Problembehandlung beim Senden von Protokollen in einer AlwaysOn-Verfügbarkeitsgruppe
Dieser Artikel enthält Lösungen für Probleme im Zusammenhang mit der Warteschlange beim Senden von Protokollen.
Was ist log send queueing?
Änderungen, die an einer Verfügbarkeitsgruppendatenbank im primären Replikat (z INSERT. B. , UPDATEund DELETE) vorgenommen werden, werden in das Transaktionsprotokoll geschrieben und an die sekundären Replikate der Verfügbarkeitsgruppe gesendet. Die Protokoll-Sendewarteschlange definiert die Anzahl der Protokolldatensätze in den Protokolldateien der primären Datenbank, die nicht an die sekundären Replikate gesendet wurden.
Symptome und Auswirkungen der Warteschlange beim Senden von Protokollen
Warteschlange zum Senden von Protokollen speichert alle anfälligen Daten
Wenn das primäre Replikat in einem plötzlichen Notfall verloren geht und Sie an das sekundäre Replikat fehlschlagen, bei dem diese Änderungen noch nicht eingegangen sind, werden diese Änderungen nicht in der neuen primären Replikatkopie der Datenbank angezeigt. Dadurch werden alle Änderungen ausgeschlossen, die gespeichert werden, wenn vollständige Datenbank- und Protokollsicherungen ausgeführt werden.
Wachsende Warteschlange zum Senden von Protokollen führt zu wachsendem Wachstum der Transaktionsprotokolldatei
Für eine Datenbank, die in einer Verfügbarkeitsgruppe definiert ist, muss Microsoft SQL Server beim primären Replikat alle Transaktionen im Transaktionsprotokoll beibehalten, die noch nicht an die sekundären Replikate übermittelt wurden. Die Protokoll-Sendewarteschlange stellt die Anzahl der protokollierten Änderungen am primären Replikat dar, die während normalen Protokollabkürzungsereignissen (z. B. während einer Datenbankprotokollsicherung) nicht abgeschnitten werden können. Eine große und wachsende Warteschlange zum Senden von Protokollen kann freien Speicherplatz auf dem Laufwerk, auf dem die Datenbankprotokolldatei gehostet wird, ausschöpfen oder die konfigurierte maximale Größe der Transaktionsprotokolldatei überschreiten. Weitere Informationen finden Sie unter Fehler 9002, wenn das Transaktionsprotokoll groß ist.
Verschiedene Diagnosefeatures melden Verfügbarkeitsgruppenprotokoll-Senden in der Warteschlange
Das Always On-Dashboard im SQL Server Management Studio meldet die Warteschlange beim Senden von Protokollen. Möglicherweise wird berichtet, dass die Verfügbarkeitsgruppe fehlerhaft ist.
So überprüfen Sie die Warteschlange für das Senden von Protokollen
Die Protokoll-Sendewarteschlange ist eine Maßeinheit pro Datenbank. Sie können diesen Wert mithilfe des Always On-Dashboards im primären Replikat oder mithilfe der sys.dm_hadr_database_replica_states dynamischen Verwaltungsansichten (DMV) für das primäre oder sekundäre Replikat überprüfen. Leistungsmonitor Indikatoren werden verwendet, um die Warteschlange für das Senden von Protokollen für das sekundäre Replikat zu überprüfen.
In den nächsten Abschnitten werden Methoden zum aktiven Überwachen der Warteschlange zum Senden der Verfügbarkeitsgruppendatenbank bereitgestellt.
