Trainieren Ihres Bildklassifizierungsmodells mit PyTorch
Hinweis
Für eine größere Funktionalität kann PyTorch auch mit DirectML unter Windows verwendet werden.
In der vorherigen Phase dieses Tutorials haben wir das Dataset erhalten, das wir zum Trainieren unserer Bildklassifizierung mit PyTorch verwenden. Nun ist es an der Zeit, diese Daten zu verwenden.
Um die Bildklassifizierung mit PyTorch zu trainieren, müssen Sie die folgenden Schritte ausführen:
- Laden Sie die Daten. Wenn Sie den vorherigen Schritt dieses Tutorials abgeschlossen haben, haben Sie dies bereits erledigt.
- Definieren Sie ein neuronales Konvolutionsnetzwerk (Convolution Neural Network, CNN).
- Definieren Sie eine Verlustfunktion.
- Trainieren Sie das Modell anhand der Trainingsdaten.
- Testen Sie das Netzwerk mit den Testdaten.
Definieren Sie ein neuronales Konvolutionsnetzwerk (Convolution Neural Network, CNN).
Zum Erstellen eines neuronalen Netzwerks mit PyTorch verwenden Sie das torch.nn-Paket. Dieses Paket enthält Module, erweiterbare Klassen und alle erforderlichen Komponenten zum Erstellen neuronaler Netzwerke.
Hier erstellen Sie ein einfaches neuronales Konvolutionsnetzwerk, um die Bilder aus dem CIFAR10-Dataset zu klassifizieren.
Ein CNN ist eine Klasse neuronaler Netzwerke, die als neuronale Netzwerke mit mehreren Ebenen definiert sind, die entwickelt wurden, um komplexe Merkmale in Daten zu erkennen. Sie werden am häufigsten in Anwendungen für maschinelles Sehen verwendet.
Unser Netzwerk wird mithilfe der folgenden 14 Ebenen strukturiert:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
Konvolutionsebene
Die Konvolutionsebene ist eine Hauptebene des CNN, mit der wir Merkmale in Bildern erkennen können. Jede der Ebenen verfügt über eine Anzahl von Kanälen, um bestimmte Merkmale in Bildern zu erkennen, und über eine Reihe von Kerneln, um die Größe des erkannten Merkmals zu definieren. Aus diesem Grund würde eine Konvolutionsebene mit 64 Kanälen und einer Kernelgröße von 3 x 3 entsprechend 64 unterschiedliche Merkmale erkennen, die jeweils 3 x 3 groß sind. Wenn Sie eine Konvolutionsebene definieren, geben Sie die Anzahl der Kanäle, die Anzahl der ausgehenden Kanäle und die Kernelgröße an. Die Anzahl der ausgehenden Kanäle in der Ebene dient als Anzahl der eingehenden Kanäle für die nächste Ebene.
Beispiel: Eine Konvolutionsebene mit drei eingehenden Kanälen, zehn ausgehenden Kanälen und einer Kernelgröße von 6 erhält das RGB-Bild (drei Kanäle) als Eingabe und wendet zehn Merkmalserkennungen auf die Bilder mit der Kernelgröße 6 x 6 an. Kleinere Kernelgrößen verringern die Berechnungszeit und die Gewichtungsfreigabe.
Andere Ebenen
Die folgenden anderen Ebenen sind in unser Netzwerk einbezogen:
- Die Ebene
ReLUist eine Aktivierungsfunktion, um alle eingehenden Merkmale auf 0 oder höher festzulegen. Wenn Sie diese Ebene anwenden, wird jede Zahl kleiner als Null in Null geändert, während andere Zahlen gleich bleiben. - Die Ebene
BatchNorm2dwendet die Normalisierung auf die Eingaben an, um Null Mittelwert- und Einheitenvarianz zu haben und die Netzwerkgenauigkeit zu erhöhen. - Die
MaxPool-Ebene hilft uns sicherzustellen, dass die Position eines Objekts in einem Bild die Fähigkeit des neuronalen Netzwerks, seine spezifischen Merkmale zu erkennen, nicht beeinträchtigt. - Die
Linear-Ebene ist die letzte Ebene in unserem Netzwerk, die die Bewertungen der einzelnen Klassen berechnet. Im CIFAR10-Dataset gibt es zehn Klassen von Bezeichnungen. Die Bezeichnung mit der höchsten Bewertung ist diejenige, die das Modell vorhersagt. Auf der linearen Ebene müssen Sie die Anzahl der Eingabemerkmale und die Anzahl der Ausgabemerkmale angeben, die der Anzahl der Klassen entsprechen sollen.
Wie funktioniert ein neuronales Netzwerk?
Das CNN ist ein Feedforward-Netzwerk. Während des Trainings verarbeitet das Netzwerk die Eingabe über alle Ebenen, berechnet den Verlust, um zu verstehen, wie weit die vorhergesagte Bezeichnung des Bilds von der richtigen abweicht, und gibt die Abstufungen zurück an das Netzwerk, um die Gewichtungen der Ebenen zu aktualisieren. Durch die Iteration über ein großes Dataset von Eingaben „lernt“ das Netzwerk, seine Gewichtungen festzulegen, um die besten Ergebnisse zu erzielen.
