Erkunden einer IaaS-Lösung für Hochverfügbarkeit und Notfallwiederherstellung
Es gibt viele verschiedene Kombinationen von Funktionen, die in Azure für IaaS bereitgestellt werden können. In diesem Abschnitt werden fünf gängige Beispiele für Hochverfügbarkeits- und Notfallwiederherstellungsarchitekturen (HADR) für SQL Server in Azure behandelt.
Hochverfügbarkeit in einer einzelnen Region, Beispiel 1: Always On-Verfügbarkeitsgruppen
Wenn Sie nur Hochverfügbarkeit und keine Notfallwiederherstellung benötigen, ist die Konfiguration einer Verfügbarkeitsgruppe eine der verbreitetsten Methoden, egal wo Sie SQL Server einsetzen. Die folgende Abbildung ist ein Beispiel dafür, wie eine mögliche Verfügbarkeitsgruppe in einer einzelnen Region aussehen könnte.
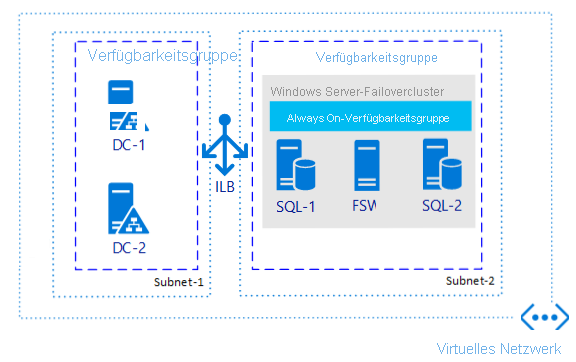
Warum ist diese Architektur eine Überlegung wert?
Diese Architektur schützt Daten durch mehrere Kopien auf verschiedenen virtuellen Computern (VMs).
Mit dieser Architektur können Sie die Recovery Time Objective (RTO) und die Recovery Point Objective (RPO) mit minimalem bis gar keinem Datenverlust erzielen, wenn sie richtig implementiert ist.
Diese Architektur bietet eine einfache, standardisierte Methode für Anwendungen, um sowohl auf primäre als auch auf sekundäre Replikate zuzugreifen (wenn Dinge wie schreibgeschützte Replikate verwendet werden sollen).
Diese Architektur bietet eine erhöhte Verfügbarkeit bei Patchingszenarien.
Diese Architektur benötigt keinen freigegebenen Speicher, sodass es weniger Komplikationen gibt als bei der Verwendung einer Failoverclusterinstanz (FCI).
Hochverfügbarkeit in einer einzelnen Region, Beispiel 2: Always On-Failoverclusterinstanz
Bis zur Einführung von Verfügbarkeitsgruppen waren FCIs die beliebteste Methode zur Implementierung von Hochverfügbarkeit für SQL Server. FCIs wurden jedoch zu einer Zeit entworfen, als physische Bereitstellungen vorherrschten. In einer virtualisierten Welt bieten FCIs nicht mehr viele der selben Schutzmechanismen wie auf physischer Hardware, da es selten vorkommt, dass eine VM ein Problem hat. FCIs wurden entwickelt, um vor Dingen wie dem Ausfall von Netzwerkkarten oder Datenträgern zu schützen, was beides in Azure eher unwahrscheinlich sein wird.
Abgesehen davon haben FCIs durchaus einen Platz in Azure. Sie funktionieren, und solange Sie die richtigen Erwartungen haben, was bereitgestellt wird und was nicht, ist eine FCI eine vollkommen akzeptable Lösung. Die folgende Abbildung aus der Microsoft-Dokumentation zeigt eine allgemeine Ansicht, wie eine FCI-Bereitstellung bei Verwendung von Storage Spaces Direct (Direkte Speicherplätze) aussieht.
