T-SQL support in Microsoft Fabric notebooks
The T-SQL notebook feature in Microsoft Fabric lets you write and run T-SQL code within a notebook. You can use T-SQL notebooks to manage complex queries and write better markdown documentation. It also allows direct execution of T-SQL on connected warehouse or SQL analytics endpoint. By adding a Data Warehouse or SQL analytics endpoint to a notebook, T-SQL developers can run queries directly on the connected endpoint. BI analysts can also perform cross-database queries to gather insights from multiple warehouses and SQL analytics endpoints.
Most of the existing notebook functionalities are available for T-SQL notebooks. These include charting query results, coauthoring notebooks, scheduling regular executions, and triggering execution within Data Integration pipelines.
Important
This feature is in preview.
In this article, you learn how to:
- Create a T-SQL notebook
- Add a Data Warehouse or SQL analytics endpoint to a notebook
- Create and run T-SQL code in a notebook
- Use the charting features to graphically represent query outcomes
- Save the query as a view or a table
- Run cross warehouse queries
- Skip the execution of non-T-SQL code
Create a T-SQL notebook
To get started with this experience, you can create a T-SQL notebook in the following two ways:
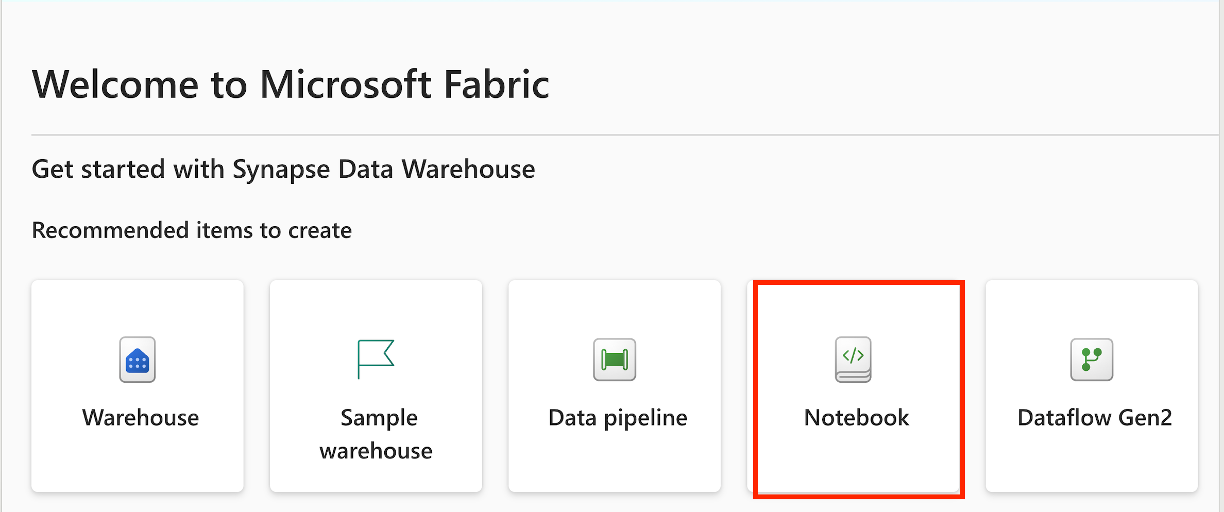
Create a T-SQL notebook from the Data Warehouse homepage: Navigate to the data warehouse experience, and choose Notebook.
