Was sind Sprachmodelle?
Generative KI-Anwendungen basieren auf Sprachmodellen, bei denen es sich um spezielle Machine Learning-Modelle handelt, die Sie für Tasks rund um die linguistische Datenverarbeitung (Natural Language Processing, NLP) verwenden können, darunter:
- Bestimmen der Stimmung oder anderweitiges Klassifizieren von Text in natürlicher Sprache
- Zusammenfassen von Text
- Vergleichen mehrerer Textquellen auf semantische Ähnlichkeit
- Generieren neuer Texte in natürlicher Sprache
Die mathematischen Prinzipien hinter diesen Sprachmodellen können zwar komplex sein, aber ein grundlegendes Verständnis der Architektur, die für ihre Implementierung verwendet wird, kann Ihnen helfen, ein konzeptionelles Verständnis ihrer Funktionsweise zu erlangen.
Transformermodelle
Machine Learning-Modelle für die linguistische Datenverarbeitung haben sich über viele Jahre weiterentwickelt. Die modernen großen Sprachmodelle von heute basieren auf der Transformerarchitektur, die auf einigen Techniken aufbaut und diese erweitert, die sich bei der Modellierung von Vokabularen bewährt haben, um NLP-Tasks und insbesondere die Sprachgenerierung zu ermöglichen. Transformermodelle werden mit großen Textmengen trainiert, sodass sie die semantischen Beziehungen zwischen Wörtern darstellen und diese Beziehungen verwenden können, um wahrscheinliche Textsequenzen zu bestimmen, die bedeutungstragend sind. Transformermodelle mit einem ausreichend großen Vokabular sind in der Lage, Sprachantworten zu generieren, die schwer von menschlichen Antworten zu unterscheiden sind.
Die Transformermodellarchitektur besteht aus zwei Komponenten, die auch als Blöcke bezeichnet werden:
- Ein Encoderblock, der semantische Darstellungen des Trainingsvokabulars erstellt
- Ein Decoderblock, der neue Sprachsequenzen generiert
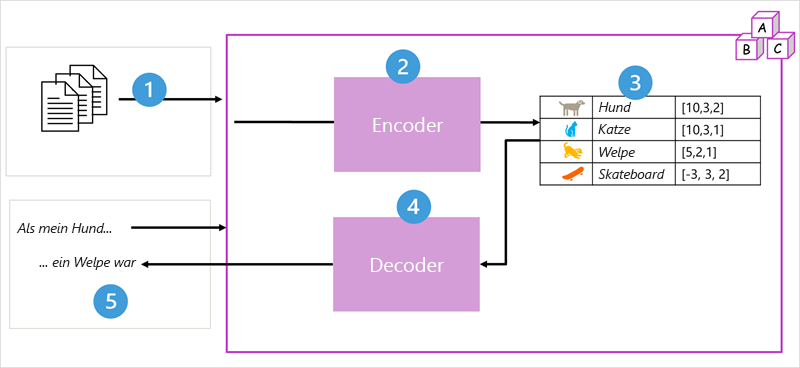
- Das Modell wird mit einem großen Volumen von Text in natürlicher Sprache trainiert, häufig aus dem Internet oder anderen öffentlichen Textquellen.
- Die Textsequenzen werden in Token (z. B. einzelne Wörter) zerlegt, und der Encoder-Block verarbeitet diese Token-Sequenzen mit Hilfe einer Technik, die als „Aufmerksamkeit“ bezeichnet wird, um Beziehungen zwischen den Token zu bestimmen (z. B. welche Token das Vorhandensein anderer Token in einer Sequenz beeinflussen, verschiedene Token, die häufig im gleichen Kontext verwendet werden, usw.).
- Die Ausgabe des Encoders ist eine Sammlung von Vektoren (mehrwertige numerische Arrays), in denen jedes Element des Vektors ein semantisches Attribut der Token darstellt. Diese Vektoren werden als Einbettungen bezeichnet.
- Der Decoderblock arbeitet mit einer neuen Sequenz von Texttoken und verwendet die vom Encoder generierten Einbettungen, um eine entsprechende natürlichsprachliche Ausgabe zu erzeugen.
- Bei einer Eingabesequenz wie „Als mein Hund“ kann das Modell beispielsweise die Aufmerksamkeitstechnik nutzen, um die Eingabetoken und die in den Einbettungen kodierten semantischen Attribute zu analysieren, um eine geeignete Vervollständigung des Satzes vorherzusagen, z. B. „ein Welpe war“.