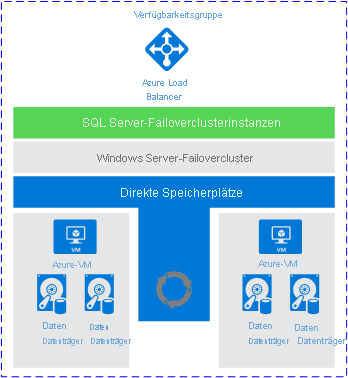
Warum ist diese Architektur eine Überlegung wert?
FCIs sind nach wie vor eine beliebte Verfügbarkeitslösung.
Aspekte des freigegebenen Speichers verbessern sich durch Funktionen wie Azure Shared Disk.
Diese Architektur erfüllt die meisten RTO und RPO für Hochverfügbarkeit (obwohl Notfallwiederherstellung nicht behandelt wird).
Diese Architektur bietet eine einfache, standardisierte Methode für Anwendungen zum Zugriff auf die gruppierte Instanz von SQL Server.
Diese Architektur bietet eine erhöhte Verfügbarkeit bei Patchingszenarien.
Notfallwiederherstellungsbeispiel 1: Always On-Verfügbarkeitsgruppe für mehrere Regionen oder Hybrid
Wenn Sie Verfügbarkeitsgruppen verwenden, besteht eine Möglichkeit darin, die Verfügbarkeitsgruppe über mehrere Azure-Regionen oder möglicherweise als Hybridarchitektur zu konfigurieren. Das bedeutet, dass alle Knoten, die die Replikate enthalten, am selben WSFC (Windows Server-Failovercluster) teilnehmen. Dies setzt eine gute Netzwerkkonnektivität voraus, insbesondere wenn es sich um eine Hybridkonfiguration handelt. Eine der wichtigsten Überlegungen wäre die Zeugenressource für den WSFC. Diese Architektur würde erfordern, dass AD DS und DNS in jeder Region und möglicherweise auch lokal verfügbar sind, wenn es sich um eine Hybridlösung handelt. Das folgende Bild zeigt, wie eine einzelne Verfügbarkeitsgruppe, die über zwei Standorte hinweg konfiguriert ist, unter Windows Server aussieht.
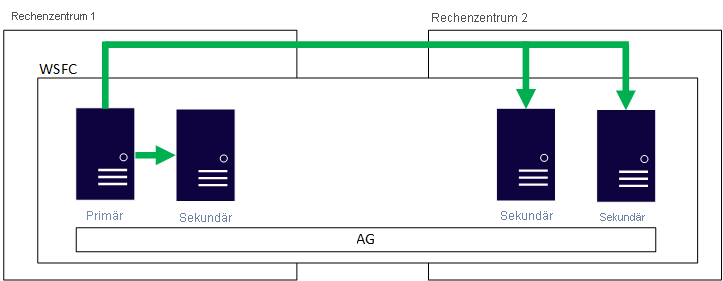
Warum ist diese Architektur eine Überlegung wert?
Diese Architektur ist eine bewährte Lösung. Es handelt sich dabei um nichts anderes, als wenn man heute zwei Rechenzentren in einer Verfügbarkeitsgruppentopologie hat.
Diese Architektur funktioniert mit den Standard und Enterprise Editionen von SQL Server.
Verfügbarkeitsgruppen bieten natürliche Redundanz mit zusätzlichen Kopien der Daten.
Bei dieser Architektur wird eine Funktion verwendet, die sowohl Hochverfügbarkeit als auch Notfallwiederherstellung bietet
Notfallwiederherstellungsbeispiel 2: Verteilte Verfügbarkeitsgruppe
Eine verteilte Verfügbarkeitsgruppe ist eine Funktion, die nur in der Enterprise Edition von SQL Server 2016 eingeführt wurde. Sie unterscheidet sich von einer herkömmlichen Verfügbarkeitsgruppe. Anstelle eines zugrunde liegenden WSFCs, bei dem alle Knoten Replikate enthalten, die an einer Verfügbarkeitsgruppe teilnehmen, wie im vorherigen Beispiel beschrieben, besteht eine verteilte Verfügbarkeitsgruppe aus mehreren Verfügbarkeitsgruppen. Das primäre Replikat, das die Lese-/Schreibdatenbank enthält, wird als globales primäres Replikat bezeichnet. Das primäre Replikat der zweiten Verfügbarkeitsgruppe wird als „Weiterleiter“ bezeichnet und hält die sekundäre(n) Replikate dieser Verfügbarkeitsgruppe synchronisiert. Im Grunde genommen ist dies eine Verfügbarkeitsgruppe aus Verfügbarkeitsgruppen.