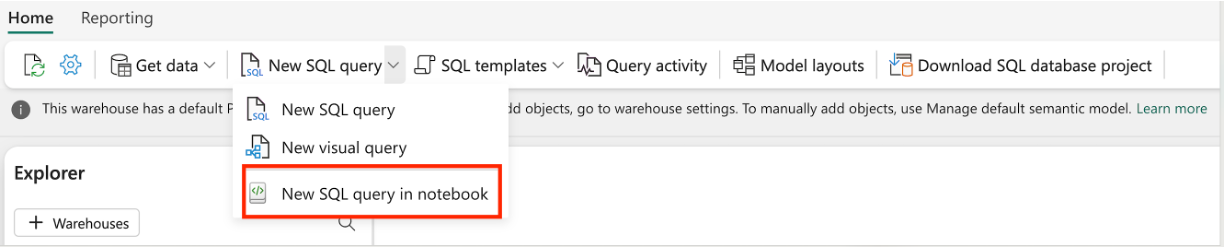
Create a T-SQL notebook from an existing warehouse editor: Navigate to an existing warehouse, from the top navigation ribbon, select New SQL query and then New T-SQL query notebook
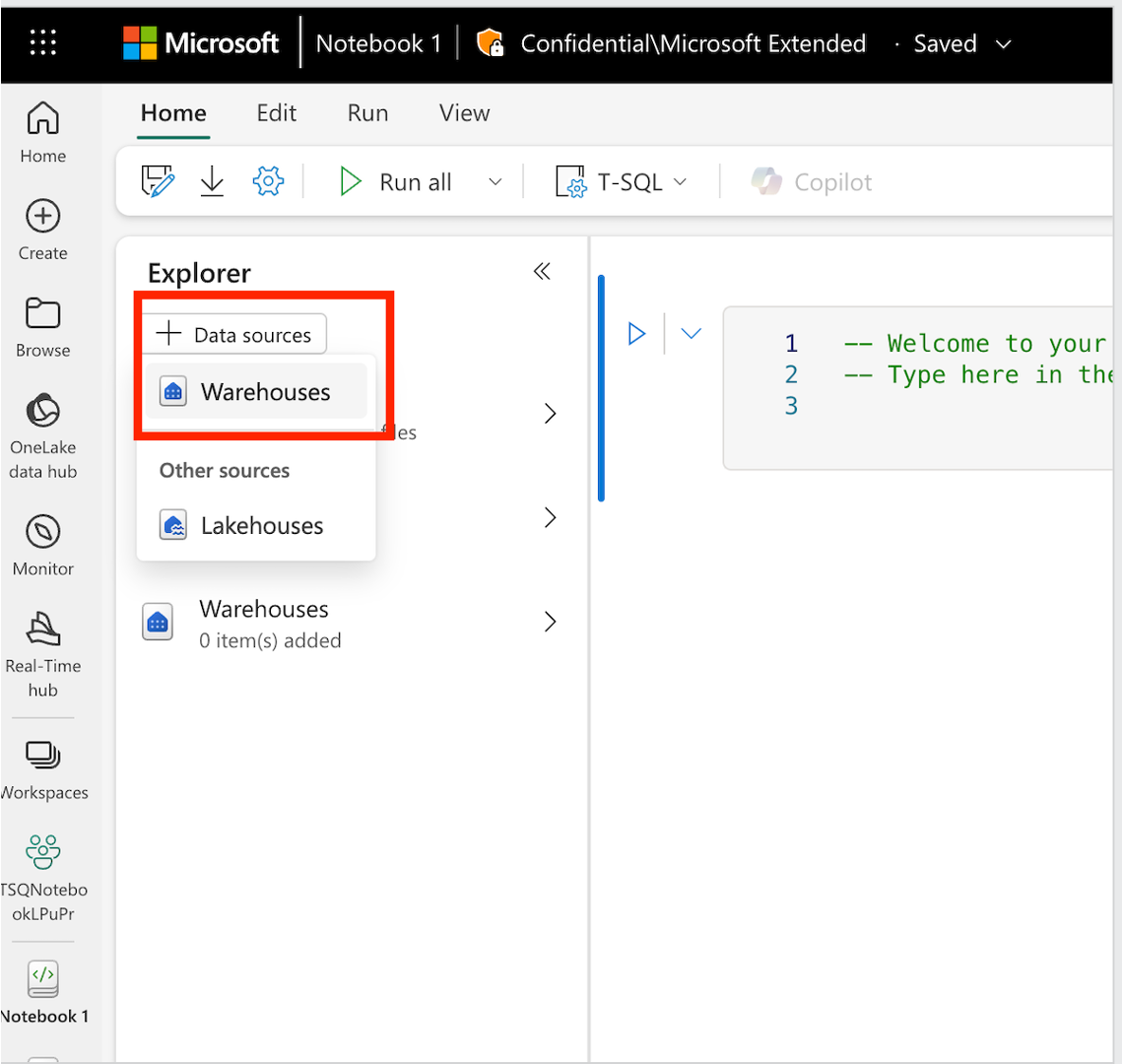
Once the notebook is created, T-SQL is set as the default language. You can add data warehouse or SQL analytics endpoints from the current workspace into your notebook.
Add a Data Warehouse or SQL analytics endpoint into a notebook
To add a Data Warehouse or SQL analytics endpoint into a notebook, from the notebook editor, select + Data sources button and select Warehouses. From the data-hub panel, select the data warehouse or SQL analytics endpoint you want to connect to.
