Kapazitätsplanung für Active Directory Domain Services
Dieser Artikel enthält Empfehlungen zur Kapazitätsplanung für Active Directory Domain Services (AD DS).
Ziele der Kapazitätsplanung
Die Kapazitätsplanung ist nicht dasselbe wie die Problembehandlung bei Leistungsvorfällen. Die Ziele der Kapazitätsplanung sind:
- Ordnungsgemäßes Implementieren und Betreiben einer Umgebung.
- Minimieren des Zeitaufwand für die Behebung von Leistungsproblemen.
Bei der Kapazitätsplanung kann eine Organisation ein Basisziel von 40 % Prozessorauslastung in Spitzenzeiten haben, um die Leistungsanforderungen der Clients zu erfüllen und genügend Zeit für das Upgrade der Hardware im Rechenzentrum zu haben. Gleichzeitig wird der Schwellenwert für Überwachungswarnungen bei Leistungsproblemen über ein fünfminütiges Intervall auf 90 % festgelegt.
Wenn Sie den Schwellenwert für das Kapazitätsmanagement dauerhaft überschreiten, wäre das Hinzufügen von mehr oder schnelleren Prozessoren eine mögliche Lösung, um die Kapazität zu erhöhen oder den Dienst auf mehreren Servern zu skalieren. Schwellenwerte für Leistungswarnungen informieren Sie, wenn Sie sofortige Maßnahmen ergreifen müssen, wenn sich Leistungsprobleme negativ auf die Benutzeroberfläche des Clients auswirken. Im Gegensatz dazu richtet sich eine Problembehandlungslösung eher auf den Umgang mit einmaligen Ereignissen.
Das Kapazitätsmanagement ähnelt den präventiven Maßnahmen, die Sie ergreifen, um etwa einen Autounfall zu vermeiden, wie z. B. defensives Fahren, die Kontrolle, dass die Bremsen ordnungsgemäß funktionieren u. dgl. Die Fehlerbehandlung bei Problemen entspricht dann eher den Reaktionen von Polizei, Feuerwehr oder Notfallmedizinern auf einen Unfall.
In den letzten Jahren hat sich die Kapazitätsplanungsanleitung für Hochskalierungssysteme erheblich verändert. Die folgenden Änderungen bei Systemarchitekturen stellen Herausforderungen für grundlegende Annahmen hinsichtlich des Entwerfens und Skalierens eines Diensts dar:
- 64-Bit-Serverplattformen
- Virtualisierung
- Kritischere Betrachtung des Stromverbrauchs
- SSD-Speicher
- Cloudszenarien
Das Konzept für die Kapazitätsplanung wandelt sich ebenfalls, von der serverbasierten Planung hin zu dienstbasiertem Vorgehen. Active Directory Domain Services (AD DS), ein ausgereifter verteilter Dienst, den viele Produkte von Microsoft und Drittanbietern als Back-End verwenden, ist heute eines der wichtigsten Produkte, um sicherzustellen, dass Ihre anderen Anwendungen über die erforderliche Kapazität für die Ausführung verfügen.
Wichtige Informationen, die Sie berücksichtigen sollten, bevor Sie mit der Planung beginnen
Um diesen Artikel optimal zu nutzen, sollten Sie die folgenden Dinge tun:
- Stellen Sie sicher, dass Sie die Leistungsoptimierungsrichtlinien für Windows Server 2012 R2 gelesen und verstanden haben.
- Beachten Sie, dass es sich bei der Windows Server-Plattform um eine x64-basierte Architektur handelt. Außerdem müssen Sie wissen, dass die Richtlinien in diesem Artikel auch dann gelten, wenn Ihre Active Directory-Umgebung unter Windows Server 2003 x86 installiert ist (jetzt über das Ende des Supportlebenszyklus hinaus) und über eine Verzeichnisinformationsstruktur (Directory Information Tree, DIT) verfügt, die kleiner als 1,5 GB ist und problemlos im Arbeitsspeicher gespeichert werden kann.
- Beachten Sie, dass die Kapazitätsplanung ein kontinuierlicher Prozess ist; daher sollten Sie regelmäßig überprüfen, wie gut die von Ihnen erstellte Umgebung Ihren Erwartungen entspricht.
- Beachten Sie, dass die Optimierung über mehrere Hardware-Lebenszyklen hinweg erfolgt, wobei sich die Hardwarekosten ändern können. Wenn z. B. Arbeitsspeicher günstiger wird, sinken die Kosten pro Kern, oder die Preise für unterschiedliche Speicheroptionen ändern sich.
- Planen Sie für die Auslastungsspitzenzeiten an jedem Tag. Wir empfehlen, dass Sie Ihre Pläne basierend auf 30-Minuten- oder Stundenintervallen erstellen. Intervalle über einer Stunde können nutzlos werden, wenn Ihr Dienst tatsächlich seine Spitzenkapazität erreicht, und Intervalle unter 30 Minuten können ungenaue Informationen liefern, die vorübergehende Erhöhungen wichtiger erscheinen lassen, als sie wirklich sind.
- Planen Sie das Wachstum im Laufe des Hardwarelebenszyklus für das Unternehmen. Diese Planung kann Strategien für gestaffelte Upgrades oder das Hinzufügen von Hardware oder auch eine vollständige Aktualisierung alle drei bis fünf Jahre beinhalten. Jeder Wachstumsplan erfordert eine Schätzung, um wie viel die Auslastung von Active Directory zunehmen wird. Historische Daten können Ihnen dabei helfen, eine genauere Bewertung vorzunehmen.
- Planen Sie Fehlertoleranz ein. Nachdem Sie die Schätzung N abgeleitet haben, planen Sie Szenarien mit N-1, N-2 und N - x.
Fügen Sie basierend auf Ihrem Wachstumsplan zusätzliche Server gemäß den Anforderungen der Organisation hinzu, um sicherzustellen, dass der Ausfall eines oder mehrerer Server nicht dazu führt, dass das System die maximalen Höchstkapazitätsschätzungen überschreitet.
Denken Sie auch daran, dass Sie Ihre Wachstums- und Fehlertoleranzpläne integrieren müssen. Wenn Sie z. B. wissen, dass ihre Bereitstellung derzeit einen Domänencontroller (DC) benötigt, um die Last zu unterstützen, Ihre aber Schätzung besagt, dass die Last im nächsten Jahr verdoppelt wird und zwei DCs dafür erforderlich sein werden, verfügt Ihr System nicht über ausreichend Kapazität, um die Fehlertoleranz zu unterstützen. Um diese Kapazitätslücke zu verhindern, sollten Sie stattdessen mit drei DCs beginnen. Wenn Ihr Budget drei DCs nicht zulässt, können Sie auch mit zwei DCs beginnen und dann nach drei oder sechs Monaten einen dritten DC hinzufügen.
Hinweis
Das Hinzufügen von Anwendungen mit Active Directory-Unterstützung kann spürbare Auswirkungen auf die Domänencontroller-Last haben, unabhängig davon, ob die Last von den Anwendungsservern oder Clients ausgeht.
Der dreiteilige Kapazitätsplanungszyklus
Bevor Sie mit Ihrem Planungszyklus beginnen, müssen Sie entscheiden, welche Dienstqualität Ihre Organisation benötigt. Alle Empfehlungen und Anleitungen in diesem Artikel sind für optimale Leistungsumgebungen gedacht. Sie können sie jedoch selektiv zurückfahren, wenn Sie keine Optimierung benötigen. Wenn Ihre Organisation beispielsweise eine höhere Parallelität und eine konsistentere Benutzerumgebung benötigt, sollten Sie die Einrichtung eines Rechenzentrums erwägen. Rechenzentren ermöglichen Ihnen, besser auf Redundanzen zu achten und System- und Infrastrukturengpässe zu minimieren. Wenn Sie hingegen eine Bereitstellung für eine Zweigstelle mit nur wenigen Benutzern planen, müssen Sie sich nicht so viel Gedanken über Hardware- und Infrastrukturoptimierung machen, da Sie dann günstigere Optionen auswählen können.
Dann müssen Sie entscheiden, ob Sie mit virtuellen oder physischen Computern arbeiten wollen. Aus Kapazitätsplanungssicht gibt es dafür keine richtige oder falsche Antwort. Sie müssen jedoch beachten, dass jedes Szenario mit anderen Variablen verbunden ist, mit denen Sie arbeiten können.
Virtualisierungsszenarien bieten Ihnen zwei Optionen:
- Direkte Zuordnung, bei der nur ein Gast pro Host vorhanden ist.
- Szenarien mit gemeinsam genutztem Host mit mehreren Gästen pro Host.
Sie können Szenarien mit direkter Zuordnung so wie physische Hosts behandeln. Wenn Sie ein Szenario mit gemeinsam genutztem Host wählen, haben Sie es mit anderen Variablen zu tun, die Sie in späteren Abschnitten berücksichtigen sollten. Gemeinsam genutzte Hosts konkurrieren auch mit Active Directory Domain Services (AD DS) um Ressourcen, was sich auf die Systemleistung und das Benutzererlebnis auswirken kann.
Nachdem wir diese Fragen beantwortet haben, sehen wir uns den Kapazitätsplanungszyklus selbst an. Jeder Kapazitätsplanungszyklus besteht aus einem dreistufigen Prozess:
- Messen Sie die vorhandene Umgebung, ermitteln Sie, wo sich derzeit Systemengpässe befinden, und verschaffen Sie sich die grundlegenden Informationen über die Umgebung, die für die Planung der für die Bereitstellung erforderlichen Kapazität erforderlich sind.
- Ermitteln Sie anhand Ihrer Kapazitätsanforderungen, welche Hardware Sie benötigen.
- Überwachen und prüfen Sie, ob die von Ihnen eingerichtete Infrastruktur innerhalb der Spezifikationen arbeitet. Die Daten, die Sie bei diesem Schritt erfassen, werden zur Grundlage für den nächsten Zyklus der Kapazitätsplanung.
Anwenden des Prozesses
Um die Leistung zu optimieren, stellen Sie sicher, dass die folgenden zentralen Komponenten korrekt ausgewählt und auf die Anwendungslasten abgestimmt sind:
- Arbeitsspeicher
- Netzwerk
- Storage
- Prozessor
- Netlogon
Grundlegende Speicheranforderungen für AD DS und das allgemeine Verhalten kompatibler Clientsoftware ermöglichen es Umgebungen mit bis zu 10.000 bis 20.000 Benutzern, die Kapazitätsplanung für physische Hardware zu ignorieren, da die meisten modernen Systeme der Serverklasse bereits Lasten dieser Größe bewältigen können. Die zusammenfassenden Tabellen zur Datenerfassung erläutern jedoch, wie Sie Ihre vorhandene Umgebung prüfen müssen, um die korrekte Hardware auszuwählen. Die Abschnitte danach gehen ausführlicher auf grundlegende Empfehlungen und umgebungsspezifische Prinzipien für Hardware ein, um AD DS-Administratoren bei der Bewertung ihrer Infrastruktur zu unterstützen.
Weitere Informationen, die Sie bei der Planung berücksichtigen sollten:
- Jede Dimensionierung, die auf aktuellen Daten basiert, ist nur für die aktuelle Umgebung korrekt.
- Wenn Sie Schätzungen vornehmen, ist davon auszugehen, dass der Bedarf über den Lebenszyklus der Hardware hinweg zunehmen wird.
- Berücksichtigen Sie zukünftiges Wachstum, indem Sie bestimmen, ob Sie Ihre Umgebung heute über den aktuellen bedarf hinaus dimensionieren oder im Laufe des Lebenszyklus nach und nach Kapazität hinzufügen sollten.
- Alle Grundsätze und Methoden für die Kapazitätsplanung, die Sie auf eine physische Bereitstellung anwenden, gelten auch für eine virtualisierte Bereitstellung. Bei der Planung einer virtualisierten Umgebung müssen Sie jedoch daran denken, den Virtualisierungsaufwand in alle domänenbezogenen Planungen oder Schätzungen einzubeziehen.
- Die Kapazitätsplanung ist eine Prognose und kein perfekt korrekter Wert, erwarten Sie daher keine absolute Präzision. Denken Sie immer daran, die Kapazität nach Bedarf anzupassen und ständig zu überprüfen, ob Ihre Umgebung wie beabsichtigt funktioniert.
Übersichtstabellen zur Datensammlung
In den folgenden Tabellen werden Kriterien für die Ermittlung ihrer Hardwareschätzungen aufgeführt und erläutert.
Arbeitsumgebung
| Komponente | Schätzungen |
|---|---|
| Größe des Speichers/der Datenbank | 40 KB bis 60 KB für jeden Benutzer |
| RAM | Datenbankgröße Basisbetriebssystemempfehlungen Drittanbieteranwendungen |
| Netzwerk | 1 GB |
| CPU | 1.000 gleichzeitige Benutzer für jeden Kern |
Allgemeine Bewertungskriterien
| Komponente | Auswertungskriterien | Planungsaspekte |
|---|---|---|
| Größe des Speichers/der Datenbank | Offlinedefragmentierung | |
| Leistung des Speichers/der Datenbank |
|
|
| RAM |
|
|
| Network |
|
|
| CPU |
|
|
| Anmeldedienst |
|
|
Planung
Lange Zeit bestand die übliche Empfehlung für die AD DS-Dimensionierung darin, die RAM-Größe an der Datenbankgröße auszurichten. Jetzt wo AD DS-Umgebungen und das Ökosystem, das sie nutzt, viel größer geworden sind, sehen die Dinge anders aus. Obwohl höhere Rechenleistung und der Wechsel von der x86-Architektur zu x64 subtilere Aspekte der Dimensionierung für die Leistung für Kunden, die AD DS auf physischen Computern ausführen, unwichtiger gemacht hat, hat die Virtualisierung Optimierungen schwieriger gemacht.
Für den Umgang mit diesen Problemen beschreiben die folgenden Abschnitte, wie Sie die Anforderungen von Active Directory-as-a-Service ermitteln und planen können. Sie können diese Richtlinien auf jede Umgebung anwenden, unabhängig davon, ob sie physisch, virtualisiert oder gemischt ist. Um Ihre Leistung zu maximieren, sollte Ihr Ziel darin bestehen, Ihre AD DS-Umgebung so nah wie möglich an den Prozessor zu binden.
RAM
Je mehr Speicher Sie im RAM zwischenspeichern können, umso weniger wird der Datenträger belastet. Um die Skalierbarkeit des Servers zu maximieren, sollte die minimale Menge an RAM, die Sie verwenden, der Summe der aktuellen Datenbankgröße, der Gesamtgröße des Systemwerts, der empfohlenen Menge für Ihr Betriebssystem und den Empfehlungen des Herstellers für die Agenten (Antivirenprogramme, Überwachung, Sicherung usw.) entsprechen. Sie sollten auch zusätzlichen RAM vorsehen, um zukünftiges Wachstum über die Lebensdauer des Servers hinweg zu berücksichtigen. Diese Schätzung wird sich je nach dem Wachstum der Datenbank und Änderungen in der Umgebung ändern.
Für Umgebungen, in denen die Maximierung des RAM nicht kostengünstig oder nicht sinnvoll ist, z. B. an Zweigstellenstandorten oder bei einer zu großen Verzeichnisinformationsstruktur (DIT), fahren Sie mit Speicher fort, um sicherzustellen, dass Ihr Speicher ordnungsgemäß konfiguriert ist.
Ein weiterer wichtiger Punkt für die Dimensionierung des Arbeitsspeichers ist die Seitendatei-Dimensionierung. Bei der Dimensionierung des Datenträgers geht es, wie bei allem rund um den Arbeitsspeicher, darum, die Nutzung des Datenträgers zu minimieren. Fragen Sie sich insbesondere, wie viel RAM Sie benötigen, um die Paginierung zu minimieren? Die nächsten Abschnitte sollten Ihnen die Informationen geben, die Sie benötigen, um diese Frage zu beantworten. Weitere Überlegungen für die Seitengröße, die sich nicht unbedingt auf die AD DS-Leistung auswirken, sind Empfehlungen für das Betriebssystem (BS) und das Konfigurieren Ihres Systems für Speicherabbilder.
Die Ermittlung, wie viel RAM ein Domänencontroller (DC) benötigt, kann aufgrund vieler komplexer Faktoren recht schwierig sein:
- Bestehende Systeme sind nicht immer zuverlässige Indikatoren für RAM-Anforderungen, da der Local Security Authority Subsystem Service (LSSAS) den RAM unter Speicherdruckbedingungen verkleinert und damit die Anforderungen künstlich senkt.
- Einzelne DCs müssen nur Daten zwischenspeichern, die für ihre Clients interessant sind. Dies bedeutet, dass Daten, die in verschiedenen Umgebungen zwischengespeichert werden, sich ändern, je nachdem, welche Arten von Clients die jeweilige Umgebung enthält. Beispielsweise erfasst ein DC in einer Umgebung mit einem Exchange Server andere Daten als ein DC, der nur Benutzer authentifiziert.
- Der Aufwand, der erforderlich ist, um den RAM für jeden DC von Fall zu Fall zu ermitteln, ist oft zu hoch und ändert sich mit allen Änderungen der Umgebung.
Die Kriterien, die den Empfehlungen zugrunde liegen, können Ihnen helfen, fundiertere Entscheidungen zu treffen:
- Je mehr Sie im RAM zwischenspeichern, umso weniger wird der Datenträger belastet.
- Der Speicher ist die langsamste Komponente eines Computers. Der Datenzugriff auf Spindel- und SSD-Speichermedien ist um eine Million Mal langsamer als der Datenzugriff im RAM.
Virtualisierungsüberlegungen zum RAM
Ihr Ziel bei der Optimierung des Arbeitsspeichers besteht darin, die Zeit zu minimieren, die für Festplattenspeicherungen benötigt wird. Sie sollten auch übermäßiges Speicher-Commits auf dem Host vermeiden. In Virtualisierungsszenarien liegen übermäßige Speicher-Commits vor, wenn das System Gästen mehr RAM zuweist, als auf dem physischen Computer selbst vorhanden ist. Dies ist an sich kein Problem, aber wenn der gesamte von allen Gästen verwendete Arbeitsspeicher die RAM-Kapazität des Hosts überschreitet, ist Paging des Hosts die Folge. Dadurch wird die Leistung vom Datenträger abhängig, wenn der DC in die NTDS.nit- oder Seitendatei wechselt, um Daten abzurufen, oder der Host auf den Datenträger wechselt, um auf RAM-Daten zuzugreifen. Dadurch beeinträchtigt dieser Prozess die Leistung und das allgemeine Benutzererlebnis erheblich.
Beispiel für die Berechnungszusammenfassung
| Komponente | Geschätzter Arbeitsspeicher (Beispiel) |
|---|---|
| Empfohlener RAM des Basisbetriebssystems (Windows Server 2008) | 2 GB |
| Interne LSASS-Aufgaben | 200 MB |
| Überwachungs-Agent | 100 MB |
| Virenschutz | 100 MB |
| Datenbank (Globaler Katalog) | 8,5 GB |
| Polster für die Ausführung der Sicherung, Administrator*innen können sich ohne Auswirkungen anmelden | 1 GB |
| Gesamt | 12 GB |
Empfohlen: 16 GB
Im Laufe der Zeit werden der Datenbank weitere Daten hinzugefügt und die durchschnittliche Serverlebensdauer beträgt etwa drei bis fünf Jahre. Basierend auf einer Wachstumsschätzung von 333 % sind 16 GB eine angemessene RAM-Größe für einen physischen Server.
Network
In diesem Abschnitt wird beschrieben, wie viel Bandbreite und Netzwerkkapazität Ihre Bereitstellung benötigt, einschließlich Clientabfragen, Gruppenrichtlinieneinstellungen usw. Sie können Daten erfassen, um Ihre Schätzung mithilfe der Leistungsindikatoren Network Interface(*)\Bytes Received/sec und Network Interface(*)\Bytes Sent/sec vorzunehmen. Die Beispielintervalle für Netzwerkschnittstellenindikatoren sollten entweder 15, 30 oder 60 Minuten betragen. Alles darunter ist für gute Messungen zu volatil und alles darüber glättet die täglichen Spitzen übermäßig.
