Nachverfolgung von Incidents
Incidents haben einen Lebenszyklus. Für eine möglichst effektive Response müssen Sie die Entwicklung des Incidents und die Entwicklung Ihrer Response darauf vom Beginn des Lebenszyklus an nachverfolgen können.
Auswertung vorliegender Informationen
Sie können Ihren Nachverfolgungsprozess für Incidents gut für einen bestimmten Incident bewerten, indem die sich einige Fragen stellen:
- Wann haben Sie das Problem entdeckt? Wenn Sie die Wiederherstellungszeit nach einem Incident reduzieren möchten, müssen Sie die Informationen ab dem Zeitpunkt erfassen, zu dem Sie auf das Problem aufmerksam geworden sind.
- Wie haben Sie das Problem entdeckt? Hat Ihr Überwachungssystem Sie über das Problem benachrichtigt? Haben Sie es über Kundenbeschwerden (direkt oder über soziale Netzwerke) entdeckt?
- Wenn Sie gerade erst von dem Problem erfahren, sind Sie dann der Erste, der davon erfährt? Wenn ja, wen müssen Sie in Kenntnis setzen? Wenn nein, wem ist das Problem noch bekannt?
- Wenn auch andere Personen Bescheid wissen, welche Maßnahmen werden (wenn überhaupt) bereits ergriffen? Geht jeder davon aus, dass sich jemand anderes dem Problem annimmt, oder hat jemand bereits Maßnahmen eingeleitet?
- Wie gravierend ist das Problem? Möglicherweise liegen keine Angaben zum Schweregrad und der Auswirkung vor, und Sie können nicht herausfinden, wie gravierend das Problem ist und wer betroffen ist.
Diese Fragen können schwer zu beantworten sein, wenn nichts nachverfolgt wird.
Standardisieren des Orts für die Nachverfolgung von Incidentinformationen
Es gibt viele mögliche Orte, an denen Sie die Liste der (aktiven oder anderen) Incidents und alle aktuellen Informationen dazu aufbewahren und freigeben können. Die Bandbreite reicht dabei von einfachen Lösungen wie einem freigegebenen Dateibereich mit Word-Dokumenten bis hin zu komplexen Lösungen wie Software und Diensten zur Nachverfolgung von Incidents, die hoch spezialisiert sind. Zwischen diesen beiden Extremen liegen Ticket- und Arbeitsüberwachungssysteme, die von Ihnen für diese Aufgabe verwendet werden können. Wichtiger als das System, für das Sie sich entscheiden, ist allerdings dessen Anwendung. Unabhängig davon, welches System Sie verwenden, muss jeder, der in irgendeiner Form mit Incidents zu tun haben kann, (Entwickler, Kundendienst, Management, PR-Abteilung, Rechtsabteilung etc.) wissen, wo er das System findet, wie ein Incident ausgelöst wird und wie auf die Daten zugegriffen werden kann, falls dies erforderlich ist. Eine Nachverfolgung von Incidents scheitert unter anderem mit Sicherheit, wenn die zu unterstützenden Personen nicht wissen, wie sie zu dem System gelangen, wenn sie es brauchen („Wie lautet die URL unseres Systems noch gleich?“).
Für das Beispielnachverfolgungssystem in diesem Modul verwenden wir die Arbeitselementfunktion von Azure DevOps.
Erstellen einer Kommunikationsbrücke
Für die Beantwortung einiger der Fragen im obigen Abschnitt Auswertung vorliegender Informationen und um mit dem Incident-Response-Prozess beginnen zu können, müssen Sie sich mit anderen über den Incident austauschen können. Im Idealfall wird hierfür ein elektronisches Kommunikationsmittel für die Zusammenarbeit im Team verwendet. Die Verwendung von Telefonkonferenzsystemen ist allerdings auch möglich. Telefonkonferenzen sind weniger bevorzugt, da es dort schwieriger ist, die Kommunikation in Bezug auf einen Incident rückwirkend zu überprüfen (daher die bereits erwähnte Schriftführerrolle).