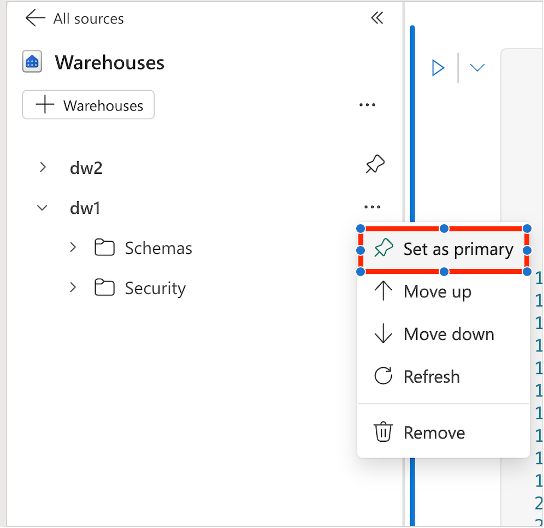
Set a primary warehouse
You can add multiple warehouses or SQL analytics endpoints into the notebook, with one of them is set as the primary. The primary warehouse runs the T-SQL code. To set it, go to the object explorer, select ... next to the warehouse, and choose Set as primary.
For any T-SQL command which supports three-part naming, primary warehouse is used as the default warehouse if no warehouse is specified.
Create and run T-SQL code in a notebook
To create and run T-SQL code in a notebook, add a new cell and set T-SQL as the cell language.

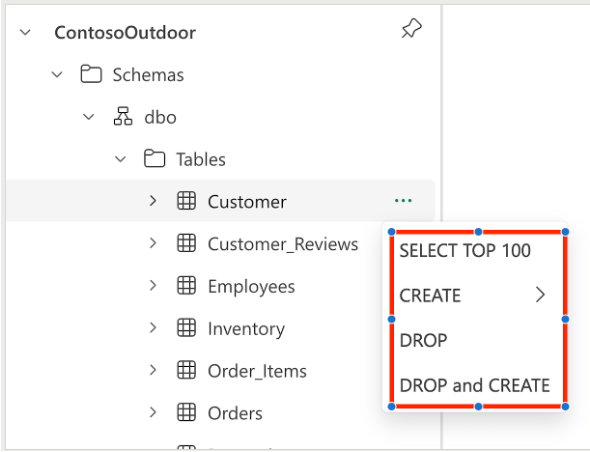
You can autogenerate T-SQL code using the code template from the object explorer's context menu. The following templates are available for T-SQL notebooks:
- Select top 100
- Create table
- Create as select
- Drop
- Drop and create
You can run one T-SQL code cell by selecting the Run button in the cell toolbar or run all cells by selecting the Run all button in the toolbar.
Note
Each code cell is executed in a separate session, so the variables defined in one cell are not available in another cell.
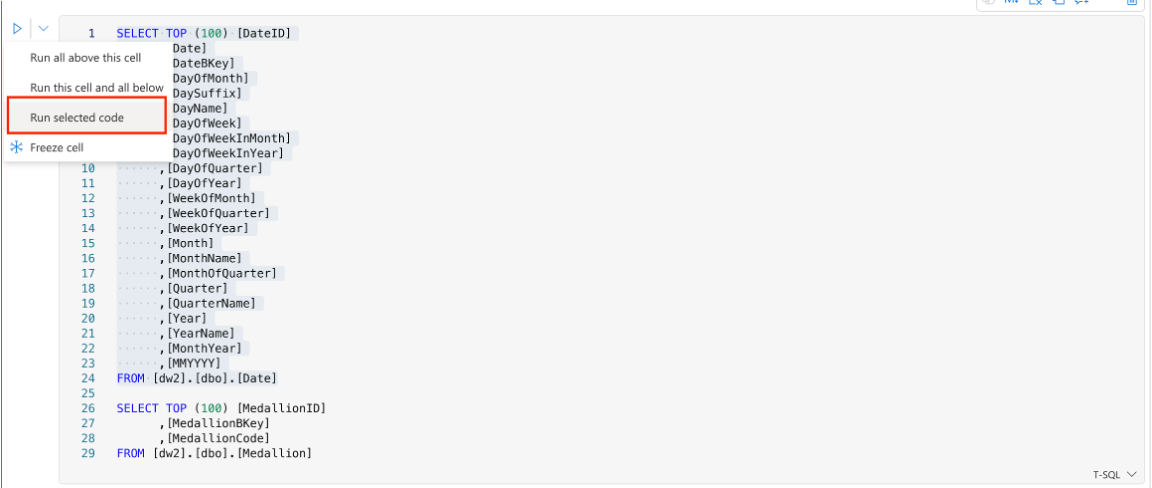
Within the same code cell, it might contain multiple lines of code. User can select part of these code and only run the selected ones. Each execution also generates a new session.