Hinweis
Im Allgemeinen ist der Großteil des Netzwerkdatenverkehrs auf einem Domänencontroller ausgehend, da der Domänencontroller auf Clientabfragen antwortet. Daher konzentriert sich dieser Abschnitt hauptsächlich auf ausgehenden Datenverkehr. Es wird jedoch auch empfohlen, jede Ihrer Umgebungen für eingehenden Datenverkehr zu evaluieren. Sie können die Richtlinien in diesem Artikel auch verwenden, um die Anforderungen für eingehenden Netzwerkdatenverkehr zu bewerten. Weitere Informationen finden Sie unter 929851: Der dynamische Standardportbereich für TCP/IP hat sich in Windows Vista und Windows Server 2008 geändert.
Bandbreitenbedarf
Die Planung der Netzwerkskalierbarkeit umfasst zwei verschiedene Kategorien: die Menge des Datenverkehrs und die CPU-Last des Netzwerkdatenverkehrs.
Es gibt zwei Dinge, die Sie bei der Kapazitätsplanung für die Datenverkehrsunterstützung berücksichtigen müssen. Zunächst müssen Sie wissen, wie viel Active Directory-Replikationsdatenverkehr zwischen Ihren DCs stattfindet. Zweitens müssen Sie ihren standortinternen Client-zu-Server-Datenverkehr evaluieren. Standortinterner Datenverkehr empfängt hauptsächlich kleinere Anforderungen von Clients relativ zu den großen Datenmengen, die an Clients zurückgesendet werden. 100 MB reichen in der Regel für Umgebungen mit bis zu 5.000 Benutzern pro Server aus. Für Umgebungen mit über 5.000 Benutzern empfehlen wir stattdessen die Verwendung eines 1-GB-Netzwerkadapters und der RSS (Receive Side Scaling)-Unterstützung.
Um die Kapazität des standortinternen Datenverkehrs zu evaluieren, insbesondere in Serverkonsolidierungsszenarien, sollten Sie sich den Network Interface(*)\Bytes/sec-Leistungsindikator auf allen DCs an einem Standort ansehen, die Werte addieren und dann die Summe durch die Zielanzahl der DCs dividieren. Eine einfache Möglichkeit zum Berechnen dieser Zahl besteht darin, den Windows Reliability and Performance Monitor zu öffnen und die Ansicht Stacked Area zu betrachten. Stellen Sie sicher, dass alle Leistungsindikatoren gleich skaliert sind.
Sehen wir uns ein Beispiel für eine komplexere Methode an, um zu überprüfen, ob diese allgemeine Regel für eine bestimmte Umgebung anwendbar ist. In diesem Beispiel gehen wir von den folgenden Annahmen aus:
- Ziel ist es, den Speicherbedarf auf so wenige Server wie möglich zu reduzieren. Im Idealfall trägt ein Server die Last, dann stellen Sie einen zusätzlichen Server für die Redundanz bereit (n + 1-Szenario).
- In diesem Szenario unterstützt der aktuelle Netzwerkadapter nur 100 MB und operiert in einer geschalteten Umgebung.
- Die maximale Ziel-Auslastung der Netzwerkbandbreite beträgt in einem n-Szenario 60 % (Verlust eines DC).
- Mit jedem Server sind etwa 10.000 Clients verbunden.
Sehen wir uns jetzt an, was das Diagramm im Network Interface(*)\Bytes Sent/sec-Indikator zu diesem Beispielszenario sagt:
- Der Geschäftstag beginnt gegen 05:30 Uhr und endet um 19:00 Uhr.
- Der Zeitraum mit der höchsten Auslastung ist von 8:00 Uhr bis 8:15 Uhr, wobei mehr als 25 Byte pro Sekunde auf dem am stärksten ausgelasteten DC gesendet werden.
Hinweis
Alle Leistungsdaten sind historisch, so dass der Spitzendatenpunkt um 8:15 Uhr die Last von 8:00 bis 8:15 Uhr angibt.
- Es gibt Spitzen vor 4:00 Uhr, bei denen mehr als 20 Byte pro Sekunde auf dem am stärksten ausgelasteten DC gesendet werden, was entweder auf eine Auslastung aus verschiedenen Zeitzonen oder auf Hintergrundinfrastrukturaktivitäten wie Sicherungsvorgänge hinweisen kann. Da der Spitzenwert um 8:00 Uhr diese Aktivität überschreitet, ist er nicht relevant.
- Es gibt fünf DCs an dem Standort.
- Die maximale Last beträgt ca. 5,5 Mbit/s pro DC, was 44 % der 100-MB-Verbindung entspricht. Anhand dieser Daten können wir schätzen, dass die gesamte benötigte Bandbreite zwischen 8:00 Uhr und 8:15 Uhr 28 Mbit/s beträgt.
Hinweis
Die Sende-/Empfangszähler der Netzwerkschnittstelle verwenden Byte, die Netzwerkbandbreite wird jedoch in Bit gemessen. Um die Gesamtbandbreite zu ermitteln, müssen Sie daher wie folgt rechnen: 100 MB ÷ 8 = 12,5 MB und 1 GB ÷ 8 = 128 MB.
Welche Schlussfolgerungen können wir jetzt aus diesen Daten ziehen?
- Die aktuelle Umgebung erfüllt die Fehlertoleranz von n +1 bei einer Zielauslastung von 60 %. Wenn ein System offline geschaltet wird, verschiebt sich die Bandbreite pro Server von etwa 5,5 Mbit/s (44 %) zu etwa 7 Mbit/s (56 %).
- Basierend auf dem zuvor erklärten Ziel der Konsolidierung auf einen Server überschreitet diese Änderung die maximale Zielauslastung und die mögliche Auslastung einer 100-MB-Verbindung.
- Bei einer 1-GB-Verbindung entspricht dieser Wert 22 % der Gesamtkapazität.
- Unter normalen Betriebsbedingungen im n + 1-Szenario ist die Clientlast mit etwa 14 Mbit/s pro Server oder 11 % der Gesamtkapazität relativ gleichmäßig verteilt.
- Um sicherzustellen, dass Sie über genügend Kapazität verfügen, während ein DC nicht verfügbar ist, liegen die normalen Betriebsziele pro Server bei etwa 30 % Netzwerkauslastung oder 38 Mbit/s pro Server. Die Failover-Ziele wären 60 % Netzwerkauslastung oder 72 Mbit/s pro Server.
Die endgültige Systembereitstellung muss über einen 1-GB-Netzwerkadapter und eine Verbindung mit einer Netzwerkinfrastruktur verfügen, die diese Last unterstützt. Aufgrund des Umfangs des Netzwerkdatenverkehrs kann die CPU-Last aus der Netzwerkkommunikation die maximale Skalierbarkeit von AD DS einschränken. Sie können diesen Prozess auch verwenden, um die eingehende Kommunikation mit dem DC zu schätzen. In den meisten Szenarien müssen Sie den eingehenden Datenverkehr jedoch nicht berechnen, da er kleiner als der ausgehende Datenverkehr ist.
Es ist wichtig, sicherzustellen, dass Ihre Hardware in Umgebungen mit mehr als 5.000 Benutzern pro Server RSS unterstützt. Bei Szenarien mit hohem Netzwerkdatenverkehr kann das Ausbalancieren der Interrupt-Last einen Engpass darstellen. Sie können potenzielle Engpässe erkennen, indem Sie den Processor(*)\% Interrupt Time-Indikator überprüfen, um festzustellen, ob die Interrupt-Zeit ungleichmäßig über CPUs verteilt ist. RSS-fähige Netzwerkschnittstellencontroller (Network Interface Controller, NICs) können diese Einschränkungen verringern und die Skalierbarkeit erhöhen.
Hinweis
Sie können ähnlich vorgehen, um zu schätzen, ob Sie mehr Kapazität benötigen, wenn Sie Rechenzentren konsolidieren oder einen DC an einem Zweigstellenstandort außer Betrieb nehmen. Um die erforderliche Kapazität zu schätzen, sehen Sie sich einfach die Daten für ausgehenden und eingehenden Datenverkehr an Clients an. Das Ergebnis ist die Menge des Datenverkehrs, der in den WAN-Verbindungen (Wide Area Network) erfolgt.
In einigen Fällen tritt möglicherweise mehr Datenverkehr als erwartet auf, da der Datenverkehr langsamer ist, z. B. wenn die Zertifikatüberprüfung keinen aggressiven Timeouts im WAN gerecht wird. Aus diesem Grund sollten die WAN-Größenanpassung und -nutzung ein iterativer, fortlaufender Prozess sein.
Überlegungen zur Virtualisierung für die Netzwerkbandbreite
Die typische Empfehlung für einen physischen Server liegt bei 1 GB für Server, die mehr als 5.000 Benutzer unterstützen. Sobald mehrere Gäste eine zugrunde liegende Virtual Switch-Infrastruktur gemeinsam nutzen, sollten Sie besonders darauf achten, ob der Host über ausreichende Netzwerkbandbreite verfügt, um alle Gäste im System zu unterstützen. Sie müssen die Bandbreite unabhängig davon berücksichtigen, ob das Netzwerk den DC umfasst, der als VM auf einem Host ausgeführt wird, wobei der Netzwerkverkehr über einen virtuellen Switch oder direkt mit einem physischen Switch verbunden ist. Virtuelle Switches sind Komponenten, bei denen der Uplink die Datenmenge unterstützen muss, die die Verbindung überträgt. Dies bedeutet, dass der mit dem Switch verbundene physische Host-Netzwerkadapter in der Lage sein muss, die DC-Last zu unterstützen, sowie alle anderen Gäste, die den virtuellen Switch gemeinsam mit dem physischen Netzwerkadapter nutzen.
Beispiel für eine Zusammenfassung der Netzwerkberechnung
Die folgende Tabelle enthält Werte aus einem Beispielszenario, mit dem wir die Netzwerkkapazität berechnen können:
| System | Spitzenbandbreite |
|---|---|
| DC 1 | 6,5 Mbit/s |
| DC 2 | 6,25 Mbit/s |
| DC 3 | 6,25 Mbit/s |
| DC 4 | 5,75 Mbit/s |
| DC 5 | 4,75 Mbit/s |
| Gesamt | 28,5 Mbit/s |
Basierend auf dieser Tabelle wäre die empfohlene Bandbreite 72 Mbit/s (28,5 Mbit/s ÷ 40 %).
| Anzahl der Zielsysteme | Gesamtbandbreite (von oben) |
|---|---|
| 2 | 28,5 Mbit/s |
| Resultierendes normales Verhalten | 28,5 ÷ 2 = 14,25 Mbit/s |
Wie immer sollten Sie davon ausgehen, dass die Clientauslastung im Laufe der Zeit zunehmen wird, daher sollten Sie dieses Wachstum so früh wie möglich einplanen. Wir empfehlen, mindestens 50 % geschätztes Netzwerkdatenverkehrswachstums einzuplanen.
Storage
Es gibt zwei Dinge, die Sie bei der Kapazitätsplanung für den Speicher berücksichtigen sollten:
- Kapazität oder Speichergröße
- Leistung
Obwohl Kapazität wichtig ist, ist es wichtig, die Leistung nicht zu vernachlässigen. Bei den derzeitigen Hardwarekosten sind die meisten Umgebungen nicht so groß, dass diese beiden Faktoren ein ernsthaftes Problem darstellen würden. Daher wird gewöhnlich empfohlen, nur so viel RAM zu verwenden, wie der Datenbankgröße entspricht. Für Zweigstellenstandorte in größeren Umgebungen könnte diese Empfehlung jedoch zu weit gehen.
Festlegen der Größe
Bewertung für Speicher
Verglichen mit der Einführung von Active Directory zu einer Zeit, als Laufwerke mit 4 GB und 9 GB die gängigsten Größen waren, wird die Dimensionierung für Active Directory heute nur für die größten Umgebungen in Betracht gezogen. Mit den kleinsten verfügbaren Festplattengrößen im Bereich von 180 GB können das gesamte Betriebssystem, SYSVOL und NTDS.dit problemlos auf ein Laufwerk passen. Daher empfehlen wir, nicht zu stark in diesen Bereich zu investieren.
Unsere einzige Empfehlung ist die, sicherzustellen, dass 110 % der NTS.dit-Größe verfügbar sind, damit Sie Ihren Speicher defragmentieren können. Darüber hinaus sollten Sie die üblichen Überlegungen für zukünftiges Wachstum berücksichtigen.
Wenn Sie Ihren Speicher evaluieren, müssen Sie zunächst ermitteln, wie groß NTDS.dit und SYSVOL sein müssen. Diese Messungen helfen Ihnen bei der Dimensionierung sowohl der Festplatten- als auch der RAM-Zuweisungen. Da die Komponenten relativ kostengünstig sind, müssen Sie bei der Berechnung nicht übermäßig präzise sein. Weitere Informationen zur Speicherevaluierung finden Sie unter Speichergrenzwerte und Wachstumsschätzungen für Active Directory-Benutzer und Organisationseinheiten.
Hinweis
Die im vorherigen Absatz verlinkten Artikel basieren auf Schätzungen der Datengröße, die während der Veröffentlichung von Active Directory in Windows 2000 vorgenommen wurden. Wenn Sie Ihre eigene Schätzung vornehmen, verwenden Sie Objektgrößen, die die tatsächliche Größe der Objekte in Ihrer Umgebung widerspiegeln.
Bei der Überprüfung vorhandener Umgebungen mit mehreren Domänen kann es sein, dass Sie Abweichungen bei der Datenbankgröße feststellen. Wenn Sie solche Abweichungen sehen, verwenden Sie den kleinsten globalen Katalog (GC) und Nicht-GC-Größen.
Datenbankgrößen können zwischen Betriebssystemversionen variieren. DCs, auf denen frühere Betriebssystemversionen wie Windows Server 2003 ausgeführt werden, weisen kleinere Datenbankgrößen auf als höhere Versionen wie Windows Server 2008 R2. Ein DC mit Features wie Active Directory-Papierkorb oder aktiviertem Credential Roaming kann sich auch auf die Datenbankgröße auswirken.
Hinweis
- Denken Sie bei neuen Umgebungen daran, dass 100.000 Benutzer in derselben Domäne etwa 450 MB Speicherplatz verbrauchen. Die Attribute, die Sie auffüllen, können sich auf die Gesamtmenge des verbrauchten Speicherplatzes auswirken. Attribute werden von vielen Objekten sowohl aus Drittanbieter- als auch aus Microsoft-Produkten aufgefüllt, einschließlich Microsoft Exchange Server und Lync. Daher empfehlen wir, die Evaluierung basierend auf dem Produktportfolio der Umgebung vorzunehmen. Sie sollten jedoch auch bedenken, dass die Berechnungen und Tests für genaue Schätzungen für alle außer den größten Umgebungen möglicherweise keinen erheblichen Zeit- oder Arbeitsaufwand rechtfertigen.
- Stellen Sie sicher, dass der verfügbare freie Speicherplatz 110 % der NTDS.dit-Größe beträgt, um die Offlinedefragmentierung zu ermöglichen. Mit diesem freien Speicherplatz können Sie auch das Wachstum über die drei bis fünfjährige Hardwarelebensdauer des Servers einplanen. Wenn Sie über den Speicher verfügen, ist das Zuordnen ausreichend freien Platz von bis zu 300 % des DIT für den Speicher eine sichere Möglichkeit, um Wachstum und Defragmentierung zu berücksichtigen.
Virtualisierungsüberlegungen zum Speicher
In Szenarien, in denen Sie einem einzelnen Volume mehrere VHD-Dateien (Virtual Hard Disk) zuordnen, sollten Sie einen festen Zustandsdatenträger mit mindestens 210 % der Größe des DIT (100 % des DIT + 110 % des freien Speicherplatzes) verwenden, um sicherzustellen, dass genügend Speicherplatz für Ihre Anforderungen reserviert ist.
Beispiel für eine Zusammenfassung der Speicherberechnung
In der folgenden Tabelle sind die Werte aufgeführt, die Sie verwenden sollten, um die Platzanforderungen für ein hypothetisches Speicherszenario zu schätzen.
| In der Auswertungsphase gesammelte Daten | Size |
|---|---|
| NTDS.dit-Größe | 35 GB |
| Modifizierer, um die Offlinedefragmentierung zuzulassen | 2,1 GB |
| Benötigter Gesamtspeicher | 73,5 GB |
Hinweis
Die Speicherschätzung sollte auch beinhalten, wie viel Speicherplatz Sie für SYSVOL, das Betriebssystem, die Seitendatei, temporäre Dateien, lokale zwischengespeicherte Daten wie Installationsdateien und Anwendungen benötigen.
Speicherleistung
Als langsamste Komponente auf jedem Computer kann der Speicher die größten negativen Auswirkungen auf die Clienterfahrung haben. In Umgebungen, die groß genug sind, dass die Empfehlungen zur RAM-Dimensionierung in diesem Artikel nicht durchführbar sind, kann eine fehlende Kapazitätsplanung für Speicher verheerende Folgen für die Systemleistung haben. Die Komplexitäten und Varianten der verfügbaren Speichertechnologien erhöhen das Risiko weiter, da die typische Empfehlung, das Betriebssystem, Protokolle und die Datenbank auf separaten physischen Datenträgern zu platzieren, nicht universell für alle Szenarien gilt.
Die früheren Empfehlungen für Datenträger gingen davon aus, dass ein Datenträger eine dedizierte Spindel war, die isolierte E/A-Vorgänge zuließ. Diese Annahme gilt aufgrund der Einführung der folgenden Speichertypen nicht mehr:
- RAID
- Neue Speichertypen und virtualisierte und freigegebene Speicherszenarien
- Freigegebene Spindeln in einem Storage Area Network (SAN)
- VHD-Datei in einem SAN-Speicher oder Network Attached Storage
- Solid-State-Laufwerke (SSDs)
- Tiered Storage-Architekturen, z. B. SSD-Storage-Tier-Caching, größerer spindelbasierter Speicher
Gemeinsam genutzter Speicher, z. B. RAID, SAN, NAS, JBOD, Storage Spaces und VHD, können von anderen Workloads überlastet werden, die Sie im Back-End-Speicher platzieren. Diese Speichertypen stellen auch eine zusätzliche Herausforderung dar: SAN-, Netzwerk- oder Treiberprobleme zwischen der physischen Festplatte und der AD-Anwendung können zu Drosselungen und Verzögerungen führen. Zur Klarstellung;: Dies sind keine schlechten Konfigurationen, aber sie sind komplexer, was bedeutet, dass Sie zusätzliche Aufmerksamkeit darauf verwenden müssen, dass jede Komponente wie beabsichtigt funktioniert. Ausführlichere Erläuterungen finden Sie in Anhang C und Anhang D weiter unten in diesem Artikel. Auch wenn SSDs nicht durch Festplatten beschränkt sind, die nur jeweils einen E/A-Vorgang verarbeiten können, verfügen sie dennoch über E/A-Einschränkungen, die zu Überlastungen führen können.
Zusammenfassend ist das Ziel aller Speicherleistungsplanungen, unabhängig von der Speicherarchitektur, sicherzustellen, dass die erforderliche Anzahl von E/As stets verfügbar ist und dass diese innerhalb eines akzeptablen Zeitrahmens erfolgen. Szenarien mit lokal angefügtem Speicher finden Sie in Anhang C für weitere Informationen zu Entwurf und Planung. Sie können die Prinzipien im Anhang auf komplexere Speicherszenarien sowie für Gespräche mit Anbietern anwenden, die Ihre Back-End-Speicherlösungen unterstützen.