Unabhängig davon, für welches Medium Sie sich entscheiden, sollten Sie sicherstellen, dass Sie einen separaten Kanal erstellen, der streng und ausschließlich auf Diskussionen zum betreffenden Incident beschränkt ist. Es ist wichtig, zu verhindern, dass in diesem Kanal irrelevante Diskussionen geführt werden, da Sie die Daten später in Ihrer Überprüfung nach dem Incident analysieren können müssen.
In diesem Modul verwenden wir Microsoft Teams als Kommunikationsmethode für Incidents.
Automatisieren des Starts der Nachverfolgung von Incidents
Sehen wir uns nun die bisher zusammengestellten Komponenten an. Sie verfügen nun über:
- Einen Dienstplan mit den Personen, die Bereitschaft haben (und ein definierter Übergabeplan für diese Personen).
- Rollen, die Sie den Personen zuweisen können, die an einem Incident arbeiten.
- Einen bestimmten Ort, an dem der Incident ausgelöst und nachverfolgt wird.
- Einen separaten Kanal für die am betreffenden Incident arbeitenden Personen, um sich darüber auszutauschen.
Sie können und sollten das Erstellen und Verwalten all dieser Dinge so weit wie möglich automatisieren. Beim Auftreten eines dringenden Problems möchten Sie sich nicht an alle erforderlichen Schritte zum Auslösen eines Incidents, Einbinden der richtigen Personen und Nachverfolgen erinnern müssen. Sie möchten einfach nur das Startsignal geben können, damit sofort mit der Bearbeitung des Problems begonnen werden kann.
Verwenden von Logic Apps für codelose Automatisierung
Eine Möglichkeit zum Automatisieren der ersten Phase der Incident Response ist die Verwendung von Logic Apps. Dieser Dienst kann die Planung, Automatisierung und Koordination von Aufgaben, Geschäftsprozessen und Workflows vereinfachen.
Logic Apps ist ein Azure-Clouddienst für das Erstellen von Integrationslösungen. Er verwendet Connectors, um automatisierte Workflows zu erstellen. Trigger starten die Logik-App, wenn ein bestimmtes Ereignis eintritt oder wenn Daten bestimmte Kriterien erfüllen. Aktionen sind die Vorgänge, die dann im Workflow der Logik-App ausgeführt werden.
In unserem Beispiel werden die folgenden Logic Apps-Connectors für die Nachverfolgung von Incidents verwendet:
- Azure Boards (Teil von Azure DevOps) kann zum Erstellen und Nachverfolgen von Issues/Incidents verwendet werden.
- Azure Storage kann zum Speichern und Abrufen von Informationen darüber, wer gerade Bereitschaft hat, verwendet werden, damit Sie die richtigen Personen zuweisen können, um auf den Incident zu reagieren. In unserem Beispiel verwenden wir Azure Table-Storage, da diese einen sehr einfachen Schlüssel-Wert-Speicher darstellen, mit dem Sie einfach eine Liste mit den Entwicklern und deren Bereitschaftsstatus speichern können.
- Microsoft Teams kann zum Erstellen eines neuen, separaten Kanals zum Nachverfolgen der Kommunikation Ihrer Entwicklerteams in Bezug auf bestimmte Incidents in Echtzeit verwendet werden. Auf diese Weise können Sie die Interaktionen zusammen mit der Chronologie der Ereignisse für eine spätere Überprüfung nach dem Incident festhalten.
Im Folgenden verbinden Sie all dies in einer Logik-App miteinander. Sehen Sie sich zunächst die gesamte App an, wie im Designer für Logic Apps gezeigt. Anschließend wird auf die einzelnen Schritte bei deren Erstellung eingegangen.