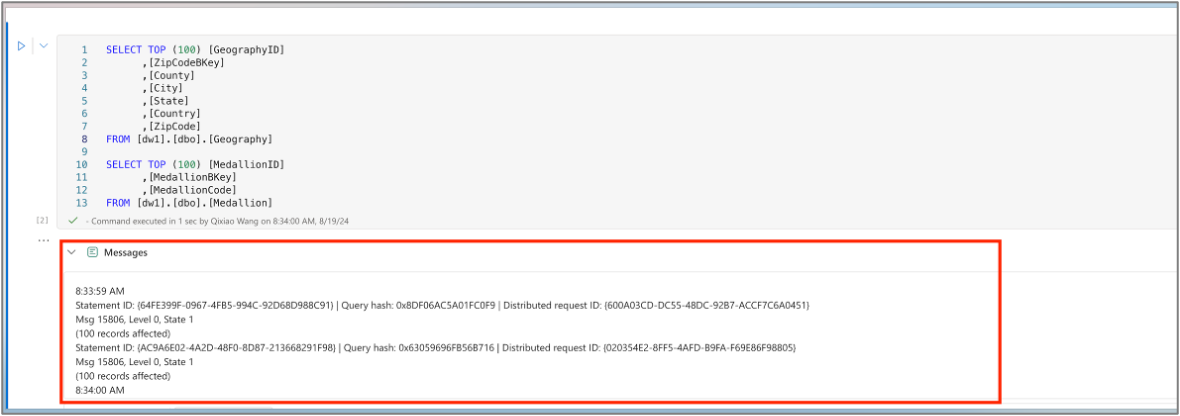
After the code is executed, expand the message panel to check the execution summary.
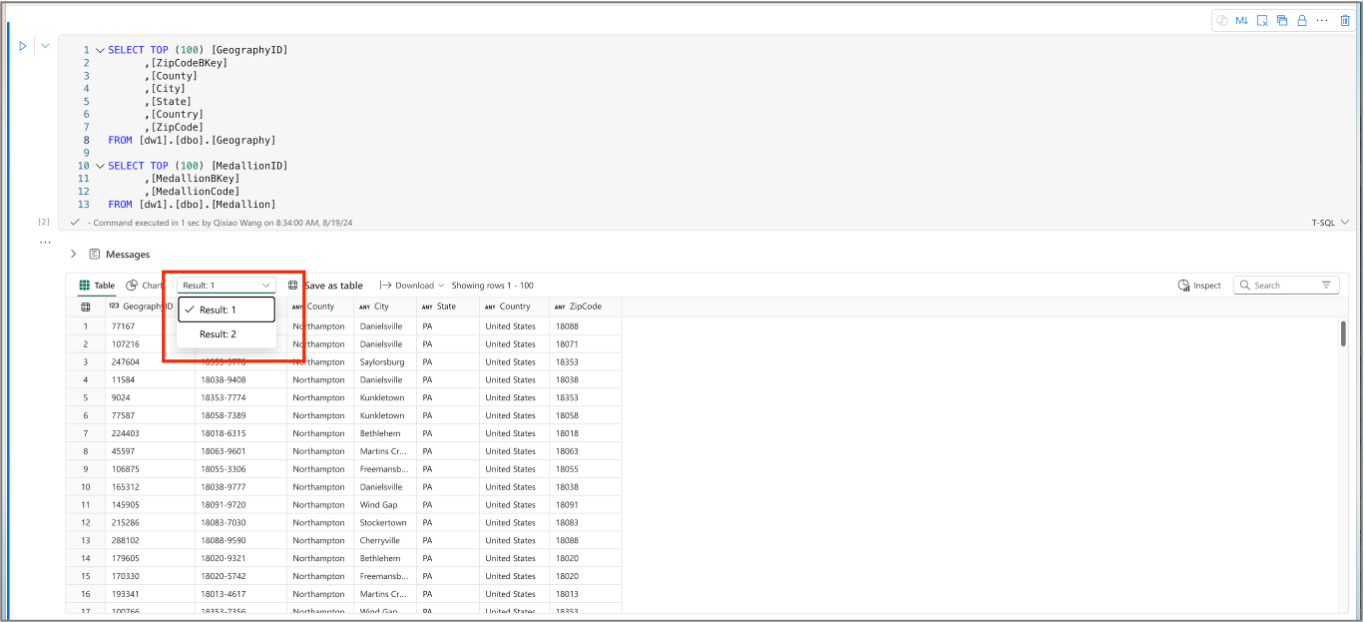
The Table tab list the records from the returned result set. If the execution contains multiple result set, you can switch from one to another via the dropdown menu.
