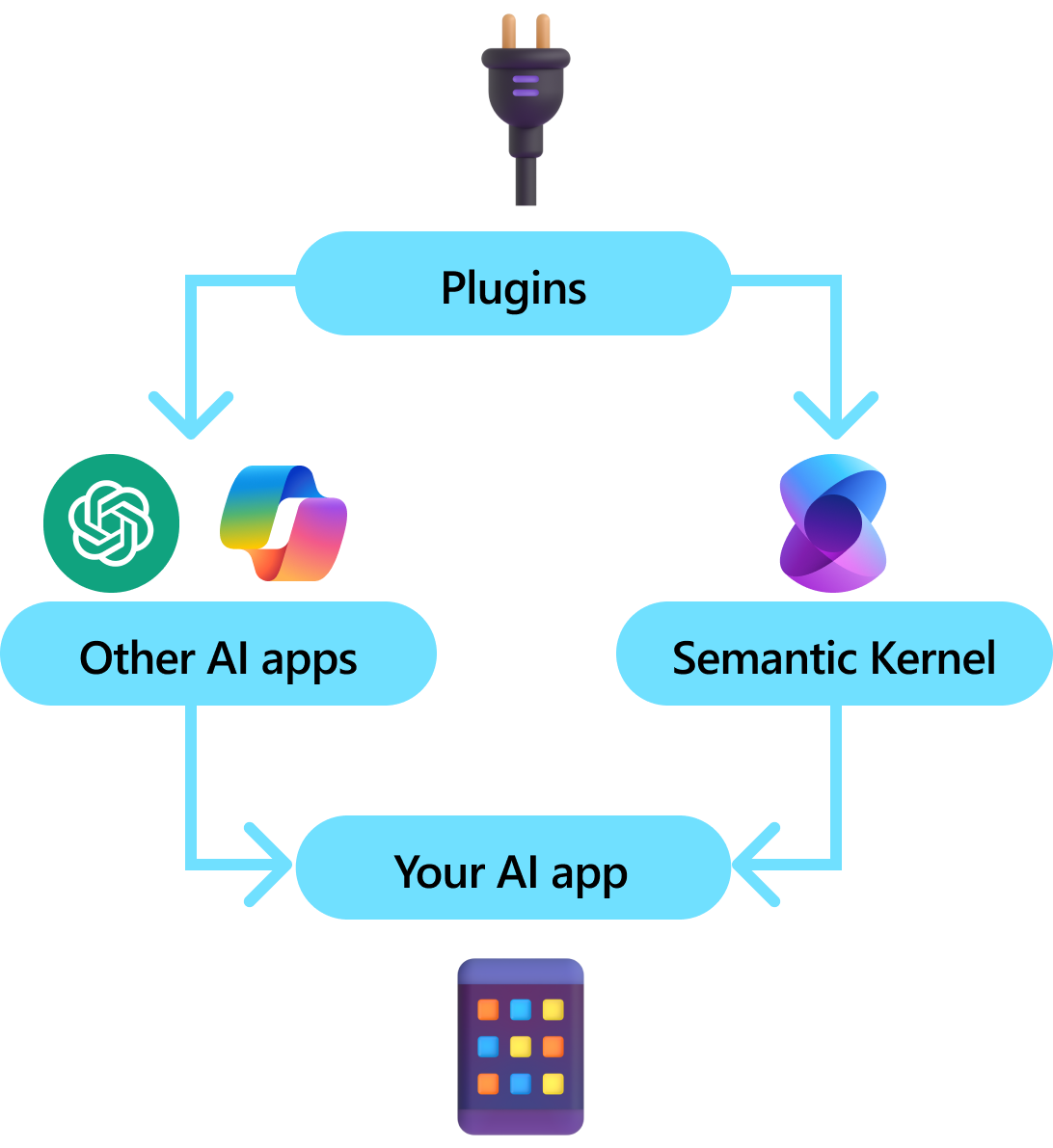
Nicht alle KI-SDKs haben ein analoges Konzept zu Plug-Ins (die meisten haben nur Funktionen oder Tools). In Unternehmensszenarien sind Plug-Ins jedoch hilfreich, da sie eine Reihe von Funktionen kapseln, die spiegeln, wie Unternehmensentwickler bereits Dienste und APIs entwickeln. Plugins arbeiten auch gut mit der Abhängigkeitsinjektion (Dependency Injection) zusammen. Innerhalb des Konstruktors eines Plug-Ins können Sie Dienste einfügen, die zum Ausführen der Arbeit des Plug-Ins erforderlich sind (z. B. Datenbankverbindungen, HTTP-Clients usw.). Dies ist schwierig mit anderen SDKs zu erreichen, die keine Plug-Ins haben.