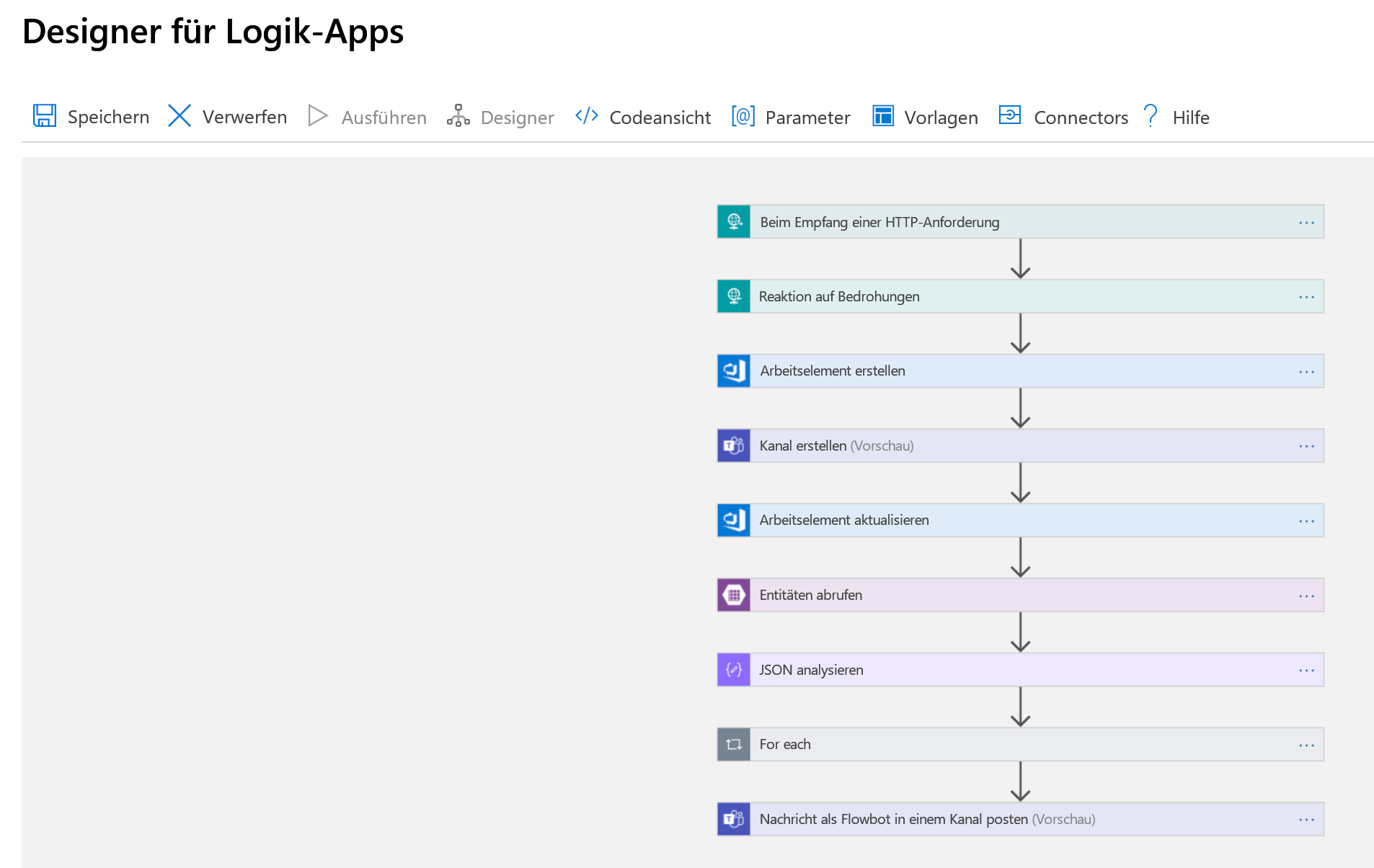
Der erste Schritt ist die Verarbeitung eines Triggers, der bereits erwähnten HTTP-Anforderung. An die Logik-App wird eine HTTP POST-Anforderung gesendet, die eine JSON-Nutzlast mit Informationen zu dem Incident enthält, den Sie auslösen möchten. Diese Nutzlast wird analysiert und eine Empfangsbestätigung zurückgesendet:
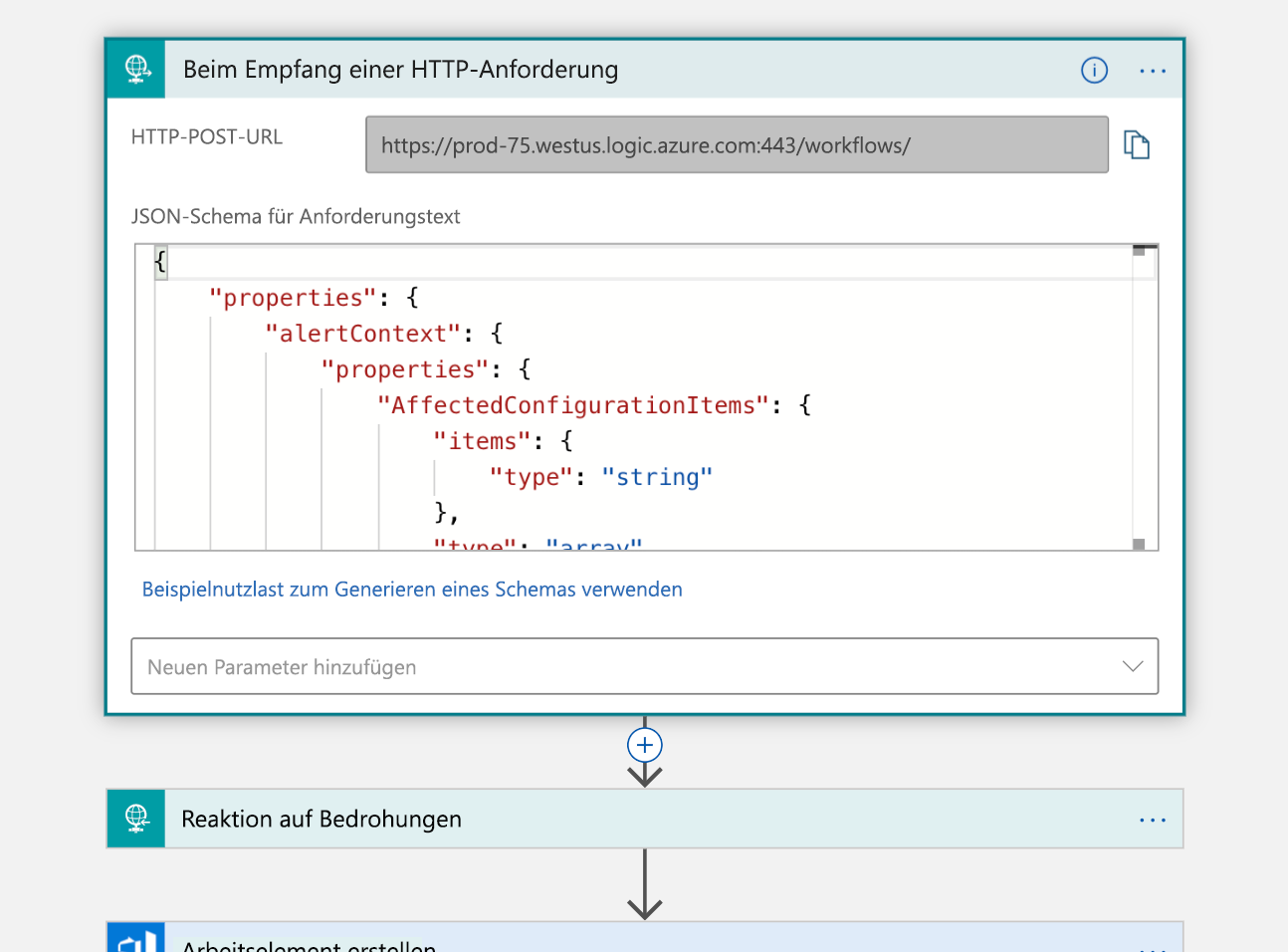
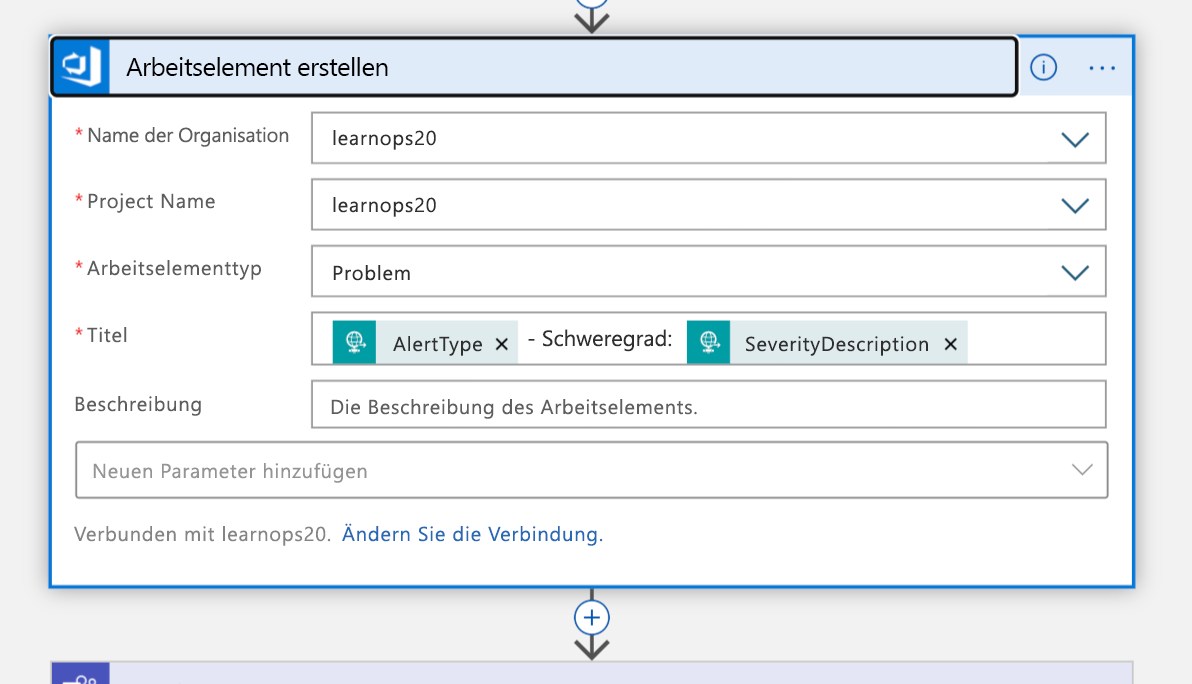
Mit diesen Informationen erstellen Sie in Ihrer Azure DevOps-Organisation ein neues Arbeitselement, das diesen Incident darstellt.
Dann wird ein neuer Teams-Kanal für den Incident erstellt:
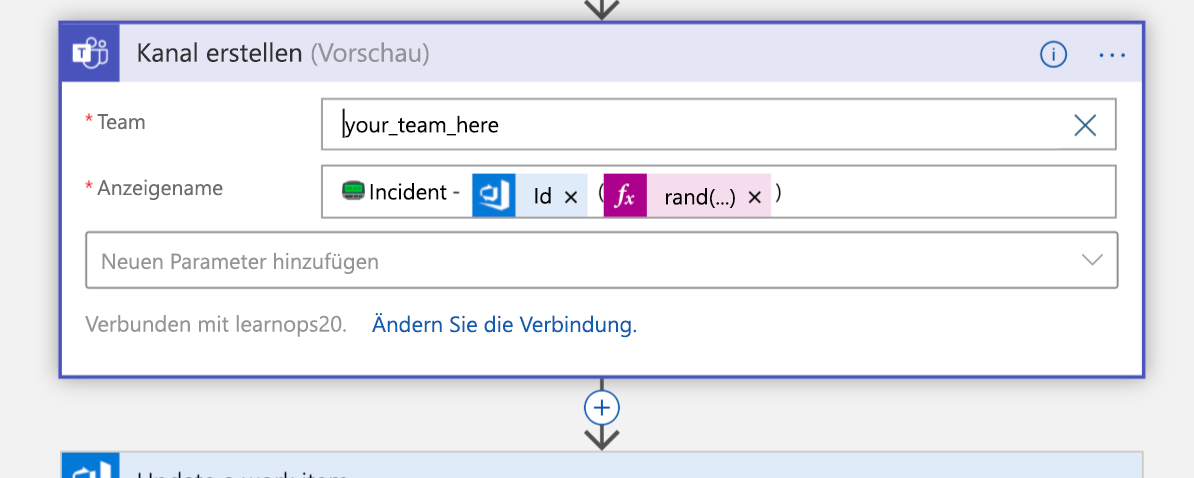
Sobald der Kanal erstellt ist, wird das soeben erstellte Arbeitselement mit einem Link zu dem neuen Kanal aktualisiert. Dadurch werden alle Informationen an einem Ort (dem Arbeitselement) aufbewahrt, und Personen, die sie sich später ansehen, wissen, wo sie diesen Kanal finden, um beizutreten.