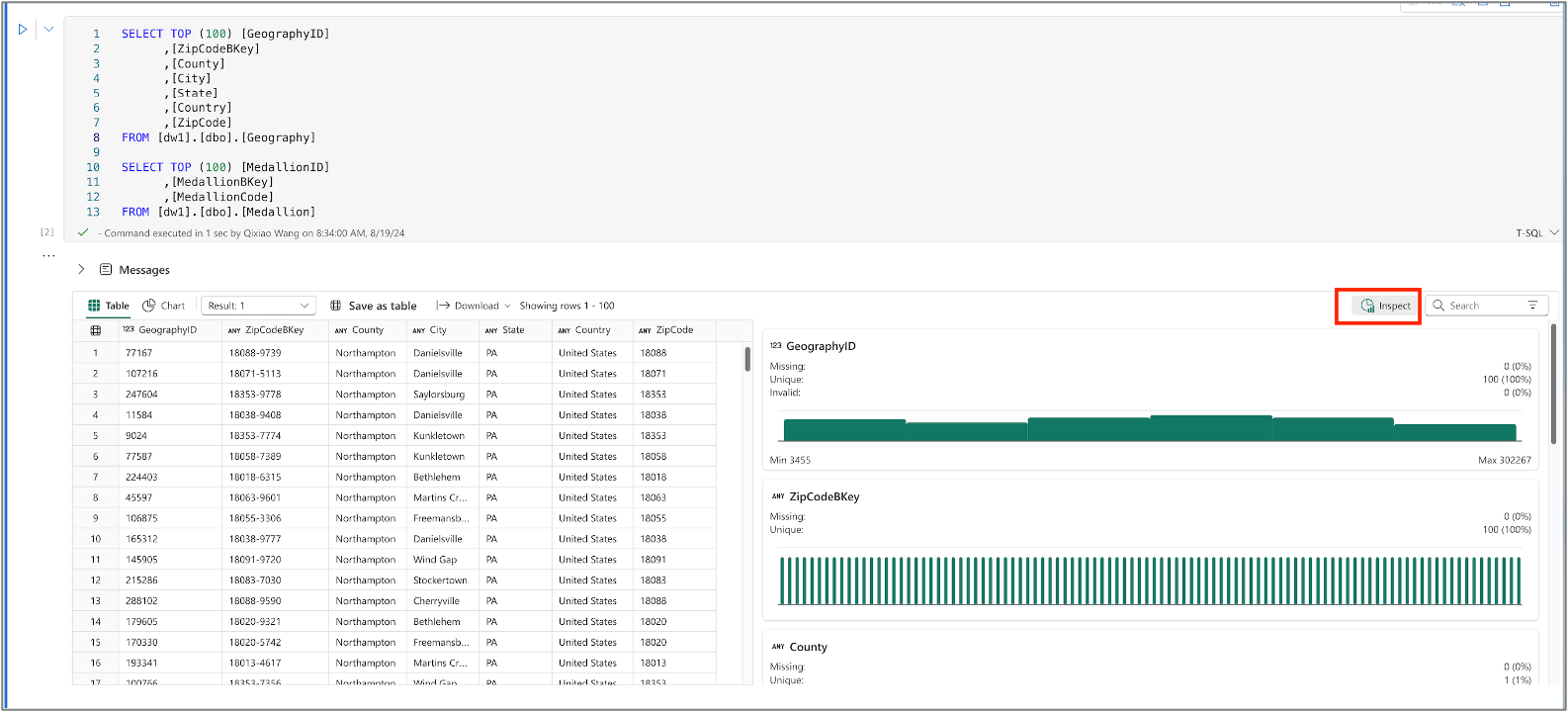
Use the charting features to graphically represent query outcomes
By clicking on the Inspect, you can see the charts which represent the data quality and distribution of each column
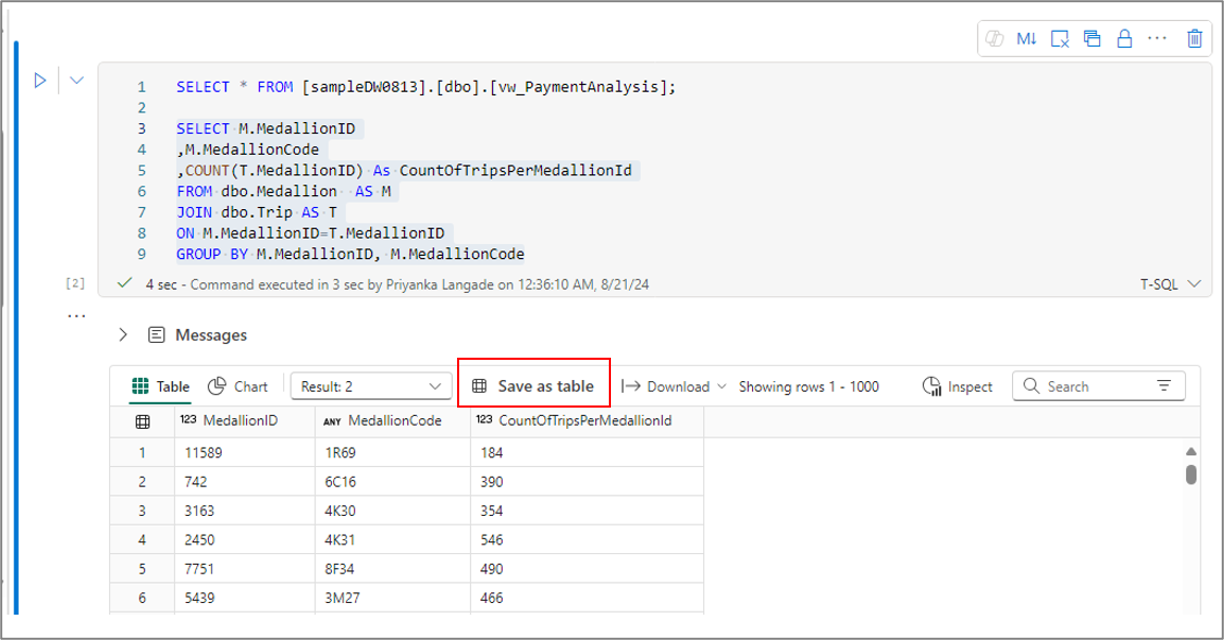
