Exakte Profilerstellung für Direct3D-API-Aufrufe (Direct3D 9)
- Die genaue Profilerstellung von Direct3D ist schwierig
- Genaues Profilieren einer Direct3D-Rendersequenz
- Profilerstellung von Direct3D-Zustandsänderungen
- Zusammenfassung
- Anhang
Sobald Sie über eine funktionsfähige Microsoft Direct3D-Anwendung verfügen und ihre Leistung verbessern möchten, verwenden Sie in der Regel ein standardfähiges Profilerstellungstool oder eine benutzerdefinierte Messtechnik, um die Zeit zu messen, die zum Ausführen eines oder mehrerer API-Aufrufe (Application Programming Interface, API) benötigt wird. Wenn Sie dies getan haben, aber Zeitliche Ergebnisse erhalten, die von einer Rendersequenz zur nächsten variieren, oder Wenn Sie Hypothesen erstellen, die den tatsächlichen Experimentergebnissen nicht standhalten, können Sie anhand der folgenden Informationen verstehen, warum.
Die hier bereitgestellten Informationen basieren auf der Annahme, dass Sie Über Kenntnisse und Erfahrungen mit den folgenden Informationen verfügen:
- C/C++-Programmierung
- Direct3D-API-Programmierung
- Messen des API-Timings
- Das Video Karte und dessen Softwaretreiber
- Mögliche unerklärliche Ergebnisse aus früheren Profilerstellungserfahrungen
Die genaue Profilerstellung von Direct3D ist schwierig
Ein Profiler berichtet über die Zeit, die für jeden API-Aufruf aufgewendet wird. Dies geschieht, um die Leistung zu verbessern, indem Hot Spots gefunden und abgesenkt werden. Es gibt verschiedene Arten von Profilern und Profilerstellungstechniken.
- Ein Sampling-Profiler befindet sich einen Großteil der Zeit im Leerlauf und weckt in bestimmten Intervallen, um die ausgeführten Funktionen zu samplen (oder aufzuzeichnen). Es gibt den Prozentsatz der Zeit zurück, die in jedem Aufruf aufgewendet wurde. Im Allgemeinen ist ein Sampling-Profiler nicht sehr invasiv für die Anwendung und hat minimale Auswirkungen auf den Aufwand für die Anwendung.
- Ein Instrumentierungsprofiler misst die tatsächliche Zeit, die bis zum Zurückgeben eines Aufrufs benötigt wird. Dies erfordert das Kompilieren von Start- und Stopptrennzeichen in einer Anwendung. Ein Instrumentierungsprofiler ist für eine Anwendung vergleichsweise invasiver als ein Samplingprofiler.
- Es ist auch möglich, ein benutzerdefiniertes Profilerstellungsverfahren mit einem leistungsstarken Timer zu verwenden. Dies führt zu Ergebnissen, die einem Instrumentierungsprofiler ähneln.
Die Art der verwendeten Profiler- oder Profilerstellungstechnik ist nur ein Teil der Herausforderung, genaue Messungen zu generieren.
Die Profilerstellung gibt Ihnen Antworten, die Ihnen helfen, die Leistung zu budgetieren. Angenommen, Sie wissen für instance, dass ein API-Aufruf durchschnittlich tausend Taktzyklen für die Ausführung aufweist. Sie können einige Schlussfolgerungen zur Leistung geltend machen, z. B. die folgenden:
- Eine 2-GHz-CPU (die 50 Prozent ihrer Zeit für das Rendern aufwendet) ist auf den Aufruf dieser API 1 Million Mal pro Sekunde beschränkt.
- Um 30 Frames pro Sekunde zu erzielen, können Sie diese API nicht mehr als 33.000 Mal pro Frame aufrufen.
- Sie können nur 3,3K-Objekte pro Frame rendern (vorausgesetzt, 10 dieser API-Aufrufe für die Rendersequenz jedes Objekts).
Mit anderen Worten, wenn Sie genügend Zeit pro API-Aufruf hatten, könnten Sie eine Budgetierungsfrage beantworten, z. B. die Anzahl der Primitiven, die interaktiv gerendert werden können. Die von einem Instrumentierungsprofiler zurückgegebenen Rohzahlen beantworten die Budgetierungsfragen jedoch nicht richtig. Dies liegt daran, dass die Grafikpipeline komplexe Entwurfsprobleme aufweist, z. B. die Anzahl der Komponenten, die arbeiten müssen, die Anzahl der Prozessoren, die steuern, wie der Arbeitsfluss zwischen Komponenten erfolgt, und Optimierungsstrategien, die in der Laufzeit und in einem Treiber implementiert werden, die entwickelt wurden, um die Pipeline effizienter zu machen.
Jeder API-Aufruf durchläuft mehrere Komponenten
Jeder Aufruf wird von mehreren Komponenten auf dem Weg von der Anwendung zum Video Karte verarbeitet. Betrachten Sie für instance die folgende Rendersequenz, die zwei Aufrufe zum Zeichnen eines einzelnen Dreiecks enthält:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
Das folgende konzeptionelle Diagramm zeigt die verschiedenen Komponenten, über die die Aufrufe übergeben müssen.

Die Anwendung ruft Direct3D auf, das die Szene steuert, Benutzerinteraktionen verarbeitet und bestimmt, wie das Rendering ausgeführt wird. All diese Arbeit wird in der Rendersequenz angegeben, die mithilfe von Direct3D-API-Aufrufen an die Runtime gesendet wird. Die Rendersequenz ist praktisch hardwareunabhängig (das heißt, die API-Aufrufe sind hardwareunabhängig, aber eine Anwendung hat Kenntnisse darüber, welche Features ein Video Karte unterstützt).
Die Runtime konvertiert diese Aufrufe in ein geräteunabhängiges Format. Die Runtime übernimmt die gesamte Kommunikation zwischen der Anwendung und dem Treiber, sodass eine Anwendung auf mehr als einem kompatiblen Hardwarestück ausgeführt wird (abhängig von den erforderlichen Features). Beim Messen eines Funktionsaufrufs misst ein Instrumentierungsprofiler die Zeit, die er in einer Funktion verbracht hat, sowie die Zeit für die Rückgabe der Funktion. Eine Einschränkung eines Instrumentierungsprofilers besteht darin, dass er möglicherweise nicht die Zeit enthält, die ein Treiber benötigt, um die resultierende Arbeit an das Video Karte zu senden, noch die Zeit, in der das Video Karte, um die Arbeit zu verarbeiten. Anders ausgedrückt: Ein Standardinstrumentierungsprofiler kann nicht die gesamte Arbeit zuordnen, die jedem Funktionsaufruf zugeordnet ist.
Der Softwaretreiber verwendet hardwarespezifische Kenntnisse über die Video-Karte, um die geräteunabhängigen Befehle in eine Sequenz von Video-Karte-Befehlen zu konvertieren. Treiber können auch die Reihenfolge der Befehle optimieren, die an das Video Karte gesendet werden, sodass das Rendern auf dem Video Karte effizient erfolgt. Diese Optimierungen können Profilerstellungsprobleme verursachen, da der Umfang der geleisteten Arbeit nicht dem entspricht, was sie zu sein scheint (Möglicherweise müssen Sie die Optimierungen verstehen, um sie zu berücksichtigen). Der Treiber gibt in der Regel die Steuerung an die Laufzeit zurück, bevor das Video Karte die Verarbeitung aller Befehle abgeschlossen hat.
Das Video Karte den Großteil des Renderings durch Kombinieren von Daten aus vertex- und Indexpuffern, Texturen, Renderzustandsinformationen und Grafikbefehlen. Wenn das Rendern des Videos Karte abgeschlossen ist, ist die arbeit, die aus der Rendersequenz erstellt wurde, abgeschlossen.
Jeder Direct3D-API-Aufruf muss von jeder Komponente (runtime, treiber und video Karte) verarbeitet werden, um alles zu rendern.
Es gibt mehrere Prozessoren, die die Komponenten steuern
Die Beziehung zwischen diesen Komponenten ist noch komplexer, da die Anwendung, die Laufzeit und der Treiber von einem Prozessor gesteuert werden und die Video-Karte von einem separaten Prozessor gesteuert wird. Das folgende Diagramm zeigt zwei Arten von Prozessoren: eine zentrale Verarbeitungseinheit (CPU) und eine Grafikverarbeitungseinheit (GPU).
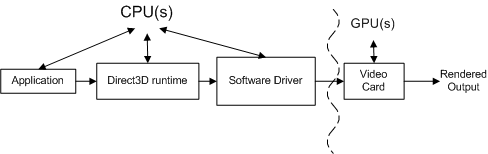
PC-Systeme verfügen über mindestens eine CPU und eine GPU, können aber mehr als eine von beiden oder beides haben. Die CPUs befinden sich auf der Hauptplatine, und die GPUs befinden sich entweder auf der Hauptplatine oder auf der Video-Karte. Die Geschwindigkeit der CPU wird durch einen Taktchip auf der Hauptplatine bestimmt, und die Geschwindigkeit der GPU wird durch einen separaten Taktchip bestimmt. Die CPU-Uhr steuert die Geschwindigkeit der Arbeit, die von der Anwendung, der Runtime und dem Treiber ausgeführt wird. Die Anwendung sendet Arbeit über die Runtime und den Treiber an die GPU.