Abfrage-sys.dm_hadr_database_replica_state
Der sys.dm_hadr_database_replica_states DMV meldet eine Zeile für jede Verfügbarkeitsgruppendatenbank. Eine Spalte in diesem Bericht ist log_send_queue_size. Dieser Wert ist die Größe der Warteschlange für das Senden von Protokollen in Kilobyte (KB). Sie können eine Abfrage wie die folgende Abfrage einrichten, um einen beliebigen Trend in der Größe der Protokollnachricht-Warteschlange zu überwachen. Die Abfrage wird im primären Replikat ausgeführt. Es verwendet das is_local=0 Prädikat, um die Daten für das sekundäre Replikat zu melden, wo log_send_queue_size und log_send_rate welche relevant sind.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Die Ausgabe sieht wie folgt aus:

Überprüfen der Warteschlange zum Senden von Protokollen im AlwaysOn-Dashboard
Führen Sie die folgenden Schritte aus, um die Warteschlange zum Senden von Protokollen zu überprüfen:
Öffnen Sie das Always On-Dashboard in SQL Server Management Studio (SSMS), indem Sie mit der rechten Maustaste auf eine Verfügbarkeitsgruppe in SSMS-Objekt-Explorer klicken.
Wählen Sie " Dashboard anzeigen" aus.
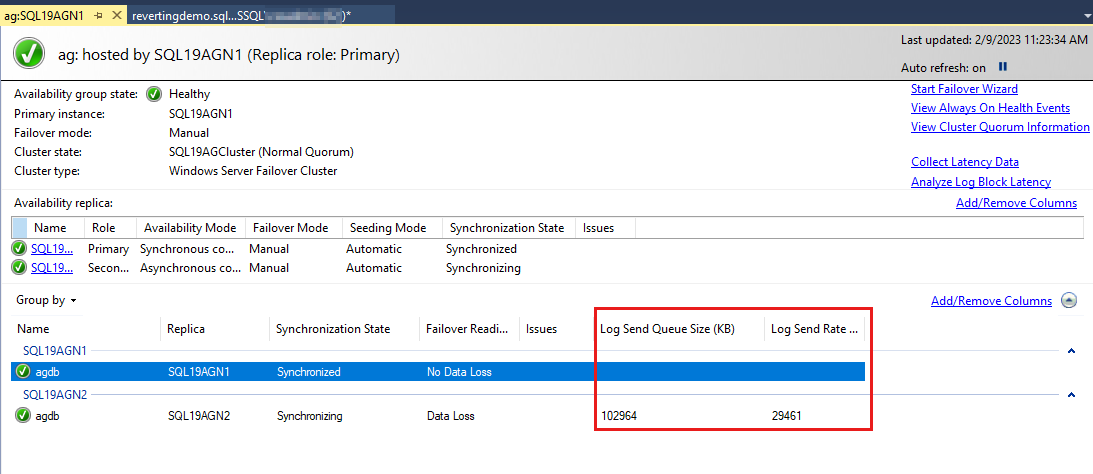
Die Verfügbarkeitsgruppendatenbanken werden zuletzt aufgelistet, und es werden einige Daten in den Datenbanken gemeldet. Obwohl die Größe der Log Send Queue (KB) und die Protokoll-Senderate (KB/Sek.) nicht standardmäßig aufgeführt sind, können Sie sie dieser Ansicht hinzufügen, wie im Screenshot im nächsten Schritt gezeigt.
Wenn Sie diese Spalten hinzufügen möchten, klicken Sie mit der rechten Maustaste auf die Spaltenüberschrift der Verfügbarkeitsgruppe, und wählen Sie aus der Liste der verfügbaren Spalten aus.
Wenn Sie die Größe der Warteschlange für das Senden von Protokollen hinzufügen möchten, klicken Sie mit der rechten Maustaste auf die Kopfzeile, die im folgenden Screenshot rot hervorgehoben ist.