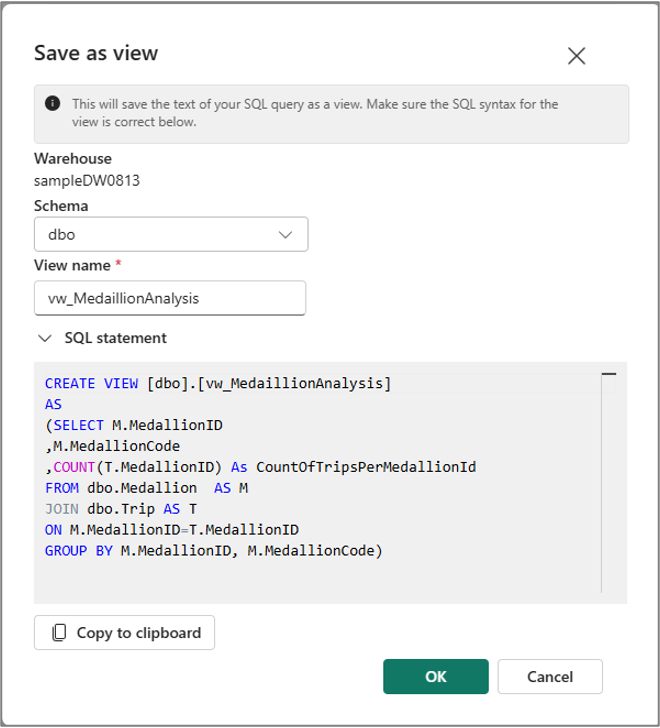
Save the query as a view or table
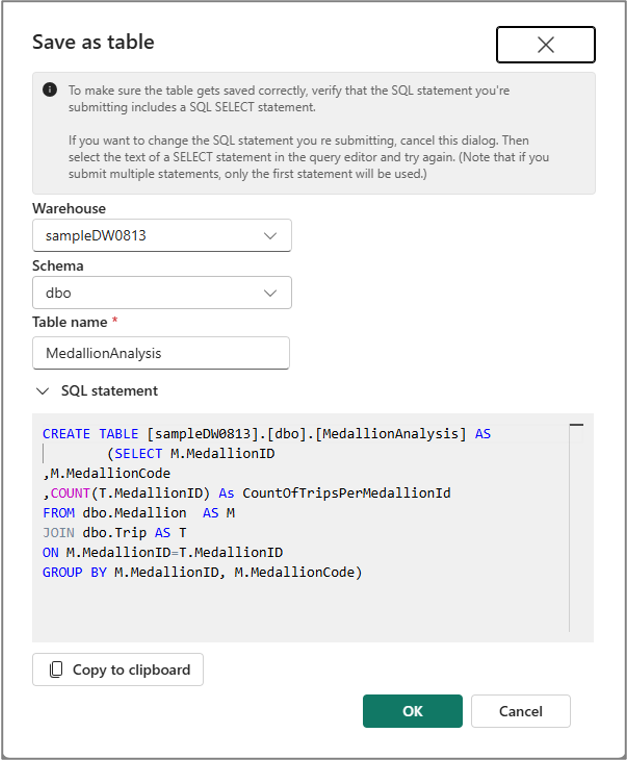
You can use Save as table menu to save the results of the query into the table using CTAS command. To use this menu, select the query text from the code cell and select Save as table menu.