CPU und GPU laufen in der Regel mit unterschiedlichen Geschwindigkeiten, unabhängig voneinander. Die GPU kann auf die Arbeit reagieren, sobald die Arbeit verfügbar ist (vorausgesetzt, die GPU hat die Verarbeitung vorheriger Arbeiten abgeschlossen). Die GPU-Arbeit erfolgt parallel zur CPU-Arbeit, wie durch die gekrümmte Linie in der obigen Abbildung hervorgehoben. Ein Profiler misst im Allgemeinen die Leistung der CPU, nicht der GPU. Dies macht die Profilerstellung schwierig, da die von einem Instrumentierungsprofiler durchgeführten Messungen die CPU-Zeit enthalten, aber möglicherweise nicht die GPU-Zeit.
Der Zweck der GPU besteht darin, die Verarbeitung von der CPU auf einen Prozessor zu laden, der speziell für Grafikarbeiten entwickelt wurde. Auf modernen Grafikkarten ersetzt die GPU einen Großteil der Transformations- und Beleuchtungsarbeiten in der Pipeline von der CPU zur GPU. Dadurch wird die CPU-Workload erheblich reduziert, sodass mehr CPU-Zyklen für andere Verarbeitungen verfügbar sind. Um eine grafische Anwendung auf Spitzenleistung zu optimieren, müssen Sie die Leistung der CPU und der GPU messen und die Arbeit zwischen den beiden Typen von Prozessoren ausgleichen.
Dieses Dokument behandelt keine Themen im Zusammenhang mit der Messung der Leistung der GPU oder dem Ausgleich der Arbeit zwischen CPU und GPU. Wenn Sie die Leistung einer GPU (oder eines bestimmten Video-Karte) besser verstehen möchten, besuchen Sie die Website des Anbieters, um weitere Informationen zur GPU-Leistung zu erhalten. Stattdessen konzentriert sich dieses Dokument auf die Arbeit der Runtime und des Treibers, indem die GPU-Arbeit auf eine vernachlässigbare Menge reduziert wird. Dies basiert teilweise auf Der Erfahrung, dass Anwendungen, bei denen Leistungsprobleme auftreten, in der Regel CPU-begrenzt sind.
Laufzeit- und Treiberoptimierungen können API-Messungen masken
Die Runtime verfügt über eine integrierte Leistungsoptimierung, die die Messung eines einzelnen Aufrufs überfordern kann. Hier sehen Sie ein Beispielszenario, das dieses Problem veranschaulicht. Betrachten Sie die folgende Rendersequenz:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Beispiel 1: Einfache Rendersequenz
Betrachtet man die Ergebnisse für die beiden Aufrufe in der Rendersequenz, könnte ein Instrumentierungsprofiler Ergebnisse wie die folgenden zurückgeben:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
Der Profiler gibt die Anzahl der CPU-Zyklen zurück, die zum Verarbeiten der mit jedem Aufruf verbundenen Arbeit erforderlich sind (denken Sie daran, dass die GPU in diesen Zahlen nicht enthalten ist, da die GPU noch nicht mit der Arbeit an diesen Befehlen begonnen hat). Da IDirect3DDevice9::D rawPrimitive fast eine Million Zyklen für die Verarbeitung erforderte, könnten Sie schließen, dass es nicht sehr effizient ist. Sie werden jedoch bald sehen, warum diese Schlussfolgerung falsch ist und wie Sie Ergebnisse generieren können, die für die Budgetierung verwendet werden können.
Das Messen von Zustandsänderungen erfordert sorgfältige Rendersequenzen
Alle anderen Aufrufe als IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive oder Clear (z. B . SetTexture, SetVertexDeclaration und SetRenderState) führen zu einer Zustandsänderung. Jede Zustandsänderung legt den Pipelinezustand fest, der steuert, wie das Rendering ausgeführt wird.
Optimierungen in der Runtime und/oder dem Treiber sind so konzipiert, dass das Rendering beschleunigt wird, indem der Aufwand reduziert wird. Im Folgenden sind einige Zustandsänderungsoptimierungen aufgeführt, die Profildurchschnitte belasten können:
- Ein Treiber (oder die Runtime) kann eine Zustandsänderung als lokaler Zustand speichern. Da der Treiber in einem "faulen" Algorithmus arbeiten könnte (die Arbeit aufschieben, bis es absolut notwendig ist), kann die Mit einigen Zustandsänderungen verbundene Arbeit verzögert werden.
- Die Runtime (oder ein Treiber) kann Zustandsänderungen durch Optimierung entfernen. Ein Beispiel hierfür könnte das Entfernen einer redundanten Zustandsänderung sein, die die Beleuchtung deaktiviert, da die Beleuchtung zuvor deaktiviert wurde.
Es gibt keine narrensichere Möglichkeit, eine Rendersequenz zu betrachten und zu schließen, welche Zustandsänderungen ein modifiziert Bit festlegen und Die Arbeit zurückstellen oder einfach durch optimierung entfernt werden. Auch wenn Sie optimierte Zustandsänderungen in der heutigen Runtime oder dem Treiber identifizieren könnten, wird wahrscheinlich die Runtime oder der Treiber von morgen aktualisiert. Sie wissen auch nicht ohne weiteres, wie der vorherige Zustand war, sodass es schwierig ist, redundante Zustandsänderungen zu identifizieren. Die einzige Möglichkeit, die Kosten einer Zustandsänderung zu überprüfen, besteht darin, die Rendersequenz zu messen, die die Zustandsänderungen enthält.
Wie Sie sehen können, erschweren die Komplikationen, die durch mehrere Prozessoren, die Verarbeitung von Befehlen von mehreren Komponenten und die in die Komponenten integrierten Optimierungen verursacht werden, die Vorhersage der Profilerstellung. Im nächsten Abschnitt wird jede dieser Herausforderungen bei der Profilerstellung behandelt. Es werden Direct3D-Beispiel-Rendersequenzen mit den zugehörigen Messtechniken angezeigt. Mit diesem Wissen sind Sie in der Lage, genaue, wiederholbare Messungen bei einzelnen Anrufen zu generieren.
Genaues Profilieren einer Direct3D-Rendersequenz
Nachdem einige der Herausforderungen bei der Profilerstellung hervorgehoben wurden, werden in diesem Abschnitt Techniken vorgestellt, mit denen Sie Profilmessungen generieren können, die für die Budgetierung verwendet werden können. Genaue, wiederholbare Profilerstellungsmessungen sind möglich, wenn Sie die Beziehung zwischen den von der CPU gesteuerten Komponenten verstehen und wie Sie Leistungsoptimierungen vermeiden können, die von der Laufzeit und dem Treiber implementiert werden.
Zunächst müssen Sie in der Lage sein, die Ausführungszeit eines einzelnen API-Aufrufs genau zu messen.
Auswählen eines genauen Messtools wie QueryPerformanceCounter
Das Microsoft Windows-Betriebssystem enthält einen Timer mit hoher Auflösung, der verwendet werden kann, um verstrichene Zeiten mit hoher Auflösung zu messen. Der aktuelle Wert eines solchen Timers kann mithilfe von QueryPerformanceCounter zurückgegeben werden. Nachdem QueryPerformanceCounter aufgerufen wurde, um Start- und Stoppwerte zurückzugeben, kann der Unterschied zwischen den beiden Werten mithilfe von QueryPerformanceCounter in die tatsächlich verstrichene Zeit (in Sekunden) konvertiert werden.
Die Vorteile der Verwendung von QueryPerformanceCounter sind, dass es in Windows verfügbar ist und einfach zu verwenden ist. Umschließen Sie die Aufrufe einfach mit einem QueryPerformanceCounter-Aufruf , und speichern Sie die Start- und Stoppwerte. Daher wird in diesem Dokument veranschaulicht, wie QueryPerformanceCounter verwendet wird, um Ausführungszeiten zu profilieren, ähnlich wie ein Instrumentierungsprofiler dies messen würde. Hier sehen Sie ein Beispiel, das zeigt, wie Sie QueryPerformanceCounter in Ihren Quellcode einbetten:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Beispiel 2: Implementierung der benutzerdefinierten Profilerstellung mit QPC
start und stop sind zwei große ganze Zahlen, die die vom Hochleistungszeitgeber zurückgegebenen Start- und Stoppwerte enthalten. Beachten Sie, dass QueryPerformanceCounter(&start) direkt vor SetTexture und QueryPerformanceCounter(&stop) direkt nach DrawPrimitive aufgerufen wird. Nach dem Abrufen des Stoppwerts wird QueryPerformanceFrequency aufgerufen, um freq zurückzugeben. Dies ist die Häufigkeit des Timers mit hoher Auflösung. Angenommen, Sie erhalten in diesem hypothetischen Beispiel die folgenden Ergebnisse für start, stop und freq:
| Lokale Variable | Anzahl der Ticks |
|---|---|
| start | 1792998845094 |
| stop | 1792998845102 |
| Freq | 3579545 |
Sie können diese Werte wie folgt in die Anzahl der Zyklen konvertieren, die zum Ausführen der API-Aufrufe benötigt werden:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
Anders ausgedrückt: Es dauert etwa 4568 Taktzyklen, um SetTexture und DrawPrimitive auf diesem 2-GHz-Computer zu verarbeiten. Sie können diese Werte wie folgt in die tatsächliche Zeit konvertieren, die zum Ausführen aller Aufrufe benötigt wurde:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
Die Verwendung von QueryPerformanceCounter erfordert, dass Sie Der Rendersequenz Start- und Stoppmessungen hinzufügen und QueryPerformanceFrequency verwenden, um die Differenz (Anzahl der Ticks) in die Anzahl der CPU-Zyklen oder in die tatsächliche Zeit zu konvertieren. Das Identifizieren der Messtechnik ist ein guter Anfang für die Entwicklung einer benutzerdefinierten Profilerstellungsimplementierung. Bevor Sie jedoch mit dem Durchführen von Messungen beginnen, müssen Sie wissen, wie Sie mit dem Video Karte umgehen.
