Auswählen der geeigneten Nvidia-GPU-Option
Wenn Sie rechenintensive Modelle trainieren, wählen Sie die GPU-Computeleistung aus, die Ihren Anforderungen am besten entspricht, um Ihre Ressourcen optimal zu nutzen.
Erinnern Sie sich an das Deep-Learning-Modell, das Sie trainieren möchten, um handschriftlichen Text aus Versicherungsformularen zu extrahieren. Sie rechnen mit der Verwendung eines großen Datasets, und das Modell selbst ist rechenintensiv. Sie fragen sich, welcher Computeclustertyp für Ihre Workload am besten geeignet ist.
Sie erfahren mehr über die GPU-Typen, die in Azure Machine Learning angeboten werden, und wie Sie diese überwachen können, um die optimale Konfiguration zu finden.
GPU-Typen in Azure Machine Learning
Wenn Sie eine Compute-Instanz oder einen Cluster in Azure Machine Learning erstellen, werden virtuelle Azure-Computer für Sie erstellt und verwaltet.
Azure verfügt über eine Vielzahl von Größen für GPU-optimierte VMs, die Teil der N-Serie sind:
- Die NC-Serie wird für High-Performance-Computing- und Machine Learning-Workloads verwendet.
- Die ND-Serie wird für Trainings- und Rückschlussszenarios für Deep Learning eingesetzt.
- Die NV-Serie wird für Remotevisualisierungsworkloads und andere grafikintensive Anwendungen verwendet.
Um GPU-Compute zu nutzen, müssen Sie Code verwenden, der für die Arbeit mit GPUs konfiguriert ist. Ein häufiger Fehler ist die Verwendung von Code, der keine GPUs verwendet, was zu vielen verschwendeten Ressourcen führen kann.
Die gängigste GPU-Programmierschnittstelle ist CUDA (Compute Unified Device Architecture). Um CUDA in Azure Machine Learning verwenden zu können, schließen Sie die Schnittstelle in die Umgebung ein, die Sie beim Übermitteln eines Auftrags verwenden. Viele der zusammengestellten Umgebungen, die Sie beim Trainieren eines rechenintensiven Modells verwenden können, enthalten bereits CUDA.
Wenn Sie Frameworks oder Bibliotheken verwenden, die für die Verwendung von GPUs konzipiert sind, stellen Sie sicher, dass Sie den entsprechenden GPU-Typ auswählen. Wenn Sie beispielsweise mithilfe von RAPIDS große Datenmengen verarbeiten, müssen Sie eine Tesla V100-GPU-Computeressource erstellen.
Tipp
Unter Azure Machine Learning – zusammengestellte Umgebungen erfahren Sie mehr über die Umgebung, die Sie benötigen.
Auswählen des GPU-Typs
Berücksichtigen Sie bei der Auswahl der Computeressourcen für einen Auftrag die folgenden Faktoren:
- Leistung: Denken Sie an das Framework, das Sie zum Trainieren eines Modells verwenden. Bestimmte Algorithmen benötigen möglicherweise weniger Zeit für das Trainieren, verursachen aber höhere Kosten. Die GPU-Leistung variiert je nach Workload, aber eine kurze Übersicht finden Sie auf der NVIDIA-Website.
- Kosten: In Abhängigkeit Ihrer Anforderungen müssen Sie möglicherweise ein Modell auswählen, das entweder kosteneffizienter ist oder eine höhere Leistung erzielt. Um Kosten zu sparen, können Sie reservierte Instanzen für VMs oder VMs mit geringer Priorität verwenden.
- Standort: Berücksichtigen Sie die Verfügbarkeit virtueller Computer pro Azure-Region. Wenn Ihre Daten in einer bestimmten Region verbleiben müssen, kann sich dies auf die Auswahl des Modells auswirken.
- GPU-Arbeitsspeichergröße: Deep-Learning-Modelle profitieren davon, wenn ein Computecluster über genügend GPU-Arbeitsspeicher verfügt. Stellen Sie sich die Arbeitsspeicheranforderungen für das Modell vor, das Sie trainieren möchten. Die Anforderungen können die Größe des Datasets und die Anzahl der Parameter umfassen.
Überwachen, um eine optimale Konfiguration zu finden
Die einzige zuverlässige Möglichkeit, die optimale Computekonfiguration zu ermitteln, besteht in der Ausführung der Workload und der Überwachung der Ergebnisse.
Es steht eine Vielzahl von Befehlszeilentools zur Verfügung, um die GPU-Computeleistung zu überwachen. NVIDIA System Management Interface (nvidia-smi) ist eines der gängigsten Befehlszeilentools, die in einem definierten Intervall ausgeführt werden können.