Aufgrund der Anzahl der Speicheroptionen, die heute verfügbar sind, empfehlen wir Ihnen, Ihre Hardwaresupportteams oder -anbieter bei der Planung zu konsultieren, um sicherzustellen, dass die Lösung den Anforderungen Ihrer AD DS-Bereitstellung entspricht. Für diese Gespräche können Ihnen möglicherweise die folgenden Leistungsindikatoren nützlich sein, insbesondere, wenn Ihre Datenbank für Ihren RAM zu groß ist:
LogicalDisk(*)\Avg Disk sec/Read(wenn NTDS.dit z. B. auf Laufwerk D gespeichert ist, lautet der vollständige PfadLogicalDisk(D:)\Avg Disk sec/Read)LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Wenn Sie die Daten angeben, sollten Sie sicherstellen, dass in Intervallen von 15, 30 oder 60 Minuten Stichproben genommen werden, um ein möglichst präzises Bild Ihrer aktuellen Umgebung zu erhalten.
Auswerten der Ergebnisse
Dieser Abschnitt konzentriert sich auf Lesevorgänge aus der Datenbank, da die Datenbank in der Regel die anspruchsvollste Komponente ist. Sie können dieselbe Logik auf Schreibvorgänge in die Protokolldatei anwenden, indem Sie sie <NTDS Log>)\Avg Disk sec/Write und LogicalDisk(<NTDS Log>)\Writes/sec) ersetzen.
Der LogicalDisk(<NTDS>)\Avg Disk sec/Read-Leistungsindikator zeigt an, ob der aktuelle Speicher angemessen dimensioniert ist. Wenn der Wert ungefähr der erwarteten Datenträgerzugriffszeit für den Datenträgertyp entspricht, ist der LogicalDisk(<NTDS>)\Reads/sec-Leistungsindikator ein brauchbares Maß. Wenn die Ergebnisse ungefähr der Datenträgerzugriffszeit für den Datenträgertyp entsprechen, ist der LogicalDisk(<NTDS>)\Reads/sec-Leistungsindikator ein brauchbares Maß. Dies kann sich zwar ändern, je nachdem, welche Herstellerspezifikationen Ihr Back-End-Speicher hat, aber gute Bereiche für LogicalDisk(<NTDS>)\Avg Disk sec/Read sind etwa:
- 7200 U/min: 9 bis 12,5 Millisekunden (ms)
- 10.000 U/min: 6 bis 10 ms
- 15.000 U/min: 4 bis 6 ms
- SSD – 1 bis 3 ms
Möglicherweise hören Sie von anderen, dass die Speicherleistung bei 15 ms bis 20 ms beeinträchtigt wird. Der Unterschied zwischen diesen Werten und den Werten in der obigen Liste besteht darin, dass die Listenwerte den normalen Betriebsbereich anzeigen. Die anderen Werte gelten für Problembehandlungszwecke und helfen Ihnen, zu ermitteln, wann die Benutzeroberfläche des Clients so stark beeinträchtigt wird, dass dies spürbar ist. Weitere Informationen finden Sie im Anhang C.
LogicalDisk(<NTDS>)\Reads/secist die Anzahl der E/A-Vorgänge, die das System zurzeit ausführt.- Wenn
LogicalDisk(<NTDS>)\Avg Disk sec/Readinnerhalb des optimalen Bereichs für den Back-End-Speicher liegt, können SieLogicalDisk(<NTDS>)\Reads/secdirekt nutzen, um den Speicher zu dimensionieren. - Wenn
LogicalDisk(<NTDS>)\Avg Disk sec/Readnicht innerhalb des optimalen Bereichs für den Back-End-Speicher liegt, wird zusätzliche E/A gemäß der folgenden Formel benötigt:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Physische Mediendatenträgerzugriffszeit ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Wenn
Wenn Sie diese Berechnungen vornehmen, sollten Sie Folgendes berücksichtigen:
- Wenn der Server über einen suboptimalen RAM-Wert verfügt, sind die resultierenden Werte zu hoch und nicht genau genug, um für die Planung nützlich zu sein. Sie können sie jedoch verwenden, um Worst-Case-Szenarien vorherzusagen.
- Wenn Sie RAM hinzufügen oder optimieren, verringern Sie auch den Lese-E/A-Wert
LogicalDisk(<NTDS>)\Reads/Sec. Diese Verringerung kann dazu führen, dass die Speicherlösung nicht so robust ist wie die ursprünglichen Berechnungen vermuten ließen. Leider können wir nicht mehr Einzelheiten dazu geben, was dies bedeutet, da Berechnungen je nach einzelnen Umgebungen, insbesondere der Clientlast, stark variieren. Wir empfehlen jedoch, die Dimensionierung anzupassen, nachdem Sie den RAM optimiert haben.
Virtualisierungsüberlegungen zur Leistung
Ähnlich wie in den vorherigen Abschnitten soll hier sichergestellt werden, dass die gemeinsame Infrastruktur die Gesamtlast aller Verbraucher unterstützen kann. Sie müssen dieses Ziel bei der Planung für die folgenden Szenarien berücksichtigen:
- Eine physische CD, die dieselben Medien auf einer SAN-, NAS- oder iSCSI-Infrastruktur wie andere Server oder Anwendungen gemeinsam verwendet.
- Ein Benutzer, der Passthrough-Zugriff auf eine SAN-, NAS- oder iSCSI-Infrastruktur verwendet, die die Medien freigibt.
- Ein Benutzer, der eine VHD-Datei lokal oder eine SAN-, NAS- oder iSCSI-Infrastruktur verwendet.
Aus der Sicht eines Gastbenutzers wirkt sich die Notwendigkeit, einen Host zu durchlaufen, um auf den Speicher zuzugreifen, auf die Leistung aus, da der Benutzer zusätzliche Codepfade durchlaufen muss, um Zugriff zu erhalten. Leistungstests deuten darauf hin, dass sich die Virtualisierung auf den Durchsatz auswirkt, basierend auf dem Umfang des Prozessors, den das Hostsystem verwendet. Die Prozessorauslastung wird auch davon beeinflusst, wie viele Ressourcen der Gastbenutzer vom Host benötigt. Diese Anforderung trägt zu den Überlegungen zur Virtualisierung für die Verarbeitung bei, die Sie für Verarbeitungsanforderungen in virtualisierten Szenarien berücksichtigen sollten. Weitere Informationen finden Sie im Anhang A.
Die Dinge werden dadurch noch weiter verkompliziert, wie viele Speicheroptionen derzeit verfügbar sind, wobei sich jede davon mit stark unterschiedlichen Leistungseinbußen auswirkt. Zu diesen Optionen gehören Passthrough-Speicher, SCSI-Adapter und IDE. Bei der Migration von einer physischen zu einer virtuellen Umgebung sollten Sie verschiedene Speicheroptionen für virtualisierte Gastbenutzer mithilfe des Multiplikationsfaktors 1,1 berücksichtigen. Sie müssen jedoch keine Anpassungen bei der Übertragung zwischen verschiedenen Speicherszenarien berücksichtigen, da es sich bei dem Speicher um lokalen Speicher, SAN, NAS oder iSCSI handelt.
Beispiel für die Virtualisierungsberechnung
Bestimmen der E/A-Menge, die für ein fehlerfreies System unter normalen Betriebsbedingungen erforderlich ist:
- LogicalDisk (
<NTDS Database Drive>) ÷ Übertragungen pro Sekunde während der Spitzenzeit von 15 Minuten - So ermitteln Sie den E/A-Bedarf für den Speicher, wenn die Kapazität des zugrunde liegenden Speichers überschritten wird:
Erforderliche IOPS = (LogicalDisk(
<NTDS Database Drive>)) ÷ Durchschn. Datenträgerlesevorgänge/Sek. ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Lesevorgänge/Sek.
| Leistungsindikator | Wert |
|---|---|
Tatsächliche LogicalDisk(<NTDS Database Drive>)\Durchschn. Disk Sek/Transfer |
0,02 Sekunden (20 Millisekunden) |
Ziel-LogicalDisk(<NTDS Database Drive>)\Durchschn. Disk Sek./Transfer |
0,01 Sekunden |
| Multiplikator für die Änderung der verfügbaren E/A-Vorgänge | 0,02 ÷ 0,01 = 2 |
| Wertname | Wert |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfers/Sek. |
400 |
| Multiplikator für die Änderung der verfügbaren E/A-Vorgänge | 2 |
| Gesamter IOPS-Bedarf während der Spitzenzeit | 800 |
So bestimmen Sie die Rate, mit der Sie den Cache anwärmen sollten:
- Bestimmen Sie die maximale Zeit, die Sie für die Cacheanwärmung akzeptabel finden. In typischen Szenarien wäre eine akzeptable Zeitdauer so lange, wie es dauern sollte, die gesamte Datenbank von einem Datenträger zu laden. Verwenden Sie in Szenarien, in denen der RAM nicht die gesamte Datenbank laden kann, die für die Füllung des gesamten RAMs benötigte Zeit.
- Bestimmen Sie die Größe der Datenbank, mit Ausnahme von Platz, den Sie nicht verwenden möchten. Weitere Informationen finden Sie unter Auswerten des Speichers.
- Dividieren Sie die Datenbankgröße durch 8 KB, um die Gesamtanzahl von E/A-Vorgängen abzurufen, die Sie zum Laden der Datenbank benötigen.
- Dividieren Sie die Gesamtzahl der E/A-Vorgänge durch die Anzahl der Sekunden im definierten Zeitraum.
Die Zahl, die Sie erhalten, ist ziemlich korrekt, aber möglicherweise nicht absolut exakt, da Sie ESE (Extensible Storage Engine) nicht so konfiguriert haben, dass eine feste Cachegröße vorhanden ist; dann entfernt AD DS zuvor geladene Seiten, da standardmäßig eine variable Cachegröße verwendet wird.
| Zu erfassende Datenpunkte | Werte |
|---|---|
| Maximal zulässige Aufwärmzeit | 10 Minuten (600 Sekunden) |
| Datenbankgröße | 2 GB |
| Berechnungsschritt | Formel | Ergebnis |
|---|---|---|
| Berechnung der Größe der Datenbank in Seiten | (2 GB × 1024 × 1024) = Größe der Datenbank in KB | 2.097.152 KB |
| Berechnung der Anzahl der Seiten in der Datenbank | 2.097.152 KB ÷ 8 KB = Anzahl der Seiten | 262.144 Seiten |
| Berechnung von IOPS, die zum vollständigen Aufwärmen des Caches erforderlich sind | 262.144 Seiten ÷ 600 Sekunden = erforderliche IOPS | 437 IOPS |
Verarbeitung
Auswerten der Active Directory-Prozessornutzung
Für die meisten Umgebungen ist die Verwaltung der Verarbeitungskapazität die Komponente, die die größte Aufmerksamkeit verdient. Wenn Sie evaluieren, wie viel CPU-Kapazität Ihre Bereitstellung benötigt, sollten Sie die folgenden beiden Punkte berücksichtigen:
- Verhalten sich die Anwendungen in Ihrer Umgebung gemäß den Kriterien, die in Nachverfolgung von teuren und ineffizienten Suchvorgängen beschrieben sind, wie sie in einer Infrastruktur für gemeinsam genutzte Dienste vorgesehen sind? In größeren Umgebungen können schlecht codierte Anwendungen dazu führen, dass die CPU-Auslastung schwankt, eine unangemessen lange CPU-Zeit auf Kosten anderer Anwendungen benötigt wird, sich die Kapazitätsanforderungen erhöhen und die Auslastung ungleich über die DCs verteilt wird.
- AD DS ist eine verteilte Umgebung mit vielen potenziellen Clients, deren Verarbeitungsanforderungen stark variieren. Die geschätzten Kosten für jeden Client können aufgrund von Nutzungsmustern und der Anzahl der Anwendungen, die AD DS verwenden, variieren. Ähnlich wie unter Netzwerk sollten Sie sich zur Evaluierung der insgesamt benötigten Kapazität in der Umgebung nähern, anstatt jeden Client einzeln zu betrachten.
Sie sollten diese Schätzung erst vornehmen, nachdem Sie Ihre Speicherschätzung abgeschlossen haben, da Sie keine genaue Schätzung ohne gültige Daten zur Prozessorlast vornehmen können. Weiterhin ist es wichtig, sicherzustellen, dass der Speicher keine Engpässe verursacht, bevor die Problemlösung zum Prozessor vorgenommen wird. Wenn Sie Wartestatus des Prozessors entfernen, erhöht sich die CPU-Auslastung, da nicht mehr auf die Daten gewartet werden muss. Daher sollten die Leistungsindikatoren, auf die Sie am meisten achten, Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read und Process(lsass)\ Processor Time sein. Wenn der Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read-Leistungsindikator über 10 oder 15 Millisekunden zeigt, sind die Daten Process(lsass)\ Processor Time künstlich niedrig, und das Problem liegt an der Speicherleistung. Wir empfehlen, für möglichst präzise Daten die Stichprobenintervalle auf 15, 30 oder 60 Minuten festzulegen.
Übersicht über die Verarbeitung
Bei der Kapazitätsplanung für Domänencontroller erfordert die Verarbeitungsleistung die meiste Aufmerksamkeit und das meiste Verständnis. Bei der Dimensionierung von Systemen für maximale Leistung gibt es immer eine Komponente, die der Engpass ist. In einem Domänencontroller mit der korrekten Größe ist diese Komponente der Prozessor.
Ähnlich wie im Netzwerkabschnitt, in dem der Bedarf der Umgebung Standort für Standort überprüft wird, muss dies auch für die erforderliche Computekapazität erfolgen. Im Gegensatz zum Netzwerkabschnitt, in dem die verfügbaren Netzwerktechnologien den normalen Bedarf bei weitem übersteigen, sollten Sie mehr auf die Dimensionierung der CPU-Kapazität achten. Wie in jeder Umgebung von auch nur mäßiger Größe kann alles, was über ein paar Tausend gleichzeitige Benutzer hinausgeht, eine erhebliche Belastung für die CPU darstellen.
Aufgrund der enormen Variabilität von Clientanwendungen, die AD nutzen, ist eine allgemeine Schätzung der Benutzer pro CPU für alle Umgebungen leider nicht anwendbar. Insbesondere die Computeanforderungen unterliegen dem Benutzerverhalten und Anwendungsprofil. Daher muss jede Umgebung individuell dimensioniert werden.
Verhaltensprofil des Zielstandorts
Wenn Sie die Kapazitätsplanung für einen gesamten Standort planen, sollte Ihr Ziel ein N + 1-Kapazitätsdesign sein. Dabei kann der Dienst auch dann, wenn ein System während des Spitzenzeitraums ausfällt, weiterhin auf akzeptablem Qualitätsniveau fortgesetzt werden. In einem N-Szenario sollte die Last in allen Feldern während der Spitzenzeiten weniger als 80–100 % betragen.
Außerdem verwenden die Anwendungen und Clients des Standorts die empfohlene DsGetDcName-Funktionsmethode zum Auffinden von DCs; diese sollten bereits gleichmäßig mit nur kleinen vorübergehenden Spitzen verteilt sein.
Sehen wir uns jetzt zwei Beispiele für Umgebungen an, die im und außerhalb des Zielbereichs liegen. Zunächst sehen wir uns ein Beispiel für eine Umgebung an, die wie beabsichtigt funktioniert und das Kapazitätsplanungsziel nicht überschreitet.
Für das erste Beispiel gehen wir von den folgenden Annahmen aus:
- Jeder der fünf DCs des Standorts verfügt über vier CPUs.
- Die CPU-Zielauslastung während der Geschäftszeiten beträgt unter normalen Betriebsbedingungen 40 % (N + 1) und andernfalls 60 % (N). Außerhalb der Geschäftszeiten beträgt die CPU-Auslastung 80 %, da wir davon ausgehen, dass die Backup-Software und andere Wartungsprozesse alle verfügbaren Ressourcen verbrauchen.
Sehen wir uns jetzt das (Processor Information(_Total)\% Processor Utility)-Diagramm für jeden der DCs an, wie in der folgenden Abbildung dargestellt.
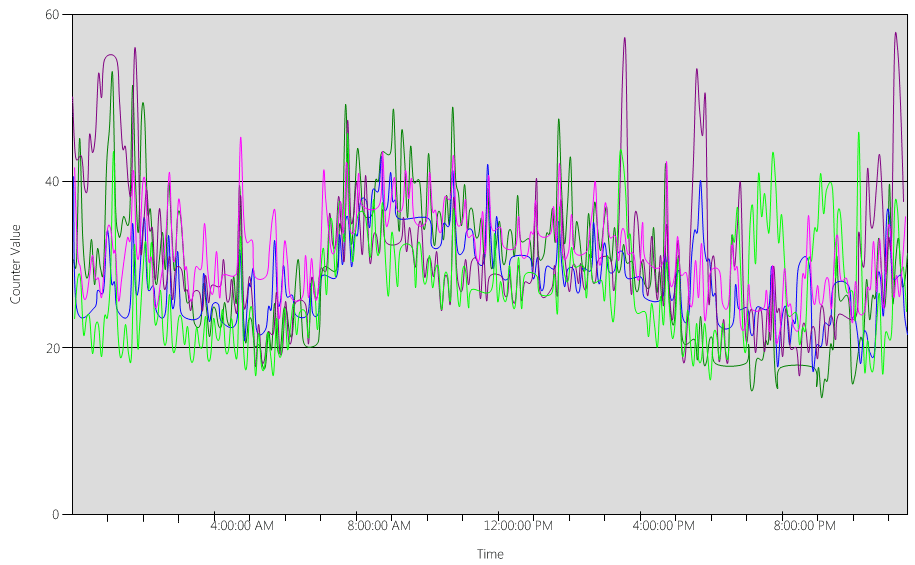
Die Last ist relativ gleichmäßig verteilt, was wir erwarten, wenn Clients den DC-Locator und gut geschriebene Suchen verwenden.
In mehreren fünfminütigen Intervallen gibt es Spitzen bei 10 %, manchmal sogar bei 20 %. Wenn diese Spitzen jedoch nicht dazu führen, dass die CPU-Auslastung das Kapazitätsplanziel überschreitet, müssen Sie sie nicht untersuchen.
Die Spitzenzeit für alle Systeme liegt zwischen 8:00 Uhr und 9:15 Uhr. Der durchschnittliche Arbeitstag dauert von 5:00 bis 17:00 Uhr. Daher liegen alle zufälligen Spitzen der CPU-Auslastung, die zwischen 17:00 und 4:00 Uhr stattfinden, außerhalb der Geschäftszeiten und Sie müssen sie nicht in Ihre Kapazitätsplanungsüberlegungen einbeziehen.
Hinweis
Auf einem gut verwalteten System werden Spitzen, die außerhalb der Spitzenzeiten auftreten, in der Regel durch Backup-Software, vollständige Antiviren-Scans des Systems, Hardware- oder Softwareinventuren, Software- oder Patch-Bereitstellungen u. dgl. verursacht. Da diese Spitzen außerhalb der Geschäftszeiten auftreten, zählen sie nicht zur Überschreitung der Kapazitätsplanungsziele.
Da jedes System bei etwa 40 % liegt und alle über die gleiche Anzahl von CPUs verfügen, gilt: Wenn eines davon ausfällt ist, werden die verbleibenden Systeme mit einem geschätzten Wert von 53 % ausgeführt. System D hat eine Last von 40 %, die gleichmäßig geteilt und der vorhandenen 40-%-Last von System A und C hinzugefügt wird. Diese lineare Annahme ist nicht vollkommen korrekt, ist aber hinreichend genau, um eine Messung vorzunehmen.
Sehen wir und jetzt ein Beispiel für eine Umgebung an, die nicht über eine gute CPU-Auslastung verfügt und das Kapazitätsplanungsziel überschreitet.
In diesem Beispiel werden zwei DCs mit 40 % ausgeführt. Ein Domänencontroller ist offline, was dazu führt, dass die geschätzte CPU-Auslastung auf dem verbleibenden DC 80 % erreicht. Diese CPU-Auslastung überschreitet den Schwellenwert für den Kapazitätsplan deutlich und beginnt, den verfügbaren Platz für die 10 % bis 20 % des Lastprofils zu begrenzen. Daher könnte jede Spitze den DC-Wert während des N-Szenarios auf 90 % oder sogar 100 % bringen und die Reaktionsfähigkeit beeinträchtigen.