Fokus auf CPU-Messungen
Wie bereits erwähnt, arbeiten die CPU und die GPU parallel, um die von den API-Aufrufen generierte Arbeit zu verarbeiten. Eine reale Anwendung erfordert die Profilerstellung für beide Prozessortypen, um festzustellen, ob Ihre Anwendung cpu- oder GPU-eingeschränkt ist. Da die GPU-Leistung herstellerspezifisch ist, wäre es sehr schwierig, in diesem Dokument Ergebnisse zu erzielen, die die Vielfalt der verfügbaren Grafikkarten abdecken.
Stattdessen konzentriert sich dieses Papier nur auf die Profilerstellung der von der CPU ausgeführten Arbeit mithilfe einer benutzerdefinierten Technik zum Messen der Laufzeit- und Treiberarbeit. Die GPU-Arbeit wird auf einen geringen Betrag reduziert, sodass CPU-Ergebnisse besser sichtbar sind. Ein Vorteil dieses Ansatzes besteht darin, dass diese Technik Ergebnisse im Anhang liefert, die Sie mit Ihren Messungen korrelieren können sollten. Um den Aufwand für die Video-Karte auf ein unbedeutendes Maß zu reduzieren, reduzieren Sie einfach den Renderingaufwand auf den geringstmöglichen Betrag. Dies kann erreicht werden, indem Zeichnungsaufrufe zum Rendern eines einzelnen Dreiecks eingeschränkt werden, und es kann weiter eingeschränkt werden, sodass jedes Dreieck nur ein Pixel enthält.
Die in diesem Dokument zum Messen der CPU-Arbeit verwendete Maßeinheit ist die Anzahl der CPU-Taktzyklen und nicht die tatsächliche Zeit. CPU-Taktzyklen haben den Vorteil, dass sie portabler (für CPU-begrenzte Anwendungen) als die tatsächlich verstrichene Zeit auf Computern mit unterschiedlichen CPU-Geschwindigkeiten ist. Dies kann bei Bedarf problemlos in die tatsächliche Zeit konvertiert werden.
Dieses Dokument behandelt keine Themen im Zusammenhang mit dem Ausgleich der Arbeitslast zwischen CPU und GPU. Denken Sie daran, dass das Ziel dieses Artikels nicht darin besteht, die Gesamtleistung einer Anwendung zu messen, sondern Ihnen zu zeigen, wie Sie die Zeit genau messen, die die Laufzeit und den Treiber für die Verarbeitung von API-Aufrufen benötigt. Mit diesen genauen Messungen können Sie die Aufgabe übernehmen, die CPU zu budgetieren, um bestimmte Leistungsszenarien zu verstehen.
Steuern von Laufzeit- und Treiberoptimierungen
Mit einer identifizierten Messtechnik und einer Strategie zur Verringerung der GPU-Arbeit besteht der nächste Schritt darin, die Laufzeit- und Treiberoptimierungen zu verstehen, die bei der Profilerstellung im Weg stehen.
Die CPU-Arbeit kann in drei Buckets unterteilt werden: die Anwendungsarbeit, die Laufzeitarbeit und die Treiberarbeit. Ignorieren Sie die Anwendungsarbeit, da dies unter der Kontrolle des Programmierers liegt. Aus Anwendungssicht sind die Laufzeit und der Treiber wie Blackboxs, da die Anwendung keine Kontrolle darüber hat, was in ihnen implementiert ist. Der Schlüssel besteht darin, die Optimierungstechniken zu verstehen, die in der Runtime und im Treiber implementiert werden können. Wenn Sie diese Optimierungen nicht verstehen, ist es sehr einfach, zu der falschen Schlussfolgerung über den Arbeitsaufwand zu springen, den die CPU basierend auf den Profilmessungen ausführt. Insbesondere gibt es zwei Themen, die sich auf etwas beziehen, das als Befehlspuffer bezeichnet wird, und was er tun kann, um die Profilerstellung zu verschleiern. Diese Themen sind:
- Laufzeitoptimierung mit dem Befehlspuffer. Der Befehlspuffer ist eine Laufzeitoptimierung, die die Auswirkungen eines Modusübergangs verringert. Informationen zum Steuern des Zeitpunkts des Modusübergangs finden Sie unter Steuern des Befehlspuffers.
- Negieren der Zeitsteuerungseffekte des Befehlspuffers. Die verstrichene Zeit eines Modusübergangs kann einen großen Einfluss auf die Profilerstellungsmessungen haben. Die Strategie hierfür besteht darin , die Rendersequenz im Vergleich zum Modusübergang groß zu machen.
Steuern des Befehlspuffers
Wenn eine Anwendung einen API-Aufruf ausführt, konvertiert die Runtime den API-Aufruf in ein geräteunabhängiges Format (das wir als Befehl bezeichnen) und speichert ihn im Befehlspuffer. Der Befehlspuffer wird dem folgenden Diagramm hinzugefügt.
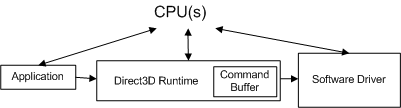
Jedes Mal, wenn die Anwendung einen weiteren API-Aufruf ausführt, wiederholt die Runtime diese Sequenz und fügt dem Befehlspuffer einen weiteren Befehl hinzu. Irgendwann leert die Runtime den Puffer (die Befehle werden an den Treiber gesendet). In Windows XP führt das Leeren des Befehlspuffers zu einem Modusübergang, wenn das Betriebssystem von der Runtime (im Benutzermodus) zum Treiber (ausgeführt im Kernelmodus) wechselt, wie im folgenden Diagramm dargestellt.
- Benutzermodus: Der nicht privilegierte Prozessormodus, der Anwendungscode ausführt. Anwendungen im Benutzermodus können nur über Systemdienste auf Systemdaten zugreifen.
- Kernelmodus: Der privilegierte Prozessormodus, in dem Windows-basierter Executive-Code ausgeführt wird. Ein Treiber oder Thread, der im Kernelmodus ausgeführt wird, hat Zugriff auf den gesamten Systemarbeitsspeicher, direkten Zugriff auf Hardware und die CPU-Anweisungen zum Ausführen von E/A mit der Hardware.
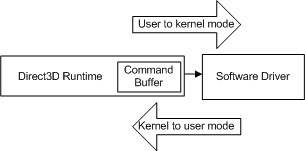
Der Übergang erfolgt jedes Mal, wenn die CPU vom Benutzer in den Kernelmodus wechselt (und umgekehrt), und die Anzahl der benötigten Zyklen ist im Vergleich zu einem einzelnen API-Aufruf groß. Wenn die Runtime jeden API-Aufruf an den Treiber gesendet hat, wenn er aufgerufen wurde, würde jeder API-Aufruf die Kosten für einen Modusübergang verursachen.
Stattdessen ist der Befehlspuffer eine Laufzeitoptimierung, die entwickelt wurde, um die effektiven Kosten des Modusübergangs zu reduzieren. Der Befehlspuffer stellt viele Treiberbefehle in die Warteschlange, um einen Übergang im einzelmodus vorzubereiten. Wenn die Runtime dem Befehlspuffer einen Befehl hinzufügt, wird die Steuerung an die Anwendung zurückgegeben. Ein Profiler weiß nicht, dass die Treiberbefehle wahrscheinlich noch nicht einmal an den Treiber gesendet wurden. Daher sind die Zahlen, die von einem standardmäßigen Instrumentierungsprofiler zurückgegeben werden, irreführend, da er die Laufzeitarbeit, aber nicht die zugeordnete Treiberarbeit misst.
Profilergebnisse ohne Modusübergang
Anhand der Rendersequenz aus Beispiel 2 finden Sie hier einige typische Zeitmessungsmessungen, die die Größe eines Modusübergangs veranschaulichen. Unter der Annahme, dass SetTexture - und DrawPrimitive-Aufrufe keinen Modusübergang verursachen, könnte ein standardmäßiger Instrumentierungsprofiler Ähnliche Ergebnisse wie die folgenden zurückgeben:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Jede dieser Zahlen ist der Zeitraum, der benötigt wird, bis die Laufzeit diese Aufrufe zum Befehlspuffer hinzunimmt. Da es keinen Modusübergang gibt, hat der Treiber noch keine Arbeit geleistet. Die Profilerergebnisse sind genau, aber sie messen nicht den gesamten Arbeitsaufwand, den die Rendersequenz letztendlich bewirkt, dass die CPU ausgeführt wird.
