Kombinieren und Optimieren von Daten
Organisationen sammeln häufig verschiedene Arten von Informationen aus vielen Quellen. Die Informationen werden in einer großen Anzahl von Tabellen gespeichert. Gelegentlich kann es erforderlich sein, Tabellen auf der Grundlage logischer Beziehungen zwischen ihnen zu verknüpfen, um eine tiefergehende Analyse oder Berichterstellung zu ermöglichen. Im Szenario des Einzelhandelsunternehmens verwenden Sie Tabellen für Kund*innen, Produkte und Verkaufsinformationen.
In diesem Modul lernen Sie die verschiedenen Möglichkeiten kennen, wie Sie Daten in Kusto-Abfragen kombinieren können, um Ihrem Team die Informationen zur Verfügung zu stellen, die es benötigt, um das Produktbewusstsein zu steigern und den Umsatz zu steigern.
Verstehen Ihrer Daten
Bevor Sie mit dem Schreiben von Abfragen beginnen, die Informationen aus Ihren Tabellen kombinieren, müssen Sie Ihre Daten verstehen. Wenn Sie mit Kusto-Abfragen arbeiten, sollten Sie sich vorstellen, dass Tabellen ganz allgemein zu einer von zwei Kategorien gehören:
- Faktentabellen: Tabellen, deren Datensätze unveränderliche Fakten darstellen, z. B. die SalesFact-Tabelle im Einzelhandelsunternehmensszenario. In diesen Tabellen werden Datensätze nach und nach in einem Streamingverfahren oder in großen Blöcken angefügt. Die Datensätze verbleiben in der Tabelle, bis sie entfernt werden, und werden nie aktualisiert.
- Dimensionstabellen: Tabellen, deren Datensätze veränderliche Dimensionen sind, z. B. die Tabellen Customers und Products im Einzelhandelsunternehmensszenario. Diese Tabellen enthalten Verweisdaten, z. B. Nachschlagetabellen zwischen einem Entitätsbezeichner und den zugehörigen Eigenschaften. Dimensionstabellen werden nicht regelmäßig mit neuen Daten aktualisiert.
In Ihrem Szenario mit einem Einzelhandelsunternehmen verwenden Sie Dimensionstabellen, um die Tabelle SalesFact mit zusätzlichen Informationen anzureichern oder weitere Optionen zum Filtern der Daten für Abfragen bereitzustellen.
Sie sollten auch die Datenvolumen, mit denen Sie arbeiten, sowie deren Struktur oder Schema (Spaltennamen und -typen) verstehen. Sie können die folgenden Abfragen ausführen, um diese Informationen abzurufen. Ersetzen Sie dabei TABLE_NAME durch den Namen der Tabelle, die Sie untersuchen:
Verwenden Sie den
count-Operator, um die Anzahl der Datensätze in einer Tabelle abzurufen:TABLE_NAME | countVerwenden Sie den
getschema-Operator, um das Schema einer Tabelle abzurufen:TABLE_NAME | getschema
Wenn Sie diese Abfragen für die Fakten- und Dimensionstabellen im Einzelhandelsunternehmensszenario ausführen, erhalten Sie Informationen wie im folgenden Beispiel:
| Tabelle | Datensätze | Schema |
|---|---|---|
| SalesFact | 2.832.193 | – SalesAmount (reell) – TotalCost (reell) – DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| Kunden | 18.484 | – CityName (string) – CompanyName (string) – CompanyName (string) - CustomerKey (long) – Education (Zeichenfolge) – FirstName (string) – Gender (string) – LastName (string) – MaritalStatus (string) – Occupation (string) – RegionCountryName (string) – StateProvinceName (string) |
| Produkte | 2.517 | – ProductName (string) – Manufacturer (string) – ColorName (string) – ClassName (string) – ProductCategoryName (string) – ProductCategoryName (string) - ProductKey (long) |
In der Tabelle sind die eindeutigen Bezeichner CustomerKey und ProductKey hervorgehoben, die zum Kombinieren von Datensätzen zwischen Tabellen verwendet werden.
Grundlegendes zu Abfragen in mehreren Tabellen
Nachdem Sie Ihre Daten analysiert haben, müssen Sie nun lernen, wie Sie Tabellen kombinieren, um die benötigten Informationen bereitzustellen. Kusto-Abfragen stellen mehrere Operatoren zur Verfügung, mit denen Sie Daten aus mehreren Tabellen kombinieren können, einschließlich der Operatoren lookup, join und union.
Der join-Operator mergt die Zeilen zweier Tabellen, indem Werte aus den angegebenen Spalten aus beiden Tabellen zugeordnet werden. Die resultierende Tabelle hängt von der Art des Joins ab, den Sie verwenden. Wenn Sie beispielsweise einen inneren Join verwenden, verfügt die Tabelle über die gleichen Spalten wie die linke Tabelle (manchmal auch als äußere Tabelle bezeichnet), zuzüglich der Spalten aus der rechten Tabelle (manchmal auch als innere Tabelle bezeichnet). Weitere Informationen zu den Jointypen finden Sie im nächsten Abschnitt. Wenn eine Tabelle immer kleiner als die andere ist, verwenden Sie diese für die bestmögliche Leistung als die linke Seite des join-Operators.
Der lookup-Operator ist eine spezielle Implementierung des join-Operators, der die Leistung von Abfragen optimiert, bei denen eine Faktentabelle mit Daten aus einer Dimensionstabelle angereichert wird. Er erweitert die Faktentabelle um Werte, die in einer Dimensionstabelle nachgeschlagen werden. Für optimale Leistung geht das System standardmäßig davon aus, dass die linke Tabelle die größere Tabelle (Faktentabelle) und die rechte Tabelle die kleinere Tabelle (Dimensionstabelle) ist. Diese Annahme ist genau das Gegenteil der Annahme, die beim join-Operator verwendet wird.
Der union-Operator gibt alle Zeilen aus mindestens zwei Tabellen zurück. Er ist nützlich, wenn Sie Daten aus mehreren Tabellen kombinieren möchten.
Die materialize()-Funktion speichert Ergebnisse innerhalb einer Abfrageausführung zwischen, um sie anschließend in der Abfrage wiederzuverwenden. Dies ist so, als würde eine Momentaufnahme der Ergebnisse einer Unterabfrage erstellt und innerhalb der Abfrage mehrfach verwendet. Diese Funktion ist nützlich, um Abfragen für Szenarien zu optimieren, in denen für die Ergebnisse Folgendes gilt:
- Ihre Berechnung ist teuer.
- Sie sind nicht deterministisch.
In Kürze erfahren Sie mehr über die verschiedenen Tabellenzusammenführungsoperatoren und die materialize()-Funktion sowie deren Verwendung.
Joinarten
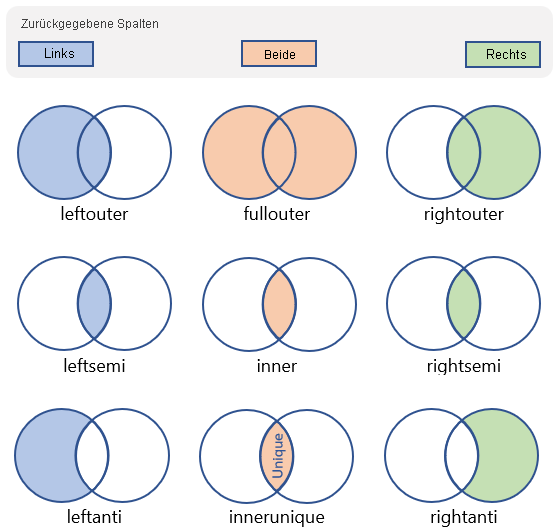
Es gibt viele verschiedene Arten von Joins, die ausgeführt werden können, die sich auf das Schema und die Zeilen in der sich ergebenden Tabelle auswirken. In der folgenden Tabelle werden die Typen von Joins aufgeführt, die von der Kusto-Abfragesprache unterstützt werden, sowie das Schema und die zurückgegebenen Zeilen:
| Art des Joins | BESCHREIBUNG | Abbildung |
|---|---|---|
innerunique (Standardwert) |
Innerer Join mit linker seitiger Deduplizierung Schema: Alle Spalten aus beiden Tabellen, einschließlich der übereinstimmenden Schlüssel. Zeilen: Alle deduplizierten Zeilen aus der linken Tabelle, die mit Zeilen aus der rechten Tabelle übereinstimmen. |