Berechnen von CPU-Anforderungen
Der Process\% Processor Time-Leistungsindikator verfolgt die Gesamtzeit, die alle Anwendungsthreads auf der CPU verbringen, und dividiert diese Summe dann durch die Gesamtzeit des Systems. Eine Multithread-Anwendung auf einem Multi-CPU-System kann 100 % CPU-Zeit überschreiten und diese Daten würden ganz anders interpretiert als die des Processor Information\% Processor Utility-Leistungsindikators. In der Praxis verfolgt der Process(lsass)\% Processor Time-Leistungsindikator, wie viele laufende CPUs bei 100 % das Systems benötigt, um die Anforderungen eines Prozesses zu unterstützen. Wenn der Leistungsindikator beispielsweise einen Wert von 200 % zeigt, benötigt das System zwei CPUs, die zu 100 % ausgelastet werden, um die vollständige AD DS-Last zu unterstützen. Obwohl eine CPU mit einer Kapazität von 100 % die kostengünstigste Lösung in Bezug auf Strom- und Energieverbrauch ist, ist ein Multithread-System aus Gründen, die in Anhang A erläutert werden, reaktionsfähiger, wenn das System nicht mit 100 % ausgeführt wird.
Um vorübergehende Spitzen in der Clientauslastung zu bewältigen, wird empfohlen, eine CPU-Spitze zwischen 40 % und 60 % der Systemkapazität anzustreben. Beispielsweise benötigen Sie im ersten Beispiel im Verhaltensprofil des Zielstandorts zwischen 3,33 CPUs (60 % Ziel) und 5 CPUs (40 % Ziel) zur Unterstützung der AD DS-Last. Sie sollten zusätzliche Kapazität entsprechend den Anforderungen des Betriebssystems und aller anderen erforderlichen Agenten hinzufügen, z. B. Virenschutz, Sicherung, Überwachung usw. Obwohl Sie die Auswirkungen von Agenten auf CPU-Agenten für jede Umgebung bewerten sollten, können Sie in der Regel zwischen 5 % und 10 % für Agentenprozesse auf einer einzelnen CPU zuweisen. Nochmal zu unserem Beispiel: Wir benötigen zwischen 3,43 (60 % Ziel) und 5,1 (40 % Ziel) CPUs, um die Last während der Spitzenzeiten zu unterstützen.
Sehen wir uns jetzt ein Beispiel für die Berechnung zu einem bestimmten Prozess an. In diesem Fall betrachten wir den LSASS-Prozess.
Berechnen der CPU-Auslastung für den LSASS-Prozess
In diesem Beispiel entspricht das System einem N +1-Szenario, bei dem ein Server die AD DS-Last trägt, während ein zusätzlicher Server für Redundanz vorhanden ist.
Das folgende Diagramm zeigt die Prozessorzeit für den LSASS-Prozess für alle Prozessoren in diesem Beispielszenario. Diese Daten wurden aus dem Process(lsass)\% Processor Time-Leistungsindikator erfasst.
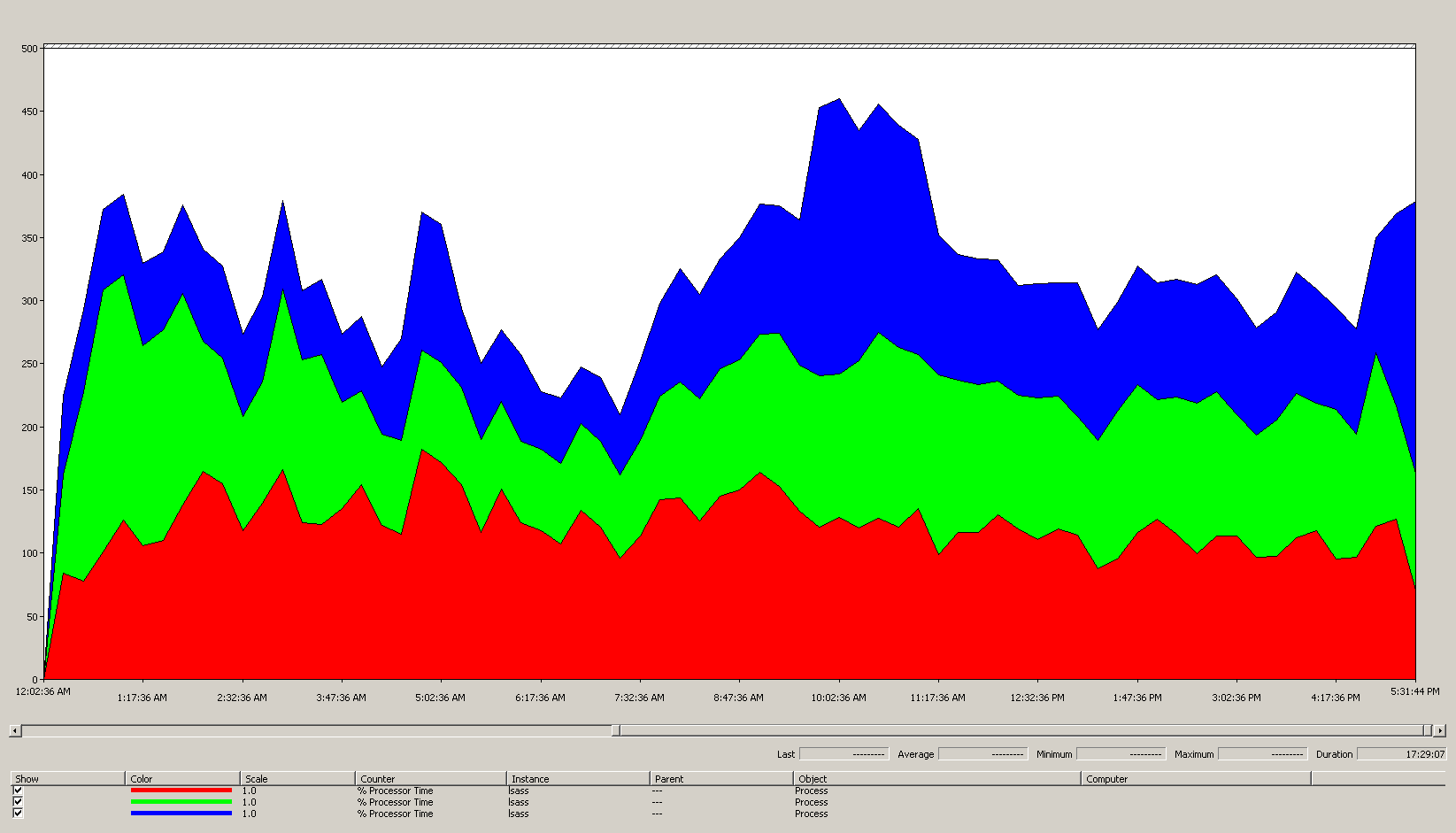
Dieses Diagramm bietet die folgenden Informationen zu der Szenarioumgebung:
- Es gibt drei Domänencontroller an diesem Standort.
- Der Geschäftstag beginnt gegen 7:00 Uhr und dauert bis 17:00 Uhr.
- Die verkehrsreichste Zeit des Tages ist von 09:30 bis 11:00 Uhr.
Hinweis
Alle Leistungsdaten sind Verlaufsdaten. Der Spitzendatenpunkt um 09:15 Uhr gibt die Auslastung von 09:00 Uhr bis 09:15 Uhr an.
- Spitzen vor 7:00 Uhr können auf zusätzliche Auslastung durch unterschiedliche Zeitzonen oder Hintergrundaktivitäten der Infrastruktur, wie z. B. Sicherungsvorgänge, hinweisen. Da diese Spitze jedoch niedriger als die Spitzenaktivität um 9:30 Uhr ist, ist dies kein Grund zur Sorge.
Bei maximaler Last verbraucht der LSASS-Prozess etwa 4,85 CPUs mit 100 %, was 485 % bei einer einzigen CPU entspräche. Diese Ergebnisse zeigen, dass der Standort in diesem Szenario ca. 12/25 CPUs benötigt, um AD DS auszuführen. Wenn Sie die empfohlene Kapazität von 5 % auf 10 % zusätzliche Kapazität für Hintergrundprozesse bringen, benötigt der Server 12,3 bis 12,25 CPUs, um seine aktuelle Last zu unterstützen. Schätzungen, die zukünftiges Wachstum berücksichtigen, erhöhen diesen Wert noch weiter.
Wann eine Optimierung der LDAP-Gewichtung erforderlich ist
Es gibt bestimmte Szenarien, in denen Sie die Optimierung von LdapSrvWeight in Betracht ziehen sollten. Im Kontext der Kapazitätsplanung optimieren Sie dies, wenn Ihre Anwendungen, Benutzerlasten oder zugrunde liegenden Systemfunktionen nicht gleichmäßig verteilt sind.
In den folgenden Abschnitten werden zwei Beispielszenarien beschrieben, in denen Sie die Gewichtungen des Lightweight Directory Access Protocol (LDAP) optimieren sollten.
Beispiel 1: PDC-Emulator-Umgebung
Wenn Sie einen PDC (Primary Domain Controller)-Emulator verwenden, können sich ungleich verteilte Benutzer- oder Anwendungsverhaltensweisen auf mehrere Umgebungen gleichzeitig auswirken. CPU-Ressourcen auf dem PDC-Emulator werden häufig stärker beansprucht als an anderen Stellen in der Bereitstellung, da sie von mehreren Tools und Aktionen verwendet werden, z. B. von Gruppenrichtlinienverwaltungstools, zweiten Authentifizierungsversuchen, der Einrichtung von Vertrauensstellungen usw.
- Sie sollten Ihren PDC-Emulator nur optimieren, wenn ein spürbarer Unterschied bei der CPU-Auslastung besteht. Die Optimierung sollte die Auslastung des PDC-Emulators verringern und die Last auf anderen DCs erhöhen, was eine noch gleichmäßigere Lastverteilung ermöglicht.
- Legen Sie in diesen Fällen den Wert für
LDAPSrvWeightzwischen 50 und 75 für den PDC-Emulator fest.
| System | CPU-Auslastung mit Standardwerten | Neues LdapSrvWeight | Geschätzte neue CPU-Auslastung |
|---|---|---|---|
| DC1 (PDC-Emulator) | 53 % | 57 | 40% |
| DC 2 | 33 % | 100 | 40% |
| DC 3 | 33 % | 100 | 40% |
Der Haken an der Sache ist, dass, wenn die PDC-Emulatorrolle übertragen oder übernommen wird, insbesondere für einen anderen Domänencontroller am Standort, die CPU-Auslastung auf dem neuen PDC-Emulator drastisch ansteigt.
In diesem Beispielszenario wird auf der Grundlage des Verhaltensprofils des Zielstandorts davon ausgegangen, dass alle drei Domänencontroller an diesem Standort vier CPUs haben. Was würde unter normalen Bedingungen geschehen, wenn einer dieser DCs acht CPUs hatte? Es gäbe dann zwei DCs mit einer Auslastung von 40 % und einen mit einer Auslastung von 20 %. Obwohl diese Konfiguration nicht notwendigerweise schlecht ist, gibt es hier die Möglichkeit, die LDAP-Gewichtsoptimierung zu verwenden, um die Last besser auszugleichen.
Beispiel 2: Umgebung mit unterschiedlichen CPU-Anzahlen
Wenn Sie über Server mit unterschiedlichen CPU-Anzahlen und Geschwindigkeiten am gleichen Standort verfügen, müssen Sie sicherstellen, dass diese gleichmäßig verteilt sind. Wenn Ihr Standort beispielsweise über zwei Acht-Core-Server und einen Vier-Core-Server verfügt, verfügt der Vier-Core-Server nur über die Hälfte der Verarbeitungsleistung der beiden anderen Server. Wenn die Clientlast gleichmäßig verteilt ist, bedeutet dies, dass der Vier-Core-Server doppelt so intensiv arbeiten muss wie die zwei Acht-Core-Server, um die CPU-Auslastung zu bewältigen. Darüber hinaus wird der Vier-Core-Server überlastet, wenn einer der Acht-Core-Server ausfällt.
| System | Prozessorinformationen\ % Prozessor-Hilfsprogramm(_Gesamt) CPU-Auslastung mit Standardwerten |
Neues LdapSrvWeight | Geschätzte neue CPU-Auslastung |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30 % |
| 4-CPU DC 2 | 40 | 100 | 30 % |
| 8-CPU DC 3 | 20 | 200 | 30 % |
Die Planung für ein „N +1“-Szenario ist von größter Bedeutung. Die Auswirkungen eines offline geschalteten Domänencontrollers müssen für jedes Szenario berechnet werden. Im unmittelbar vorhergehenden Szenario, bei dem die Lastverteilung gleichmäßig ist, ist die Verteilung in Ordnung, da die Verhältnisse konsistent bleiben, um eine Auslastung von 60 % während eines „N“-Szenarios sicherzustellen und die Last gleichmäßig auf alle Server zu verteilen. Beim PDC-Emulator-Optimierungsszenario oder einem allgemeinen Szenario, bei dem die Benutzer- oder Anwendungslast nicht ausgeglichen ist, ist der Effekt sehr unterschiedlich:
| System | Optimierte Auslastung | Neues LdapSrvWeight | Geschätzte neue Auslastung |
|---|---|---|---|
| DC1 (PDC-Emulator) | 40% | 85 | 47 % |
| DC 2 | 40% | 100 | 53 % |
| DC 3 | 40% | 100 | 53 % |
Überlegungen zur Virtualisierung für die Verarbeitung
Wenn Sie die Kapazitätsplanung für eine virtualisierte Umgebung planen, müssen Sie zwei Ebenen berücksichtigen: die Host-Ebene und die Gast-Ebene. Auf Host-Ebene müssen Sie die Spitzenzeiten Ihres Geschäftszyklus identifizieren. Da das Planen von Gast-Threads auf der CPU für einen virtuellen Computer mit dem Abrufen von AD DS-Threads auf der CPU für einen physischen Computer vergleichbar ist, empfehlen wir weiterhin, 40 % bis 60 % des zugrunde liegenden Hosts zu verwenden. Da die zugrunde liegenden Threadplanungsprinzipien unverändert sind, empfehlen wir auch für die Gast-Ebene, die CPU-Auslastung im Bereich von 40 % bis 60 % beizubehalten.
In einem direkt zugeordneten Szenario mit einem Gast pro Host müssen Sie alle Kapazitätsplanungsschätzungen einbeziehen, die Sie in den vorherigen Abschnitten vorgenommen haben, um Ihre Schätzung vorzunehmen. Bei einem Szenario mit gemeinsam genutztem Host gibt es ca. 10 % Auswirkungen auf die Effizienz der zugrunde liegenden Prozessoren, was bedeutet, dass ein Standort 10 CPUs für ein Ziel von 40 % benötigt, und die empfohlene Anzahl virtueller CPUs, die Sie für alle N-Gäste zuordnen sollten, 11 beträgt. An Standorten mit gemischten Verteilungen von physischen und virtuellen Servern gilt dieser Modifizierer nur für die virtuellen Maschinen (VMs). In einem N +1-Szenario entspricht beispielsweise ein physischer oder direkt zugeordneter Server mit 10 CPUs fast einem Gast mit 11 CPUs auf einem Host mit 11 weiteren CPUs, die für den DC reserviert sind.
Während Sie analysieren und berechnen, wie viele CPUs Sie zur Unterstützung der AD DS-Auslastung benötigen, denken Sie daran, dass die verfügbaren Hardwaretypen möglicherweise nicht genau Ihren Schätzungen entsprechen, wenn Sie physische Hardware erwerben möchten. In einem Virtualisierungsszenario tritt dieses Problem hingegen nicht auf. Die Verwendung von virtuellen Computern verringert den Aufwand, den Sie zum Hinzufügen von Rechenkapazität zu einem Standort benötigen, da Sie beliebig viele CPUs mit den genauen Spezifikationen hinzufügen können, die Sie einem virtuellen Computer hinzufügen möchten. Die Virtualisierung beseitigt jedoch nicht Ihre Verantwortung dafür, genau zu bewerten, wie viel Rechenleistung Sie benötigen, um sicherzustellen, dass Ihre zugrunde liegende Hardware verfügbar ist, wenn Gäste mehr CPUs benötigen. Denken Sie wie immer daran, auch künftiges Wachstum in Ihre Planung einzubeziehen.
Zusammenfassungsbeispiel für Virtualisierungsberechnung
| System | Höchstwert für CPU |
|---|---|
| DC 1 | 120 % |
| DC 2 | 147 % |
| DC 3 | 218 % |
| Gesamte CPU-Nutzung | 485 % |
| Anzahl der Zielsysteme | Gesamtbandbreite (von oben) |
|---|---|
| Bei einem Ziel von 40 % erforderliche CPUs | 4,85 ÷ 0,4 = 12,25 |
Wenn Sie in diesem Szenario vorausplanen, dass die Nachfrage in den nächsten drei Jahren um 50 % wachsen wird, müssen Sie sicherstellen, dass sie bis zu diesem Zeitpunkt 18,375 CPUs (12,25 × 1,5) haben. Sie können den Bedarf auch nach dem ersten Jahr prüfen und dann auf der Grundlage der Ergebnisse zusätzliche Kapazität hinzufügen.
Vertrauenswürdige Clientauthentifizierungslast für NTLM
Auswerten der Last der vertrauenswürdigen Clientauthentifizierung
Viele Umgebungen verfügen möglicherweise über eine oder mehrere Domänen, die durch eine Vertrauensstellung verbunden sind. Authentifizierungsanforderungen für Identitäten in anderen Domänen, die Kerberos nicht verwenden, müssen eine Vertrauensstellung mithilfe eines sicheren Kanals zwischen zwei Domänencontrollern durchlaufen. Der Domänencontroller, auf den der Benutzer zugreifen möchte, stellt eine Verbindung mit einem anderen Domänencontroller, der sich entweder in der Zieldomäne oder an einer anderen Stelle im Pfad zur Zieldomäne weiter nach oben befindet, her. Wie viele Aufrufe der DC an den anderen DC in der vertrauenswürdigen Domäne vornehmen kann, wird durch die *MaxConcurrentAPI-Einstellung gesteuert. Um sicherzustellen, dass der sichere Kanal die für die Kommunikation mit den DCs erforderliche Last verarbeiten kann, können Sie entweder MaxConcurrentAPI optimieren oder, wenn Sie sich in einer Gesamtstruktur befinden, Verknüpfungsvertrauensstellungen erstellen. Weitere Informationen dazu, wie Sie das Datenverkehrsvolumen über Vertrauensstellungen hinweg ermitteln, finden Sie unter Leistungsoptimierung für die NTLM-Authentifizierung mithilfe der Einstellung MaxConcurrentApi.
Wie bei den vorherigen Szenarien, müssen Sie auch hier Daten während der Zeiträume mit Spitzenauslastung am Tag sammeln, damit sie nützlich sind.
Hinweis
Intra-Struktur- und Inter-Struktur-Szenarien können dazu führen, dass die Authentifizierung mehrere Vertrauensstellungen durchläuft. Das bedeutet, dass Sie in jeder Phase des Prozesses eine Optimierung durchführen müssen.
Planen der Virtualisierung
Es gibt einige Aspekte, die Sie bei der Kapazitätsplanung für die Virtualisierung beachten sollten:
- Zahlreiche Anwendungen verwenden standardmäßig oder in bestimmten Konfigurationen die Network Level Trust Manager (NTLM)-Authentifizierung.
- Mit zunehmender Anzahl an aktiven Clients nimmt auch die Notwendigkeit für größere Kapazitäten von Anwendungsservern zu.
- Clients halten Sitzungen manchmal für einen begrenzten Zeitraum geöffnet und stellen gleichzeitig regelmäßig Verbindungen für Dienste wie die E-Mail-Pullsynchronisierung her.