Profilerstellung von Ergebnissen mit einem Modusübergang
Sehen Sie sich nun an, was für dasselbe Beispiel geschieht, wenn ein Modusübergang auftritt. Gehen Sie diesmal davon aus, dass SetTexture und DrawPrimitive einen Modusübergang verursachen. Auch hier könnte ein Instrumentierungsprofiler von der Stange ähnliche Ergebnisse wie die folgenden zurückgeben:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
Die für SetTexture gemessene Zeit ist ungefähr gleich, aber der dramatische Anstieg der Zeit in DrawPrimitive ist auf den Modusübergang zurückzuführen. Dies geschieht:
- Angenommen, der Befehlspuffer verfügt über Platz für einen Befehl, bevor die Rendersequenz gestartet wird.
- SetTexture wird in ein geräteunabhängiges Format konvertiert und dem Befehlspuffer hinzugefügt. In diesem Szenario füllt dieser Aufruf den Befehlspuffer aus.
- Die Runtime versucht, DrawPrimitive dem Befehlspuffer hinzuzufügen, kann aber nicht, da er voll ist. Stattdessen leert die Laufzeit den Befehlspuffer. Dies verursacht den Kernelmodusübergang. Angenommen, der Übergang dauert etwa 5000 Zyklen. Diese Zeit trägt zur Zeit bei, die in DrawPrimitive verbracht wird.
- Der Treiber verarbeitet dann die Arbeit, die allen Befehlen zugeordnet ist, die aus dem Befehlspuffer geleert wurden. Angenommen, die Zeit des Treibers für die Verarbeitung der Befehle, die den Befehlspuffer fast gefüllt haben, beträgt etwa 935.000 Zyklen. Angenommen, die Mit SetTexture zugeordnete Treiberarbeit beträgt etwa 2750 Zyklen. Diese Zeit trägt zur Zeit bei, die in DrawPrimitive verbracht wird.
- Wenn der Treiber seine Arbeit abgeschlossen hat, gibt der Benutzermodusübergang die Steuerung zur Laufzeit zurück. Der Befehlspuffer ist jetzt leer. Angenommen, der Übergang dauert etwa 5000 Zyklen.
- Die Rendersequenz wird abgeschlossen, indem DrawPrimitive konvertiert und dem Befehlspuffer hinzugefügt wird. Angenommen, dies dauert etwa 900 Zyklen. Diese Zeit trägt zur Zeit bei, die in DrawPrimitive verbracht wird.
Wenn Sie die Ergebnisse zusammenfassen, sehen Sie:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Genau wie die Messung für DrawPrimitive ohne Modusübergang (900 Zyklen) ist die Messung für DrawPrimitive mit dem Modusübergang (947.950 Zyklen) genau, aber nutzlos in Bezug auf die Budgetierung der CPU-Arbeit. Das Ergebnis enthält die richtige Laufzeitarbeit, die Treiberarbeit für SetTexture, der Treiber für alle Befehle, die SetTexture vorangestellt haben, und zwei Modusübergänge. Bei der Messung fehlt jedoch die DrawPrimitive-Treiberarbeit .
Ein Modusübergang kann als Reaktion auf jeden Anruf erfolgen. Dies hängt davon ab, was sich zuvor im Befehlspuffer befand. Sie müssen den Modusübergang steuern, um zu verstehen, wie viel CPU-Arbeit (Laufzeit und Treiber) den einzelnen Aufrufen zugeordnet ist. Dazu benötigen Sie einen Mechanismus zum Steuern des Befehlspuffers und des Timings des Modusübergangs.
Der Abfragemechanismus
Der Abfragemechanismus in Microsoft Direct3D 9 wurde so konzipiert, dass die Runtime den Fortschritt der GPU abfragen und bestimmte Daten von der GPU zurückgeben kann. Wenn die GPU-Arbeit während der Profilerstellung minimiert wird, sodass sie sich geringfügig auf die Leistung auswirkt, können Sie status von der GPU zurückgeben, um die Treiberarbeit zu messen. Schließlich ist die Treiberarbeit abgeschlossen, wenn die GPU die Treiberbefehle gesehen hat. Darüber hinaus kann der Abfragemechanismus koaxiert werden, um zwei Befehlspuffermerkmale zu steuern, die für die Profilerstellung wichtig sind: wann der Befehlspuffer geleert wird und wie viel Arbeit im Puffer liegt.
Hier sehen Sie die gleiche Rendersequenz mit dem Abfragemechanismus:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Beispiel 3: Verwenden einer Abfrage zum Steuern des Befehlspuffers
Im Folgenden finden Sie eine ausführlichere Erläuterung der einzelnen Codezeilen:
- Erstellen Sie eine Ereignisabfrage, indem Sie ein Abfrageobjekt mit D3DQUERYTYPE_EVENT erstellen.
- Fügen Sie dem Befehlspuffer eine Abfrageereignismarkierung hinzu, indem Sie Issue(D3DISSUE_END) aufrufen. Dieser Marker weist den Treiber an, nachzuverfolgen, wann die GPU die Ausführung der Befehle vor dem Marker beendet hat.
- Der erste Aufruf leert den Befehlspuffer, da der Aufruf von GetData mit D3DGETDATA_FLUSH erzwingt, dass der Befehlspuffer geleert wird. Jeder nachfolgende Aufruf überprüft die GPU, um festzustellen, wann die Verarbeitung der gesamten Befehlspufferarbeit abgeschlossen ist. Diese Schleife gibt erst S_OK zurück, wenn sich die GPU im Leerlauf befindet.
- Beispiel für die Startzeit.
- Rufen Sie die API-Aufrufe auf, für die ein Profil erstellt wird.
- Fügen Sie dem Befehlspuffer eine zweite Abfrageereignismarkierung hinzu. Dieser Marker wird verwendet, um den Abschluss der Aufrufe nachzuverfolgen.
- Der erste Aufruf leert den Befehlspuffer, da der Aufruf von GetData mit D3DGETDATA_FLUSH erzwingt, dass der Befehlspuffer geleert wird. Wenn die GPU die Gesamte Verarbeitung des Befehlspuffers abgeschlossen hat, gibt GetData S_OK zurück, und die Schleife wird beendet, weil sich die GPU im Leerlauf befindet.
- Probieren Sie die Stoppzeit aus.
Die folgenden Ergebnisse werden mit QueryPerformanceCounter und QueryPerformanceFrequency gemessen:
| Lokale Variable | Anzahl der Ticks |
|---|---|
| start | 1792998845060 |
| stop | 1792998845090 |
| Freq | 3579545 |
Erneutes Konvertieren von Ticks in Zyklen (auf einem 2-GHz-Computer):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Hier ist die Aufschlüsselung der Anzahl der Zyklen pro Anruf:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
Der Abfragemechanismus hat es uns ermöglicht, die Laufzeit und die zu messende Treiberarbeit zu steuern. Um jede dieser Zahlen zu verstehen, sehen Sie sich an, was als Reaktion auf die einzelnen API-Aufrufe geschieht, zusammen mit den geschätzten Zeitangaben:
Der erste Aufruf leert den Befehlspuffer, indem GetData mit D3DGETDATA_FLUSH aufgerufen wird. Wenn die GPU die Gesamte Verarbeitung des Befehlspuffers abgeschlossen hat, gibt GetData S_OK zurück, und die Schleife wird beendet, weil sich die GPU im Leerlauf befindet.
Die Rendersequenz beginnt, indem SetTexture in ein geräteunabhängiges Format konvertiert und dem Befehlspuffer hinzugefügt wird. Angenommen, dies dauert etwa 100 Zyklen.
DrawPrimitive wird konvertiert und dem Befehlspuffer hinzugefügt. Angenommen, dies dauert etwa 900 Zyklen.
Das Problem fügt dem Befehlspuffer einen Abfragemarker hinzu. Angenommen, dies dauert etwa 200 Zyklen.
GetData bewirkt, dass der Befehlspuffer geleert wird, wodurch der Kernelmodusübergang erzwungen wird. Angenommen, dies dauert etwa 5000 Zyklen.
Der Treiber verarbeitet dann die Arbeit, die allen vier Aufrufen zugeordnet ist. Angenommen, die Treiberzeit für die Verarbeitung von SetTexture beträgt etwa 2964 Zyklen, DrawPrimitive etwa 3600 Zyklen, Issue etwa 200 Zyklen. Die gesamte Fahrerzeit für alle vier Befehle beträgt also etwa 6450 Zyklen.
Hinweis
Der Treiber benötigt auch etwas Zeit, um zu sehen, was die status der GPU ist. Da die GPU-Arbeit trivial ist, sollte die GPU bereits ausgeführt werden. GetData gibt S_OK basierend auf der Wahrscheinlichkeit zurück, dass die GPU abgeschlossen ist.