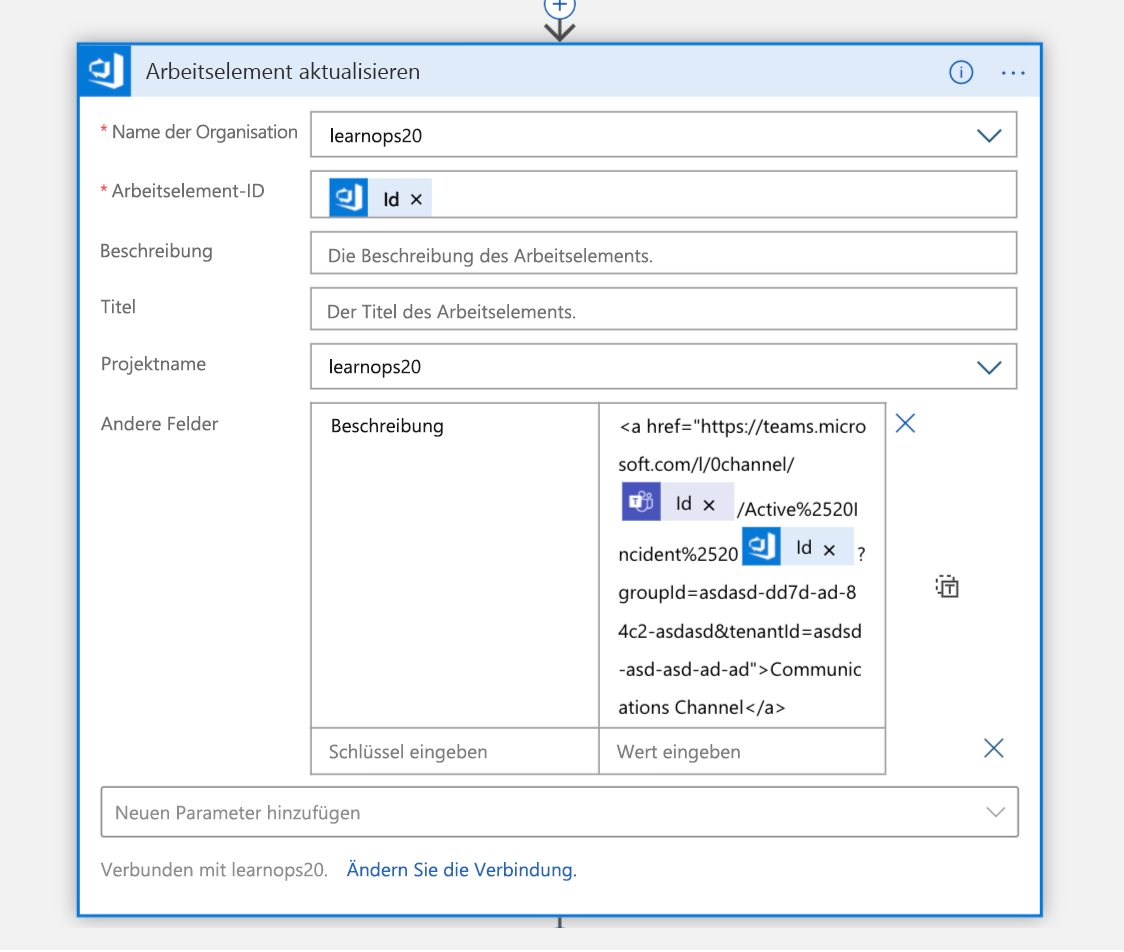
Nun soll die Person einbezogen werden, die jeweils Bereitschaft hat. Führen Sie eine Suche in Azure Table-Storage nach der E-Mail-Adresse des Entwicklers durch, für den angegeben ist, dass er Bereitschaft hat. Es wird eine JSON-Antwort zurückgegeben, die dann analysiert wird.