In der Praxis variieren die spezifischen Implementierungen der Architektur. Beispielsweise verwendet das von Google zur Unterstützung der Suchmaschine entwickelte BERT-Modell (Bidirectional Encoder Representations from Transformers) nur den Encoderblock, während das von OpenAI entwickelte GPT-Modell (Generative Pretrained Transformer) nur den Decoderblock verwendet.
Eine vollständige Erläuterung aller Aspekte von Transformermodellen geht zwar über den Rahmen dieses Moduls hinaus, aber es werden einige der wichtigsten Elemente eines Transformers erläutert, damit Sie ein Verständnis dafür entwickeln, wie diese generative KI unterstützen.
Tokenisierung
Der erste Schritt beim Trainieren eines Transformermodells besteht darin, den Trainingstext in Token zu unterteilen, d. h. jeden eindeutigen Textwert zu identifizieren. Der Einfachheit halber können Sie sich jedes einzelne Wort im Trainingstext als Token vorstellen (obwohl in Wirklichkeit Token für Teilwörter oder Kombinationen aus Wörtern und Satzzeichen generiert werden können).
Wir veranschaulichen das am folgenden Satz:
I heard a dog bark loudly at a cat
Um diesen Text zu tokenisieren, können Sie jedes einzelne Wort ermitteln und diesen jeweils Token-IDs zuweisen. Zum Beispiel:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
Der Satz kann nun mit den Token dargestellt werden: {1 2 3 4 5 6 7 3 8}. Ebenso könnte der Satz „I heard a cat“ als {1 2 3 8} dargestellt werden.
Während Sie das Modell weiter trainieren, wird jedes neue Token im Trainingstext dem Vokabular mit den entsprechenden Token-IDs hinzugefügt:
- meow (9)
- skateboard (10)
- und so weiter...
Mit einem ausreichend großen Dataset mit Trainingstext könnte ein Vokabular aus vielen Tausenden Token kompiliert werden.
Einbettungen
Es kann zwar praktisch sein, Token als einfache IDs darzustellen, wodurch im Wesentlichen ein Index für alle Wörter im Vokabular erstellt wird, doch diese sagen nichts über die Bedeutung der Wörter oder die Beziehungen zwischen ihnen aus. Um ein Vokabular zu erstellen, das semantische Beziehungen zwischen den Token kapselt, definieren wir kontextbezogene Vektoren, die als Einbettungen bezeichnet werden. Vektoren sind mehrwertige numerische Darstellungen von Informationen, z. B. [10, 3, 1], bei denen jedes numerische Element ein bestimmtes Attribut der Informationen darstellt. Bei Sprachtoken stellt jedes Element des Tokenvektors ein semantisches Attribut des Tokens dar. Die spezifischen Kategorien für die Elemente der Vektoren in einem Sprachmodell werden während des Trainings basierend darauf bestimmt, wie häufig Wörter zusammen oder in ähnlichen Kontexten verwendet werden.
Vektoren stellen Linien im mehrdimensionalen Raum dar, die Richtung und Entfernung entlang mehrerer Achsen beschreiben (Sie können Ihre Mathe-Freunde beeindrucken, indem Sie von Amplitude und Magnitude sprechen). Es kann hilfreich sein, sich die Elemente in einem Einbettungsvektor für ein Token als Schritte entlang eines Pfads im mehrdimensionalen Raum vorzustellen. Ein Vektor mit drei Elementen stellt z. B. einen Pfad im dreidimensionalen Raum dar, in dem die Elementwerte die Einheiten angeben, die sich vorwärts/rückwärts, links/rechts und aufwärts/abwärts bewegt haben. Insgesamt beschreibt der Vektor die Richtung und den Abstand des Pfads vom Ursprung zum Ende.
