Verstehen der Azure Data Factory-Komponenten
Ein Azure-Abonnement kann über eine oder mehrere Azure Data Factory-Instanzen verfügen. Azure Data Factory besteht aus vier Kernkomponenten. Zusammen stellen sie die Plattform dar, auf der Sie datengesteuerte Workflows mit Schritten zum Verschieben und Transformieren von Daten zusammenstellen können.
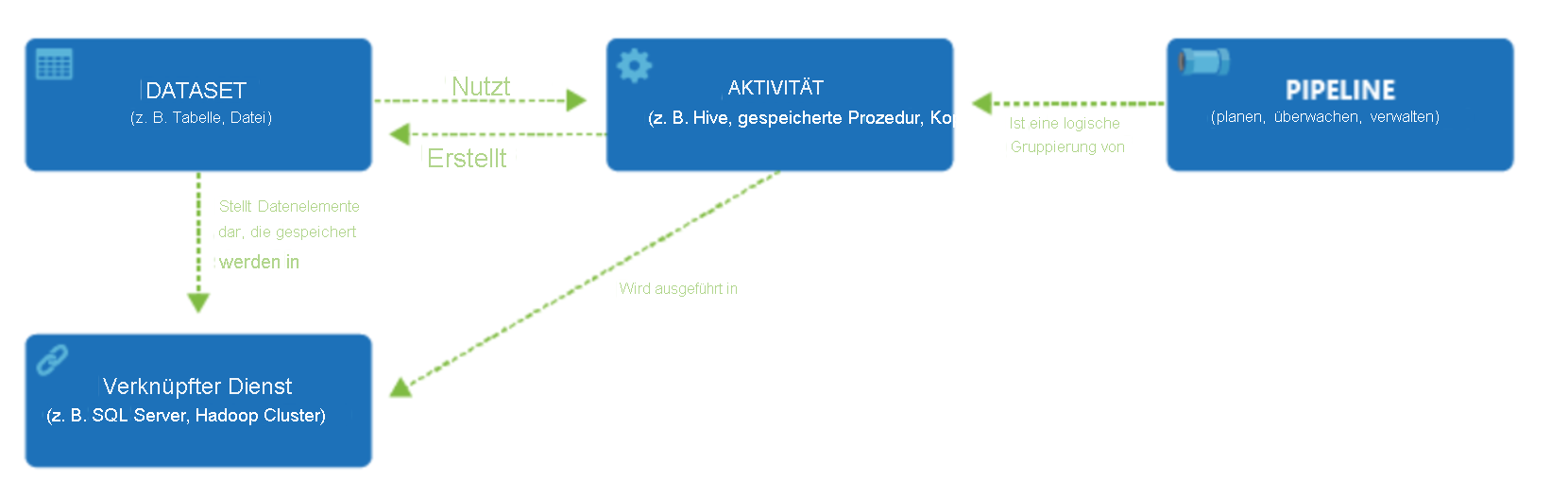
Data Factory unterstützt eine Vielzahl von Datenquellen, mit denen Sie mithilfe eines Objekts, eines sogenannten verknüpften Diensts, eine Verbindung herstellen können. Dadurch können Sie die Daten aus einer Datenquelle erfassen, um die Daten für die Transformation und/oder Analyse vorzubereiten. Darüber hinaus können verknüpfte Dienste Computedienste bedarfsbasiert starten. Beispielsweise kann es erforderlich sein, einen HDInsight-Cluster bedarfsbasiert zu starten, um Daten nur über eine Hive-Abfrage zu verarbeiten. Mit verknüpften Diensten können Sie also Datenquellen oder Computeressourcen definieren, die zum Erfassen und Vorbereiten von Daten erforderlich sind.
Wenn der verknüpfte Dienst definiert ist, wird Azure Data Factory über zu nutzende Datasets informiert. Dies geschieht durch die Erstellung eines Datasets-Objekts. Datasets stellen Datenstrukturen im Datenspeicher dar, auf den vom Objekt des verknüpften Diensts verwiesen wird. Datasets können auch von einem ADF-Objekt verwendet werden, das als Aktivität bezeichnet wird.
Aktivitäten enthalten üblicherweise die Transformationslogik oder die Analysebefehle für die Aufgaben von Azure Data Factory. Zu den Aktivitäten gehört auch die Copy-Aktivität (Kopieren), mit der Daten aus einer Vielzahl von Datenquellen erfasst werden können. Aktivitäten können auch codefreie Datentransformationen des Zuordnungsdatenflusses sein. Auch das Ausführen einer gespeicherten Prozedur, einer Hive-Abfrage oder eines Pig-Skripts zur Datentransformation gilt als Aktivität. Sie können Daten in ein Machine-Learning-Modell pushen, um Analysen auszuführen. Es ist nicht ungewöhnlich, dass mehrere Aktivitäten stattfinden, z. B. das Transformieren von Daten mithilfe einer gespeicherten SQL-Prozedur und die anschließende Durchführung von Analysen mit Azure Databricks. In diesem Fall können mehrere Aktivitäten logisch in einem Objekt gruppiert werden, einer sogenannten Pipeline. Die Ausführung dieser Pipeline kann im Voraus geplant werden, oder es kann ein Trigger definiert werden, der angibt, wann eine Pipelineausführung gestartet werden muss. Es gibt verschiedene Arten von Triggern für unterschiedliche Arten von Ereignissen.
Die Ablaufsteuerung ist eine Orchestrierung von Pipelineaktivitäten und umfasst die Verkettung von Aktivitäten in einer Sequenz, Verzweigungen, Definition von Parametern auf Pipelineebene sowie Übergabe von Argumenten, während die Pipeline bedarfs- oder triggergesteuert aufgerufen wird. Darüber hinaus umfasst sie das Übergeben von benutzerdefinierten Zuständen und Schleifencontainern sowie ForEach-Iteratoren.
Parameter sind Schlüssel-Wert-Paare einer schreibgeschützten Konfiguration. Parameter werden in der Pipeline definiert. Die Argumente für die definierten Parameter werden im Rahmen der Ausführung aus dem Ausführungskontext eines Triggers oder einer manuell ausgeführten Pipeline übergeben. Die Parameterwerte werden von Aktivitäten in der Pipeline genutzt.
Azure Data Factory verfügt über eine Integration Runtime, die es ermöglicht, zwischen der Aktivität und den Objekten des verknüpften Diensts zu überbrücken. Vom verknüpften Dienst wird darauf verwiesen, und sie stellt die Computeumgebung bereit, in der die Aktivität entweder ausgeführt wird oder aus der sie verteilt wird. Auf diese Weise kann die-Aktivität in der nächsten Region ausgeführt werden. Es gibt drei Arten der Integration Runtime: Azure, selbstgehostet und Azure-SSIS.
Nachdem alle Aufgaben abgeschlossen sind, können Sie mit Data Factory das finale Dataset in einem anderen verknüpften Dienst veröffentlichen, der dann von Technologien wie Power BI oder Machine Learning genutzt werden kann.