Wenn der Treiber seine Arbeit abgeschlossen hat, gibt der Benutzermodusübergang die Steuerung zur Laufzeit zurück. Der Befehlspuffer ist jetzt leer. Angenommen, dies dauert etwa 5000 Zyklen.
Zu den Zahlen für GetData gehören:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
Der in Kombination mit QueryPerformanceCounter verwendete Abfragemechanismus misst die gesamte CPU-Arbeit. Dies erfolgt mit einer Kombination aus Abfragemarkern und Abfrage-status Vergleichen. Start- und Stop-Abfragemarker, die dem Befehlspuffer hinzugefügt werden, werden verwendet, um zu steuern, wie viel Arbeit im Puffer liegt. Indem Sie warten, bis der richtige Rückgabecode zurückgegeben wird, wird die Startmessung unmittelbar vor dem Start einer sauber Rendersequenz durchgeführt, und die Stoppmessung erfolgt direkt nach Abschluss der Arbeit des Treibers, die dem Inhalt des Befehlspuffers zugeordnet ist. Dies erfasst effektiv die CPU-Arbeit, die sowohl von der Runtime als auch vom Treiber ausgeführt wird.
Nachdem Sie nun den Befehlspuffer und die Auswirkungen kennen, die er auf die Profilerstellung haben kann, sollten Sie wissen, dass es einige andere Bedingungen gibt, die dazu führen können, dass die Laufzeit den Befehlspuffer leert. Sie müssen diese in Ihren Rendersequenzen watch. Einige dieser Bedingungen sind als Reaktion auf API-Aufrufe, andere als Reaktion auf Ressourcenänderungen in der Runtime. Eine der folgenden Bedingungen führt zu einem Modusübergang:
- Wenn eine der Sperrmethoden (Lock) für einen Vertexpuffer, Indexpuffer oder eine Textur (unter bestimmten Bedingungen mit bestimmten Flags) aufgerufen wird.
- Wenn ein Geräte- oder Vertexpuffer, Indexpuffer oder Textur erstellt wird.
- Wenn ein Gerät oder ein Vertexpuffer, ein Indexpuffer oder eine Textur durch das letzte Release zerstört wird.
- Wenn ValidateDevice aufgerufen wird.
- Wenn Present aufgerufen wird.
- Wenn der Befehlspuffer aufgefüllt wird.
- Wenn GetData mit D3DGETDATA_FLUSH aufgerufen wird.
Achten Sie darauf, dass Sie für diese Bedingungen in Ihren Rendersequenzen watch. Jedes Mal, wenn ein Modusübergang hinzugefügt wird, werden Ihren Profilerstellungsmessungen 10.000 Fahrerarbeitszyklen hinzugefügt. Darüber hinaus ist der Befehlspuffer nicht statisch dimensioniert. Die Runtime kann die Größe des Puffers als Reaktion auf den Arbeitsaufwand ändern, der von der Anwendung generiert wird. Dies ist eine weitere Optimierung, die von einer Rendersequenz abhängt.
Achten Sie daher darauf, modusübergänge während der Profilerstellung zu steuern. Der Abfragemechanismus bietet eine robuste Methode zum Leeren des Befehlspuffers, sodass Sie sowohl den Zeitpunkt des Modusübergangs als auch den Arbeitsaufwand des Puffers steuern können. Allerdings kann auch diese Technik verbessert werden, indem die Übergangszeit des Modus reduziert wird, sodass sie im Hinblick auf das gemessene Ergebnis unerheblich ist.
Rendersequenz groß im Vergleich zum Modusübergang festlegen
Im vorherigen Beispiel verbrauchen der Kernelmodusschalter und der Benutzermodusswitch etwa 10.000 Zyklen, die nichts mit Laufzeit- und Treiberarbeit zu tun haben. Da der Modusübergang in das Betriebssystem integriert ist, kann er nicht auf null reduziert werden. Um den Modusübergang unbedeutend zu machen, muss die Rendersequenz angepasst werden, sodass die Arbeit von Treiber und Laufzeit eine Größenordnung größer ist als die Modusschalter. Sie könnten versuchen, eine Subtraktion auszuführen, um die Übergänge zu entfernen, aber die Amortisierung der Kosten gegenüber einer viel höheren Rendersequenzkosten ist zuverlässiger.
Die Strategie zum Reduzieren des Modusübergangs, bis er unbedeutend wird, besteht darin, der Rendersequenz eine Schleife hinzuzufügen. Sehen wir uns beispielsweise die Profilerstellungsergebnisse an, wenn eine Schleife hinzugefügt wird, die die Rendersequenz 1500 Mal wiederholt:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Beispiel 4: Hinzufügen einer Schleife zur Rendersequenz
Die folgenden Ergebnisse werden mit QueryPerformanceCounter und QueryPerformanceFrequency gemessen:
| Lokale Variable | Anzahl der Tics |
|---|---|
| start | 1792998845000 |
| stop | 1792998847084 |
| Freq | 3579545 |
Die Verwendung von QueryPerformanceCounter misst jetzt 2.840 Ticks. Die Konvertierung von Ticks in Zyklen entspricht dem bereits gezeigten:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
Anders ausgedrückt: Es dauert etwa 6,9 Millionen Zyklen auf diesem 2-GHz-Computer, um die 1500 Aufrufe in der Renderschleife zu verarbeiten. Von den 6,9 Millionen Zyklen beträgt die Zeitspanne in den Modusübergängen ungefähr 10.000. Jetzt sind die Profilergebnisse fast vollständig mit der Messung der Arbeit verbunden mit SetTexture und DrawPrimitive.
Beachten Sie, dass für das Codebeispiel ein Array von zwei Texturen erforderlich ist. Um eine Laufzeitoptimierung zu vermeiden, die SetTexture entfernt, wenn bei jedem Aufruf derselbe Texturzeiger festgelegt wird, verwenden Sie einfach ein Array von zwei Texturen. Auf diese Weise ändert sich jedes Mal, wenn die Schleife durchläuft, der Texturzeiger, und die gesamte Arbeit, die SetTexture zugeordnet ist, wird ausgeführt. Stellen Sie sicher, dass beide Texturen die gleiche Größe und das gleiche Format haben, sodass sich kein anderer Zustand ändert, wenn die Textur dies tut.
Und jetzt verfügen Sie über eine Technik zum Profilieren von Direct3D. Es basiert auf dem Hochleistungsindikator (QueryPerformanceCounter), um die Anzahl von Ticks aufzuzeichnen, die die CPU für die Verarbeitung der Arbeit benötigt. Die Arbeit wird sorgfältig gesteuert, um die Laufzeit- und Treiberarbeit zu sein, die API-Aufrufen mithilfe des Abfragemechanismus zugeordnet ist. Eine Abfrage bietet zwei Möglichkeiten der Steuerung: erstens, um den Befehlspuffer zu leeren, bevor die Rendersequenz gestartet wird, und zweitens, um zurückzugeben, wenn die GPU-Arbeit abgeschlossen ist.
Bisher wurde in diesem Artikel gezeigt, wie eine Rendersequenz profiliert wird. Jede Rendersequenz war recht einfach und enthielt einen einzelnen DrawPrimitive-Aufruf und einen SetTexture-Aufruf . Dies wurde durchgeführt, um sich auf den Befehlspuffer und die Verwendung des Abfragemechanismus zu konzentrieren, um ihn zu steuern. Im Folgenden finden Sie eine kurze Zusammenfassung der Profilerstellung für eine beliebige Rendersequenz:
- Verwenden Sie einen Hochleistungsindikator wie QueryPerformanceCounter, um die Zeit zu messen, die zum Verarbeiten der einzelnen API-Aufrufe benötigt wird. Verwenden Sie QueryPerformanceFrequency und die CPU-Taktrate, um dies in die Anzahl der CPU-Zyklen pro API-Aufruf zu konvertieren.
- Minimieren Sie die GPU-Arbeit, indem Sie Dreieckslisten rendern, wobei jedes Dreieck ein Pixel enthält.
- Verwenden Sie den Abfragemechanismus, um den Befehlspuffer vor der Rendersequenz zu leeren. Dadurch wird sichergestellt, dass die Profilerstellung die richtige Menge an Laufzeit- und Treiberarbeit erfasst, die der Rendersequenz zugeordnet ist.
- Steuern Sie den Arbeitsaufwand, der dem Befehlspuffer mit Abfrageereignismarkern hinzugefügt wird. Dieselbe Abfrage erkennt, wenn die GPU ihre Arbeit beendet. Da die GPU-Arbeit trivial ist, entspricht dies praktisch der Messung, wann die Treiberarbeit abgeschlossen ist.
Alle diese Techniken werden verwendet, um Statusänderungen zu profilieren. Unter der Annahme, dass Sie die Steuerung des Befehlspuffers gelesen und verstanden haben und die Baselinemessungen in DrawPrimitive erfolgreich abgeschlossen haben, können Sie Ihren Rendersequenzen Zustandsänderungen hinzufügen. Beim Hinzufügen von Zustandsänderungen zu einer Rendersequenz gibt es einige zusätzliche Herausforderungen bei der Profilerstellung. Wenn Sie Ihren Rendersequenzen Zustandsänderungen hinzufügen möchten, sollten Sie mit dem nächsten Abschnitt fortfahren.
