Beschreiben der Medallion-Architektur
Data Lakehouses in Fabric basieren auf dem Delta Lake-Format, das nativ ACID-Transaktionen (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) unterstützt. Innerhalb dieses Frameworks ist die Medallion-Architektur ein empfohlenes Datenentwurfsmuster, das zum logischen Organisieren von Daten in einem Lakehouse verwendet wird. Es zielt darauf ab, die Qualität der Daten zu verbessern, während sie verschiedene Ebenen durchlaufen. Die Architektur verfügt in der Regel über drei Ebenen – Bronze (roh), Silber (validiert) und Gold (angereichert), die jeweils höhere Datenqualitätsstufen darstellen. Dies wird auch als „Multi-Hop“-Architektur bezeichnet, was bedeutet, dass Daten nach Bedarf zwischen Ebenen verschoben werden können.
Diese Architektur stellt sicher, dass Daten zuverlässig und konsistent sind, während sie verschiedene Überprüfungen und Änderungen durchlaufen. Außerdem wird sichergestellt, dass die Daten sicher gespeichert sind und einfacher und schneller analysiert werden können.
Die Medallion-Architektur ergänzt andere Verfahren zur Datenorganisation und ersetzt sie nicht. Die Medallion-Architektur ist eher ein Framework für die Datenbereinigung als eine Datenarchitektur oder ein Modell. Sie gewährleistet Kompatibilität und Flexibilität für Unternehmen, damit diese ihre Vorteile neben vorhandenen Datenmodellen nutzen können. So lassen sich Datenlösungen anpassen und Fachwissen nutzen, während Sie gleichzeitig in der sich ständig verändernden Datenlandschaft flexibel bleiben.
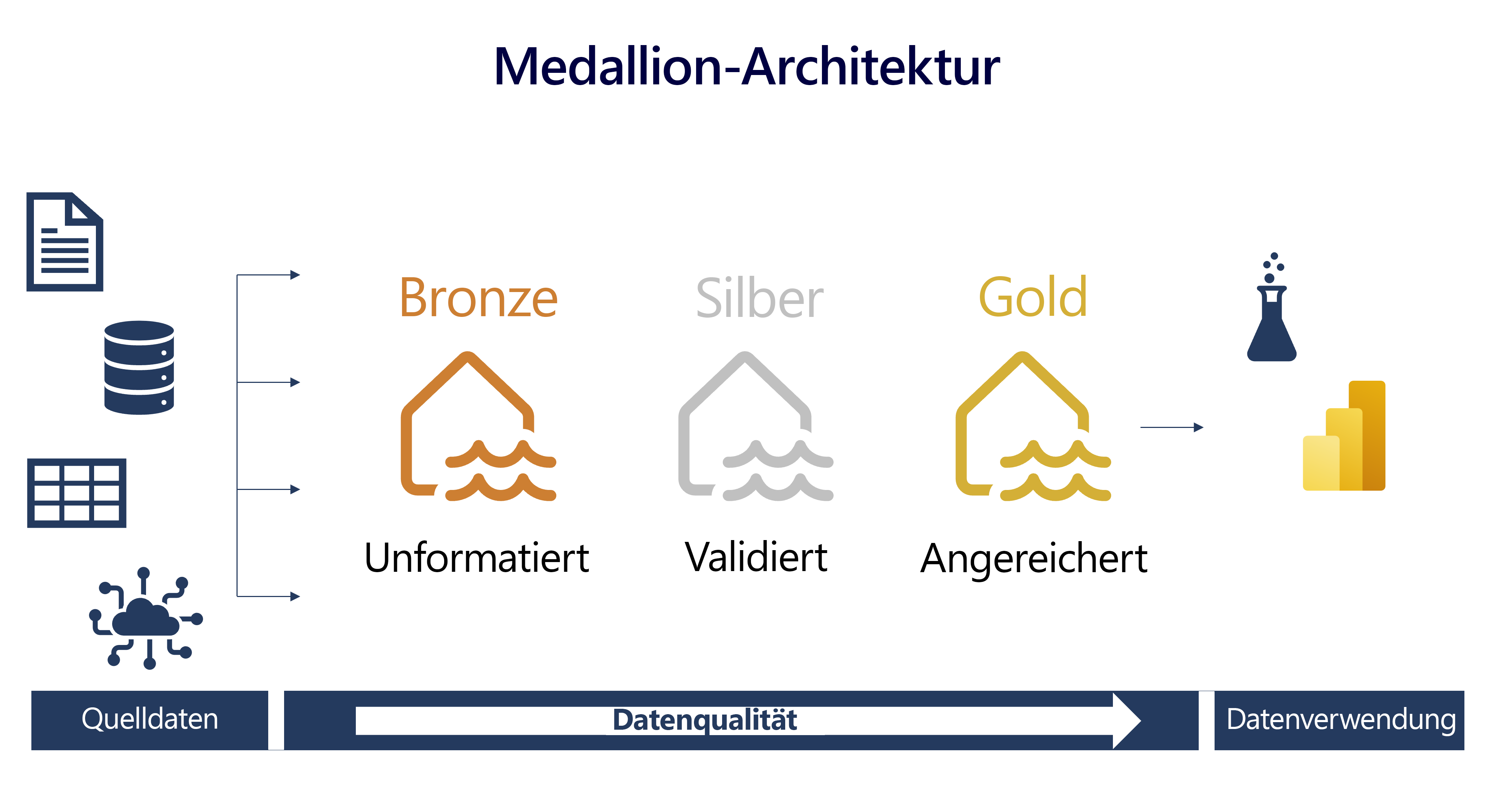
Grundlegendes zum Format der Medallion-Architektur
eBronze-Ebene
Die Bronze- oder Rohdatenebene der Medallion-Architektur ist die erste Ebene des Lakehouse. Dies ist die Zielzone für alle Daten, unabhängig davon, ob sie strukturiert, teilweise strukturiert oder unstrukturiert sind. Die Daten werden im ursprünglichen Format gespeichert, und es werden keine Änderungen daran vorgenommen.