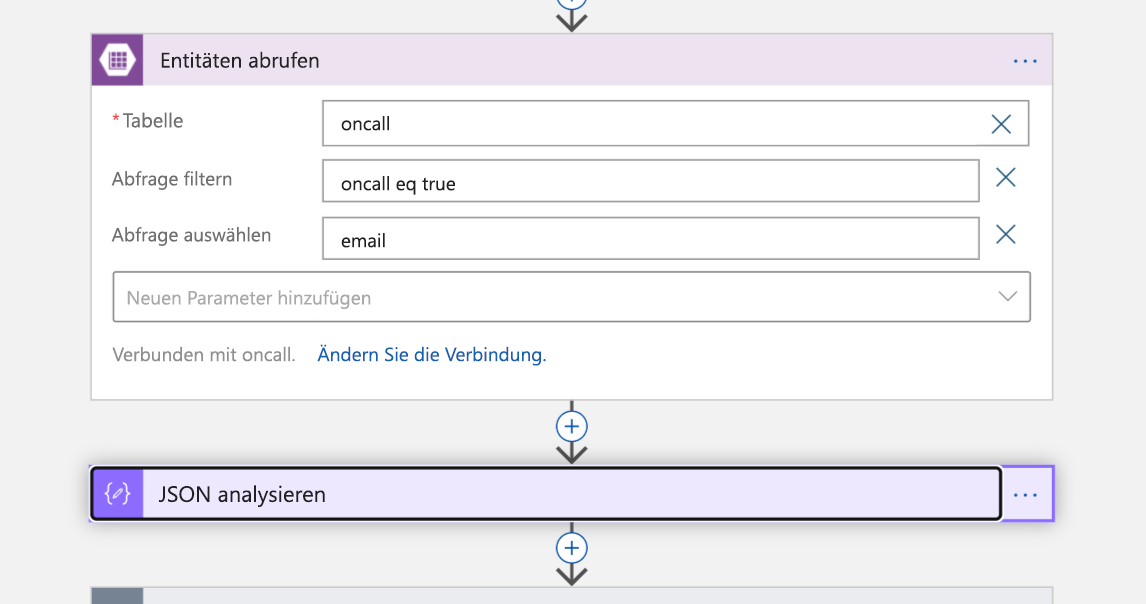
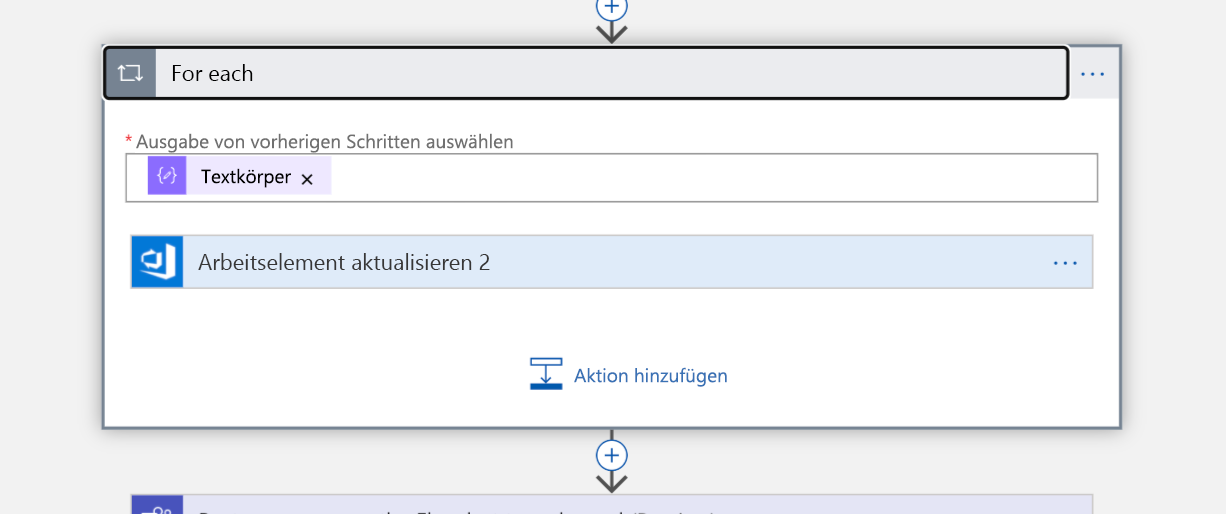
Weil unsere Abfrage eine Liste zurückgibt, müssen im nächsten Schritt alle Elemente dieser Liste durchlaufen werden. Das Arbeitselement wird allen diesen Personen zugewiesen. (Sie sind damit jetzt „Besitzer“ des Incidents.)