|
inner |
Innerer Standard-Join Schema: Alle Spalten aus beiden Tabellen, einschließlich der übereinstimmenden Schlüssel. Zeilen: Nur übereinstimmende Zeilen aus beiden Tabellen. |

|
leftouter |
Left Outer Join Schema: Alle Spalten aus beiden Tabellen, einschließlich der übereinstimmenden Schlüssel. Zeilen: Alle Datensätze aus der linken Tabelle und nur übereinstimmende Zeilen aus der rechten Tabelle. |

|
rightouter |
Rechte äußere Verknüpfung Schema: Alle Spalten aus beiden Tabellen, einschließlich der übereinstimmenden Schlüssel. Zeilen: Alle Datensätze aus der rechten Tabelle und nur übereinstimmende Zeilen aus der linken Tabelle. |

|
fullouter |
Vollständiger äußerer Join Schema: Alle Spalten aus beiden Tabellen, einschließlich der übereinstimmenden Schlüssel. Zeilen: Alle Datensätze aus beiden Tabellen mit nicht übereinstimmenden Zellen, die mit NULL aufgefüllt werden. |

|
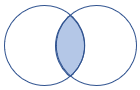
leftsemi |
Linker Semi-Join Schema: Alle Spalten aus der linken Tabelle. Zeilen: Alle Datensätze aus der linken Tabelle, die mit Datensätzen aus der rechten Tabelle übereinstimmen. |
|
leftanti, anti, leftantisemi |
Linker Antijoin und Semivariante Schema: Alle Spalten aus der linken Tabelle. Zeilen: Alle Datensätze aus der linken Tabelle, die nicht mit Datensätzen aus der rechten Tabelle übereinstimmen. |

|
rightsemi |
Rechter Semi-Join Schema: Alle Spalten aus der rechten Tabelle. Zeilen: Alle Datensätze aus der rechten Tabelle, die mit Datensätzen aus der linken Tabelle übereinstimmen. |

|
rightanti, rightantisemi |
Rechter Antijoin und Semivariante Schema: Alle Spalten aus der rechten Tabelle. Zeilen: Alle Datensätze aus der rechten Tabelle, die nicht mit Datensätzen aus der linken Tabelle übereinstimmen. |

|
Beachten Sie, dass der Standardjointyp innerunique ist. Er muss nicht angegeben werden. Dennoch empfiehlt es sich, den Jointyp aus Gründen der Klarheit immer explizit anzugeben.
Wenn Sie die Lerneinheiten durcharbeiten, lernen Sie auch die Aggregationsfunktionen arg_min() und arg_max() kennen, den as-Operator als Alternative zur let-Anweisung und die startofmonth()-Funktion zur Unterstützung bei der Gruppierung von Daten nach Monat.