Anatomie eines Plug-Ins
Auf hoher Ebene ist ein Plug-In eine Gruppe von Funktionen, die KI-Apps und -Dienste verfügbar gemacht werden können. Die Funktionen in Plug-Ins können dann von einer KI-Anwendung orchestriert werden, um Benutzeranforderungen auszuführen. Innerhalb des semantischen Kernels können Sie diese Funktionen automatisch mit Funktionsaufrufen aufrufen.
Anmerkung
In anderen Plattformen werden Funktionen häufig als "Tools" oder "Aktionen" bezeichnet. Im semantischen Kernel verwenden wir den Begriff "Funktionen", da sie in der Regel als systemeigene Funktionen in Ihrer Codebasis definiert sind.
Die Bereitstellung von Funktionen reicht jedoch nicht aus, um ein Plug-In zu erstellen. Um die automatische Orchestrierung mit Funktionsaufrufen zu aktivieren, müssen Plug-Ins auch Details angeben, die semantisch beschreiben, wie sie sich verhalten. Sowohl die Eingabe, die Ausgabe als auch die Nebenwirkungen der Funktion müssen so beschrieben werden, damit die KI sie verstehen kann; andernfalls kann die KI die Funktion nicht korrekt aufrufen.
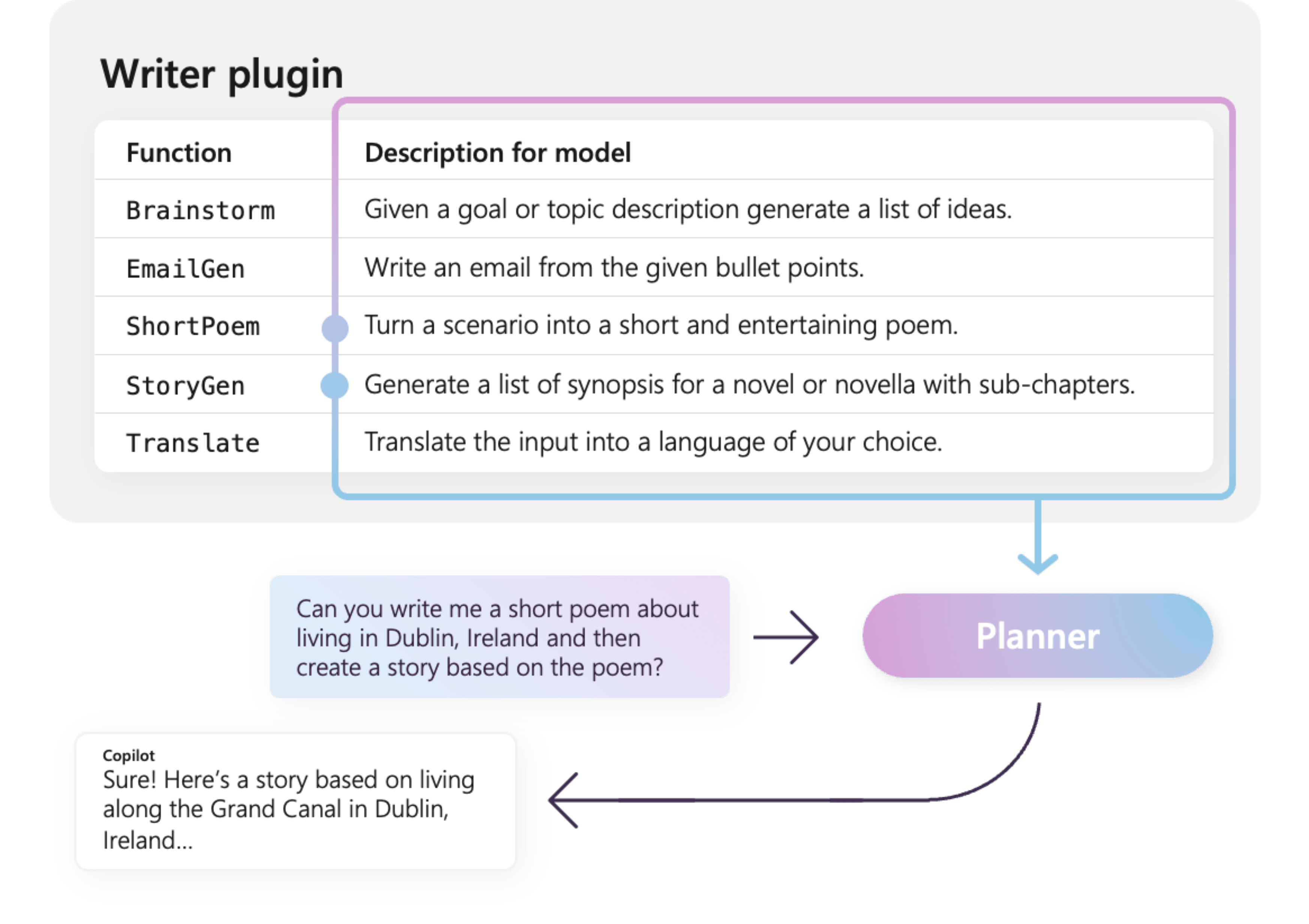
Beispielsweise verfügt das Beispiel WriterPlugin Plug-In auf der rechten Seite über Funktionen mit semantischen Beschreibungen, die beschreiben, was jede Funktion tut. Ein LLM kann dann diese Beschreibungen verwenden, um die besten Funktionen auszuwählen, die aufgerufen werden sollen, um die Anfrage eines Benutzers zu erfüllen.
Auf der rechten Seite würde ein LLM wahrscheinlich die Funktionen ShortPoem und StoryGen aufrufen, um die Anfrage des Benutzers dank der bereitgestellten semantischen Beschreibungen zu erfüllen.
Importieren verschiedener Arten von Plug-Ins