- Webproxyserver, die eine Authentifizierung für den Internetzugang erfordern, können eine hohe NTLM-Last verursachen.
Diese Anwendungen können eine große Last für die NTLM-Authentifizierung erzeugen. Dies bedeutet eine hohe Belastung für die Domänencontroller, insbesondere, wenn sich Benutzer und Ressourcen in unterschiedlichen Domänen befinden.
Es gibt zahlreiche Ansätze für die Verwaltung von Lasten über mehrere Vertrauensstellungen hinweg, die Sie häufig gleichzeitig verwenden können und sollten:
- Reduzieren Sie den Aufwand für die Clientauthentifizierung über mehrere Vertrauensstellungen hinweg, indem Sie die verwendeten Dienste in der Domäne suchen, in der sich die jeweiligen Benutzer*innen befinden.
- Erhöhen Sie die Anzahl der verfügbaren sicheren Kanäle. Diese Kanäle werden als Vertrauensstellungsabkürzungen bezeichnet und sind für den Intra-Datenverkehr- und Inter-Struktur-Datenverkehr relevant.
- Optimieren Sie die Standardeinstellungen für MaxConcurrentAPI.
Verwenden Sie die folgende Gleichung, um MaxConcurrentAPI auf einem vorhandenen Server zu optimieren:
Neue_MaxConcurrentApi-Einstellung ≥ (Semaphor_erwirbt + Semaphortimeouts) × Durchschnittliche_Semaphorenhaltezeit ÷ Dauer_der_Zeiterfassung
Weitere Informationen hierzu finden Sie unter KB-Artikel 2688798: Leistungsoptimierung für NTLM-Authentifizierung mithilfe der Einstellung MaxConcurrentApi.
Virtualisierung: Überlegungen
Es gibt keine besonderen Überlegungen, da die Virtualisierung eine Einstellung ist, die das Betriebssystems optimiert.
Beispiel für die Berechnung der Virtualisierungsoptimierung
| Datentyp | Wert |
|---|---|
| Semaphor erwirbt (Minimum) | 6.161 |
| Semaphor erwirbt (Maximum) | 6.762 |
| Semaphortimeouts | 0 |
| Durchschnittliche Semaphorenhaltezeit | 0,012 |
| Sammlungsdauer (Sekunden) | 1:11 Minuten (71 Sekunden) |
| Formel (von KB 2688798) | ((6762 – 6161) + 0) × 0,012 / |
| Mindestwert für MaxConcurrentAPI | ((6762 – 6161) + 0) × 0,012 ÷ 71 = 0,101 |
Für dieses System und diesen Zeitraum sind die Standardwerte akzeptabel.
Überwachung der Einhaltung der Ziele für die Kapazitätsplanung
In diesem Artikel haben wir beschrieben, wie Planung und Skalierung Auslastungsziele unterstützen. In der folgenden Tabelle werden die empfohlenen Schwellenwerte zusammengefasst, die Sie überwachen müssen, um sicherzustellen, dass Systeme wie vorgesehen ausgeführt werden. Beachten Sie, dass es sich hier nicht um Leistungsschwellenwerte, sondern nur lediglich um Schwellenwerte für die Kapazitätsplanung handelt. Ein Server, der diese Schwellenwerte überschreitet, funktioniert weiterhin. Sie müssen jedoch überprüfen, ob Ihre Anwendungen wie vorgesehen funktionieren, bevor Leistungsprobleme auftreten, weil die Benutzernachfrage steigt. Wenn die Anwendungen wie vorgesehen funktionieren, sollten Sie mit der Auswertung von Hardwareupgrades oder anderen Konfigurationsänderungen beginnen.
| Kategorie | Leistungsindikator | Intervall/Stichprobenentnahme | Ziel | Warnung |
|---|---|---|---|---|
| Prozessor | Processor Information(_Total)\% Processor Utility |
60 Min. | 40% | 60% |
| RAM (Windows Server 2008 R2 oder früher) | Arbeitsspeicher\Verfügbare MB | < 100 MB | – | < 100 MB |
| RAM (Windows Server 2012) | Arbeitsspeicher\Langfristige durchschnittliche Lebensdauer im Standbycache | 30 Min. | Muss getestet werden | Muss getestet werden |
| Netzwerk | Netzwerkschnittstelle(*)\Gesendete Bytes/s Netzwerkschnittstelle(*)\Empfangene Bytes/s |
30 Min. | 40% | 60% |
| Storage | LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/ReadLogicalDisk(( |
60 Min. | 10 ms | 15 ms |
| AD-Dienste | Netlogon(*)\Durchschnittliche Semaphorenhaltezeit | 60 Min. | 0 | 1 Sekunde |
Anhang A: Kriterien der CPU-Dimensionierung
In diesem Anhang werden nützliche Begriffe und Konzepte erläutert, die Sie bei der Dimensionierung der CPUs in Ihrer Umgebung unterstützen können.
Definitionen: CPU-Dimensionierung
Ein Prozessor (Mikroprozessor) ist eine Komponente, die Programmanweisungen liest und ausführt.
Ein Multi-Core-Prozessor verfügt über mehrere CPUs im selben integrierten Schaltkreis.
Ein Multi-CPU-System verfügt über mehrere CPUs, die sich nicht im selben integrierten Schaltkreis befinden.
Ein logischer Prozessor ist ein Prozessor, der aus Sicht des Betriebssystems nur über eine einzelne logische Computer-Engine verfügt.
Zu diesen Definitionen gehören Hyperthreading, ein einzelner Core in Multi-Core-Prozessoren oder Single-Core-Prozessoren.
Da die aktuellen Serversysteme über mehrere Prozessoren, mehrere Multi-Core-Prozessoren und Hyperthreading verfügen, werden diese Definitionen so verfasst, dass sie beide Szenarien abdecken. Wir verwenden den Begriff „logischer Prozessor“, weil er die Betriebssystem- und Anwendungsperspektive der verfügbaren Computing-Engines darstellt.
Parallelität auf Threadebene
Jeder Thread ist ein unabhängiger Task, da jeder Thread über einen eigenen Stapel und eigene Anweisungen verfügt. AD DS verwendet Multithreading. Sie können die Anzahl der verfügbaren Threads optimieren, indem Sie die Anleitung in Anzeigen und Festlegen der LDAP-Richtlinie in Active Directory mithilfe von Ntdsutil.exe befolgen. AD DS kann gut über mehrere logische Prozessoren hinweg skaliert werden.
Parallelität auf Datenebene
Parallelität auf Datenebene liegt vor, wenn ein Dienst Daten für denselben Prozess über zahlreiche Threads hinweg und zahlreiche Threads über mehrere Prozesse hinweg freigibt. Der AD DS-Prozess an sich würde als ein Dienst betrachtet werden, der Daten über mehrere Threads hinweg für einen einzelnen Prozess freigibt. Alle Änderungen der Daten werden in allen ausgeführten Threads auf allen Ebenen des Caches, in jedem Kern und in allen Aktualisierungen des freigegebenen Speichers reflektiert. Die Leistung kann während Schreibvorgängen abnehmen, da alle Speicherorte die Änderungen übernehmen müssen, bevor die Befehlsverarbeitung fortgesetzt werden kann.
Verhältnis zwischen CPU-Geschwindigkeit und Multi-Core-Prozessoren
Im Allgemeinen reduzieren schnellere logische Prozessoren den Zeitaufwand für die Verarbeitung einer Reihe von Anweisungen. Eine größere Zahl logischer Prozessoren bedeutet, dass Sie mehr Aufgaben gleichzeitig ausführen können. Diese Regeln gelten jedoch nicht in komplexeren Szenarien, z. B. beim Abrufen von Daten aus freigegebenem Speicher, beim Warten auf Parallelität auf Datenebene und hinsichtlich des Aufwands für die gleichzeitige Verwaltung mehrerer Threads. Die Skalierbarkeit von Multi-Core-Systemen verhält sich daher nicht linear.
Um dies zu verstehen, können Sie sich diese Szenarien als Autobahn vorstellen. Jeder Thread ist ein einzelnes Auto, jede Spur ist ein Kern, und die Geschwindigkeitsbegrenzung ist die Taktgeschwindigkeit.
Wenn nur ein Auto auf der Autobahn unterwegs ist, spielt es keine Rolle, ob es zwei oder 12 Spuren gibt. Dieses Auto fährt nur so schnell, wie es die Geschwindigkeitsbegrenzung zulässt.
Wenn die Daten, die der Thread benötigt, nicht sofort verfügbar sind, kann der Thread keine Anweisungen verarbeiten, bis die relevanten Daten aus dem Arbeitsspeicher abgerufen werden. Dies ist der Sperrung eines Abschnitts der Autobahn vergleichbar. Auch wenn nur ein Auto auf der Autobahn unterwegs ist, wirkt sich das Geschwindigkeitslimit nicht auf dessen Fähigkeit aus, zu fahren, da es warten muss, bis der Abschnitt der Autobahn wieder geöffnet wird.
Mit zunehmender Anzahl von Autos steigt auch der Overhead, den die Autobahn für die Bewältigung der Anzahl der Autos benötigt. Die Fahrer*innen müssen sich während der Stoßzeiten auf der Autobahn stärker konzentrieren als am späten Abend, wenn die Autobahn meist leer ist. Außerdem erfordert das Fahren auf einer zweispurigen Autobahn, bei der Sie nur auf eine weitere Spur achten müssen, weniger Konzentration als das Fahren auf einer sechsspurigen Autobahn, auf der Sie auf fünf weitere Spuren achten müssen.
Kurz gesagt, sind die Antworten auf die Frage, ob Sie mehr Prozessoren oder schnellere Prozessoren hinzufügen sollten, sehr subjektiv und sollten fallweise formuliert werden. Insbesondere für AD DS sind die Verarbeitungsanforderungen von Umgebungsfaktoren abhängig und können in derselben Umgebung von Server zu Server unterschiedlich sein. Daher wurden in den vorherigen Abschnitten in diesem Artikel keine superpräzisen Berechnungen bereitgestellt. Wenn Sie budgetbasierte Kaufentscheidungen treffen, sollten Sie die Prozessorauslastung zunächst für 40 % oder den Prozentsatz optimieren, den Ihre spezifische Umgebung erfordert. Wenn Ihr System nicht optimiert ist, profitieren Sie nicht sehr viel vom Kauf zusätzlicher Prozessoren.
Hinweis
Amdahls Gesetz und Gustafsons Gesetz sind die relevanten Konzepte, die hier genannt werden müssen.
Antwortzeiten und Auswirkungen der Systemaktivitätsstufen auf die Leistung
Die Warteschlangentheorie ist die mathematische Untersuchung von Warteschlangen. In der Warteschlangentheorie für das Computing wird das Auslastungsgesetz durch die t-Gleichung dargestellt:
U k = B ÷ T
Dabei ist U k der Auslastungsprozentsatz, B ist die Zeit, die mit Aktivitäten verbracht wird, und T ist die gesamte Zeit, die mit der Beobachtung des Systems verbracht wird. In einem Microsoft-Kontext bedeutet dies die Anzahl der Threads mit einem Intervall von 100 Nanosekunden (ns), die sich im Ausführungsstatus befinden, geteilt durch die Anzahl der 100-Nanosekunden-Intervalle, die im angegebenen Zeitintervall verfügbar waren. Dies ist die gleiche Formel, die den Prozentsatz der Prozessorauslastung berechnet, wie in Prozessorobjekt und PERF_100NSEC_TIMER_INV gezeigt.
Die Warteschlangentheorie stellt auch die folgende Formel bereit: N = U k ÷ (1 – U k), um die Anzahl der wartenden Elemente basierend auf der Auslastung zu schätzen, wobei N die Länge der Warteschlange ist. Wenn Sie diese Gleichung über alle Auslastungsintervalle hinweg grafisch darstellen, erhalten Sie die folgenden Schätzungen für die Länge der Warteschlange für den Prozessor bei einer bestimmten CPU-Auslastung.
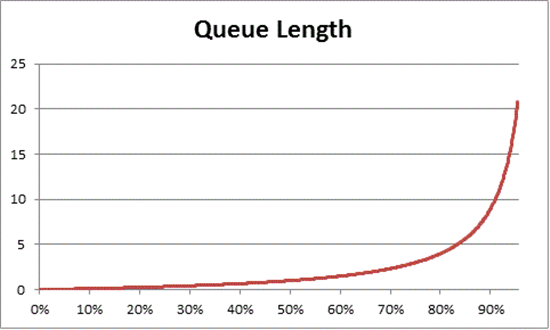
Basierend auf dieser Schätzung können wir beobachten, dass nach Erreichen einer CPU-Auslastung von 50 % die durchschnittliche Warteschlange in der Regel ein weiteres Element aufnimmt und sich die CPU-Auslastung schnell auf 70 % erhöht.
Um die Anwendung der Warteschlangentheorie auf Ihre AD DS-Bereitstellung zu erklären, kehren wir zur Autobahnmetapher zurück, die wir bereits in Verhältnis zwischen CPU-Geschwindigkeit und Multi-Core-Prozessoren verwendet haben.
Zeiten mit größerer Auslastung am Nachmittag würden in den Kapazitätsbereich von 40 % bis 70 % fallen. Ihre Fähigkeit, eine Spur zu wählen, ist daher nicht erheblich eingeschränkt. Auch wenn die Chance groß ist, dass andere Fahrer*innen Sie behindern, müssen Sie sich nicht in dem Umfang wie während der Stoßzeiten konzentrieren, um eine sichere Lücke zwischen anderen Autos in der Spur zu finden.
Je näher die Stoßzeiten sind, desto stärker nähert sich die Autobahn einer Auslastung von 100 %. Das Wechseln von Spuren während der Stoßzeiten wird sehr schwierig, da die Autos so nahe aneinander fahren, dass Sie nicht viel Platz haben, wenn Sie die Spur wechseln möchten.
Daher ermöglicht die Schätzung eines langfristigen Durchschnittswerts für die Kapazität von 40 % mehr Spielraum für anomale Auslastungsspitzen, unabhängig davon, ob es sich um vorübergehende Spitzen handelt (z. B. bei schlecht codierten Abfragen, deren Ausführung eine Weile dauert) oder um anomale Spitzen der allgemeinen Auslastung (z. B. Aktivitätsspitzen am Morgen nach einem Feiertag).
Die vorherige Aussage betrachtet die Berechnung des Prozentsatzes der Prozessorzeit als identisch mit der Auslastungsgesetzgleichung. Diese vereinfachte Version soll das Konzept für neue Benutzer*innen erklären. Für komplexere Berechnungen können Sie jedoch die folgenden Referenzen als Leitfaden verwenden:
- Übersetzen von PERF_100NSEC_TIMER_INV
- B = Die Anzahl der 100-Nanosekunden-Intervalle, die der Leerlaufthread im logischen Prozessor verbringt. Die Änderung der Variablen X in der Berechnung PERF_100NSEC_TIMER_INV.
- T = die Gesamtzahl der 100-ns-Intervalle in einem bestimmten Zeitbereich. Die Änderung der Variablen Y in der Berechnung PERF_100NSEC_TIMER_INV.
- U k = Der Auslastungsprozentsatz des logischen Prozessors durch Leerlaufthread oder % Leerlaufzeit.
- Ausarbeiten der Berechnung:
- U k = 1 – %Prozessorzeit
- %Prozessorzeit = 1 – U k
- %Prozessorzeit = 1 – B / T
- %Prozessorzeit = 1 – X1 – X0 / Y1 – Y0
Anwendung dieser Konzepte auf die Kapazitätsplanung
Die Formel im vorherigen Abschnitt lässt die Berechnung der benötigten Zahl von logischen Prozessoren in einem System wahrscheinlich sehr komplex erscheinen. Daher sollte sich Ihr Ansatz für die Dimensionierung des Systems zunächst auf die Bestimmung der maximalen Zielauslastung basierend auf der aktuellen Auslastung konzentrieren. In einem zweiten Schritt sollten Sie die Anzahl der logischen Prozessoren berechnen, die Sie benötigen, um dieses Ziel zu erreichen. Ihre Schätzung muss nicht perfekt sein. Die Geschwindigkeit der logischen Prozessoren hat erhebliche Auswirkungen auf die Synchronisierung. Die Leistung kann jedoch auch von anderen Faktoren beeinflusst werden:
- Effizienz der Cachenutzung
- Anforderungen an die Speicherkohärenz
- Threadplanung und -synchronisierung
- Ungenauer Lastenausgleich für Clients
Da die Computeleistung relativ kostengünstig ist, lohnt es sich nicht, zu viel Zeit in die Berechnung der genauen Anzahl der benötigten CPUs zu investieren.
Sie sollten auch daran denken, dass die Empfehlung von 40 %, wie in diesem Fall, keine obligatorische Anforderung ist. Wir verwenden diese Zahl als einen angemessenen Startwert für Berechnungen. Verschiedene Arten von AD-Benutzer*innen benötigen verschiedene Reaktionsstufen. Es kann sogar Szenarien geben, in denen Umgebungen mit einer durchschnittlichen Auslastung von 80 % oder sogar 90 % ausgeführt werden können, ohne dass sich die längeren Wartezeiten für den Prozessorzugriff bemerkbar auf die Clientleistung auswirken.
Es gibt weitere Bereiche im System, die sehr viel langsamer als der logische Prozessor sind, die Sie ebenfalls optimieren sollten, darunter der RAM-Zugriff, der Datenträgerzugriff und die Übertragung von Antworten über das Netzwerk. Zum Beispiel:
Wenn Sie Prozessoren zu einem datenträgerbasierten System hinzufügen, das mit einer Auslastung von 90 % ausgeführt wird, wird dies die Leistung wahrscheinlich nicht erheblich verbessern. Wenn Sie sich das System genauer ansehen, werden Sie feststellen, dass es viele Threads gibt, die nicht einmal zum Prozessor gelangen, da sie auf den Abschluss von E/A-Vorgängen warten.
Die Behebung von datenträgerbasierten Problemen kann dazu führen, dass Threads, die zuvor im Wartezustand stecken geblieben sind, nicht mehr stecken bleiben, wodurch mehr Wettbewerb um die CPU-Zeit entsteht. Daher erhöht sich die Auslastung von 90 % auf 100 %. Sie müssen beide Komponenten optimieren, um die Auslastung wieder auf ein verwaltbares Niveau zu führen.
Hinweis
Der
Processor Information(*)\% Processor UtilityZähler kann bei Systemen mit Turbomodus die Marke von 100 % überschreiten. Im Turbomodus kann die CPU die Nenngeschwindigkeit des Prozessors kurzzeitig überschreiten. Wenn Sie weitere Informationen benötigen, schauen Sie sich die Dokumentation der CPU-Hersteller und die Zählerbeschreibungen an.
Bei der Diskussion der Auslastung des gesamten Systems müssen auch Domänencontroller als virtualisierte Gäste berücksichtigt werden. Reaktionszeiten und die Aktivitätsstufen auf Systemebene sind beides Faktoren, die sich in einem virtualisierten Szenario sowohl auf den Host als auch auf den Gast auswirken. In einem Host mit nur einem Gast weist ein Domänencontroller oder ein System beinahe die gleiche Leistung wie auf physischer Hardware auf. Das Hinzufügen weiterer Gäste zu den Hosts erhöht die Auslastung des zugrunde liegenden Hosts und damit auch die Wartezeiten für den Zugriff auf die Prozessoren. Daher müssen Sie die Auslastung des logischen Prozessors sowohl auf Host- als auch auf Gastebene verwalten.
Schauen wir uns die Autobahnmetapher aus den vorherigen Abschnitten noch einmal an. Diesmal stellen wir uns die Gast-VM als Expressbus vor. Im Gegensatz zu öffentlichen Verkehrsmitteln oder Schulbussen fahren Expressbusse direkt und ohne Zwischenhalt zum Ziel.