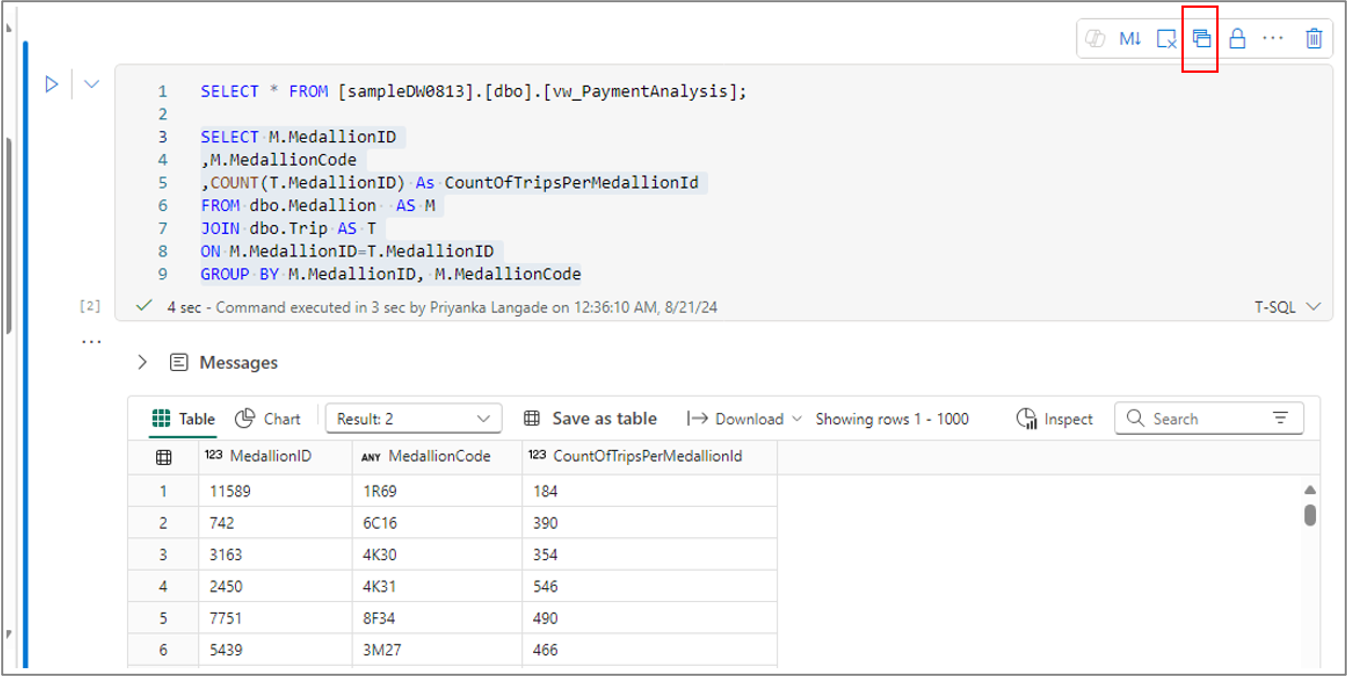
Similarly, you can create a view from your selected query text using Save as view menu in the cell command bar.
Note
Because the Save as table and Save as view menu are only available for the selected query text, you need to select the query text before using these menus.
Create View does not support three-part naming, so the view is always created in the primary warehouse by setting the warehouse as the primary warehouse.