Profilerstellung für Direct3D-Statusänderungen
Direct3D verwendet viele Renderzustände, um fast jeden Aspekt der Pipeline zu steuern. Zu den APIs, die Zustandsänderungen verursachen, gehören alle Funktionen oder Methoden, die nicht die Draw*Primitive-Aufrufe sind.
Zustandsänderungen sind schwierig, da Sie die Kosten einer Zustandsänderung ohne Rendering möglicherweise nicht sehen können. Dies ist ein Ergebnis des verzögerten Algorithmus, den der Treiber und die GPU verwenden, um die Arbeit zu verzögern, bis dies absolut erledigt werden muss. Im Allgemeinen sollten Sie die folgenden Schritte ausführen, um eine einzelne Zustandsänderung zu messen:
- Profil DrawPrimitive zuerst.
- Fügen Sie der Rendersequenz eine Zustandsänderung hinzu, und erstellen Sie ein Profil für die neue Sequenz.
- Subtrahieren Sie den Unterschied zwischen den beiden Sequenzen, um die Kosten für die Zustandsänderung zu erhalten.
Natürlich gilt weiterhin alles, was Sie über die Verwendung des Abfragemechanismus und das Einfügen der Rendersequenz in einer Schleife gelernt haben, um die Kosten für den Modusübergang zu negieren.
Profilerstellung für eine einfache Zustandsänderung
Beginnend mit einer Rendersequenz, die DrawPrimitive enthält, finden Sie hier die Codesequenz zum Messen der Kosten für das Hinzufügen von SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Beispiel 5: Messen eines API-Aufrufs für Zustandsänderungen
Beachten Sie, dass die Schleife zwei Aufrufe enthält: SetTexture und DrawPrimitive. Die Rendersequenz wird 1500 Mal schleift und generiert ähnliche Ergebnisse wie die folgenden:
| Lokale Variable | Anzahl der Tics |
|---|---|
| start | 1792998860000 |
| stop | 1792998870260 |
| Freq | 3579545 |
Die Konvertierung von Ticks in Zyklen ergibt erneut Folgendes:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Dividiert durch die Anzahl der Iterationen in der Schleife ergibt Folgendes:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Jede Iteration der Schleife enthält eine Zustandsänderung und einen Draw-Aufruf. Wenn Sie das Ergebnis der DrawPrimitive-Rendersequenz subtrahieren, bleibt Folgendes übrig:
3850 - 1100 = 2750 cycles for SetTexture
Dies ist die durchschnittliche Anzahl von Zyklen, mit der SetTexture dieser Rendersequenz hinzugefügt werden soll. Diese Technik kann auch auf andere Zustandsänderungen angewendet werden.
Warum wird SetTexture als einfache Zustandsänderung bezeichnet? Da der festgelegte Zustand eingeschränkt ist, sodass die Pipeline bei jeder Zustandsänderung den gleichen Arbeitsaufwand ausführt. Durch das Einschränken beider Texturen auf die gleiche Größe und das gleiche Format wird der gleiche Arbeitsaufwand für jeden SetTexture-Aufruf sichergestellt.
Profilerstellung einer Zustandsänderung, die umgeschaltet werden muss
Es gibt andere Zustandsänderungen, die dazu führen, dass sich der Von der Grafikpipeline ausgeführte Arbeitsaufwand für jede Iteration der Renderschleife ändert. Wenn z-Testing beispielsweise aktiviert ist, aktualisiert jede Pixelfarbe ein Renderziel erst, nachdem der z-Wert des neuen Pixels mit dem Z-Wert für das vorhandene Pixel getestet wurde. Wenn Z-Testing deaktiviert ist, wird dieser Pro-Pixel-Test nicht durchgeführt, und die Ausgabe wird viel schneller geschrieben. Durch das Aktivieren oder Deaktivieren des Z-Test-Zustands wird der Arbeitsaufwand während des Renderings (sowohl von der CPU als auch von der GPU) erheblich geändert.
SetRenderState erfordert einen bestimmten Renderzustand und einen Zustandswert, um Z-Testing zu aktivieren oder zu deaktivieren. Der bestimmte Zustandswert wird zur Laufzeit ausgewertet, um zu bestimmen, wie viel Arbeit erforderlich ist. Es ist schwierig, diese Zustandsänderung in einer Renderschleife zu messen und trotzdem den Pipelinezustand so vorzukonditionieren, dass er wechselt. Die einzige Lösung besteht darin, die Zustandsänderung während der Rendersequenz umzuschalten.
Die Profilerstellungsmethode muss z. B. wie folgt zweimal wiederholt werden:
- Beginnen Sie mit der Profilerstellung für die DrawPrimitive-Rendersequenz . Rufen Sie die Baseline auf.
- Erstellen Sie ein Profil für eine zweite Rendersequenz, die die Zustandsänderung um schaltet. Die Rendersequenzschleife enthält:
- Eine Zustandsänderung, um den Zustand in eine "false"-Bedingung festzulegen.
- DrawPrimitive genau wie die ursprüngliche Sequenz.
- Eine Zustandsänderung, um den Zustand in eine "true"-Bedingung festzulegen.
- Ein zweites DrawPrimitive,um zu erzwingen, dass die zweite Zustandsänderung realisiert wird.
- Ermitteln Sie den Unterschied zwischen den beiden Rendersequenzen. Dies wird wie folgt erreicht:
- Multiplizieren Sie die DrawPrimitive-Baselinesequenz mit 2, da in der neuen Sequenz zwei DrawPrimitive-Aufrufe vorhanden sind.
- Subtrahieren Sie das Ergebnis der neuen Sequenz von der ursprünglichen Sequenz.
- Dividieren Sie das Ergebnis durch 2, um die durchschnittlichen Kosten für die Zustandsänderung "false" und "true" zu erhalten.
Bei der Schleifentechnik, die in der Rendersequenz verwendet wird, müssen die Kosten für die Änderung des Pipelinezustands gemessen werden, indem der Zustand für jede Iteration in der Rendersequenz von einer "true" zu einer "false"-Bedingung und umgekehrt umgeschaltet wird. Die Bedeutung von "true" und "false" ist hier nicht literal, dies bedeutet einfach, dass der Zustand in entgegengesetzte Bedingungen gesetzt werden muss. Dadurch werden beide Zustandsänderungen während der Profilerstellung gemessen. Natürlich gilt weiterhin alles, was Sie über die Verwendung des Abfragemechanismus und das Platzieren der Rendersequenz in einer Schleife gelernt haben, um die Kosten für den Modusübergang zu negieren.
Hier ist z. B. die Codesequenz zum Messen der Kosten für das Ein- oder Ausschalten von Z-Tests:
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Beispiel 5: Messen einer Änderung des Umschaltzustands
Die Schleife schaltet den Zustand um, indem zwei SetRenderState-Aufrufe ausgeführt werden. Der erste SetRenderState-Aufruf deaktiviert z-testing und der zweite SetRenderState aktiviert Z-Testing. Jedem SetRenderState folgt DrawPrimitive, sodass die der Zustandsänderung zugeordnete Arbeit vom Treiber verarbeitet wird, anstatt nur ein modifiziert Bit im Treiber festzulegen.
Diese Zahlen sind für diese Rendersequenz angemessen:
| Lokale Variable | Anzahl von Ticks |
|---|---|
| start | 1792998845000 |
| stop | 1792998861740 |
| Freq | 3579545 |
Die Konvertierung von Ticks in Zyklen ergibt erneut Folgendes:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Dividiert durch die Anzahl von Iterationen in der Schleife ergibt Folgendes:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Jede Iteration der Schleife enthält zwei Zustandsänderungen und zwei Zeichnungsaufrufe. Das Subtrahieren der Zeichnungsaufrufe (bei 1100 Zyklen) bleibt wie folgt:
6200 - 1100 - 1100 = 4000 cycles for both state changes
Dies ist die durchschnittliche Anzahl von Zyklen für beide Zustandsänderungen, sodass die durchschnittliche Zeit für jede Zustandsänderung beträgt:
4000 / 2 = 2000 cycles for each state change
Daher beträgt die durchschnittliche Anzahl von Zyklen zum Aktivieren oder Deaktivieren von Z-Tests 2000 Zyklen. Beachten Sie, dass QueryPerformanceCounter z-enable zur Hälfte der Zeit und Z-Deaktivierung zur Hälfte der Zeit misst. Diese Technik misst tatsächlich den Durchschnitt beider Zustandsänderungen. Mit anderen Worten, Sie messen die Zeit zum Umschalten eines Zustands. Mit diesem Verfahren können Sie nicht wissen, ob die Aktivierungs- und Deaktivierungszeiten gleichwertig sind, da Sie den Durchschnitt beider Werte gemessen haben. Dennoch ist dies eine angemessene Zahl, die beim Budgetieren eines Umschaltzustands verwendet werden kann, da eine Anwendung, die diese Zustandsänderung verursacht, dies nur durch Umschalten dieses Zustands tun kann.