Es gibt zwei primäre Methoden zum Importieren von Plug-ins in den Semantic Kernel: mit systemeigenem Code oder mit einer OpenAPI-Spezifikation. Letzteres ermöglicht Ihnen, Plugins in Ihrer vorhandenen Codebasis zu erstellen, die vorhandene Abhängigkeiten und Dienste nutzen können, die Sie bereits haben. Letzteres ermöglicht es Ihnen, Plug-Ins aus einer OpenAPI-Spezifikation zu importieren, die für verschiedene Programmiersprachen und Plattformen freigegeben werden kann.
Nachfolgend finden Sie ein einfaches Beispiel für das Importieren und Verwenden eines nativen Plug-Ins. Weitere Informationen zum Importieren dieser verschiedenen Arten von Plug-Ins finden Sie in den folgenden Artikeln:
Tipp
Bei den ersten Schritten empfehlen wir die Verwendung nativer Code-Plug-Ins. Wenn Ihre Anwendung reift und während Sie plattformübergreifend arbeiten, sollten Sie die Verwendung von OpenAPI-Spezifikationen in Betracht ziehen, um Plug-Ins in verschiedenen Programmiersprachen und Plattformen freizugeben.
Die verschiedenen Arten von Plug-In-Funktionen
Innerhalb eines Plugins haben Sie in der Regel zwei verschiedene Funktionstypen: solche, die Daten für die Retrieval-Augmented-Generation (RAG) abrufen, und solche, die Aufgaben automatisieren. Obwohl jeder Typ funktional gleich ist, werden sie in der Regel in Anwendungen unterschiedlich verwendet, die semantischen Kernel verwenden.
Mit Abruffunktionen können Sie z. B. Strategien verwenden, um die Leistung zu verbessern (z. B. Zwischenspeichern und Verwenden günstigerer Zwischenmodelle für die Zusammenfassung). Bei Aufgabenautomatisierungsfunktionen möchten Sie wahrscheinlich Genehmigungsprozesse mit Mensch im Entscheidungsprozess implementieren, um sicherzustellen, dass Aufgaben ordnungsgemäß ausgeführt werden.