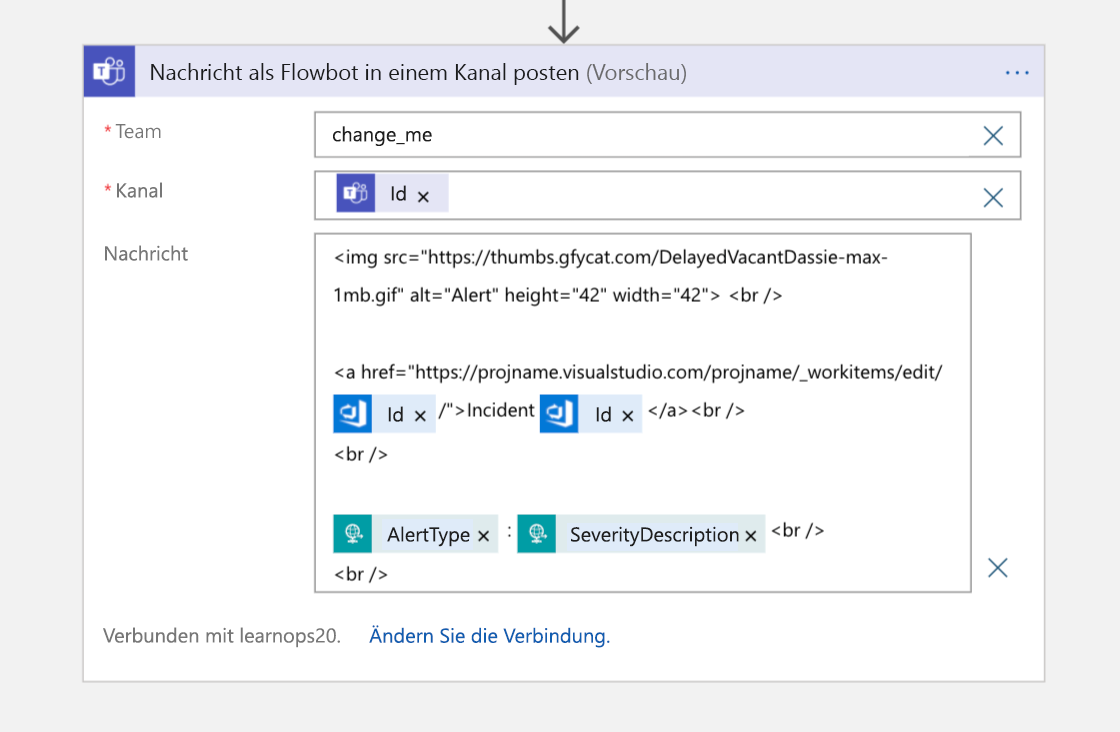
Im letzten Schritt wird eine Nachricht mit einem Zeiger zum Arbeitselement an den Teams-Kanal gesendet für Personen, die dem Kanal beitreten und wissen möchten, wo die maßgeblichen Informationen für diesen Incident gespeichert sind.
Dies ist nur ein Beispiel dafür, wie die Einrichtung der Mechanismen für die Nachverfolgung von Incidents und die entsprechende Kommunikation automatisiert werden kann. In der nächsten Lerneinheit wird näher auf Aspekte der Kommunikation im Zusammenhang mit einem Incident eingegangen.