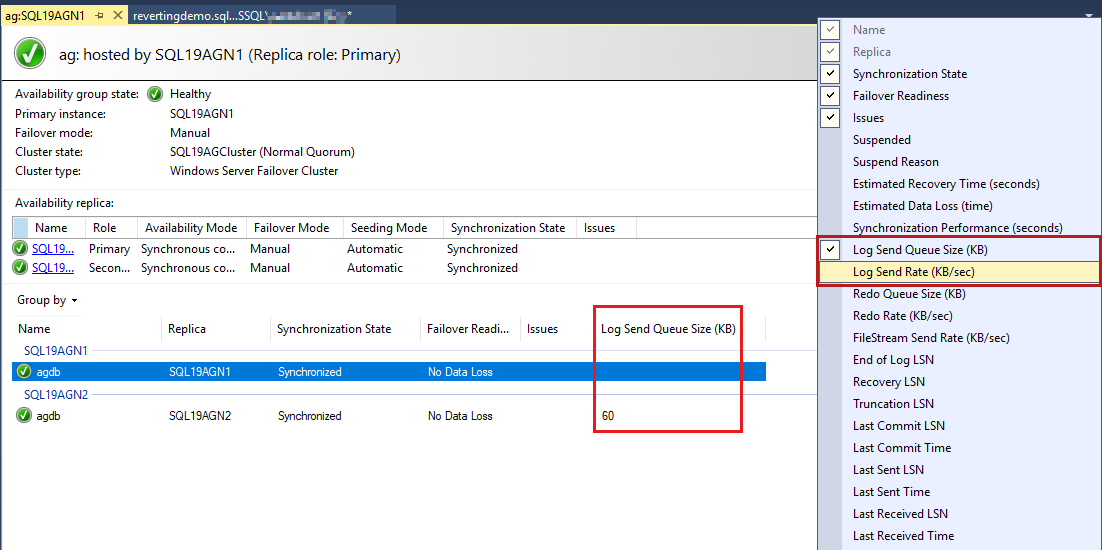
Standardmäßig aktualisiert das Always On-Dashboard diese Daten automatisch alle 60 Sekunden.


Überprüfen der Warteschlange zum Senden von Protokollen in Leistungsmonitor
Die Protokoll-Sendewarteschlange ist spezifisch für jede sekundäre Replikatdatenbank. Führen Sie daher die folgenden Schritte aus, um die Warteschlange zum Senden von Protokollen einer Verfügbarkeitsgruppe zu überprüfen:
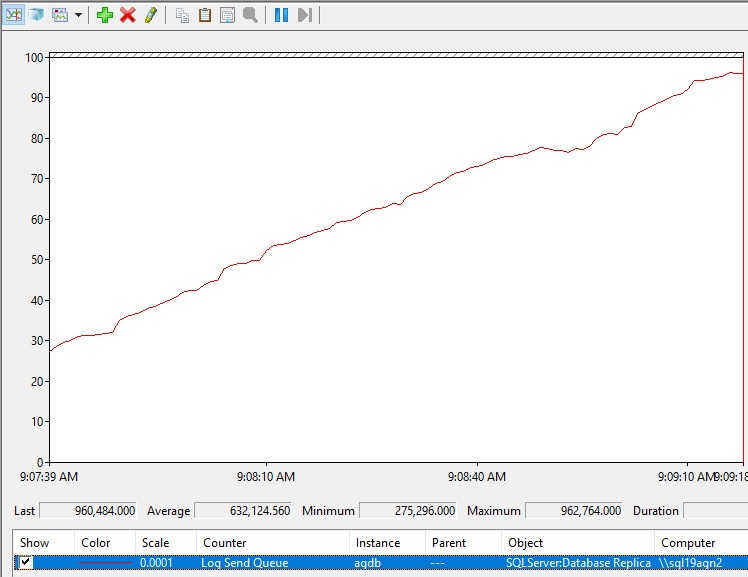
Öffnen Sie Leistungsmonitor für das sekundäre Replikat.
Wählen Sie die Schaltfläche "Hinzufügen " (Zähler) aus.
Wählen Sie unter "Verfügbare Leistungsindikatoren" die Zähler "SQLServer:Database Replica " und "Log Send Queue " aus.
Wählen Sie im Listenfeld "Instanz " die Verfügbarkeitsgruppendatenbank aus, die Sie auf die Warteschlange zum Senden von Protokollen überprüfen möchten.
Wählen Sie "Hinzufügen" und "OK" aus.
So könnte die Erhöhung der Warteschlange für das Senden von Protokollen aussehen.

Interpretieren von Protokoll-Sendewarteschlangenwerten
In diesem Abschnitt wird erläutert, wie die Werte der Größe der Protokoll-Sendewarteschlange interpretiert werden.