Jetzt können Sie diese Techniken anwenden und alle gewünschten Zustandsänderungen profilieren, richtig? Das trifft nicht vollständig zu. Sie müssen immer noch vorsichtig mit Optimierungen sein, die darauf ausgelegt sind, den Arbeitsaufwand zu reduzieren, der ausgeführt werden muss. Es gibt zwei Arten von Optimierungen, die Sie beim Entwerfen Ihrer Rendersequenzen beachten sollten.
Achten Sie auf Zustandsänderungsoptimierungen
Im vorherigen Abschnitt wird gezeigt, wie Beide Arten von Zustandsänderungen beschrieben werden: eine einfache Zustandsänderung, die eingeschränkt ist, um die gleiche Menge an Arbeit für jede Iteration zu generieren, und eine Änderung des Umschaltzustands, die den Umfang der geleisteten Arbeit dramatisch ändert. Was geschieht, wenn Sie die vorherige Rendersequenz übernehmen und ihr eine weitere Zustandsänderung hinzufügen? Für instance verwendet dieses Beispiel die Rendersequenz z-enable> und fügt ihr einen z-func-Vergleich hinzu:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
Der z-func-Zustand legt die Vergleichsebene beim Schreiben in den z-Puffer fest (zwischen dem z-Wert eines aktuellen Pixels mit dem z-Wert eines Pixels im Tiefenpuffer). D3DCMP_NEVER deaktiviert den Z-Testvergleich, während D3DCMP_ALWAYS den Vergleich jedes Mal festlegt, wenn Z-Tests durchgeführt werden.
Durch das Profilieren einer dieser Zustandsänderungen in einer Rendersequenz mit DrawPrimitive werden Ergebnisse wie die folgenden generiert:
| Single State Change | Durchschnittliche Anzahl von Zyklen |
|---|---|
| nur D3DRS_ZENABLE | 2000 |
oder
| Single State Change | Durchschnittliche Anzahl von Zyklen |
|---|---|
| nur D3DRS_ZFUNC | 600 |
Wenn Sie jedoch sowohl D3DRS_ZENABLE als auch D3DRS_ZFUNC in derselben Rendersequenz profilieren, können Ergebnisse wie die folgenden angezeigt werden:
| Beide Zustandsänderungen | Durchschnittliche Anzahl von Zyklen |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
Sie können davon ausgehen, dass das Ergebnis die Summe von 2000 und 600 Zyklen (oder 2600) Zyklen sein wird, da der Treiber alle Aufgaben ausführt, die mit dem Festlegen beider Renderzustände verbunden sind. Stattdessen beträgt der Durchschnitt 2000 Zyklen.
Dieses Ergebnis spiegelt eine Optimierung der Zustandsänderung wider, die in der Runtime, dem Treiber oder der GPU implementiert wurde. In diesem Fall könnte der Treiber den ersten SetRenderState sehen und einen modifiziert Zustand festlegen, der die Arbeit auf einen späteren Zeitpunkt verschieben würde. Wenn der Treiber den zweiten SetRenderState sieht, könnte derselbe modifiziert Zustand redundant festgelegt werden, und die gleiche Arbeit wird erneut verschoben. Wenn DrawPrimitive aufgerufen wird, wird die dem modifiziert Zustand zugeordnete Arbeit schließlich verarbeitet. Der Treiber führt die Arbeit einmal aus, was bedeutet, dass die ersten beiden Zustandsänderungen vom Treiber effektiv konsolidiert werden. Auf ähnliche Weise werden die dritten und vierten Zustandsänderungen effektiv vom Treiber in eine einzelne Zustandsänderung konsolidiert, wenn die zweite DrawPrimitive aufgerufen wird. Das Nettoergebnis ist, dass der Treiber und die GPU eine einzelne Zustandsänderung für jeden Zeichnungsaufruf verarbeiten.
Dies ist ein gutes Beispiel für eine sequenzabhängige Treiberoptimierung. Der Treiber hat die Arbeit zweimal verschoben, indem er einen modifiziert Zustand festgelegt hat, und die Arbeit dann einmal ausgeführt, um den modifiziert Zustand zu löschen. Dies ist ein gutes Beispiel für die Art der Effizienzverbesserung, die erfolgen kann, wenn Die Arbeit zurückgestellt wird, bis sie absolut notwendig ist.
Woher wissen Sie, welche Zustandsänderungen einen modifiziert Zustand intern festlegen und daher die Arbeit auf einen späteren Zeitpunkt verschieben? Nur durch Testen von Rendersequenzen (oder Durchsprechen mit Treiberschreibern). Treiber werden regelmäßig aktualisiert und verbessert, sodass die Liste der Optimierungen nicht statisch ist. Es gibt nur eine Möglichkeit, absolut zu wissen, was eine Zustandsänderung in einer bestimmten Rendersequenz auf einer bestimmten Hardware kostet. und das ist, um es zu messen.
Achten Sie auf DrawPrimitive Optimierungen
Zusätzlich zur Optimierung von Zustandsänderungen versucht die Runtime, die Anzahl der Zuziehungsaufrufe zu optimieren, die der Treiber verarbeiten muss. Betrachten Sie z. B. die folgenden Aufrufe zum Zurück-zu-Zurück-Zeichnen:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Beispiel 5a: Zwei Zeichnungsaufrufe
Diese Sequenz enthält zwei Zeichnungsaufrufe, die von der Runtime in einen einzelnen Aufruf konsolidiert werden, der entspricht:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Beispiel 5b: Ein einzelner verketteter Zeichnungsaufruf
Die Runtime verkettet beide speziellen Zeichnungsaufrufe zu einem einzelnen Aufruf, wodurch die Treiberarbeit um 50 Prozent reduziert wird, da der Treiber jetzt nur noch einen Zeichnungsaufruf verarbeiten muss.
Im Allgemeinen verkettet die Runtime zwei oder mehr Back-to-Back-DrawPrimitive-Aufrufe, wenn:
- Der primitive Typ ist eine Dreiecksliste (D3DPT_TRIANGLELIST).
- Jeder nachfolgende DrawPrimitive-Aufruf muss auf aufeinanderfolgende Scheitelpunkte innerhalb des Vertexpuffers verweisen.
Ebenso sind die richtigen Bedingungen für die Verkettung von zwei oder mehr Back-to-Back DrawIndexedPrimitive-Aufrufen :
- Der primitive Typ ist eine Dreiecksliste (D3DPT_TRIANGLELIST).
- Jeder nachfolgende DrawIndexedPrimitive-Aufruf muss sequenziell aufeinanderfolgende Referenzindizes innerhalb des Indexpuffers verweisen.
- Jeder nachfolgende DrawIndexedPrimitive-Aufruf muss denselben Wert für BaseVertexIndex verwenden.
Um eine Verkettung während der Profilerstellung zu verhindern, ändern Sie die Rendersequenz so, dass der primitive Typ keine Dreiecksliste ist, oder ändern Sie die Rendersequenz so, dass es keine Back-to-Back-Zeichnungsaufrufe gibt, die aufeinanderfolgende Scheitelpunkte (oder Indizes) verwenden. Genauer gesagt verkettet die Runtime auch Zeichnungsaufrufe, die die beiden folgenden Bedingungen erfüllen:
- Wenn der vorherige Aufruf DrawPrimitive ist, wenn der nächste Zeichnungsaufruf:
- verwendet eine Dreiecksliste, UND
- gibt startVertex = previous StartVertex + previous PrimitiveCount * 3 an
- Wenn Sie DrawIndexedPrimitive verwenden, wenn das nächste Zeichnen aufruft:
- verwendet eine Dreiecksliste, UND
- gibt den StartIndex = previous StartIndex + previous PrimitiveCount * 3, AND
- gibt den BaseVertexIndex = previous BaseVertexIndex an.
Dies ist ein subtileres Beispiel für die Verkettung von Zeichenaufrufen, das beim Erstellen der Profilerstellung leicht übersehen werden kann. Angenommen, die Rendersequenz sieht wie folgt aus:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Beispiel 5c: Ein Zustandswechsel und ein Zeichnungsaufruf
Die Schleife durchläuft 1500 Dreiecke, legt eine Textur fest und zeichnet jedes Dreieck. Diese Renderschleife benötigt ungefähr 2750 Zyklen für SetTexture und 1100 Zyklen für DrawPrimitive , wie in den vorherigen Abschnitten gezeigt. Sie können intuitiv erwarten, dass das Verschieben von SetTexture außerhalb der Renderschleife den Arbeitsaufwand des Treibers um 1500 x 2750 Zyklen reduzieren sollte, was der Arbeitsaufwand ist, der mit dem 1500-malen Aufruf von SetTexture verbunden ist. Der Codeausschnitt würde wie folgt aussehen:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Beispiel 5d: Beispiel 5c mit Zustandsänderung außerhalb der Schleife
Das Verschieben von SetTexture außerhalb der Renderschleife verringert den Mit SetTexture zugeordneten Arbeitsaufwand, da es einmal statt 1500 Mal aufgerufen wird. Ein weniger offensichtlicher sekundärer Effekt ist, dass die Arbeit für DrawPrimitive ebenfalls von 1500 Aufrufen auf 1 Aufruf reduziert wird, da alle Bedingungen für die Verkettung von Zeichnungsaufrufen erfüllt sind. Wenn die Rendersequenz verarbeitet wird, verarbeitet die Laufzeit 1500 Aufrufe in einem einzelnen Treiberaufruf. Durch das Verschieben dieser eine Codezeile wurde die Menge an Treiberarbeit drastisch reduziert:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Diese Ergebnisse sind völlig richtig, aber im Kontext der ursprünglichen Frage sehr irreführend. Die Optimierung des Draw-Aufrufs hat dazu geführt, dass die Arbeit des Fahrers erheblich reduziert wurde. Dies ist ein häufiges Problem bei der benutzerdefinierten Profilerstellung. Achten Sie beim Entfernen von Aufrufen aus einer Rendersequenz darauf, die Verkettung von Zeichenaufrufen zu vermeiden. Tatsächlich ist dieses Szenario ein aussagekräftiges Beispiel für das Ausmaß der Verbesserung der Treiberleistung, die durch diese Laufzeitoptimierung möglich ist.