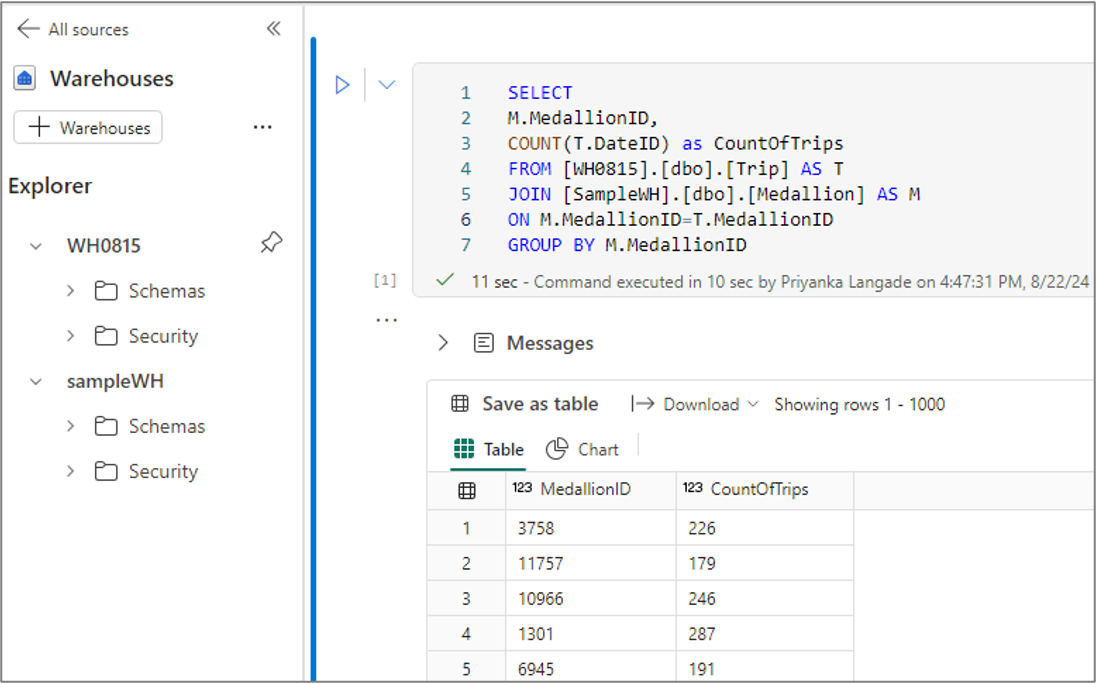
Cross warehouse query
You can run cross warehouse query by using three-part naming. The three-part naming consists of the database name, schema name, and table name. The database name is the name of the warehouse or SQL analytics endpoint, the schema name is the name of the schema, and the table name is the name of the table.
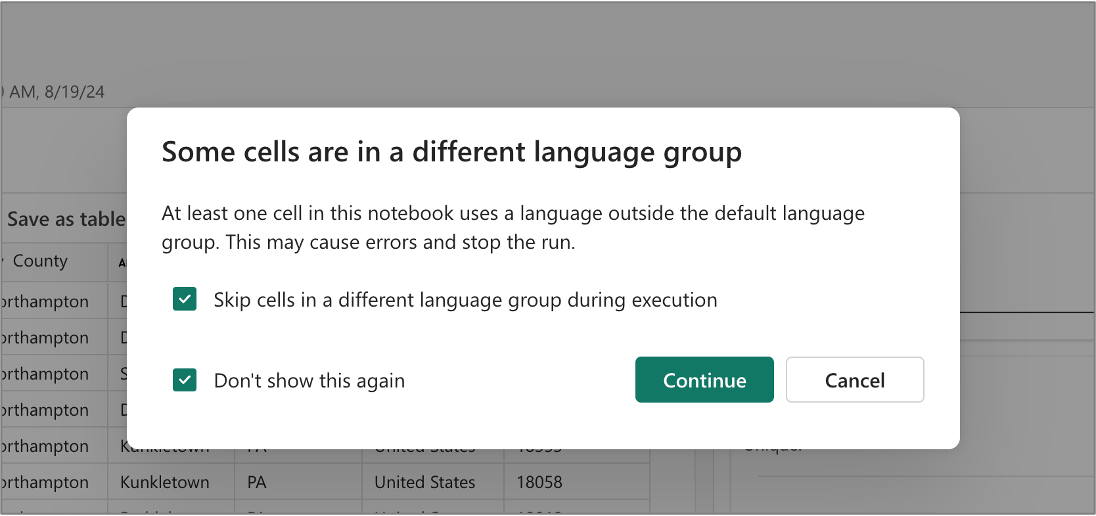
Skip the execution of non-T-SQL code
Within the same notebook, it's possible to create code cells that use different languages. For instance, a PySpark code cell can precede a T-SQL code cell. In such case, user can choose to skip the run of any PySpark code for T-SQL notebook. This dialog appears when you run all the code cells by clicking the Run all button in the toolbar.
Public preview limitations
- Parameter cell isn't yet supported in T-SQL notebook. The parameter passed from pipeline or scheduler won't be able to be used in T-SQL notebook.
- The Recent Run feature isn't yet supported in T-SQL notebook. You need to use the current data warehouse monitoring feature to check the execution history of the T-SQL notebook. See Monitor Data Warehouse article for more details.
- The monitor URL inside the pipeline execution isn't yet supported in the T-SQL notebook.
- The snapshot feature isn't yet supported in the T-SQL notebook.
- Git and Deployment pipline support isn't yet supported in the T-SQL notebook.
Related content
For more information about Fabric notebooks, see the following articles.
- What is data warehousing in Microsoft Fabric
- Questions? Try asking the Fabric Community.
- Suggestions? Contribute ideas to improve Fabric.