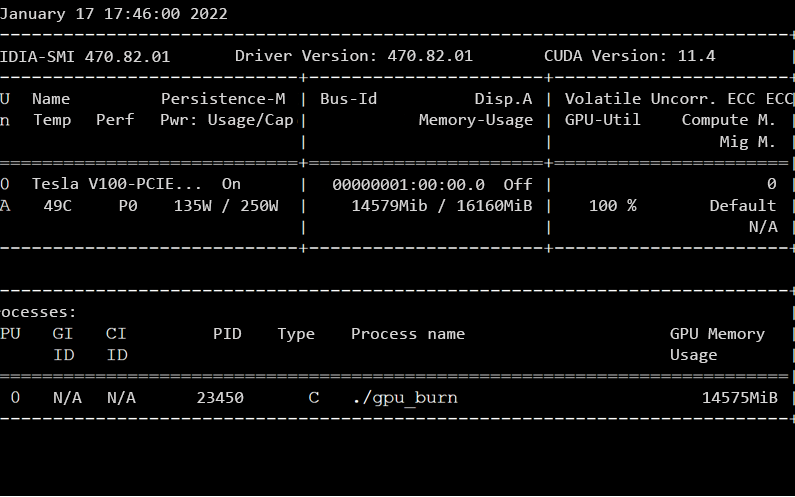
Tipp
Weitere Informationen finden Sie in der Beschreibung zur Verwendung von „nvidia-smi“ zum Überwachen Ihrer GPU-Computeressource.
Zum Überwachen der GPU-Auslastung eines Azure Machine Learning-Computeclusters können Sie Azure Monitor verwenden. Eine einfache Möglichkeit, auf den Dienst zuzugreifen, ist das Azure-Portal:
- Navigieren Sie zu https://portal.azure.com.
- Navigieren Sie zu Ihrer Azure Machine Learning-Ressource.
- Wählen Sie unter Überwachung die Option Metriken aus.
- Erstellen Sie ein neues Diagramm, und untersuchen Sie die Metriken für die GPU-Auslastung.
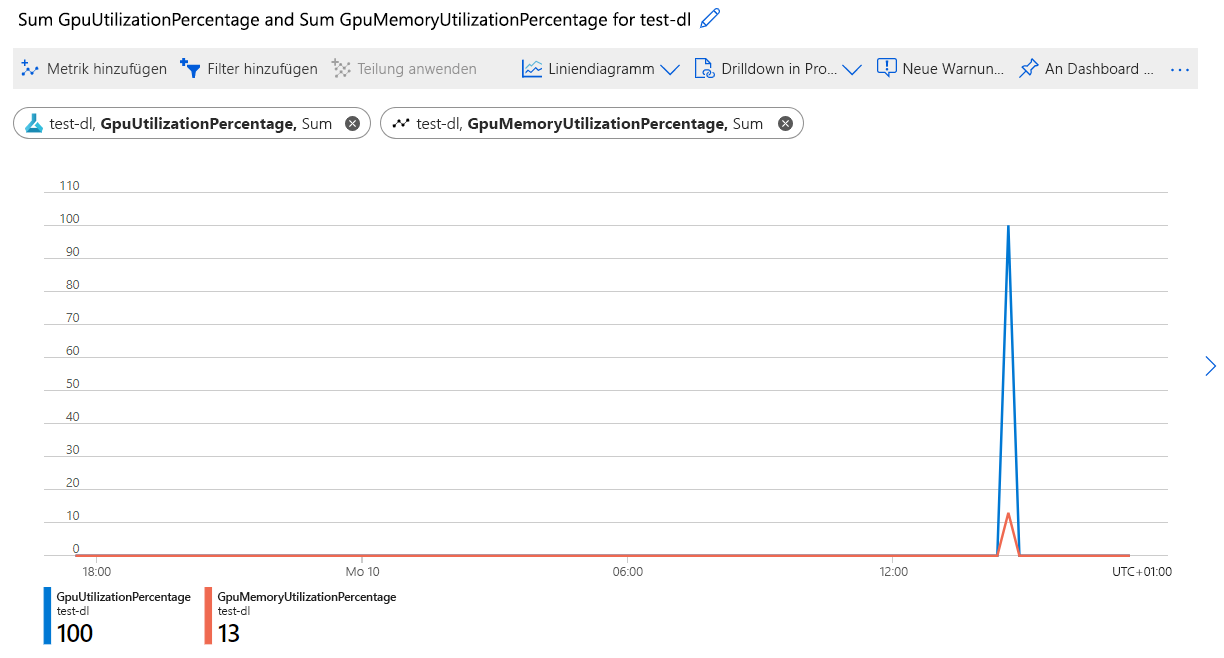
Im Azure Machine Learning Studio ist es auch möglich, die GPU-Auslastung für bestimmte Ausführungen zu überwachen.
Wenn Sie wissen, wie viel GPU während des Modelltrainings verbraucht wurde, können Sie überprüfen, ob die Workload die verfügbaren Ressourcen optimal nutzt. Im Idealfall maximieren die Ausführungen die verfügbare GPU und den GPU-Arbeitsspeicher und sind nicht durch den Durchsatz eingeschränkt.
Ein gängiger Ansatz ist es, mit einer einzelnen GPU und einem einzelnen Knoten zu beginnen. Als Nächstes können Sie mit mehr GPUs hochskalieren, indem Sie die Größe Ihrer Computeressourcen in Azure Machine Learning ändern. Sie können auch knotenübergreifend skalieren und Daten parallel verarbeiten. Ein verteilter Ansatz kann die Leistung verbessern, erfordert jedoch mehr Aufwand. Dieser Ansatz sollte nur verwendet werden, wenn erhebliche Verbesserungen vorgenommen werden können.