Wann ist log send queuing schlecht? Wie viel Log Send Queuing sollte toleriert werden?
Wenn die Protokoll-Sendewarteschlange den Wert 0 meldet, bedeutet dies, dass zum Zeitpunkt dieses Berichts keine Warteschlange zum Senden von Protokollen auftritt. Wenn Ihre Produktionsumgebung jedoch ausgelastet ist, sollten Sie davon ausgehen, dass die Protokoll-Sendewarteschlange häufig einen anderen Wert als Null meldet, auch in einer fehlerfreien AlwaysOn-Umgebung. Während der typischen Produktion sollten Sie davon ausgehen, dass dieser Wert zwischen 0 und einem Wert ungleich Null schwankt.
Wenn Sie beobachten, dass die Warteschlange für das Senden von Protokollen im Laufe der Zeit erhöht wird, wird eine weitere Untersuchung garantiert. Diese zusätzliche Aktivität gibt an, dass sich etwas geändert hat. Wenn Sie ein plötzliches Wachstum in der Protokoll-Sendewarteschlange beobachten, sind die folgenden Messungen für die Problembehandlung hilfreich:
- Protokoll-Senderate (KB/Sek.) (AlwaysOn-Dashboard)
- sys.dm_hadr_database_replica_states (DMV)
- Datenbankreplikat::Gespiegelte Transaktionen/Sek. (Leistungsmonitor)
Abrufen der Basissätze für die Protokoll-Senderate und gespiegelte Transaktionen/Sek.
Überwachen Sie während der fehlerfreien AlwaysOn-Leistung die Protokoll-Senderate und gespiegelte Transaktionen/Sek .-Werte für Ihre Datenbank für die Beschäftigt-Verfügbarkeitsgruppe. Wie sehen sie während der üblicherweise ausgelasteten Geschäftszeiten aus? Wie sehen sie in Zeiten der Wartung aus, wenn große Transaktionen einen höheren Transaktionsdurchsatz auf dem System fördern? Sie können diese Werte vergleichen, wenn Sie das Senden von Warteschlangen im Protokoll beobachten, um zu bestimmen, was sich geändert hat. Die Arbeitsauslastung ist möglicherweise größer als üblich. Wenn die Protokoll-Senderate kleiner als üblich ist, können weitere Untersuchungen erforderlich sein, um zu ermitteln, warum.
Workloadvolumes sind wichtig
Wenn Sie über große Arbeitslasten verfügen (z. B. eine UPDATE Anweisung für 1 Millionen Zeilen, eine Indexneuerstellung in einer 1-Terabyte-Tabelle oder sogar einen ETL-Batch, der Millionen von Zeilen einfügt), sollten Sie davon ausgehen, dass einige Warteschlangenwachstum für das Senden von Protokollen sofort oder im Laufe der Zeit angezeigt werden. Dies wird erwartet, wenn in der Verfügbarkeitsgruppendatenbank plötzlich eine große Anzahl von Änderungen vorgenommen wird.
So diagnostizieren Sie die Warteschlange zum Senden von Protokollen
Nachdem Sie die Warteschlange zum Senden von Protokollen für eine bestimmte Verfügbarkeitsgruppendatenbank identifiziert haben, sollten Sie nach verschiedenen möglichen Ursachen des Problems suchen, wie in den folgenden Abschnitten beschrieben.
Wichtig
Überprüfen Sie bei einer sinnvollen Ausgabe des Wartetyps mithilfe einer der Methoden, die in den vorherigen Abschnitten beschrieben werden, nach einer Erhöhung der Protokoll-Sendewarteschlange, wenn Sie die folgenden Bedingungen überwachen.