Diese Architektur macht es einfacher, mit Dingen wie Quoren umzugehen, da jeder Cluster sein eigenes Quorum aufrechterhalten würde, was bedeutet, dass er auch seinen eigenen Zeugen hätte. Eine verteilte Verfügbarkeitsgruppe würde funktionieren, egal ob Sie Azure für alle Ressourcen verwenden oder eine Hybridarchitektur nutzen.
Das folgende Bild zeigt die Beispielkonfiguration einer verteilten Verfügbarkeitsgruppe. Es gibt zwei WSFCs. Stellen Sie sich vor, jedes Clustering befindet sich in einer anderen Azure-Region, oder eins ist lokal und das andere in Azure. Jeder WSFC hat eine Verfügbarkeitsgruppe mit zwei Replikaten. Das globale primäre Replikat in Verfügbarkeitsgruppe 1 hält das sekundäre Replikat von Verfügbarkeitsgruppe 1 sowie den Forwarder synchronisiert, der auch das primäre Replikat von Verfügbarkeitsgruppe 2 ist. Dieses Replikat hält das sekundäre Replikat von Verfügbarkeitsgruppe 2 synchronisiert.
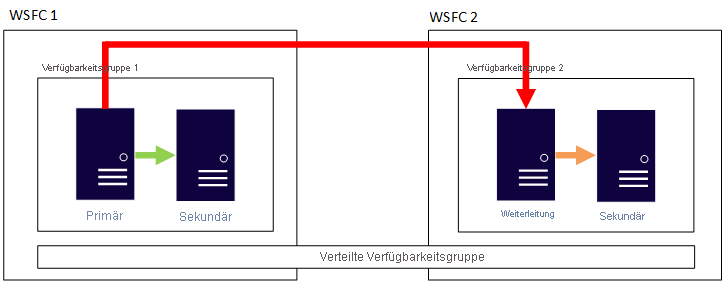
Warum ist diese Architektur eine Überlegung wert?
Diese Architektur trennt den WSFC als Single Point of Failure ab, wenn alle Knoten die Kommunikation verlieren
In dieser Architektur synchronisiert ein primäres Replikat nicht alle sekundären Replikate.
Diese Architektur kann ein Failback von einem Standort zu einem anderen ermöglichen.
Notfallwiederherstellungsbeispiel 3: Protokollversand
Der Protokollversand ist eine der ältesten HADR-Methoden zur Konfiguration der Notfallwiederherstellung für SQL Server. Wie oben beschrieben, ist die Maßeinheit die Transaktionsprotokollsicherung. Wenn der Wechsel auf einen betriebsbereiten Standbyserver nicht geplant ist, um Datenverluste zu verhindern, wird es höchstwahrscheinlich zu einem Datenverlust kommen. Wenn es um die Notfallwiederherstellung geht, ist es immer am besten, von einem gewissen Datenverlust auszugehen, auch wenn er minimal sein wird. Die folgende Abbildung aus der Microsoft-Dokumentation zeigt eine Beispieltopologie für den Protokollversand.
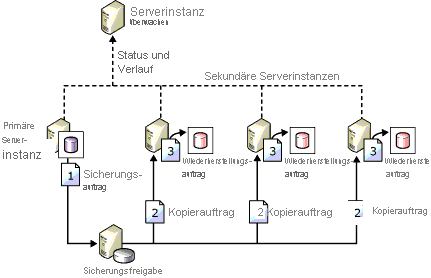
Warum ist diese Architektur eine Überlegung wert?
