Troubleshoot Azure Event Hubs event processor
This article provides solutions to common problems that you might encounter when you use the EventProcessorClient type. If you're looking for solutions to other common problems that you might encounter when you use Azure Event Hubs, see Troubleshoot Azure Event Hubs.
412 precondition failures when you use an event processor
412 precondition errors occur when the client tries to take or renew ownership of a partition, but the local version of the ownership record is outdated. This problem occurs when another processor instance steals partition ownership. For more information, see the next section.
Partition ownership changes frequently
When the number of EventProcessorClient instances changes (that is, are added or removed), the running instances try to load-balance partitions between themselves. For a few minutes after the number of processors changes, partitions are expected to change owners. After it's balanced, partition ownership should be stable and change infrequently. If partition ownership is changing frequently when the number of processors is constant, it likely indicates a problem. We recommended that you file a GitHub issue with logs and a repro.
Partition ownership is determined via the ownership records in the CheckpointStore. On every load balancing interval, the EventProcessorClient will perform the following tasks:
- Fetch the latest ownership records.
- Check the records to see which records haven't updated their timestamp within the partition ownership expiration interval. Only records matching this criteria are considered.
- If there are any unowned partitions and the load is not balanced between instances of
EventProcessorClient, the event processor client will try to claim a partition. - Update the ownership record for the partitions it owns that have an active link to that partition.
You can configure the load balancing and ownership expiration intervals when you create the EventProcessorClient via the EventProcessorClientBuilder, as described in the following list:
- The loadBalancingUpdateInterval(Duration) method indicates how often the load balancing cycle runs.
- The partitionOwnershipExpirationInterval(Duration) method indicates the minimum amount of time since the ownership record has been updated, before the processor considers a partition unowned.
For example, if an ownership record was updated at 9:30am and partitionOwnershipExpirationInterval is 2 mins. When a load balance cycle occurs and it notices that the ownership record has not been updated in the last 2 min or by 9:32am, it will consider the partition unowned.
If an error occurs in one of the partition consumers, it will close the corresponding consumer but will not try to reclaim it until the next load balancing cycle.
"...current receiver '<RECEIVER_NAME>' with epoch '0' is getting disconnected"
The entire error message looks similar to the following output:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
This error is expected when load balancing occurs after EventProcessorClient instances are added or removed. Load balancing is an ongoing process. When you use the BlobCheckpointStore with your consumer, every ~30 seconds (by default), the consumer checks to see which consumers have a claim for each partition, then runs some logic to determine whether it needs to 'steal' a partition from another consumer. The service mechanism used to assert exclusive ownership over a partition is known as the Epoch.
However, if no instances are being added or removed, there's an underlying issue that should be addressed. For more information, see the Partition ownership changes frequently section and Filing GitHub issues.
High CPU usage
High CPU usage is usually because an instance owns too many partitions. We recommend no more than three partitions for every CPU core. It's better to start with 1.5 partitions for each CPU core and then test by increasing the number of partitions owned.
Out of memory and choosing the heap size
The out of memory (OOM) problem can happen if the current max heap for the JVM is insufficient to run the application. You may want to measure the application's heap requirement. Then, based on the result, size the heap by setting the appropriate max heap memory using the -Xmx JVM option.
You shouldn't specify -Xmx as a value larger than the memory available or limit set for the host (the VM or container) - for example, the memory requested in the container's configuration. You should allocate enough memory for the host to support the Java heap.
The following steps describe a typical way to measure the value for max Java Heap:
Run the application in an environment close to production, where the application sends, receives, and processes events under the peak load expected in production.
Wait for the application to reach a steady state. At this stage, the application and JVM would have loaded all domain objects, class types, static instances, object pools (TCP, DB connection pools), etc.