Das System ist zu ausgelastet
Überprüfen Sie, ob die Workload des primären Replikats die CPUs des Systems überlastet. Wenn eine Erhöhung der Warteschlange für das Senden von Protokollen angezeigt wird, fragen Sie den sys.dm_os_schedulers DMV ab, und überwachen Sie nach high runnable_tasks_count. Diese Anzahl gibt ausstehende Aufgaben an, die zu diesem Zeitpunkt ausgeführt wurden.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
Die folgende Tabelle enthält Beispiel für Ergebnisse. Eine Erhöhung des runnable_tasks_count Werts gibt an, dass eine große Anzahl von Aufgaben auf die CPU-Zeit wartet.
| scheduler_address | scheduler_id | cpu_id | Status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | SICHTBAR OFFLINE | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | SICHTBAR ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | SICHTBAR ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | SICHTBAR ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | SICHTBAR ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | SICHTBAR ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | SICHTBAR ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISIBLE | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | SICHTBAR ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | SICHTBAR ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | SICHTBAR ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | SICHTBAR ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | SICHTBAR ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | SICHTBAR ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | SICHTBAR ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | SICHTBAR ONLINE | 104 | 16 | 116 | 103 |
Lösung: Wenn Sie einen hohen runnable_task_countWert erkennen, verringern Sie die Arbeitsauslastung auf dem System, oder erhöhen Sie die Anzahl der CPUs, die für das System verfügbar sind.
Netzwerklatenz
Diese Bedingung ist besonders häufig, wenn das sekundäre Replikat physisch vom primären Replikat entfernt ist. Mithilfe von Verfügbarkeitsgruppen mit mehreren Standorten können Kunden Kopien von Geschäftsdaten an mehreren Standorten für die Notfallwiederherstellung und -berichterstellung bereitstellen. Dadurch werden nahezu echtzeitnahe Änderungen an den Kopien der Produktionsdaten an Remotestandorten zur Verfügung gestellt.
Wenn ein sekundäres Replikat weit vom primären Replikat gehostet wird, kann die Warteschlange für das Senden von Protokollen durch Netzwerklatenz und eine Unfähigkeit verursacht werden, Änderungen an die sekundäre Remote-Sekundäre zu senden, sobald sie in der primären Replikatdatenbank erstellt werden.
Wichtig
SQL Server verwendet eine einzelne Verbindung, um Änderungen von der primären mit den sekundären Replikaten zu synchronisieren. Wenn ein sekundäres Replikat remote ist, wirkt sich die Breite der Pipe daher nicht darauf aus, wie viele Daten SQL Server senden kann. Stattdessen hängt dieser Betrag von der Netzwerklatenz in der Pipe (Verbindungsgeschwindigkeit) ab.
Testen der Netzwerklatenz
Überprüfen, ob Ablaufsteuerungseinstellungen zur Netzwerklatenz beitragen
Microsoft SQL Server-Verfügbarkeitsgruppen verwenden Flusssteuerungsgates, um übermäßigen Verbrauch von Netzwerkressourcen, Arbeitsspeicher und anderen Ressourcen für alle Verfügbarkeitsreplikate zu vermeiden. Diese Flusssteuerungsgates wirken sich nicht auf den Synchronisierungsstatus der Verfügbarkeitsreplikate aus. Sie können sich jedoch auf die Gesamtleistung Ihrer Verfügbarkeitsdatenbanken einschließlich RPO auswirken.
Spätere Versionen von SQL Server ändern die Schwellenwerte, an denen die Flusssteuerung eingegeben wird. Dies kann dazu beitragen, den Effekt zu lindern, den die Flusssteuerung auf Symptome wie log send queueing hat. Weitere Informationen zur Flusssteuerung und zum Verlauf von Änderungen an Flusssteuerungsschwellenwerten finden Sie unter Flusssteuerungstore.
Sie können die Flusssteuerung überwachen, indem Sie Leistungsmonitor verwenden, um Daten im primären Replikat zu erfassen. Um die Datenbankflusssteuerung zu überwachen, fügen Sie SQLServer:Database Replica-Leistungsindikatoren hinzu, und wählen Sie die Datenbankflusssteuerungsverzögerung und Datenbankflusssteuerelemente/Sek . aus. Wählen Sie im Dialogfeld "Instanz " die Verfügbarkeitsgruppendatenbank aus, die Sie auf die Datenbankflusssteuerung überprüfen möchten. Um die Verfügbarkeitsreplikatflusssteuerung zu erkennen und zu überwachen, fügen Sie SQLServer:Availability Replica-Leistungsindikatoren hinzu, und wählen Sie die Ablaufsteuerungszeit (ms/sek) und die Ablaufsteuerung/Sek . aus.