Weitere Informationen zu den verschiedenen Arten von Plug-In-Funktionen finden Sie in den folgenden Artikeln:
Erste Schritte mit Plug-Ins
Die Verwendung von Plug-Ins innerhalb des semantischen Kernels ist immer ein dreistufiger Prozess:
- Ihr Plug-in definieren
- Fügen Sie das Plugin zu Ihrem Kernel hinzu
- Und rufen Sie dann entweder die Funktionen des Plug-Ins in einer Eingabeaufforderung mit Funktionsaufrufen
Nachfolgend finden Sie ein allgemeines Beispiel für die Verwendung eines Plugins innerhalb des Semantischen Kernels. Ausführlichere Informationen zum Erstellen und Verwenden von Plug-Ins finden Sie unter den oben genannten Links.
1) Definieren Ihres Plug-Ins
Die einfachste Möglichkeit zum Erstellen eines Plug-Ins besteht darin, eine Klasse zu definieren und die Methoden mit dem attribut KernelFunction zu kommentieren. Damit weiß das semantische Kernel, dass es sich um eine Funktion handelt, die von einer KI aufgerufen oder in einem Prompt referenziert werden kann.
Sie können Plugins auch aus einer OpenAPI-Spezifikationimportieren.
Unten erstellen wir ein Plug-In, das den Zustand der Lichter abrufen und seinen Zustand ändern kann.
Tipp
Da die meisten LLM mit Python zum Aufrufen von Funktionen trainiert wurden, empfiehlt es sich, Snake Case für Funktionsnamen und Eigenschaftsnamen zu verwenden, auch wenn Sie das C#- oder Java-SDK verwenden.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
[return: Description("An array of lights")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
[return: Description("The state of the light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
[return: Description("The updated state of the light; will return null if the light does not exist")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> Annotated[list[LightModel], "An array of lights"]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Annotated[LightModel | None], "The state of the light"]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Annotated[Optional[LightModel], "The updated state of the light; will return null if the light does not exist"]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Beachten Sie, dass wir Beschreibungen für die Funktion, den Rückgabewert und die Parameter bereitstellen. Dies ist wichtig für die KI, um zu verstehen, was die Funktion tut und wie sie verwendet wird.
Tipp
Scheuen Sie sich nicht, detaillierte Beschreibungen für Ihre Funktionen bereitzustellen, wenn eine KI Probleme beim Aufrufen hat. Einige Beispiele, Empfehlungen, wann man die Funktion verwenden (und wann nicht) sollte, sowie Hinweise, wie man die erforderlichen Parameter ermitteln kann, können hilfreich sein.
2) Hinzufügen des Plug-Ins zu Ihrem Kernel
Nachdem Sie Ihr Plug-In definiert haben, können Sie es ihrem Kernel hinzufügen, indem Sie eine neue Instanz des Plug-Ins erstellen und der Plug-In-Sammlung des Kernels hinzufügen.
In diesem Beispiel wird die einfachste Methode zum Hinzufügen einer Klasse als Plug-In mit der AddFromType-Methode veranschaulicht. Weitere Informationen zum Hinzufügen von Plug-Ins finden Sie im Artikel Hinzufügen von nativen Plug-Ins.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Aufrufen der Funktionen des Plug-Ins
Schließlich können Sie die Funktionen Ihres Plugins von der KI durch Funktionsaufrufe ausführen lassen. Im Folgenden finden Sie ein Beispiel, das veranschaulicht, wie die KI dazu gebracht wird, die get_lights-Funktion des Lights-Plugins aufzurufen, bevor die change_state-Funktion aufgerufen wird, um ein Licht einzuschalten.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_call_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Mit dem obigen Code sollten Sie eine Antwort erhalten, die wie folgt aussieht:
| Rolle | Nachricht |
|---|---|
| 🔵 Benutzer | Bitte schalten Sie die Lampe ein |
| 🔴 Assistant (Funktionsaufruf) | Lights.get_lights() |
| 🟢 Tool | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| 🔴 Assistent (Funktionsaufruf) | Lights.change_state(1, { "isOn": true }) |
| 🟢 Tool | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 Assistant | Die Lampe ist jetzt eingeschaltet |
Trinkgeld
Zwar können Sie eine Plugin-Funktion direkt aufrufen, dies wird jedoch nicht empfohlen, da die KI diejenige sein sollte, die entscheidet, welche Funktionen aufgerufen werden sollen. Wenn Sie explizit steuern müssen, welche Funktionen aufgerufen werden, sollten Sie die Verwendung von Standardmethoden in Ihrer Codebasis anstelle von Plug-Ins in Betracht ziehen.