Jetzt wissen Sie also, wie Sie Zustandsänderungen messen. Beginnen Sie mit der Profilerstellung für DrawPrimitive. Fügen Sie dann jede zusätzliche Zustandsänderung der Sequenz hinzu (in einigen Fällen wird ein Aufruf hinzugefügt und in anderen Fällen zwei Aufrufe hinzugefügt), und messen Sie den Unterschied zwischen den beiden Sequenzen. Sie können die Ergebnisse in Teilstriche, Zyklen oder Zeit konvertieren. Genau wie das Messen von Rendersequenzen mit QueryPerformanceCounter basiert das Messen einzelner Zustandsänderungen auf dem Abfragemechanismus, um den Befehlspuffer zu steuern und die Zustandsänderungen in einer Schleife zu platzieren, um die Auswirkungen der Modusübergänge zu minimieren. Diese Technik misst die Kosten für das Umschalten eines Zustands, da der Profiler den Durchschnitt der Aktivierung und Deaktivierung des Zustands zurückgibt.
Mit dieser Funktion können Sie mit dem Generieren beliebiger Renderingsequenzen beginnen und die zugehörige Laufzeit- und Treiberarbeit genau messen. Die Zahlen können dann verwendet werden, um Budgetierungsfragen wie "Wie viele weitere dieser Aufrufe" in der Rendersequenz zu beantworten, während eine angemessene Framerate beibehalten wird, vorausgesetzt, dass die CPU-begrenzte Szenarien besteht.
Zusammenfassung
In diesem Dokument wird veranschaulicht, wie sie den Befehlspuffer steuern, damit einzelne Aufrufe genau profiliert werden können. Die Profilerstellungsnummern können in Ticks, Zyklen oder absoluter Zeit generiert werden. Sie stellen den Umfang der Laufzeit- und Treiberarbeit dar, die jedem API-Aufruf zugeordnet ist.
Beginnen Sie mit der Profilerstellung für einen Draw*Primitive-Aufruf in einer Rendersequenz. Beachten Sie Folgendes:
- Verwenden Sie QueryPerformanceCounter, um die Anzahl der Ticks pro API-Aufruf zu messen. Verwenden Sie QueryPerformanceFrequency, um die Ergebnisse bei Bedarf in Zyklen oder Zeit zu konvertieren.
- Verwenden Sie den Abfragemechanismus, um den Befehlspuffer vor dem Starten zu leeren.
- Schließen Sie die Rendersequenz in eine Schleife ein, um die Auswirkungen des Modusübergangs zu minimieren.
- Verwenden Sie den Abfragemechanismus, um zu messen, wann die GPU ihre Arbeit abgeschlossen hat.
- Achten Sie auf Laufzeitverkettung, die sich erheblich auf den Arbeitsaufwand auswirken wird.
Dadurch erhalten Sie eine Basisleistung für DrawPrimitive , die zum Erstellen von verwendet werden kann. Befolgen Sie die folgenden zusätzlichen Tipps, um ein Profil für eine Statusänderung zu erstellen:
- Fügen Sie die Statusänderung zu einem bekannten Rendersequenzprofil der neuen Sequenz hinzu. Da der Test in einer Schleife durchgeführt wird, muss der Zustand zweimal in entgegengesetzte Werte festgelegt werden (z. B. Aktivieren und Deaktivieren für instance).
- Vergleichen Sie die Unterschiedlichen Zykluszeiten zwischen den beiden Sequenzen.
- Subtrahieren Sie bei Zustandsänderungen, die die Pipeline erheblich ändern (z. B. SetTexture), den Unterschied zwischen den beiden Sequenzen, um die Zeit für die Zustandsänderung zu erhalten.
- Subtrahieren Sie bei Zustandsänderungen, die die Pipeline erheblich ändern (und daher umschaltende Zustände wie SetRenderState erfordern), den Unterschied zwischen den Rendersequenzen und dividieren Sie durch 2. Dadurch wird die durchschnittliche Anzahl von Zyklen für jede Zustandsänderung generiert.
Achten Sie jedoch auf Optimierungen, die bei der Profilerstellung zu unerwarteten Ergebnissen führen. Zustandsänderungsoptimierungen können modifiziert Zustände festlegen, wodurch die Arbeit verzögert wird. Dies kann zu Profilergebnissen führen, die nicht so intuitiv wie erwartet sind. Das Zeichnen von Aufrufen, die verkettet sind, reduziert die Arbeit des Treibers erheblich, was zu irreführenden Schlussfolgerungen führen kann. Sorgfältig geplante Rendersequenzen werden verwendet, um Zustandsänderungen und Zeichnen von Aufrufverkettungen zu verhindern. Der Trick besteht darin, zu verhindern, dass die Optimierungen während der Profilerstellung stattfinden, sodass die von Ihnen generierten Zahlen vernünftige Budgetierungszahlen sind.
Hinweis
Das Duplizieren dieser Profilerstellungsstrategie in einer Anwendung ohne Abfragemechanismus ist schwieriger. Vor Direct3D 9 besteht die einzige vorhersagbare Möglichkeit zum Leeren des Befehlspuffers darin, eine aktive Oberfläche (z. B. ein Renderziel) zu sperren, um zu warten, bis sich die GPU im Leerlauf befindet. Dies liegt daran, dass das Sperren einer Oberfläche die Laufzeit erzwingt, den Befehlspuffer zu leeren, falls im Puffer Renderingbefehle vorhanden sind, die die Oberfläche aktualisieren sollten, bevor sie gesperrt wird, zusätzlich zum Warten auf den Abschluss der GPU. Diese Technik ist funktionsfähig, obwohl sie eher aufdringlicher ist als die Verwendung des in Direct3D 9 eingeführten Abfragemechanismus.
Anhang
Die Zahlen in dieser Tabelle sind ein Bereich von Näherungen für den Umfang der Laufzeit- und Treiberarbeit, die jeder dieser Zustandsänderungen zugeordnet ist. Die Näherungsangaben basieren auf tatsächlichen Messungen an Treibern unter Verwendung der im Papier gezeigten Techniken. Diese Zahlen wurden mit der Direct3D 9-Runtime generiert und sind treiberabhängig.
Die Techniken in diesem Dokument wurden entwickelt, um die Laufzeit und die Treiberleistung zu messen. Im Allgemeinen ist es unpraktisch, Ergebnisse bereitzustellen, die der Leistung der CPU und der GPU in jeder Anwendung entsprechen, da dies ein vollständiges Array von Rendersequenzen erfordern würde. Darüber hinaus ist es besonders schwierig, die Leistung der GPU zu vergleichen, da sie stark vom Zustandssetup in der Pipeline vor der Rendersequenz abhängig ist. Für instance wirkt sich die Aktivierung der Alphamischung wenig auf die menge der erforderlichen CPU-Arbeit aus, kann sich jedoch stark auf den Arbeitsaufwand der GPU auswirken. Daher beschränken die Techniken in diesem Dokument die GPU-Arbeit auf die minimale Menge, die möglich ist, indem die Menge der Zu rendernden Daten begrenzt wird. Dies bedeutet, dass die Zahlen in der Tabelle am ehesten mit den Ergebnissen übereinstimmen, die von Anwendungen erzielt werden, die cpu-begrenzt sind (im Gegensatz zu einer Anwendung, die durch die GPU eingeschränkt wird).
Es wird empfohlen, die vorgestellten Techniken zu verwenden, um die für Sie wichtigsten Szenarien und Konfigurationen abzudecken. Die Werte in der Tabelle können zum Vergleichen mit den von Ihnen generierten Zahlen verwendet werden. Da die einzelnen Treiber variieren, besteht die einzige Möglichkeit, die tatsächlich angezeigten Zahlen zu generieren, darin, Profilerstellungsergebnisse unter Verwendung Ihrer Szenarien zu generieren.
| API-Aufruf | Durchschnittliche Anzahl von Zyklen |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 Konstante) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| BELEUCHTUNG | 1700 - 7500 |
| DIFFUSEMATERIALQUELLE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| SetLight | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| SetIndices | 900 - 5600 |
| AMBIENT | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 Konstante) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| CLIPPING | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| SCHABLONENMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| SCHABLONENFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Zugehörige Themen