Überprüfen, ob ein Überlastungs-Windows-Neustart zur Netzwerklatenz beiträgt
Netzwerkleistungsprobleme, die dazu führen, dass die Warteschlange für das Senden von Protokollen ausgelöst wird, indem die Tcp-Einstellung "Windows-Überlastung neu starten" auf "True" festgelegt ist. Dies war die Standardeinstellung in Windows Server 2016. Stellen Sie sicher, dass der Neustart des Überlastungsfensters auf "False" auf Windows-Servern festgelegt ist, auf denen Verfügbarkeitsgruppenreplikate gehostet werden, auf denen die Protokoll-Sendewarteschlange beobachtet wird.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart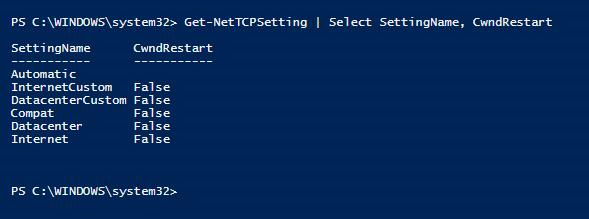
Weitere Informationen zum Festlegen der TCP-Überlastungs-Windows-Neustarteigenschaft auf "False" finden Sie unter "Set-NetTCPSetting (NetTCPIP)".
Weitere Informationen zum Synchronisierungsprozess finden Sie unter Überwachen der Leistung für AlwaysOn-Verfügbarkeitsgruppen . In diesem Artikel wird auch erläutert, wie Sie einige der wichtigsten Metriken berechnen und Links zu einigen der gängigen Szenarien zur Problembehandlung bei der Leistung bereitstellen.
Verwenden von Ping zum Abrufen eines Latenzbeispiels
Bei einer Befehlszeile auf Node1 (primäres Replikat), Pingknoten2 (sekundäres Replikat):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msTesten des Netzwerkdurchsatzes von primär zu sekundär mithilfe eines unabhängigen Tools
Verwenden Sie ein Tool wie NTttcp, um den Netzwerkdurchsatz zwischen den primären und sekundären Replikaten mithilfe einer einzigen Verbindung unabhängig zu erkennen. Die Netzwerklatenz ist eine häufige Ursache für das Senden von Protokollen. Die folgenden Schritte zeigen, wie Sie ein unabhängiges Tool wie NTttcp verwenden, um den Netzwerkdurchsatz zu messen.
Wichtig
SQL Server sendet Änderungen vom primären Replikat mithilfe einer einzigen Verbindung an das sekundäre Replikat. Im folgenden Abschnitt konfigurieren und führen wir NTttcp aus, um eine einzelne Verbindung (auf die gleiche Weise wie SQL Server) zu verwenden, um den Durchsatz genau zu vergleichen.
Sie können NTttcp von Github – microsoft/ntttcp herunterladen.
Führen Sie die folgenden Schritte aus, um NTttcp auszuführen:
Laden Sie das Tool herunter, und kopieren Sie es auf die primären und sekundären SQL Server-basierten Server.