Allgemeine Empfehlungen für die Erstellung von Plug-Ins
In Anbetracht der Tatsache, dass jedes Szenario über einzigartige Anforderungen verfügt, unterschiedliche Plugindesigns verwendet und mehrere LLMs enthalten kann, ist es schwierig, einen universellen Leitfaden für das Plugindesign zu entwerfen. Im Folgenden finden Sie jedoch einige allgemeine Empfehlungen und Richtlinien, um sicherzustellen, dass Plug-Ins KI-freundlich sind und leicht und effizient von LLMs genutzt werden können.
Nur die erforderlichen Plug-Ins importieren
Importieren Sie nur die Plug-Ins, die Funktionen enthalten, die für Ihr spezifisches Szenario erforderlich sind. Durch diesen Ansatz wird nicht nur die Anzahl der verbrauchten Eingabetoken reduziert, sondern auch das Auftreten von unnötigen Funktionsaufrufen minimiert, die im Szenario nicht verwendet werden. Insgesamt sollte diese Strategie die Funktionsaufrufgenauigkeit verbessern und die Anzahl an falsch positiven Ergebnissen verringern.
Darüber hinaus empfiehlt OpenAI, nicht mehr als 20 Tools in einem einzigen API-Aufruf zu verwenden; idealerweise nicht mehr als 10 Tools. Wie von OpenAI angegeben: "Es wird empfohlen, nicht mehr als 20 Tools in einem einzigen API-Aufruf zu verwenden. Entwickler sehen in der Regel eine Verringerung der Fähigkeit des Modells, das richtige Tool auszuwählen, sobald sie zwischen 10 und 20 Tools definiert sind."* Weitere Informationen finden Sie in der Dokumentation unter OpenAI Function Calling Guide.
Machen Sie Plugins KI-freundlich
Um die Fähigkeit des LLM zu verbessern, Plug-Ins zu verstehen und zu nutzen, empfiehlt es sich, die folgenden Richtlinien zu befolgen:
Beschreibende und präzise Funktionsnamen verwenden: Stellen Sie sicher, dass Funktionsnamen ihren Zweck deutlich vermitteln, damit das Modell verstehen kann, wann jede Funktion ausgewählt werden soll. Wenn ein Funktionsname mehrdeutig ist, sollten Sie ihn aus Gründen der Übersichtlichkeit umbenennen. Vermeiden Sie die Verwendung von Abkürzungen oder Akronyme zum Kürzen von Funktionsnamen. Verwenden Sie die
DescriptionAttribute, um zusätzlichen Kontext und Anweisungen nur bei Bedarf bereitzustellen, um den Tokenverbrauch zu minimieren.Funktionsparameter minimieren: Beschränken Sie die Anzahl der Funktionsparameter, und verwenden Sie primitive Typen, wenn möglich. Durch diesen Ansatz wird die Nutzung von Tokens reduziert und die Funktionssignatur vereinfacht, sodass das LLM die Funktionsparameter effizienter verarbeiten kann.
Benennen Sie Funktionsparameter klar: Weisen Sie Funktionsparametern beschreibende Namen zu, um ihren Zweck zu verdeutlichen. Vermeiden Sie die Verwendung von Abkürzungen oder Akronymen zum Kürzen von Parameternamen, da dies dem LLM bei der Argumentation über die Parameter und der Angabe genauer Werte hilft. Verwenden Sie wie bei Funktionsnamen die
DescriptionAttributenur, wenn dies erforderlich ist, um den Tokenverbrauch zu minimieren.
Finden Sie ein richtiges Gleichgewicht zwischen der Anzahl der Funktionen und deren Zuständigkeiten.