Under the steady state, you see the stable sawtooth-shaped pattern for the heap collection, as shown in the following screenshot:
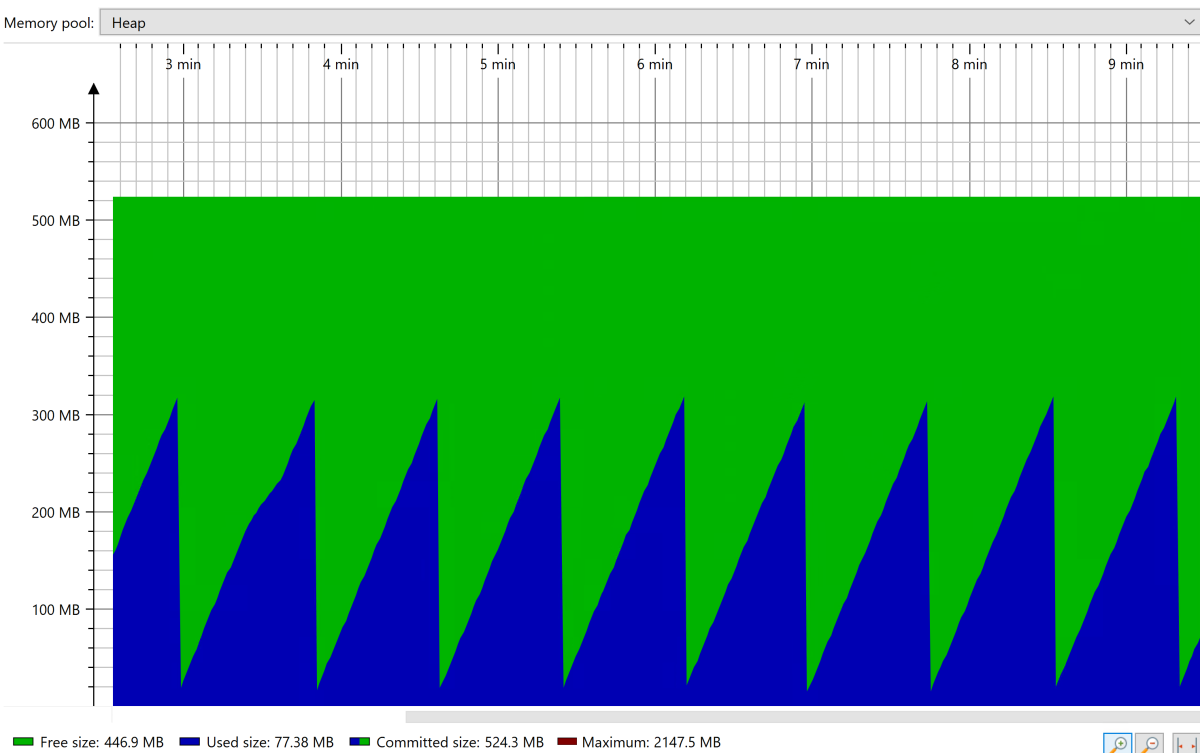
After the application reaches the steady state, force a full garbage collection (GC) using tools like JConsole. Observe the memory occupied after the full GC. You want to size the heap such that only 30% is occupied after the full GC. You can use this value to set the max heap size (using
-Xmx).

If you're on the container, then size the container to have an extra ~1 GB of memory for the non-heap need for the JVM instance.
Processor client stops receiving
The processor client often continually runs in a host application for days on end. Sometimes, it notices that EventProcessorClient isn't processing one or more partitions. Usually, there isn't enough information to determine why the exception occurred. The EventProcessorClient stopping is the symptom of an underlying cause (that is, the race condition) that occurred while trying to recover from a transient error. For the information we require, see Filing GitHub issues.
Duplicate EventData received when processor is restarted
The EventProcessorClient and Event Hubs service guarantees an at-least-once delivery. You can add metadata to discern duplicate events. For more information, see Does Azure Event Hubs guarantee an at-least once delivery? on Stack Overflow. If you require only-once delivery, you should consider Service Bus, which waits for an acknowledgment from the client. For a comparison of the messaging services, see Choosing between Azure messaging services.
Migrate from legacy to new client library
The migration guide includes steps on migrating from the legacy client and migrating legacy checkpoints.
Next steps
If the troubleshooting guidance in this article doesn't help to resolve issues when you use the Azure SDK for Java client libraries, we recommended that you file an issue in the Azure SDK for Java GitHub repository.