Betrachten wir nun vier Szenarien:
- Ein System verhält sich außerhalb von Zeiten mit Spitzenauslastungen wie ein Expressbus spät am Abend. Wenn der Fahrgast in den Bus einsteigt, gibt es so gut wie keine anderen Passagiere und die Straße ist beinahe leer. Da es keinen Verkehr gibt, mit dem der Expressbus konkurrieren muss, ist die Fahrt ist einfach und genauso schnell, als wenn der Fahrgast mit dem eigenen Auto fahren würde. Die Fahrtzeit für den Fahrgast unterliegt jedoch auch den lokalen Geschwindigkeitsbegrenzungen.
- Wenn die CPU-Auslastung in Zeiten außerhalb der Spitzenauslastungszeiten zu hoch ist, entspricht dies einer Fahrt mit dem Expressbus, wenn die meisten Autobahnspuren gesperrt sind. Auch wenn der Expressbus selbst beinahe leer ist, wird die Autobahn aufgrund der gesperrten Spuren weiter vom Restverkehr verstopft. Der Fahrgast kann zwar den Sitzplatz im Expressbus frei wählen, die tatsächliche Fahrtzeit wird jedoch durch den Verkehr außerhalb des Busses bestimmt.
- Ein System mit einer hohen CPU-Auslastung während Spitzenauslastungszeiten verhält sich hingegen wie ein überfüllter Expressbus während der Stoßzeiten. Die Fahrt dauert nicht nur länger, sondern es ist auch schwieriger, in den Expressbus einzusteigen oder aus ihm auszusteigen, da er voll mit weiteren Passagieren ist. Wenn Sie dem Gastsystem weitere logische Prozessoren hinzufügen, um die Wartezeiten zu verkürzen, wäre es so, als würden Sie weitere Expressbusse hinzufügen, um das Datenverkehrsproblem zu lösen. Das Problem ist nicht die Anzahl der Busse, sondern die Dauer der Fahrt.
- Ein System mit hoher CPU-Auslastung außerhalb der Spitzenauslastungszeiten verhält sich wie ein überfüllter Expressbus auf einer beinahe leeren Straße in der Nacht. Während die Fahrgäste möglicherweise Probleme haben, einen Sitzplatz zu finden oder in den Bus einzusteigen oder aus ihm auszusteigen, verläuft die Fahrt an sich vergleichsweise problemlos, sobald der Bus alle Fahrgäste abgeholt hat. Dieses Szenario ist das einzige Szenario, in dem die Leistung durch das Hinzufügen weiterer Busse verbessert werden würde.
Anhand dieser Beispiele können Sie erkennen, dass es zahlreiche Szenarien zwischen 0 % und 100 % Auslastung gibt, die sich unterschiedlich auf die Leistung auswirken. Das Hinzufügen logischer Prozessoren verbessert die Leistung nicht notwendigerweise, abgesehen von sehr spezifischen Szenarien. Es sollte vergleichsweise einfach sein, diese Grundsätze auf das empfohlene CPU-Auslastungsziel von 40 % für Hosts und Gäste anzuwenden.
Anhang B: Überlegungen zu unterschiedlichen Prozessorgeschwindigkeiten
Hinsichtlich der Verarbeitung sind wir davon ausgegangen, dass der Prozessor während der Datenerfassung mit einer Taktgeschwindigkeit von 100 % ausgeführt wird und alle Ersatzsysteme die gleiche Verarbeitungsgeschwindigkeit aufweisen. Auch wenn diese Annahmen nicht korrekt sind (insbesondere für Windows Server 2008 R2 und höhere Versionen, bei denen der Standardenergiesparplan „Ausgeglichen“ ist), sind diese Annahmen für konservative Schätzungen geeignet. Die Zahl der potenziellen Fehler kann zwar zunehmen, wird die Sicherheitsreserve mit zunehmender Prozessorgeschwindigkeit erhöht.
- Wenn beispielsweise in einem Szenario, das 11,25 CPUs erfordert, die Prozessoren beim Erfassen der Daten mit halber Geschwindigkeit ausgeführt werden, würde der Bedarf mit 5,125 ÷ 2 korrekter geschätzt werden.
- Es ist unmöglich, zu garantieren, dass eine Verdoppelung der Taktfrequenz auch die Menge der Verarbeitungsvorgänge verdoppelt, die innerhalb des aufgezeichneten Zeitraums stattfinden. Die Zeit, die Prozessoren mit dem Warten auf RAM oder andere Komponenten verbringen, bleibt ungefähr gleich. Daher könnten schnellere Prozessoren einen größeren Prozentsatz der Zeit im Leerlauf verbringen, während sie darauf warten, dass das System Daten abruft. Wir empfehlen Ihnen, sich an den niedrigsten gemeinsamen Nenner zu halten, Ihre Schätzungen konservativ zu halten und die Annahme eines linearen Verhältnisses zwischen Prozessorgeschwindigkeiten zu vermeiden, die dies zu ungenauen Ergebnissen führen könnte.
Wenn die Prozessorgeschwindigkeiten der Ersatzhardware niedriger sind als die Prozessorgeschwindigkeiten der aktuellen Hardware, sollten Sie die Schätzung der Anzahl der benötigten Prozessoren proportional erhöhen. Betrachten wir beispielsweise ein Szenario, in dem Sie Ihrer Berechnung nach 10 Prozessoren benötigen, um die Auslastung Ihrer Site zu bewältigen. Die aktuellen Prozessoren besitzen eine Taktfrequenz von 3,3 GHz. Die Prozessoren, mit denen Sie diese ersetzen möchten, besitzen eine Taktfrequenz von 2,6 GHz. Wenn Sie nur die 10 originalen Prozessoren ersetzen, würde die Geschwindigkeit um 21 % verringert. Um die Geschwindigkeit zu erhöhen, müssen Sie mindestens 12 Prozessoren statt 10 verwenden.
Diese Variabilität ändert jedoch die Kapazitätsverwaltung hinsichtlich der Prozessorauslastungsziele. Die Prozessortaktfrequenzen werden basierend auf den Auslastungsanforderungen dynamisch angepasst. Daher führt die Ausführung des Systems bei höheren Auslastungen dazu, dass die CPU mehr Zeit in einem höheren Taktfrequenzzustand verbringt. Das ultimative Ziel besteht darin, für die CPU während Zeiten mit einer Spitzenauslastung eine Auslastung von 40 % und eine Taktfrequenz von 100 % zu erreichen. Niedrigere Werte führen zu Energieeinsparungen, indem die CPU-Geschwindigkeit außerhalb der Spitzenzeiten gedrosselt wird.
Hinweis
Sie können die Energieverwaltung für die Prozessoren während der Datenerfassung deaktivieren, indem Sie den Energiesparplan auf Hohe Leistung festlegen. Wenn Sie die Energieverwaltung deaktivieren, erhalten Sie genauere Werte für den CPU-Verbrauch auf dem Zielserver.
Um Schätzungen für verschiedene Prozessoren zu erhalten, sollten Sie den Benchmark SPECint_rate2006 der Standard Performance Evaluation Corporation verwenden. So verwenden Sie diesen Benchmark:
Rufen Sie die Website der Standard Performance Evaluation Corporation (SPEC) auf.
Wählen Sie Ergebnisse aus.
Geben Sie CPU2006 ein, und wählen Sie Suchen aus.
Wählen Sie im Dropdownmenü Verfügbare Konfigurationen die Option Alle SPEC CPU2006 aus.
Wählen Sie im Feld Art der Suchanforderung die Option Einfach und dann OK aus.
Geben Sie in Einfache Anforderung die Suchkriterien für den Zielprozessor ein. Wenn Sie beispielsweise nach einem ES-2630-Prozessor suchen, wählen Sie im Dropdownmenü Prozessor aus und geben dann den Namen des Prozessors in das Suchfeld ein. Wenn Sie fertig sind, wählen Sie Einfachen Abruf ausführen aus.
Suchen Sie in den Suchergebnissen nach Ihrer Server- und Prozessorkonfiguration. Wenn die Suchmaschine keine genaue Übereinstimmung zurückgibt, suchen Sie nach der bestmöglichen Übereinstimmung.
Notieren Sie die Werte in den Spalten Ergebnis und # Kerne.
Ermitteln Sie mithilfe dieser Gleichung den Modifizierer:
((Wert der Zielplattform pro Kern) × (MHz pro Kern der Baselineplattform)) ÷ ((Baseline-Wert pro Kern) × (MHz pro Kern der Zielplattform))
So finden Sie beispielsweise den Modifizierer für einen ES-2630-Prozessor:
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Multiplizieren Sie die Anzahl der Prozessoren, die Ihrer Schätzung nach erforderlich sind, mit diesem Modifizierer.
Im Beispiel mit dem ES-2630-Prozessor wären dies 0,92 × 10,3 = 10,35 Prozessoren.
Anhang C: Art der Interaktion des Betriebssystems mit dem Speicher
Die Konzepte der Warteschlangentheorie, die in Antwortzeiten und Auswirkungen der Systemaktivitätsstufen auf die Leistung behandelt wurden, gelten auch für den Speicher. Sie müssen damit vertraut sein, wie Ihr Betriebssystem E/A-Anforderungen behandelt, um diese Konzepte effektiv anwenden zu können. In Windows-Betriebssystemen erstellt das Betriebssystem eine Warteschlange mit E/A-Anforderungen für jeden physischen Datenträger. Bei einem physischen Datenträger handelt es sich jedoch nicht notwendigerweise um einen einzelnen Datenträger. Das Betriebssystem kann auch eine Aggregation von Spindeln auf einem Arraycontroller oder in einem SAN als physischen Datenträger registrieren. Arraycontroller und SANs können auch mehrere Datenträger zu einem einzigen Arraysatz aggregieren, diesen in mehrere Partitionen aufteilen und dann jede Partition als einen physischen Datenträger verwenden, wie in der folgenden Abbildung dargestellt.
In dieser Abbildung werden die beiden Spindeln gespiegelt und in logische Bereiche für die Datenspeicherung aufgeteilt, die mit „Data 1“ und „Data 2“ bezeichnet sind. Das Betriebssystem registriert jeden dieser logischen Bereiche als getrennte physische Datenträger.
Nachdem wir nun den Begriff „physischer Datenträger“ geklärt haben, sollten Sie sich auch mit den folgenden Begriffen vertraut machen, um die Informationen in diesem Anhang besser verstehen zu können.
- Eine Spindel ist das Gerät, das physisch im Server installiert ist.
- Ein Array ist eine Sammlung von Spindeln, die vom Controller aggregiert werden.
- Eine Array-Partition ist eine Partitionierung des aggregierten Arrays.
- Eine Logical Unit Number (LUN) ist ein Array von SCSI-Geräten, die mit einem Computer verbunden sind. In diesem Artikel werden im Zusammenhang mit SANs die folgenden Begriffe verwendet.
- Ein Datenträger enthält alle Spindeln oder Partitionen, die vom Betriebssystem als einzelne physische Datenträger registriert werden.
- Eine Partition ist eine logische Partitionierung von dem, was vom Betriebssystem als physischer Datenträger registriert wird.
Überlegungen zur Architektur des Betriebssystems
Das Betriebssystem erstellt für jeden von ihm registrierten Datenträger eine First In, First Out (FIFO)-Warteschlange für E/A-Anforderungen. Bei diesen Datenträgern kann es sich um Spindeln, Arrays oder Arraypartitionen handeln. Hinsichtlich der Behandlung von E/A-Anforderungen durch das Betriebssystem gilt: Je mehr aktive Warteschleifen, desto besser. Wenn das Betriebssystem die FIFO-Warteschlange serialisiert, muss sie alle FIFO-E/A-Anforderungen, die für das Speichersubsystem ausgegeben werden, in der Reihenfolge des Eintreffens verarbeiten. Wenn das Betriebssystem jeden Datenträger mit einer Spindel oder einem Array korreliert, verwaltet es eine E/A-Warteschlange für jede einzelne Gruppe von Datenträgern. Dies beseitigt den Wettbewerb um knappe E/A-Ressourcen über Datenträger hinweg und die Isolierung von E/A-Anforderungen zu einem einzelnen Datenträger. Windows Server 2008 hat jedoch eine Ausnahme in Form der E/A-Priorisierung eingeführt. Anwendungen, deren E/A-Anforderungen eine niedrige Priorität haben, werden unabhängig davon, wann das Betriebssystem sie erhalten hat, zu einer hinteren Position in der Warteschlange verschoben. Für Anwendungen, die nicht speziell für E/A-Anforderungen mit niedriger Priorität entwickelt wurden, gilt stattdessen die normale Priorität.
Einführung einfacher Speichersubsysteme
In diesem Abschnitt werden einfache Speichersubsysteme behandelt. Beginnen wir mit dem folgenden Beispiel: eine einzelne Festplatte in einem Computer. Wenn wir dieses System in die wesentlichen Speichersubsystemkomponenten aufteilen, erhalten wir Folgendes:
- Eine ultraschnelle SCSI-HD mit 10.000 U/min (ultraschnelles SCSI hat eine Übertragungsrate von 20 Mbit/s)
- Einen einzelnen SCSI-Bus (das Kabel)
- Einen einzelnen ultraschnellen SCSI-Adapter
- Einen einzelnen PCI-Bus mit 32 Bit und 33 MHz
Hinweis
In diesem Beispiel wird der Datenträgercache nicht berücksichtigt, in dem das System in der Regel die Daten eines einzelnen Zylinders speichert. In diesem Fall benötigt die erste E/A-Anforderung 10 ms. Die Festplatte liest den gesamten Zylinder. Alle weiteren sequenziellen E/A-Anforderungen werden vom Cache erfüllt. Daher können Datenträgercaches die sequenzielle E/A-Leistung verbessern.
Wenn Sie die Komponenten identifizieren, erhalten Sie eine Vorstellung davon, wie viele Daten das System übertragen kann und wie viele E/A-Anforderungen es verarbeiten kann. Es gibt zwar eine Entsprechung zwischen der Zahl der E/A-Anforderungen und der Menge der Daten, die das System verarbeiten kann. Es handelt sich jedoch nicht um denselben Wert. Diese Korrelation ist von der Blockgröße und davon abhängig, ob die Datenträger-E/A-Verarbeitung zufällig oder sequenziell ist. Das System schreibt alle Daten als Block zum Datenträger. Unterschiedliche Anwendungen können jedoch unterschiedliche Blockgrößen verwenden.
Betrachten wir nun diese Komponenten einzeln.
Festplattenzugriffszeiten
Eine durchschnittliche Festplatte mit 10.000 U/min stellt eine Suchzeit von 7 ms und eine Zugriffszeit von 3 ms bereit. Die Suchzeit ist die durchschnittliche Zeit, die der Lese- oder Schreibkopf benötigt, um sich zu einer Position auf der Festplatte zu bewegen. Die Zugriffszeit ist die durchschnittliche Zeit, die der Kopf benötigt, um die Daten auf der Festplatte zu lesen oder zur Festplatte zu schreiben, sobald er sich in der richtigen Position befindet. Daher umfasst die durchschnittliche, für das Lesen eines eindeutigen Datenblocks auf einer Festplatte mit 10.000 U/min benötigte Zeit sowohl die Such- als auch die Zugriffszeiten pro Datenblock, insgesamt ungefähr 10 ms bzw. 0,010 Sekunden.
Wenn jeder Festplattenzugriff erfordert, dass der Kopf zu einer neuen Position auf der Festplatte bewegt wird, wird das Lese- oder Schreibverhalten als „zufällig“ bezeichnet. Wenn alle E/A-Anforderungen zufällig sind, kann eine Festplatte mit 10.000 U/min ungefähr 100 E/A-Anforderungen pro Sekunde (I/O Per Second, IOPS) verarbeiten.
Wenn alle E/A-Anforderungen für benachbarte Sektoren auf der Festplatte ausgeführt werden, wird das Lese- oder Schreibverhalten als sequenziell bezeichnet. Für sequenzielle E/A-Anforderungen gibt es keine Suchzeit, da sich nach Abschluss der ersten E/A-Anforderung der Lese- oder Schreibkopf am Anfang der Position befindet, an der die Festplatte den nächsten Datenblock auf der Festplatte gespeichert hat. Eine Festplatte mit 10.000 U/min kann beispielsweise ungefähr 333 E/A-Anforderungen pro Sekunde verarbeiten. Dies basiert auf der folgenden Gleichung:
1000 ms pro Sekunde ÷ 3 ms pro E/A-Anforderung
Bisher war die Übertragungsrate der Festplatte für unser Beispiel nicht relevant. Unabhängig von der Festplattengröße beträgt die tatsächliche IOPS-Zahl, die eine Festplatte mit 10.000 U/min verarbeiten kann, immer ungefähr 100 zufällige oder 300 sequenzielle E/A-Anforderungen. Da die Blockgrößen von der jeweiligen Anwendung abhängig sind, die zum Laufwerk schreibt, ändert sich auch die Datenmenge, die pro E/A-Anforderung abgerufen wird. Wenn die Blockgröße beispielsweise 8 KB beträgt, werden bei 100 E/A-Vorgängen insgesamt 800 KB von der Festplatte gelesen oder darauf geschrieben. Wenn die Blockgröße 32 KB beträgt, werden von 100 E/A-Anforderungen 3.200 KB (3,2 MB) von der Festplatte gelesen oder zur Festplatte geschrieben. Wenn die SCSI-Übertragungsrate die Gesamtmenge der übertragenen Daten überschreitet, führt eine schnellere Übertragungsrate nicht zu einer Änderung. Ausführlichere Informationen finden Sie in den folgenden Tabellen:
| Beschreibung | 7.200 U/min, 9 ms Suchzeit, 4 ms Zugriffszeit | 10.000 U/min, 7 ms Suchzeit, 3 ms Zugriffszeit | 15.000 U/min, 4 ms Suchzeit, 2 ms Zugriffszeit |
|---|---|---|---|
| Zufällige E/A | 80 | 100 | 150 |
| Sequenzielle E/A | 250 | 300 | 500 |
| Laufwerk mit 10.000 U/min | Blockgröße von 8 KB (Active Directory Jet) |
|---|---|
| Zufällige E/A | 800 KB/s |
| Sequenzielle E/A | 2.400 KB/s |
Das SCSI-Backplane
Die Auswirkungen des SCSI-Backplane (in diesem Beispielszenario das Flachbandkabel) auf den Durchsatz des Speichersubsystems sind von der Blockgröße abhängig. Wie viele E/A-Anforderungen kann der Bus verarbeiten, wenn die E/A-Anforderungen in 8-KB-Blöcken erfolgen? In diesem Szenario hat der SCSI-Bus eine Kapazität von 20 Mbit/s bzw. 20480 KB/s. 20.480 KB/s geteilt durch 8-KB-Blöcke ergibt ein vom SCSI-Bus unterstütztes Maximum von ca. 2.500 IOPS.
Hinweis
Die Zahlen in der folgenden Tabelle stellen ein Beispielszenario dar. Die meisten angeschlossenen Speichergeräte verwenden derzeit PCI Express, was einen viel höheren Durchsatz bietet.
| Vom SCSI-Bus pro Blockgröße unterstützte E/A-Vorgänge | 2 KB Blockgröße | 8 KB Blockgröße (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 MBit/s | 10.000 | 2\.500 |
| 40 MBit/s | 20.000 | 5\.000 |
| 128 Mbit/s | 65.536 | 16.384 |
| 320 Mbit/s | 160.000 | 40.000 |
Wie in der vorherigen Tabelle gezeigt, wird der Bus in diesem Beispielszenario niemals zum Engpass, da die maximale Zahl der E/A-Anforderungen für die Spindel 100 beträgt, d. h. weit unter den aufgeführten Schwellenwerten liegt.
Hinweis
In diesem Szenario wird davon ausgegangen, dass der SCSI-Bus 100 % effizient ist.