Die Elemente der Token im Einbettungsraum stellen jeweils ein semantisches Attribut des Tokens dar, sodass semantisch ähnliche Token zu Vektoren führen sollten, die eine ähnliche Ausrichtung haben, d. h. sie zeigen in die gleiche Richtung. Eine Technik namens Kosinusähnlichkeit wird verwendet, um festzustellen, ob zwei Vektoren ähnliche Richtungen haben (unabhängig von der Entfernung) und daher semantisch verbundene Wörter darstellen. Nehmen wir als einfaches Beispiel an, dass die Einbettungen für unsere Token aus Vektoren mit drei Elementen bestehen, zum Beispiel:
- 4 („Hund“): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 („puppy“): [5,2,1]
- 10 („skateboard“): [-3,3,2]
Wir können diese Vektoren im dreidimensionalen Raum wie folgt darstellen:
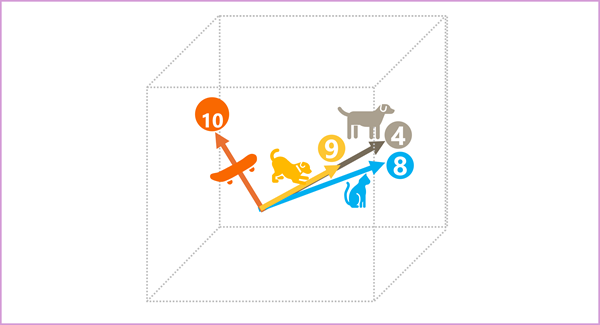
Die Einbettungsvektoren für „dog“ und „puppy“ beschreiben einen Pfad entlang einer fast identischen Richtung, die auch relativ ähnlich der Richtung für „cat“ ist. Der Einbettungsvektor für „Skateboard“ beschreibt jedoch die Journey in eine ganz andere Richtung.
Hinweis
Das vorige Beispiel zeigt ein einfaches Beispielmodell, in dem jede Einbettung nur drei Dimensionen aufweist. Echte Sprachmodelle haben viel mehr Dimensionen.
Es gibt mehrere Möglichkeiten, geeignete Einbettungen für einen bestimmten Tokensatz zu berechnen, einschließlich Sprachmodellierungsalgorithmen wie Word2Vec oder des Encoderblocks in einem Transformermodell.
Attention
Die Encoder- und Decoderblöcke in einem Transformermodell enthalten mehrere Schichten, die das neuronale Netz für das Modell bilden. Wir müssen nicht auf die Details all dieser Schichten eingehen, aber es ist hilfreich, eine der Arten von Schichten zu betrachten, die in beiden Blöcken verwendet wird: Aufmerksamkeitsschichten. Aufmerksamkeit ist eine Technik, die verwendet wird, um eine Sequenz aus Texttoken zu untersuchen und zu versuchen, die Intensität der Beziehungen zwischen ihnen zu quantifizieren. Insbesondere beinhaltet die Selbstaufmerksamkeit , wie andere Token um ein bestimmtes Token herum die Bedeutung dieses Tokens beeinflussen.
In einem Encoderblock wird jedes Token in seinem Kontext genau untersucht und es wird eine geeignete Codierung für seine Vektoreinbettung bestimmt. Die Vektorwerte basieren auf der Beziehung zwischen dem Token und anderen Token, mit denen es häufig auftaucht. Dieser kontextbezogene Ansatz bedeutet, dass ein und dasselbe Wort je nach dem Kontext, in dem es verwendet wird, mehrere Einbettungen haben kann. Beispielsweise bedeutet „the bark of a tree“ (die Rinde eines Baumes) etwas anderes als „I heard a dog bark“ (Ich hörte einen Hund bellen).
In einem Decoderblock werden Aufmerksamkeitsschichten verwendet, um das nächste Token in einer Sequenz vorherzusagen. Für jedes generierte Token verfügt das Modell über eine Aufmerksamkeitsschicht, die die Reihenfolge der Token bis zu diesem Punkt berücksichtigt. Das Modell berücksichtigt, welches der Token am einflussreichsten ist, wenn es das nächste Token vorhersagt. Zum Beispiel könnte bei der Sequenz „I heard a dog“ die Aufmerksamkeitsschicht den Token „heard“ und „dog“ eine größere Gewichtung zuweisen, wenn das nächste Wort in der Sequenz betrachtet wird:
I heard a dog [bark]
Bedenken Sie, dass die Aufmerksamkeitsschicht mit numerischen Vektordarstellungen der Token arbeitet, nicht mit dem tatsächlichen Text. In einem Decoder beginnt der Prozess mit einer Sequenz aus Tokeneinbettungen, die den zu schreibenden Text darstellen. Zuerst fügt eine weitere Positionscodierungsschicht jeder Einbettung einen Wert hinzu, um dessen Position in der Sequenz anzugeben:
- [1,5,6,2] (I)
- [2,9,3,1] (heard)
- [3,1,1,2] (a)
- [4,10,3,2] (dog)
Während des Trainings besteht das Ziel darin, den Vektor für das endgültige Token in der Sequenz basierend auf den vorherigen Token vorherzusagen. Die Aufmerksamkeitsschicht weist jedem Token in der bisherigen Sequenz eine numerische Gewichtung zu. Dieser Wert wird verwendet, um eine Berechnung auf Grundlage der gewichteten Vektoren auszuführen, die einen Aufmerksamkeitswert erzeugt, der zum Berechnen eines möglichen Vektors für das nächste Token verwendet werden kann. In der Praxis verwendet eine Technik, die als Multi-Head-Attention-Ansatz bezeichnet wird, verschiedene Elemente der Einbettungen, um mehrere Aufmerksamkeitswerte zu berechnen. Ein neuronales Netz wird dann verwendet, um alle möglichen Token auszuwerten und das wahrscheinlichste Token zu bestimmen, mit dem die Sequenz fortgesetzt wird. Der Prozess wird für jedes Token in der Sequenz iterativ fortgesetzt, wobei die Ausgabesequenz bisher regressiv als Eingabe für die nächste Iteration verwendet wird. Im Wesentlichen wird die Ausgabe Token für Token erzeugt.