Öffnen Sie auf dem sekundären Replikatserver ein Eingabeaufforderungsfenster mit erhöhten Rechten, ändern Sie das Verzeichnis in den NTttcp-Toolordner , und führen Sie dann den folgenden Befehl aus:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Notiz
In diesem Befehl
<secondaryipaddress>ist ein Platzhalter für die tatsächliche IP-Adresse des sekundären Replikatservers.Öffnen Sie auf dem primären Replikatserver ein Eingabeaufforderungsfenster mit erhöhten Rechten, ändern Sie das Verzeichnis in den Toolordner "NTttcp", und führen Sie dann den folgenden Befehl aus, indem Sie erneut die tatsächliche IP-Adresse des sekundären Replikatservers angeben:
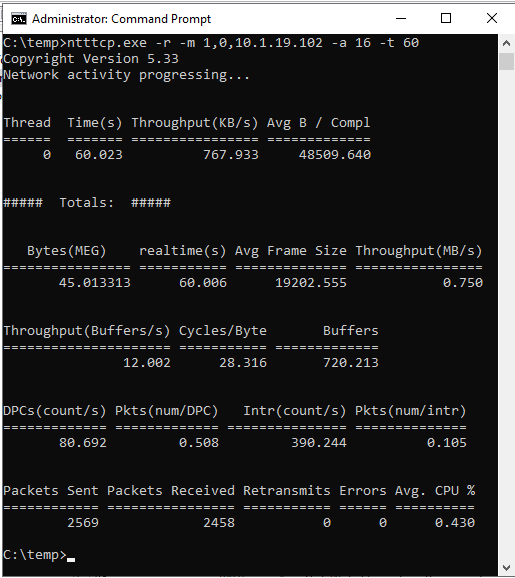
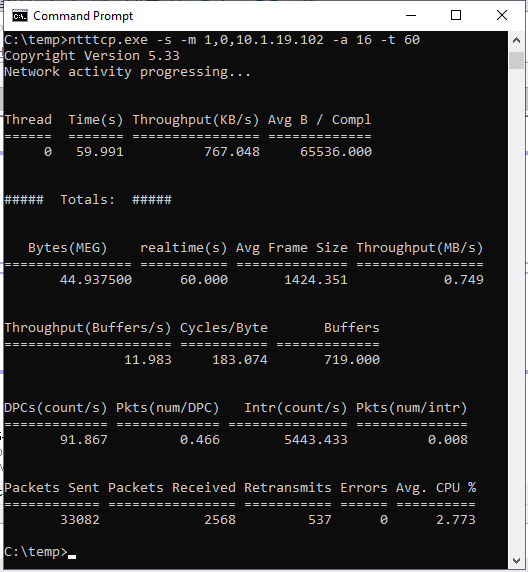
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60Die folgenden Screenshots zeigen NTttcp, der auf den sekundären und primären Replikaten ausgeführt wird. Aufgrund der Netzwerklatenz kann das Tool nur 739 KB/s Daten senden. Das können Sie davon ausgehen, dass SQL Server senden kann.
NTttcp für sekundäres Replikat
NTttcp für primäres Replikat
Überprüfen Leistungsmonitor Leistungsindikatoren
Überprüfen Sie, was NTttcp meldet. Eine große Transaktion wird in SQL Server im primären Replikat ausgeführt. Nachdem Sie Leistungsmonitor für das primäre Replikat gestartet haben, fügen Sie den Zähler "Network Interface::Bytes Sent/sec" hinzu. Dieser Leistungsindikator bestätigt, dass das primäre Replikat ca. 777 KB/s Daten senden kann. Dies ähnelt dem Wert von 739 KB/s, der vom NTttcp-Test gemeldet wird.

Es ist auch hilfreich, den SQL Server::D atabases::Log Bytes Flushed/sec-Wert für das primäre Replikat mit SQL Server::D atabase Replica::Log Bytes Received/sec für dieselbe Datenbank im sekundären Replikat zu vergleichen. Im Durchschnitt beobachten wir ca. 20 MB/s von Änderungen, die in der Datenbank "agdb" erstellt wurden. Das sekundäre Replikat empfängt jedoch im Durchschnitt nur 5,4 MB Änderungen. Dies führt dazu, dass die Warteschlange beim Senden von Protokollen im primären Replikat ausstehender Änderungen im Datenbanktransaktionsprotokoll, die noch nicht an das sekundäre Replikat gesendet wurden, gesendet wurde.
Primäre Replikatprotokoll bytes Flushed/sec für die Datenbank "agdb"

Sekundäre Replikatprotokollbytes empfangen/s für die Datenbank agdb