Der SCSI-Adapter
Um die Zahl der E/A-Anforderungen zu ermitteln, die das System verarbeiten kann, müssen Sie die Spezifikationen des Herstellers überprüfen. Die Weiterleitung von E/A-Anforderungen an das entsprechende Gerät setzt Verarbeitungsleistung voraus. Daher ist die Zahl der E/A-Anforderungen, die das System verarbeiten kann, vom SCSI-Adapter oder vom Prozessor des Arraycontrollers abhängig.
In diesem Beispielszenario wird davon ausgegangen, dass das System 1.000 E/A-Anforderungen verarbeiten kann.
Der PCI-Bus
Der PCI-Bus ist eine häufig übersehene Komponente. In diesem Beispielszenario ist der PCI-Bus nicht der Engpass. Mit zunehmender Skalierung des Systems kann er jedoch in der Zukunft zum Engpass werden.
Wir können anhand der folgenden Formel feststellen, wie viele Daten ein PCI-Bus in unserem Beispielszenario übertragen kann:
32 Bit ÷ 8 Bit pro Byte × 33 MHz = 133 Mbit/s
Daher können wir davon ausgehen, dass ein PCI-Bus mit 32 Bit und 33 MHz Daten mit einer Rate von 133 Mbit/s übertragen kann.
Hinweis
Das Ergebnis dieser Gleichung stellt die theoretische Grenze für die Menge der übertragenen Daten dar. In der Realität erreichen die meisten Systeme lediglich ungefähr 50 % der Höchstgrenze. In bestimmten Burstszenarien kann Systeme kurzzeitig 75 % des Grenzwerts erreichen.
Ein PCI-Bus mit 64 Bit und 66 MHz kann ein theoretisches Maximum von 528 Mbit/s unterstützen, basierend auf dieser Formel:
64 Bit ÷ 8 Bit pro Byte × 66 MHz = 528 Mbit/s
Wenn Sie ein weiteres Gerät hinzufügen, z. B. einen Netzwerkadapter oder einen zweiten SCSI-Controller, reduziert dies die für das System verfügbare Bandbreite, da alle Geräte die Bandbreite gemeinsam nutzen und um begrenzte Verarbeitungsressourcen konkurrieren können.
Analyse der Speichersubsysteme zur Ermittlung von Engpässen
In diesem Szenario ist die Spindel der begrenzende Faktor hinsichtlich der Zahl der E/A-Anforderungen, die Sie anfordern können. Daher wirkt sich dieser Engpass auch auf die Menge der Daten aus, die das System übertragen kann. Da es sich bei unserem Beispiel um ein AD DS-Szenario handelt, beträgt die Menge der übertragbaren Daten 100 zufällige E/A-Anforderungen pro Sekunde in Schritten von 8 KB, d. h. insgesamt 800 KB pro Sekunde, wenn Sie auf die Jet-Datenbank zugreifen. Im Gegensatz hierzu würde der maximale Durchsatz für eine Spindel, die Sie ausschließlich für die Speicherung von Protokolldateien konfigurieren, auf 300 sequenzielle E/A-Anforderungen pro Sekunde in Schritten von 8 KB begrenzt, d. h. insgesamt 2.400 KB oder 2,4 MB pro Sekunde.
Nachdem wir nun die Komponenten der Beispielkonfiguration analysiert haben, betrachten wir nun eine Tabelle, die angibt, an welchen Stellen Engpässe auftreten können, wenn wir im Speichersubsystem Komponenten hinzufügen oder ändern.
| Hinweise | Engpassanalyse | Datenträger | Bus | Adapter | PCI-Bus |
|---|---|---|---|---|---|
| Dies ist die Domänencontrollerkonfiguration nach dem Hinzufügen eines zweiten Datenträgers. Die Datenträgerkonfiguration stellt den Engpass bei 800 KB/s dar. | Hinzufügen von 1 Datenträger (Gesamtmenge=2) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD |
200 E/A-Vorgänge insgesamt 800 KB/s insgesamt |
|||
| Nach dem Hinzufügen von 7 Datenträgern stellt die Datenträgerkonfiguration bei 3.200 KB/s weiterhin den Engpass dar. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD |
800 E/A-Vorgänge insgesamt 3.200 KB/s insgesamt |
|||
| Nach der Änderung der Verarbeitung von E/A-Anforderungen in eine sequenzielle Verarbeitung wird der Netzwerkadapter zum Engpass, da er auf 1000 IOPS begrenzt ist. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist sequenziell 4 KB Blockgröße 10.000 U/min-HD |
2.400 E/A-Vorgänge (Lesen/Schreiben) pro Sekunde auf dem Datenträger, Controller auf 1.000 IOPS beschränkt | |||
| Nach dem Ersetzen des Netzwerkadapters durch einen SCSI-Adapter, der 10.000 IOPS unterstützt, liegt der Engpass wieder bei der Datenträgerkonfiguration. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD Upgrade des SCSI-Adapters (unterstützt jetzt 10.000 E/A) |
800 E/A-Vorgänge insgesamt 3.200 KB/s insgesamt |
|||
| Nach dem Erhöhen der Blockgröße auf 32 KB wird der Bus zum Engpass, da er maximal 20 Mbit/s unterstützt. | Hinzufügen von 7 Datenträgern (Gesamtmenge=8) E/A ist wahlfrei 32 KB Blockgröße 10.000 U/min-HD |
800 E/A-Vorgänge insgesamt Es können 25.600 KB/s (25 Mbit/s) von der Festplatte gelesen oder zur Festplatte geschrieben werden. Der Bus unterstützt maximal 20 Mbit/s. |
|||
| Nach dem Upgrade des Busses und dem Hinzufügen weiterer Datenträger bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist wahlfrei 4 KB Blockgröße 10.000 U/min-HD Upgrade auf einen SCSI-Bus mit 320 Mbit/s |
2.800 E/A 11.200 KB/s (10,9 Mbit/s) |
|||
| Nach dem Ändern der E/A in sequenziell bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 4 KB Blockgröße 10.000 U/min-HD Upgrade auf einen SCSI-Bus mit 320 Mbit/s |
8.400 E/A 33,600 KB/s (32,8 MB/s) |
|||
| Nach dem Hinzufügen schnellerer Festplatten bleibt der Datenträger der Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 4 KB Blockgröße 15.000 U/min-HD Upgrade auf einen SCSI-Bus mit 320 Mbit/s |
14.000 E/A 56.000 KB/s (54,7 Mbit/s) |
|||
| Nach dem Erhöhen der Blockgröße auf 32 KB wird der PCI-Bus zum Engpass. | Hinzufügen von 13 Datenträgern (Gesamtmenge=14) Hinzufügen eines zweiten SCSI-Adapters mit 14 Datenträgern E/A ist sequenziell 32 KB Blockgröße 15.000 U/min-HD Upgrade auf einen SCSI-Bus mit 320 Mbit/s |
14.000 E/A 448.000 KB/s (437 Mbit/s) ist der Grenzwert für Lese-/Schreibvorgänge für die Spindel. Der PCI-Bus unterstützt theoretisch maximal 133 Mbit/s (mit einer Effizienz von maximal 75 %). |
Einführung von RAID
Wenn Sie einen Arraycontroller in das Speichersubsystem einführen, ergeben sich keine erheblichen Änderungen. Der Arraycontroller ersetzt lediglich den SCSI-Adapter in den Berechnungen. Die Kosten für Lese- und Schreibvorgänge vom und zum Datenträger ändern sich jedoch abhängig von der verwendeten Arrayebene.
In RAID 0 werden Daten beim Schreiben über alle Festplatten im RAID-Satz verteilt. Während eines Lese- oder Schreibvorgangs liest das System Daten von jedem Datenträger oder schreibt Daten auf jeden Datenträger. Dies erhöht die Datenmenge, die das System während dieses bestimmten Zeitraums überträgt. Daher könnten in diesem Beispiel, in dem Laufwerke mit 10.000 U/min verwendet werden, 100 E/A-Anforderungen bei Verwendung von RAID 0 ausgeführt werden. Die Gesamtzahl der E/A-Anforderungen, die das System unterstützt, beträgt N Spindeln mal 100 E/A-Anforderungen pro Sekunde und Spindel bzw. N Spindeln × 100 E/A-Anforderungen pro Sekunde und Spindel.

Bei RAID 1 spiegelt oder dupliziert das System Daten über ein Spindelpaar, um Redundanz zu erzielen. Wenn das System einen E/A-Lesevorgang ausführt, kann es Daten von beiden Spindeln im Spindelsatz lesen. Aufgrund dieser Spiegelung sind während eines Lesevorgangs E/A-Kapazitäten für beide Festplatten verfügbar. RAID 1 bietet jedoch keine Leistungsvorteile für Schreibvorgänge, da das System die geschriebenen Daten im Spindelpaar auch spiegeln muss. Auch wenn die Spiegelung nicht dazu führt, dass Schreibvorgänge länger dauern, verhindert sie die gleichzeitige Ausführung von mehr als einem Schreibvorgang. Daher entspricht jeder E/A-Schreibvorgang den Kosten von zwei E/A-Lesevorgängen.
Mit der folgenden Formel kann berechnet werden, wie viele E/A-Vorgänge in diesem Szenario ausgeführt werden:
Lese-E/A + 2 × Schreib-E/A = Insgesamt verbrauchte verfügbare Datenträger-E/A
Wenn Sie das Verhältnis von Lesevorgängen zu Schreibvorgängen und die Anzahl der Spindeln in der Bereitstellung kennen, können Sie anhand dieser Gleichung die Zahl der E/A-Vorgänge berechnen, die Ihr Array unterstützen kann:
Maximale Zahl der IOPS-Vorgänge pro Spindel × 2 Spindeln × [(% Lesevorgänge + % Schreibvorgänge) ÷ (% Lesevorgänge + 2 × % Schreibvorgänge)] = Gesamtzahl der IOPS-Vorgänge
Ein Szenario, in dem sowohl RAID 1 als auch RAID 0 verwendet werden, verhält sich genau wie RAID 1 hinsichtlich der Kosten für Lese- und Schreibvorgänge. Die E/A wird jetzt jedoch auf alle Spiegelsätze verteilt. Das bedeutet, dass die Gleichung jetzt wie folgt aussieht:
Maximale Zahl der IOPS-Vorgänge pro Spindel × 2 Spindeln × [(% Lesevorgänge + % Schreibvorgänge) ÷ (% Lesevorgänge + 2 × % Schreibvorgänge)] = Gesamtzahl der E/A-Vorgänge
Wenn Sie in einem RAID 1-Satz ein Striping für N RAID 1-Sätze ausführen, kann Ihr Array pro RAID 1-Satz insgesamt N × E/A-Vorgänge verarbeiten:
N × {Maximale Zahl der IOPS-Vorgänge pro Spindel × 2 Spindeln × [(% Lesevorgänge + % Schreibvorgänge) ÷ (% Lesevorgänge + 2 × % Schreibvorgänge)]} = Gesamtzahl der IOPS-Vorgänge
Manchmal wird RAID 5 N + 1 aufgerufen, da das System ein Striping für die Daten über N Spindeln hinweg ausführt und Paritätsinformationen zur + 1 Spindel schreibt. RAID 5 verbraucht jedoch beim Ausführen von E/A-Schreibvorgängen mehr Ressourcen als RAID 1 oder RAID 1 + 0. RAID 5 führt den folgenden Prozess jedes Mal aus, wenn das Betriebssystem eine E/A-Schreibanforderung an das Array sendet:
- Lesen der alten Daten.
- Lesen der alten Parität.
- Schreiben der neuen Daten.
- Schreiben der neuen Parität.
Für jede E/A-Schreibanforderung, die das Betriebssystem an den Arraycontroller sendet, sind vier E/A-Vorgänge erforderlich. Daher benötigt eine N + 1 RAID-Schreibanforderung viermal mehr Zeit bis zum Abschluss als eine E/A-Leseanforderung. Anders ausgedrückt, verwenden Sie die folgende Gleichung, um zu ermitteln, wie viele E/A-Anforderungen des Betriebssystems wie vielen Anforderungen für die Spindeln entsprechen:
Lese-E/A + 4 × Schreib-E/A = Gesamt-E/A
In einem RAID 1-Satz, für den Sie das Verhältnis zwischen Lesevorgängen und Schreibvorgängen sowie die Zahl der Spindeln kennen, können Sie zur Ermittlung der Zahl der E/A-Vorgänge, die Ihr Array unterstützen kann, die folgende Gleichung verwenden:
IOPS-Vorgänge pro Spindel × (Spindeln – 1) × [(% Lesevorgänge + % Schreibvorgänge) ÷ (% Lesevorgänge + 4 × % Schreibvorgänge)] = Gesamtzahl der IOPS-Vorgänge
Hinweis
Das Ergebnis der vorherigen Gleichung berücksichtigt nicht das Laufwerk, das an die Parität verloren geht.
Einführung von SANs
Wenn Sie ein Storage Area Network (SAN) in Ihre Umgebung einführen, hat dies keine Auswirkungen auf die Planungsgrundsätze, die in den vorherigen Abschnitten beschrieben wurden. Sie sollten jedoch berücksichtigen, dass das SAN das E/A-Verhalten aller mit ihm verbundenen Systeme ändern kann. Zu den Hauptvorteilen eines SAN gehört, dass es Ihnen mehr Redundanz in Bezug auf intern oder extern angefügten Speicher bietet. Das bedeutet jedoch auch, dass Sie bei der Kapazitätsplanung den Fehlertoleranzbedarf berücksichtigen müssen. Wenn Sie mehr Komponenten in Ihr System einführen, müssen Sie diese neuen Komponenten auch bei Ihren Berechnungen berücksichtigen.
Dies sind die Komponenten eines SAN:
- Die SCSI- oder Fibre Channel-Laufwerk
- Das Backplane des Kanals der Speichereinheit
- Die Speichereinheiten selbst
- Das Speichercontrollermodul
- Ein oder mehrere SAN-Switches
- Ein oder mehrere Hostbusadapter (HBAs)
- Der Peripheral Component Interconnect (PCI)-Bus
Wenn Sie ein System im Hinblick auf Redundanz entwerfen, müssen Sie zusätzliche Komponenten verwenden, um sicherzustellen, dass Ihr System auch in Krisenszenarien funktioniert, in denen mindestens eine der ursprünglichen Komponenten nicht mehr funktioniert. Wenn Sie die Kapazität planen, müssen Sie diese redundanten Komponenten jedoch aus den verfügbaren Ressourcen ausschließen, um eine genaue Schätzung der Grundkapazität Ihres Systems zu erhalten, da diese Komponenten in der Regel nur in Notfällen online sind. Wenn Ihr SAN beispielsweise über zwei Controllermodule verfügt, müssen Sie bei der Berechnung des insgesamt verfügbaren E/A-Durchsatzes nur ein Modul berücksichtigen, da das zweite Modul nur dann aktiv ist, wenn das erste Modul nicht mehr funktioniert. Außerdem sollten Sie bei der E/A-Berechnung keine redundanten SAN-Switches, Speichereinheiten oder Spindeln berücksichtigen.
Da Sie bei der Kapazitätsplanung nur Zeiträume mit Spitzenauslastungen berücksichtigen, sollten Sie redundante Komponenten auch nicht als verfügbare Ressourcen zählen. Die Spitzenauslastung sollte 80 % der Kapazität des Systems nicht überschreiten, um Reserven für Bursts oder andere ungewöhnliche Verhaltensweisen des Systems zu schaffen.
Bei der Analyse des Verhaltens des SCSI- oder Fibre Channel-Laufwerks sollten Sie die Grundsätze anwenden, die in den vorherigen Abschnitten beschrieben wurden. Auch wenn jedes Protokoll seine eigenen Vor- und Nachteile hat, sind die mechanisch bedingten Einschränkungen der Festplatte der Hauptfaktor, der die Leistung der Festplatte begrenzt.
Bei der Analyse des Speichereinheitenkanals sollten Sie den gleichen Ansatz anwenden, den Sie auch für die Berechnung der Zahl der verfügbaren Ressourcen im SCSI-Bus angewendet haben: Teilen Sie die Bandbreite durch die Blockgröße. Wenn Ihre Speichereinheit beispielsweise sechs Kanäle besitzt, die jeweils eine maximale Übertragungsrate von 20 Mbit/s unterstützen, beträgt die verfügbare Übertragungsrate für E/A- und Datenübertragungsvorgänge insgesamt 100 Mbit/s. Die verfügbare Übertragungsrate beträgt 100 Mbit/s und nicht 120 Mbit/s, weil der Gesamtdurchsatz des Speicherkanals nicht den Durchsatz überschreiten sollte, der verfügbar ist, wenn ein Kanal plötzlich deaktiviert wird und nur fünf Kanäle funktionieren. Natürlich wird in diesem Beispiel auch davon ausgegangen, dass das System Auslastung und Fehlertoleranz gleichmäßig über alle Kanäle verteilt.
Ob Sie das vorherige Beispiel in ein E/A-Profil umwandeln können, ist vom Anwendungsverhalten abhängig. Für Active Directory-Jet-E/A-Vorgänge beträgt der maximale Wert ungefähr 12.500 E/A-Vorgänge pro Sekunde bzw. 100 Mbit/s ÷ 8 KB pro E/A-Vorgang.
Die Herstellerspezifikationen geben Auskunft über den Durchsatz, den Ihre Controllermodulen jeweils unterstützen. In diesem Beispiel verfügt das SAN über zwei Controllermodule, die jeweils 7.500 E/A-Vorgänge unterstützen. Wenn Ihr System nicht auf Redundanz ausgelegt ist, würde der gesamte Systemdurchsatz 15.000 IOPS betragen. In einem Szenario, das Redundanz erfordert, würden Sie den maximalen Durchsatz basierend auf den Grenzwerten nur eines der Controller berechnen, d. h. basierend auf 7.500 IOPS. Unter der Annahme, dass die Blockgröße 4 KB beträgt, liegt dieser Schwellenwert deutlich unter dem Maximum von 12.500 IOPS, das die Speicherkanäle unterstützen können. Daher stellt der Controllerdurchsatz in Ihrer Analyse den Engpass dar. Für Planungszwecke sollten Sie den maximalen Wert für E/A-Vorgänge jedoch auf 10.400 E/A-Vorgänge festlegen.
Wenn die Daten das Controllermodul verlassen, werden sie über eine Fibre Channel-Verbindung mit einer Nennleistung von 1 Gbit/s bzw. 128 Mbit/s übertragen. Da dieser Wert höher als die Gesamtbandbreite von 100 Mbit/s für alle Speichereinheitenkanäle ist, stellt die Fibre Channel-Verbindung keinen Engpass dar. Da diese Übertragung jedoch aus Redundanzgründen nur über einen der beiden Fibre Channels ausgeführt wird, verfügt der verbleibende Fibre Channel auch über genügend Kapazität, um die Datenübertragungsanforderung zu bewältigen.
Die Daten werden anschließend auf dem Weg zum Server über einen SAN-Switch geleitet. Der Switch begrenzt die Menge der E/A-Vorgänge, die verarbeitet werden können, da er die eingehenden Anforderungen verarbeiten und dann an den richtigen Port weiterleiten muss. Sie können den Grenzwert für den SAN-Switch jedoch nur anhand der Herstellerspezifikationen ermitteln. Wenn Ihr System beispielsweise über zwei Switches verfügt und jeder Switch 10.000 IOPS verarbeiten kann, beträgt der Gesamtdurchsatz 20.000 IOPS. Basierend auf den Regeln für die Fehlertoleranz beträgt der Gesamtdurchsatz des Systems 10.000 IOPS, wenn ein Switch nicht mehr funktioniert. Daher sollten Sie unter normalen Umständen nicht für mehr als 80 % Auslastung bzw. 8.000 E/A-Vorgänge planen.
Schließlich schränkt der im Server installierte Hostbusadapter (HBA) die Zahl der verarbeitbaren E/A-Vorgänge ebenfalls ein. In der Regel installieren Sie aus Redundanzgründen einen zweiten HBA. Wie beim SAN-Switch beträgt der E/A-Durchsatz, den das System insgesamt verarbeiten kann, jedoch N – 1 HBA.