Eine Vorwärtsfunktion (Forward) berechnet den Wert der Verlustfunktion, und die Rückwärtsfunktion (Backward) berechnet die Abstufungen der erlernbaren Parameter. Wenn Sie unser neuronales Netzwerk mit PyTorch erstellen, müssen Sie nur die Vorwärtsfunktion definieren. Die Rückwärtsfunktion wird automatisch definiert.
- Kopieren Sie den folgenden Code in die
PyTorchTraining.py-Datei in Visual Studio, um das CCN zu definieren.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Hinweis
Möchten Sie mehr über neuronale Netzwerke mit PyTorch erfahren? Sehen Sie sich die PyTorch-Dokumentation an.
Definieren einer Verlustfunktion
Eine Verlustfunktion berechnet einen Wert, der schätzt, wie weit die Ausgabe vom Ziel entfernt ist. Das Hauptziel besteht darin, den Wert der Verlustfunktion zu reduzieren, indem die Gewichtungsvektorwerte durch Rückpropagierung in neuronalen Netzwerken geändert werden.
Der Verlustwert unterscheidet sich von der Modellgenauigkeit. Die Verlustfunktion gibt uns Aufschluss darüber, wie gut sich ein Modell nach jeder Iteration der Optimierung für den Trainingssatz verhält. Die Genauigkeit des Modells wird anhand der Testdaten berechnet und zeigt den Prozentsatz der richtigen Vorhersage an.
In PyTorch enthält das neuronale Netzwerkpaket verschiedene Verlustfunktionen, die die Bausteine von Deep Neural Networks bilden. In diesem Tutorial verwenden Sie eine Klassifizierungsverlustfunktion, die auf „Definieren der Verlustfunktion mit klassifizierungsübergreifendem Entropieverlust“ und einem Adam-Optimierer basiert. Die Lernrate (Learning Rate, lr) legt fest, wie stark Sie die Gewichtungen unseres Netzwerks in Bezug auf den Verlustgradienten anpassen. Sie legen ihn auf 0,001 fest. Je niedriger der Wert ist, desto langsamer ist das Training.
- Kopieren Sie den folgenden Code in die Datei
PyTorchTraining.pyin Visual Studio, um die Verlustfunktion und einen Optimierer zu definieren.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Trainieren Sie das Modell anhand der Trainingsdaten.
Um das Modell zu trainieren, müssen Sie eine Schleife über unseren Dateniterator ausführen, die Eingaben an das Netzwerk übergeben und optimieren. PyTorch verfügt nicht über eine dedizierte Bibliothek für die GPU-Verwendung, aber Sie können das Ausführungsgerät manuell definieren. Das Gerät ist eine Nvidia-GPU, wenn sie auf Ihrem Computer vorhanden ist, oder Ihre CPU, wenn dies nicht der Fall ist.
- Fügen Sie der
PyTorchTraining.py-Datei den folgenden Code hinzu.
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Testen Sie das Modell anhand der Testdaten.
Jetzt können Sie das Modell mit einem Batch von Bildern aus unserem Testsatz testen.
- Fügen Sie der Datei
PyTorchTraining.pyden folgenden Code hinzu.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Abschließend fügen wir den Hauptcode hinzu. Dadurch wird das Modelltraining gestartet, das Modell gespeichert und die Ergebnisse auf dem Bildschirm angezeigt. Wir führen nur zwei Iterationen [train(2)] mit dem Trainingssatz durch, sodass der Trainingsprozess nicht zu lange dauern wird.
- Fügen Sie der Datei
PyTorchTraining.pyden folgenden Code hinzu.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Führen wir den Test durch! Stellen Sie sicher, dass die Dropdownmenüs in der oberen Symbolleiste auf „Debuggen“ festgelegt sind. Ändern Sie die Projektmappenplattform in x64, um das Projekt auf dem lokalen Computer auszuführen, wenn es sich um ein 64-Bit-Gerät handelt, oder in x86 für einen 32-Bit-Computer.
Wenn Sie für die Epochenzahl (die Anzahl der vollständigen Durchläufe durch das Trainingsdataset) den Wert „2“ ([train(2)]) wählen, wird zweimal durch das gesamte Testdataset mit 10.000 Bildern iteriert. Es dauert ungefähr 20 Minuten, bis das Training auf der Intel-CPU der 8. Generation abgeschlossen ist, und das Modell sollte bei der Klassifizierung von zehn Bezeichnungen eine Erfolgsquote von etwa 65 % erreichen.
- Klicken Sie zum Ausführen des Projekts auf der Symbolleiste auf die Schaltfläche „Debuggen starten“, oder drücken Sie F5.