Silberebene
Die Silber- oder validierte Ebene ist die zweite Ebene des Lakehouse. Hier überprüfen und verfeinern Sie Ihre Daten. Typische Aktivitäten auf der Silberebene umfassen das Kombinieren und Zusammenführen von Daten und das Erzwingen von Datenüberprüfungsregeln, z. B. das Entfernen von NULL-Werten und die Deduplizierung. Die Silberebene kann als zentrales Repository in einer Organisation oder einem Team betrachtet werden. Hier werden Daten in einem einheitlichen Format gespeichert, auf die durch mehrere Teams zugegriffen werden kann. In der Silberebene bereinigen Sie Ihre Daten soweit, dass sich alle Daten an einem Ort befinden und bereit sind, in der Goldebene verfeinert und modelliert zu werden.
Goldebene
Die Gold- oder angereicherte Ebene ist die dritte Ebene des Lakehouse. In der Goldebene werden die Daten weiter angereichert, um sie auf bestimmte Geschäfts- und Analyseanforderungen abzustimmen. Dies kann das Aggregieren von Daten mit einer bestimmten Granularität umfassen, z. B. täglich oder stündlich, oder die Anreicherung mit externen Informationen. Sobald die Daten die Goldebene erreicht haben, können sie von nachgelagerten Teams verwendet werden, z. B. Analyse-, Data Science- oder MLOps-Teams.
Anpassen der Medallion-Architektur
Abhängig vom spezifischen Anwendungsfall Ihrer Organisation benötigen Sie möglicherweise weitere Ebenen. Sie könnten z. B. eine zusätzliche Rohdatenebene einrichten, um Daten in einem bestimmten Format aufzunehmen, bevor sie in die Bronzeebene transformiert werden. Oder Sie sehen eine Platinebene für Daten vor, die für einen bestimmten Anwendungsfall noch weiter verfeinert und angereichert wurden. Unabhängig von den Namen und der Anzahl der Ebenen ist die Medallion-Architektur flexibel und kann an die speziellen Anforderungen Ihrer Organisation angepasst werden.
Verschieben von Daten auf andere Ebenen in Fabric
Durch das Verschieben von Daten zwischen den Medallion-Ebenen werden sie optimiert, organisiert und für nachgelagerte Datenaktivitäten vorbereitet. Innerhalb des Fabric-Lakehouse gibt es mehrere Möglichkeiten, Daten zwischen Ebenen zu verschieben. So können Sie die für Sie am besten geeignete Methode auswählen.
Bei der Entscheidung, wie Daten über Ebenen hinweg verschoben und transformiert werden sollen, müssen einige Punkte beachtet werden.
- Mit wie vielen Daten arbeiten Sie?
- Wie komplex sind die Transformationen, die Sie vornehmen müssen?
- Wie oft müssen Sie Daten zwischen Ebenen verschieben?
- Mit welchen Tools sind Sie am besten vertraut?
Ein Verständnis des Unterschieds zwischen Datentransformation und Datenorchestrierung hilft Ihnen dabei, die richtigen Tools in Fabric auszuwählen.
Die Datentransformation umfasst das Ändern der Struktur oder des Inhalts von Daten, um bestimmte Anforderungen zu erfüllen. Zu den Tools für die Datentransformation in Fabric gehören Dataflows (Gen2) und Notebooks. Dataflows sind eine gute Option für kleinere semantische Modelle und einfache Transformationen. Notebooks sind eine bessere Option für größere semantische Modelle und komplexere Transformationen. Notebooks ermöglichen es Ihnen auch, Ihre transformierten Daten als verwaltete Delta-Tabelle im Lakehouse zu speichern, sodass sie für die Berichterstellung verwendet werden können.
Datenorchestrierung bezieht sich auf die Koordinierung und Verwaltung mehrerer datenbezogener Prozesse, um sicherzustellen, dass diese zusammenarbeiten und ein gewünschtes Ergebnis liefern. Das primäre Tool für die Datenorchestrierung in Fabric sind Pipelines. Eine Pipeline bezeichnet eine Reihe von Schritten, mit denen Daten von einem Ort an einen anderen verschoben werden, in diesem Fall zwischen den Ebenen der Medallion-Architektur. Pipelines können so automatisiert werden, dass sie nach einem Zeitplan ausgeführt oder durch ein Ereignis ausgelöst werden.