Überlegungen zur Zwischenspeicherung
Caches gehören zu den Komponenten, die sich erheblich auf die Gesamtleistung des Speichersystems auswirken können. Eine detaillierte Analyse von Cachingalgorithmen liegt jedoch außerhalb des Umfangs dieses Artikels. Wir geben Ihnen stattdessen eine kurze Übersicht darüber, was Sie über das Caching auf Datenträgersubsystemen wissen sollten.
- Das Caching verbessert sequenzielle E/A-Schreibvorgänge, da viele kleinere Schreibvorgänge zu größeren E/A-Blöcken zusammengefasst werden. Außerdem werden Vorgänge in wenigen großen Blöcken statt in vielen winzigen Blöcken gespeichert. Da diese Optimierung die Zahl der zufälligen und sequenziellen E/A-Vorgänge reduziert, sind mehr Ressourcen für andere E/A-Vorgänge verfügbar.
- Das Caching verbessert jedoch nicht den dauerhaften Durchsatz für E/A-Schreibvorgänge im Speichersubsystem, da die Schreibvorgänge nur solange zwischengespeichert werden, bis Spindeln zum Speichern der Daten verfügbar sind. Wenn alle verfügbaren E/A-Kapazitäten der Spindeln über einen längeren Zeitraum mit Daten ausgelastet sind, füllt sich der Cache schließlich. Um den Cache zu leeren, müssen Sie genügend E/A-Kapazitäten für den Cache bereitstellen, um sich selbst zu leeren, indem Sie zusätzliche Spindeln bereitstellen oder dem System zwischen Bursts genügend Zeit bereitstellen, um aufzuholen.
- Größere Caches ermöglichen das Zwischenspeichern einer größeren Zahl von Daten. Das bedeutet, dass der Cache längere Zeiträume bewältigen kann, in denen die Kapazitäten der Spindeln ausgelastet sind.
- In typischen Speichersubsystemen verbessern Caches die Schreibleistung des Betriebssystems, da das System die Daten nur zum Cache schreiben muss. Sobald jedoch die E/A-Kapazitäten der zugrunde liegenden Medien ausgelastet sind, füllt sich der Cache, und die Schreibleistung kehrt zur regulären Datenträgergeschwindigkeit zurück.
- Wenn Sie E/A-Lesevorgänge zwischenspeichern, ist der Cache am nützlichsten, wenn Sie Daten sequenziell auf dem Datenträger speichern und dem Cache ein Read-Ahead gestatten. Ein Read-Ahead liegt vor, wenn sich der Cache sofort zum nächsten Sektor bewegen kann, als ob der nächste Sektor die Daten enthält, die das System als Nächstes anfordern wird.
- Bei zufälligen E/A-Lesevorgängen erhöht ein Caching im Laufwerkcontroller nicht die Menge der Daten, die der Datenträger lesen kann. Wenn der Betriebssystem- oder Anwendungscache größer als der Hardwarecache ist, kann die Lesegeschwindigkeit des Datenträgers nicht verbessert werden.
- In Active Directory wird der Cache nur durch die Menge an RAM begrenzt, über die das System verfügt.
Überlegungen zu SSD
Solid State Drives (SSDs) unterscheiden sich grundlegend von spindelbasierten Festplatten. SSDs können höhere Mengen an E/A-Vorgängen mit geringerer Latenz verarbeiten. Auch wenn SSDs auf einer Kosten-pro-Gigabyte-Basis teuer sein können, sind sie hinsichtlich der Kosten pro E/A-Vorgang sehr günstig. Bei der Kapazitätsplanung mit SSDs müssen Sie sich jedoch die gleichen Fragen stellen, die Sie auch bei spindelbasierten Festplatten stellen würden: Wie viele IOPS können sie verarbeiten und was ist die Latenz dieser IOPS?
Im Folgenden werden einige Punkte aufgelistet, die Sie bei der Planung mit SSDs berücksichtigen sollten:
- Sowohl die IOPS- als auch die Latenzwerte unterliegen den Herstellerdesigns. In einigen Fällen können bestimmte SSD-Designs eine schlechtere Leistung als spindelbasierte Technologien aufweisen. Bei der Entscheidung, ob Sie SSDs oder spindelbasierte Festplatten verwenden sollten, sollten Sie die Herstellerspezifikationen für jedes Laufwerk einzeln überprüfen und nicht davon ausgehen, dass alle Technologien auf ähnliche Weise funktionieren.
- IOPS-Typen können unterschiedliche Werte aufweisen, abhängig davon, ob es sich um Lesevorgänge oder um Schreibvorgänge handelt. AD DS-Dienste sind überwiegend lesebasiert. Daher hat die verwendete Schreibtechnologie im Vergleich zu anderen Anwendungsszenarien weniger starke Auswirkungen auf sie.
- Die Lebensdauer in Bezug auf Schreibvorgänge basiert auf der Annahme, dass SSD-Zellen eine begrenzte Lebensdauer haben und sich abnutzen, wenn sie viel verwendet werden. Bei Datenbanklaufwerken erweitert ein E/A-Profil, das überwiegend Lesevorgänge verarbeitet, die Lebensdauer in Bezug auf Schreibvorgänge bis zu einem Punkt, an dem Sie sich keine Gedanken mehr über die Lebensdauer in Bezug auf Schreibvorgänge machen müssen.
Zusammenfassung
Stellen Sie sich den Speicher als die internen Installationssysteme eines Hauses vor. Der IOPS-Wert der Medien, auf denen Sie Ihre Daten speichern, ist der Hauptabfluss des Hauses. Wenn der Hauptabfluss verstopft ist, hinsichtlich der Größe begrenzt ist oder ein Rohr kollabiert, stauen sich die Abwasser und die Installationssysteme des Hauses funktionieren nicht mehr ordnungsgemäß, wenn der Haushalt viel Wasser verbraucht. So wie in diesem Szenario verhält es sich mit einer freigegebenen Umgebung mit einem oder mehreren Systemen, die im selben SAN, NAS oder iSCSI einen Speicher mit denselben zugrunde liegenden Medien gemeinsam nutzen. Da die Benutzeranforderungen die Kapazitäten des Systems überschreiten, leidet die Leistung.
Ebenso können Sie in unserem imaginären Szenario verschiedene Ansätze verfolgen, um Verstopfungen und andere Leistungsprobleme zu beheben:
- Um ein Problem mit einem kollabierten oder zu kleinem Abflussrohr zu beheben, müssen Sie die Rohre durch funktionierende und ordnungsgemäß dimensionierte Rohre ersetzen. Bei einem freigegebenen Speicher entspricht dies dem Hinzufügen neuer Hardware oder der Neuverteilung der Auslastung auf den gemeinsam genutzten Systemen über die gesamte Infrastruktur.
- Die Behebung von Verstopfungen erfordert die Identifizierung der zugrunde liegenden Probleme und der Stellen, an denen diese Probleme vorliegen. Anschließend werden sie mit den entsprechenden Tools beseitigt. Zum Beispiel ist für die Beseitigung einer relativ einfachen Verstopfung eines Küchenspülenabflusses lediglich ein Saugkolben oder ein Abflussreiniger erforderlich. Komplexere Verstopfungen, an denen eingeschlossene Objekte beteiligt sind, erfordern möglicherweise die Verwendung einer Spirale zur Auflösung der Verstopfung. Ebenso hilft in einem Speichersystem, das gemeinsam genutzt wird, die Identifizierung der Ursache eines Leistungsproblems bei der Entscheidung, ob Sie eine Sicherung auf Systemebene erstellen, Antivirenscans auf allen Servern synchronisieren oder die Defragmentierungssoftware synchronisieren müssen, die Sie während Spitzenauslastungen ausführen.
Bei den meisten Installationsdesigns führen mehrere Abflüsse in den Hauptabfluss. Wenn ein Abfluss verstopft ist, staut sich das Wasser nur bis zu dem Punkt, an dem sich die Verstopfung befindet. Wenn ein Verbindungsteil verstopft ist, staut sich das Wasser in allen Abflüssen, die zu diesem Verbindungsteil führen. In einem Speicherszenario entspricht das verstopfte Verbindungsteil einem überlasteten Switch, einem Problem mit der Treiberkompatibilität oder nicht synchronisierten Softwareaufgaben. Sie müssen die IOPS- und E/A-Werte messen, um zu ermitteln, ob Ihr Speichersystem die Auslastung bewältigen kann, und dann das System wie erforderlich anpassen.
Anhang D: Problembehandlung für Speicher in Umgebungen, in denen mehr RAM keine Option ist
Zahlreiche Speicherempfehlungen vor der Einführung von virtualisierten Speichern erfüllten zwei Zwecke:
- Isolieren von E/A-Vorgängen, um zu verhindern, dass Leistungsprobleme für die Betriebssystemspindel die Leistung der Datenbank- und E/A-Profile beeinträchtigen.
- Nutzung der Leistungssteigerung, die spindelbasierte Festplatten und Caches Ihrem System bei Verwendung mit den sequenziellen E/A-Vorgängen von AD DS-Protokolldateien bieten können. Die Isolierung sequenzieller E/A-Vorgänge auf einem getrennten physischen Laufwerk kann den Durchsatz ebenfalls erhöhen.
Angesichts der neuen Speicheroptionen gelten jedoch viele der Annahmen nicht mehr, die früheren Speicherempfehlungen zugrunde lagen. In Szenarien mit virtualisierten Speichern, z. B. iSCSI-, SAN-, NAS- und Virtual Disk-Imagedateien, werden häufig Speichermedien auf mehreren Hosts gemeinsam genutzt. Daher müssen Sie E/A-Vorgänge nicht mehr isolieren und sequenzielle E/A-Vorgänge nicht mehr optimieren. Jetzt können andere Hosts, die auf die gemeinsam genutzten Medien zugreifen, die Reaktionsfähigkeit für den Domänencontroller reduzieren.
Bei der Kapazitätsplanung für die Speicherleistung sollten Sie drei Punkte berücksichtigen:
- Kalter Cache
- Warmer Cache
- Sichern und Wiederherstellen
Ein kalter Cache liegt anfänglich beim Neustart des Domänencontrollers oder Active Directory-Diensts vor, wenn sich keine Active Directory-Daten im RAM befinden. Ein warmer Cache liegt vor, wenn der Domänencontroller in einem stabilen Zustand ausgeführt wird und die Datenbank zwischengespeichert hat. Im Hinblick auf das Leistungsdesign ist die Befüllung eines kalten Cache mit zwischengespeicherten Daten einem Sprint vergleichbar, während die Ausführung eines Servers mit einem vollständig warmen Cache einem Marathon vergleichbar ist. Es ist wichtig, diese Zustände und ihre unterschiedlichen Leistungsprofile zu definieren, da Sie bei der Kapazitätsplanung beide Zustände berücksichtigen müssen. Wenn Sie beispielsweise über genügend RAM verfügen, um die gesamte Datenbank in einem warmen Cache zwischenzuspeichern, bedeutet das nicht, dass Sie die Leistung optimieren können, wenn der Cache kalt ist.
Bei beiden Cacheszenarien stellt die Geschwindigkeit, mit der der Speicher Daten vom Datenträger zum Arbeitsspeicher verschieben kann, den wichtigsten Faktor dar. Wenn der Cache mit Daten aufgefüllt wird, verbessert sich die Leistung über die Zeit, da Abfragen Daten wiederverwenden, die Cachetrefferrate steigt und die Häufigkeit abnimmt, mit der Daten vom Datenträger abgerufen werden. Infolgedessen werden auch die Leistungsnachteile reduziert, die durch den Abruf von Daten vom Datenträger entstehen. Alle Leistungsbeeinträchtigungen sind lediglich temporär und verschwinden in der Regel, wenn der Cache den warmen Zustand und die maximale Größe erreicht, den das System zulässt.
Sie können die Geschwindigkeit messen, mit der das System Daten vom Datenträger abrufen kann, indem Sie die verfügbaren IOPS in Active Directory messen. Die Zahl der verfügbaren IOPS ist auch davon abhängig, wie viele IOPS im zugrunde liegenden Speicher verfügbar sind. Da die Auffüllung des Cache (wie auch Sicherungen oder Wiederherstellungen) außergewöhnliche Ereignisse darstellen, die in der Regel außerhalb von Zeiten mit Spitzenauslastungen auftreten und der Auslastung des Domänencontrollers unterliegen, gibt es nicht viele allgemeine Empfehlungen außer der Empfehlung, diese Vorgänge nur außerhalb von Zeiten mit Spitzenauslastungen auszuführen.
In den meisten Szenarien verwendet AD DS überwiegend E/A-Lesevorgänge mit einem Verhältnis von 90 % Lesevorgängen zu 10 % Schreibvorgängen. E/A-Lesevorgänge stellen den typischen Engpass in der Benutzererfahrung dar, während E/A-Schreibvorgänge den Engpass bilden, der die Schreibleistung beeinträchtigt. Caches bieten tendenziell minimale Vorteile für E/A-Lesevorgänge, da E/A-Vorgänge für die Datei NTDS.dit überwiegend zufällig sind. Daher besteht Ihre Hauptpriorität in der korrekten Konfigurierung des Profilspeichers für E/A-Lesevorgänge.
Unter normalen Betriebsbedingungen besteht Ihr Ziel bei der Speicherplanung in der Minimierung der Wartezeiten, bis das System Anforderungen aus AD DS an den Datenträger zurückgibt. Die Anzahl der ausstehenden E/A-Vorgänge sollte kleiner oder gleich der Anzahl der Pfade auf dem Datenträger sein. In Leistungsüberwachungsszenarien empfehlen wir im Allgemeinen, dass der Zähler LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read kleiner als 20 ms sein sollte. Abhängig vom Speichertyp sollten Sie den Betriebsschwellenwert wesentlich niedriger und so nahe an der Speichergeschwindigkeit wie möglich festlegen (innerhalb eines Bereichs von zwei bis sechs Millisekunden).
Das folgende Liniendiagramm zeigt die Messung der Datenträgerlatenz innerhalb eines Speichersystems.
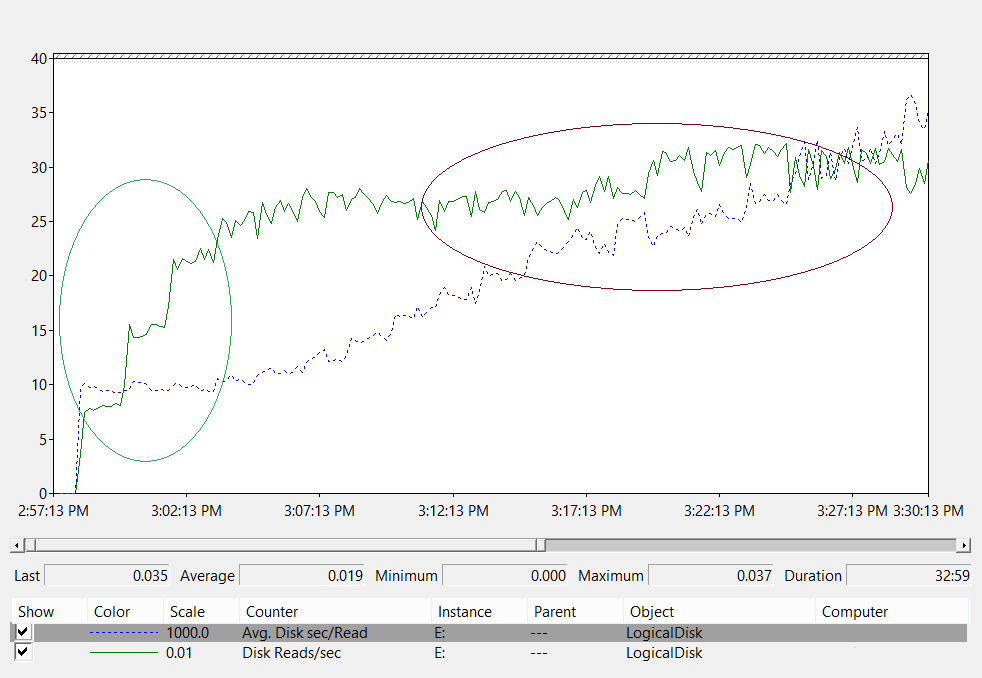
Analysieren wir dieses Liniendiagramm:
- Der Bereich auf der linken Seite des Diagramms, um den ein grüner Kreis gezeichnet ist, zeigt eine konsistente Latenz von 10 ms an, während die Auslastung von 800 IOPS auf 2.400 IOPS steigt. Dieser Bereich ist der Basiswert für die Geschwindigkeit, mit der der zugrunde liegende Speicher eine E/A-Anforderung verarbeiten kann. Dieser Basiswert ist jedoch von der Art der verwendeten Speicherlösung abhängig.
- Der Bereich auf der rechten Seite des Diagramms, um den ein rotbrauner Kreis gezeichnet ist, zeigt den Systemdurchsatz zwischen dem Basiswert und dem Ende der Datensammlung an. Der Durchsatz selbst ändert sich nicht, die Latenz steigt jedoch. Dieser Bereich zeigt, dass Anforderungen in der Warteschlange länger darauf warten, an das Speichersubsystem gesendet zu werden, wenn die Zahl der Anforderungen die physischen Grenzwerte des zugrunde liegenden Speichers überschreiten.
Lassen Sie uns nun überlegen, was diese Daten uns mitteilen.
Angenommen, die Abfrage eines Benutzers, mit der die Mitgliedschaft einer großen Gruppe abgefragt wird, erfordert zunächst, dass das System 1 MB Daten vom Datenträger liest. Sie können die erforderliche Zahl der E/A-Vorgänge und die Dauer der Vorgänge anhand dieser Werte evaluieren:
- Die Größe jeder Active Directory-Datenbankseite beträgt 8 KB.
- Die Mindestanzahl der Seiten, die das System lesen muss, beträgt 128.
- Daher sollte das System im Basisbereich, der im Diagramm gezeigt wird, mindestens 1,28 Sekunden benötigen, um die Daten vom Datenträger zu laden und an den Client zurückzugeben. Bei der Marke von 20 ms, bei der der Durchsatz deutlich über dem empfohlenen Maximum liegt, dauert der Prozess 2,5 Sekunden.
Basierend auf diesen Zahlen können Sie anhand der folgenden Gleichung berechnen, wie schnell der Cache mit Daten gefüllt wird:
2.400 IOPS × 8 KB pro E/A-Vorgang
Nach der Ausführung dieser Berechnung können wir sagen, dass die Auffüllungsrate für den Cache in diesem Szenario 20 Mbit/s beträgt. Mit anderen Worten, das System lädt alle 53 Sekunden ungefähr 1 GB der Datenbank in den RAM.
Hinweis
Es ist normal, dass die Latenz für kurze Zeiträume steigt, während aggressiv vom Datenträger gelesen oder zum Datenträger geschrieben wird. Beispielsweise steigt die Latenz, wenn das System gesichert wird oder AD DS eine Garbage Collection ausführt. Sie sollten zusätzlich zu den ursprünglichen Auslastungsschätzungen weitere Reserven für diese regelmäßigen Ereignisse bereitstellen. Ihr Ziel besteht darin, ausreichend Durchsatz zur Bewältigung dieser Spitzenauslastungen bereitzustellen, ohne dass sich dies auf die Gesamtfunktion auswirkt.
Es gibt ein physisches Limit für die Auffüllung des Cache, das vom Design des Speichersystems abhängig ist. Der Cache kann nur durch eingehende Clientanforderungen die Geschwindigkeit erreichen, die der zugrunde liegende Speicher verarbeiten kann. Die Ausführung von Skripts während Zeiten mit Spitzenauslastungen, um den Cache vorab mit Daten auszufüllen, konkurriert mit echten Clientanforderungen, erhöht die Gesamtauslastung, lädt Daten, die für die Clientanforderungen nicht relevant sind, und beeinträchtigt die Leistung. Es wird empfohlen, künstliche Maßnahmen zur Auffüllung des Cache mit Daten zu vermeiden.