Die folgende Animation zeigt eine vereinfachte Darstellung der Funktionsweise. In Wirklichkeit sind die Berechnungen, die von der Aufmerksamkeitsschicht durchgeführt werden, komplexer, aber die Prinzipien können wie dargestellt vereinfacht werden:

- Eine Sequenz aus Tokeneinbettungen wird in die Aufmerksamkeitsschicht eingespeist. Jedes Token wird als Vektor numerischer Werte dargestellt.
- Ein Decoder hat die Aufgabe, das nächste Token in der Sequenz vorherzusagen. Dabei handelt es sich ebenfalls um einen Vektor, der an einer Einbettung im Vokabular des Modells ausgerichtet ist.
- Die Aufmerksamkeitsschicht wertet die bisherige Sequenz aus und weist jedem Token eine Gewichtung zu, um den relativen Einfluss auf das nächste Token darzustellen.
- Die Gewichtungen können verwendet werden, um einen neuen Vektor für das nächste Token mit einem Aufmerksamkeitswert zu berechnen. Der Multi-Head-Attention-Ansatz verwendet verschiedene Elemente in den Einbettungen, um mehrere alternative Token zu berechnen.
- Ein vollständig vernetztes neuronales Netz verwendet die Ergebnisse in den berechneten Vektoren, um das wahrscheinlichste Token aus dem gesamten Vokabular vorherzusagen.
- Die vorhergesagte Ausgabe wird an die bisherige Sequenz angefügt, die als Eingabe für die nächste Iteration verwendet wird.
Während des Trainings ist die tatsächliche Abfolge der Token bekannt. Wir maskieren nur diejenigen, die später in der Sequenz auftauchen, nicht die Tokenposition, die derzeit berücksichtigt wird. Wie in jedem neuronalen Netz wird der vorhergesagte Wert für den Tokenvektor mit dem tatsächlichen Wert des nächsten Vektors in der Sequenz verglichen, und der Verlust wird berechnet. Die Gewichtungen werden dann inkrementell angepasst, um den Verlust zu reduzieren und das Modell zu verbessern. Bei Verwendung für Rückschlüsse (Vorhersage einer neuen Abfolge der Token) wendet die trainierte Aufmerksamkeitsschicht Gewichtungen an, die das wahrscheinlichste Token im Vokabular des Modells vorhersagen, das semantisch auf die bisherige Sequenz ausgerichtet ist.
Doch was bedeutet das alles? Es bedeutet, dass ein Transformermodell wie GPT-4 (das Modell hinter ChatGPT und Bing) entwickelt wurde, um eine Texteingabe (als Prompt bezeichnet) zu verarbeiten und eine syntaktisch korrekte Ausgabe (als Completion bezeichnet) zu generieren. Tatsächlich besteht der „Zauber“ des Modells darin, dass es in der Lage ist, zusammenhängende Sätze zu bilden. Diese Fähigkeit setzt weder „Wissen“ noch „Intelligenz“ seitens des Modells voraus, sondern lediglich einen großen Wortschatz und die Fähigkeit, sinnvolle Wortfolgen zu erzeugen. Was ein großes Sprachmodell wie GPT-4 jedoch so leistungsfähig macht, sind die schiere Menge an Daten, mit denen es trainiert wurde (öffentliche und lizenzierte Daten aus dem Internet) und die Komplexität des neuronalen Netzes. Dadurch kann das Modell Completions generieren, die auf den Beziehungen zwischen Wörtern in dem Vokabular basieren, mit dem das Modell trainiert wurde. Häufig wird eine Ausgabe generiert, die von einer menschlichen Antwort auf dieselbe Prompt nicht zu unterscheiden ist.