Das Konsolenfenster wird geöffnet, und Sie können den Trainingsprozess sehen.
Wie Sie definiert haben, wird der Verlustwert alle 1.000 Bilderbatches oder fünfmal für jede Iteration über den Trainingssatz ausgegeben. Sie erwarten, dass der Verlustwert mit jeder Schleife abnimmt.
Sie sehen auch die Genauigkeit des Modells nach jeder Iteration. Die Modellgenauigkeit unterscheidet sich vom Verlustwert. Die Verlustfunktion gibt uns Aufschluss darüber, wie gut sich ein Modell nach jeder Iteration der Optimierung für den Trainingssatz verhält. Die Genauigkeit des Modells wird anhand der Testdaten berechnet und zeigt den Prozentsatz der richtigen Vorhersage an. In unserem Fall wird sie uns vermitteln, wie viele Bilder aus dem 10.000 Bilder umfassenden Testsatz unser Modell nach jeder Trainingsiteration richtig klassifizieren konnte.
Sobald das Training abgeschlossen ist, sollten Sie eine Ausgabe ähnlich der nachfolgenden erwarten. Ihre Zahlen werden nicht genau gleich sein. Das Training hängt von vielen Faktoren ab und wird nicht immer identische Ergebnisse liefern, aber sie sollten ähnlich aussehen.
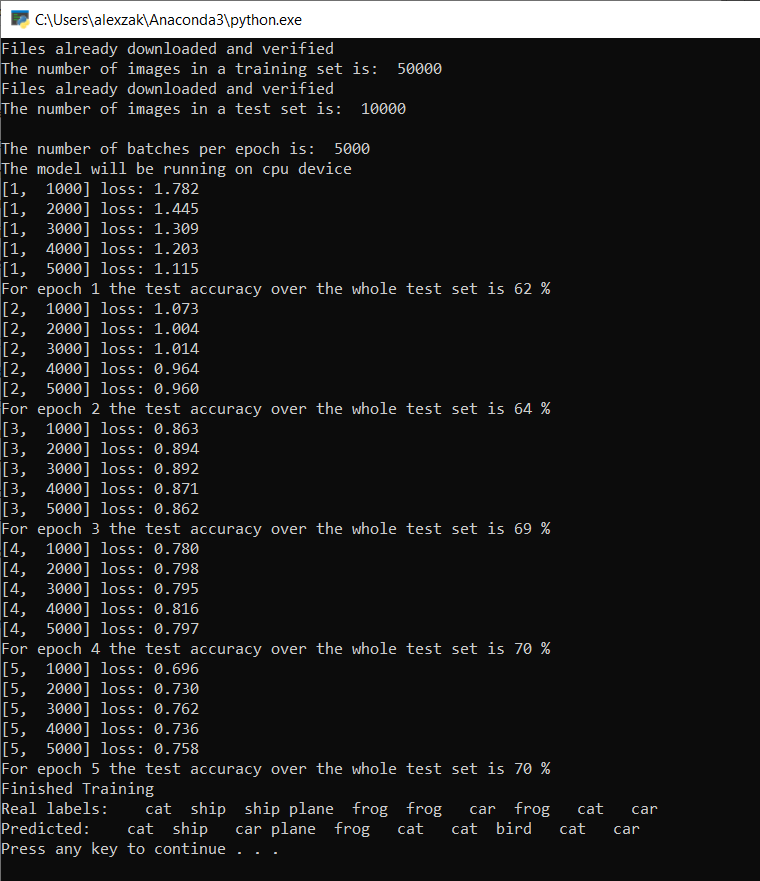
Nach nur fünf Epochen beträgt die Erfolgsrate des Modells 70 %. Dies ist ein gutes Ergebnis für ein einfaches Modell, das für kurze Zeit trainiert wurde!
Beim Testen mit dem Bilderbatch hat das Modell genau sieben Bilder aus dem zehn Bilder umfassenden Batch richtig erkannt. Gar nicht schlecht und konsistent mit der Erfolgsquote des Modells.

Sie können überprüfen, welche Klassen unser Modell am besten vorhersagen kann. Fügen Sie einfach den folgenden Code hinzu und führen Sie ihn aus:
- Optional: Fügen Sie der Datei
PyTorchTraining.pydie folgendetestClassess-Funktion hinzu, und fügen Sie einen Aufruf dieser FunktiontestClassess()in der Hauptfunktion (main)__name__ == "__main__"hinzu.
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
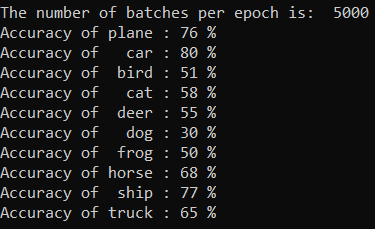
Die Ausgabe lautet wie folgt:
Nächste Schritte
Nachdem wir nun über ein Klassifizierungsmodell verfügen, besteht der nächste Schritt darin, das Modell in das ONNX-Format zu konvertieren.