Einerseits ist es eine bewährte Methode, Funktionen mit einer einzigen Verantwortung zu haben, die es ermöglicht, Funktionen in mehreren Szenarien einfach und wiederverwendbar zu halten. Andererseits verursacht jeder Funktionsaufruf mehr Aufwand in Bezug auf die Latenz von Netzwerk-Roundtrips und die Anzahl der verbrauchten Eingabe- und Ausgabetoken: Eingabetoken werden verwendet, um die Funktionsdefinition und das Aufrufergebnis an die LLM zu senden, während Ausgabetoken beim Empfangen des Funktionsaufrufs aus dem Modell verwendet werden.
Alternativ kann eine einzelne Funktion mit mehreren Aufgaben implementiert werden, um die Anzahl der verbrauchten Tokens zu reduzieren und den Netzwerkaufwand zu verringern, auch wenn dies auf Kosten einer geringeren Wiederverwendbarkeit in anderen Szenarien geht.
Das Konsolidieren vieler Verantwortlichkeiten in eine einzelne Funktion kann jedoch die Anzahl und Komplexität von Funktionsparametern und deren Rückgabetyp erhöhen. Diese Komplexität kann zu Situationen führen, in denen das Modell Schwierigkeiten haben kann, die Funktionsparameter korrekt abzugleichen, was dazu führt, dass Parameter übersehen werden oder Werte falschen Typs entstehen. Daher ist es wichtig, das richtige Gleichgewicht zwischen der Anzahl der Funktionen zu treffen, um den Netzwerkaufwand zu reduzieren und die Anzahl der Verantwortlichkeiten, die jede Funktion hat, sicherzustellen, dass das Modell Funktionsparameter genau abgleichen kann.
Transformation semantischer Kernelfunktionen
Verwenden Sie die Transformationstechniken für semantische Kernelfunktionen, wie im Blogbeitrag "Transforming Semantic Kernel Functions" beschrieben, um:
Verhalten der Funktion ändern: Es gibt Szenarien, in denen das Standardverhalten einer Funktion möglicherweise nicht mit dem gewünschten Ergebnis übereinstimmt und es nicht möglich ist, die Implementierung der ursprünglichen Funktion zu ändern. In solchen Fällen können Sie eine neue Funktion erstellen, die den ursprünglichen umschließt und das Verhalten entsprechend ändert.
Kontextinformationen bereitstellen: Funktionen erfordern möglicherweise Parameter, die der LLM nicht ableiten kann oder nicht ableiten sollte. Wenn z. B. eine Funktion im Namen des aktuellen Benutzers handeln muss oder Authentifizierungsinformationen erfordert, ist dieser Kontext in der Regel für die Hostanwendung, aber nicht für die LLM verfügbar. In solchen Fällen können Sie die Funktion so transformieren, dass die ursprüngliche aufgerufen wird, und dabei die erforderlichen Kontextinformationen aus der Hostanwendung sowie die von der LLM bereitgestellten Argumente bereitstellen.
Parameterliste, Typen und Namen ändern: Wenn die ursprüngliche Funktion eine komplexe Signatur aufweist, die für LLM schwer zu interpretieren ist, können Sie die Funktion in eine umwandeln, die eine einfachere Signatur hat und von LLM leichter verstanden werden kann. Dies kann unter anderem das Ändern von Parameternamen, Typen, die Anzahl der Parameter und die Abschwächung oder das Aufblasen komplexer Parameter umfassen.
Verwendung des lokalen Zustands
Beim Entwerfen von Plug-Ins, die mit relativ großen oder vertraulichen Datasets arbeiten, z. B. Dokumente, Artikel oder E-Mails, die vertrauliche Informationen enthalten, sollten Sie den lokalen Zustand verwenden, um ursprüngliche Daten oder Zwischenergebnisse zu speichern, die nicht an das LLM gesendet werden müssen. Funktionen für solche Szenarien können eine Status-ID akzeptieren und zurückgeben, sodass Sie lokal nachschlagen und auf die Daten zugreifen können, anstatt die tatsächlichen Daten an das LLM zu übergeben, nur um sie als Argument für den nächsten Funktionsaufruf zurückzugeben.
Durch lokales Speichern von Daten können Sie die Informationen privat und sicher halten und gleichzeitig unnötige Tokennutzung während Funktionsaufrufen vermeiden. Dieser Ansatz verbessert nicht nur den Datenschutz, sondern verbessert auch die Gesamteffizienz bei der Verarbeitung großer oder sensibler Datasets.