Der Protokollversand ist eine bewährte Funktion, die es schon seit über 20 Jahren gibt
Protokollversand ist einfach bereitzustellen und zu verwalten, da er auf Sicherung und Wiederherstellung basiert.
Protokollversand ist tolerant gegenüber nicht robusten Netzwerken.
Der Protokollversand erfüllt die meisten RTO- und RPO-Ziele für die Notfallwiederherstellung.
Der Protokollversand ist eine gute Möglichkeit, um FCIs zu schützen.
Notfallwiederherstellungsbeispiel 4: Azure Site Recovery
Für diejenigen, die keine SQL Server-basierte Notfalllösung implementieren möchten, ist Azure Site Recovery eine mögliche Option. Die meisten Datenexperten bevorzugen jedoch einen datenbankzentrierten Ansatz, da dieser in der Regel eine niedrigere RPO aufweist.
Die folgende Abbildung aus der Microsoft-Dokumentation zeigt, wo Sie im Azure-Portal die Replikation für Azure Site Recovery konfigurieren würden.
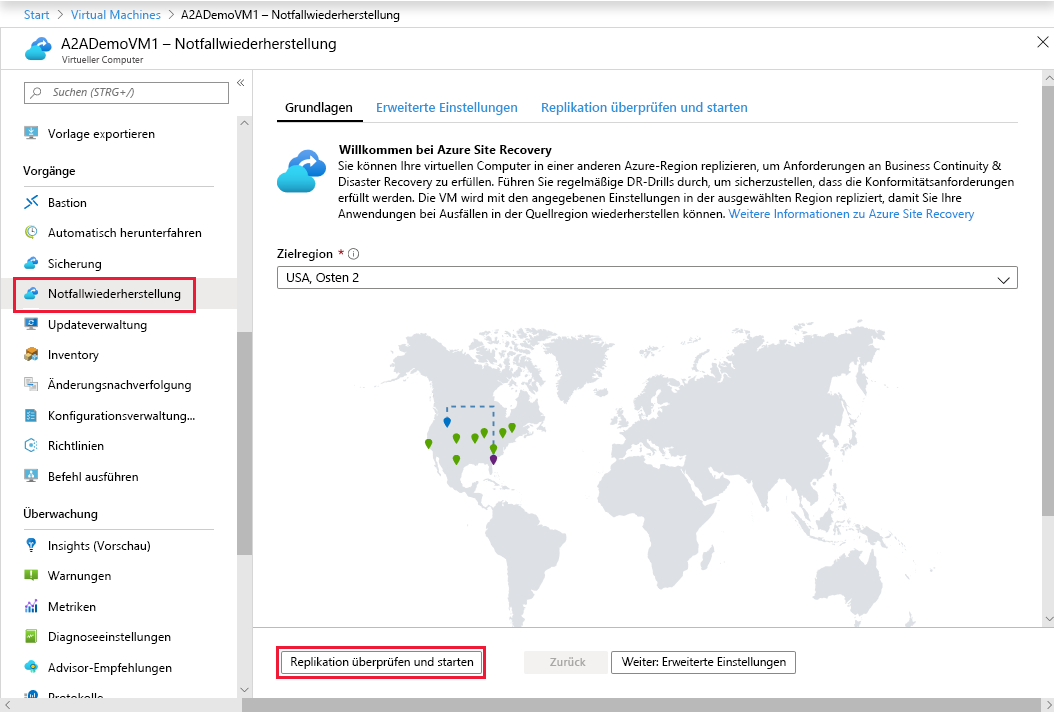
Warum ist diese Architektur eine Überlegung wert?
Azure Site Recovery funktioniert mit mehr als nur SQL Server.
Azure Site Recovery kann die RTO und möglicherweise die RPO erfüllen.
Azure Site Recovery wird als Teil der Azure-Plattform bereitgestellt.