Geo-replication (Public Preview)
There are two features that provide geo-disaster recovery in Azure Event Hubs.
- Geo-disaster recovery (Metadata DR), which just provides replication of only metadata.
- Geo-replication (public preview), which provides replication of both metadata and the data.
Note
The Geo-replication feature is supported by only the dedicated tier.
These features shouldn't be confused with Availability Zones. Both geographic recovery features provide resilience between Azure regions such as East US and West US. Availability Zone support provides resilience within a specific geographic region, such as East US. For more information on Availability Zones, see Event Hubs Availability Zone support.
Important
- This feature is currently in public preview, and as such shouldn't be used in production scenarios.
- The following regions are currently supported in the public preview.
| Region | Region | Region |
|---|---|---|
| AustraliaCentral | GermanyNorth | NorwayWest |
| AustraliaCentral2 | GermanyWestCentral | PolandCentral |
| AustraliaEast | IsraelCentral | SouthAfricaNorth |
| AustraliaSoutheast | ItalyNorth | SouthAfricaWest |
| BrazilSoutheast | JapanEast | SoutheastAsia |
| CanadaCentral | JapanWest | SouthIndia |
| CanadaEast | JioIndiaCentral | SpainCentral |
| CentralIndia | JioIndiaWest | SwedenCentral |
| CentralUS | KoreaCentral | SwitzerlandNorth |
| CentralUSEUAP | KoreaSouth | SwitzerlandWest |
| EastAsia | MexicoCentral | UAECentral |
| EastUS2 | NorthCentralUS | UAENorth |
| FranceCentral | NorthEurope | UKSouth |
| FranceSouth | NorwayEast | UKWest |
Metadata disaster recovery vs. Geo-replication of metadata and data
The Metadata DR feature replicates configuration information for a namespace from a primary namespace to a secondary namespace. It supports a one time only failover to the secondary region. During customer initiated failover, the alias name for the namespace is repointed to the secondary namespace and then the pairing is broken. No data is replicated other than configuration information nor are permission assignments replicated.
The newer Geo-replication feature replicates configuration information and all of the data from a primary namespace to one, or more secondary namespaces. When a failover is performed, the selected secondary becomes the primary and the previous primary becomes a secondary. Users can perform a failover back to the original primary when desired.
This rest of this article focuses on the Geo-replication feature. For details on the metadata DR feature, see Event Hubs Geo-disater recovery for metadata.
Geo-replication
The public preview of the Geo-replication feature is supported for namespaces in Event Hubs self-serve scaling dedicated clusters. You can use the feature with new, or existing namespaces in dedicated self-serve clusters. The following features aren't supported with Geo-replication:
- Customer-managed keys (CMK)
- Managed identity for capture
- Virtual network features (service endpoints, or private endpoints)
- Large messages support (now in public preview)
- Kafka Transactions (now in public preview)
Some of the key aspects of Geo-data Replication public preview are:
- Primary-secondary replication model – Geo-replication is built on primary-secondary replication model, where at a given time there’s only one primary namespace that serves event producers and event consumers.
- Event Hubs performs fully managed byte-to-byte replication of metadata, event data, and consumer offset across secondaries with the configured consistency levels.
- Stable namespace fully qualified domain name (FQDN) – The FQDN doesn't need to change when promotion is performed.
- Replication consistency - There are two replication consistency settings, synchronous and asynchronous.
- User-managed promotion of a secondary to being the new primary.
Changing a secondary to being a new primary is done two ways:
- Planned: a promotion of the secondary to primary where traffic isn't processed until the new primary catches up with all of the data held by the former primary instance.
- Forced: as a failover where the secondary becomes primary as fast as possible. The Geo-replication feature replicates all data and metadata from the primary region to the selected secondary regions. The namespace FQDN always points to the primary region.
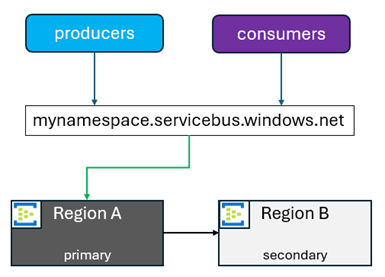
When you initiate a promotion of a secondary, the FQDN points to the region selected to be the new primary. The old primary then becomes a secondary. You can promote your secondary to be the new primary for reasons other than a failover. Those reasons can include application upgrades, failover testing, or any number of other things. In those situations, it's common to switch back when those activities are completed.
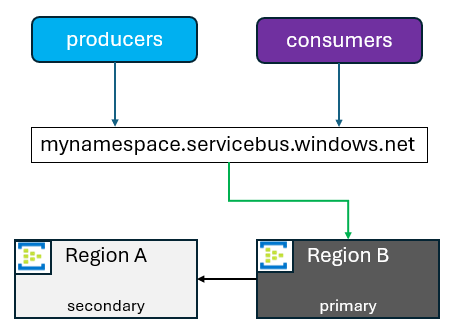
Secondary regions are added, or removed at the customer's discretion. There are some current limitations worth noting:
- There's no ability to support read-only views on secondary regions.
- There's no automatic promotion/failover capability. All promotions are customer initiated.
- Secondary regions must be different from the primary region. You can't select another dedicated cluster in the same region.
- Only one secondary is supported for public preview.
Replication consistency
There are two replication consistency configurations, synchronous and asynchronous. It's important to know the differences between the two configurations as they have an impact on your applications and your data consistency.
Asynchronous replication
With asynchronous replication enabled, all messages are committed in the primary and then sent to the secondary. Users can configure an acceptable amount of lag time that the secondary has to catch-up. When the lag for an active secondary is greater than user lag configuration, the primary region throttles incoming publish requests.
Synchronous replication
When synchronous replication is enabled, published events are replicated to the secondary, which must confirm the message before it's committed in the primary. With synchronous replication, your application publishes at the rate it takes to publish, replicate, acknowledge, and commit. It also means that your application is tied to the availability of both regions. If the secondary region goes down, messages can't be acknowledged or committed.
Replication consistency comparison
With synchronous replication:
- Latency is longer due to the distributed commit.
- Availability is tied to the availability of two regions. If one region goes down, your namespace is unavailable.
- Received data always resides in at least two regions (only two regions supported in the initial public preview).
Synchronous replication provides the greatest assurance that your data is safe. If you have synchronous replication, then when it's committed, then it's committed in all of the regions configured for Geo-replication. When synchronous replication is enabled though, your application availability can be reduced due to depending on the availability of both regions.
Enabling asynchronous replication doesn't impact latency very much, and service availability isn't impacted by the loss of a secondary region. Asynchronous replication doesn’t have the absolute guarantee that all regions have the data before it's committed it like synchronous replication does. You can also set the amount of time that your secondary can be out of sync before incoming traffic is throttled. The setting can be from 5 minutes to 1,440 minutes, which is one day. If you're looking to use regions with a large distance between them, then asynchronous replication is likely the best option for you.
Replication consistency configuration can change after Geo-replication configuration. You can go from synchronous to asynchronous, or from asynchronous to synchronous. If you go from synchronous to asynchronous, your latency, and application availability improves. If you go from asynchronous to synchronous, your secondary becomes configured as synchronous after lag reaches zero. If you're running with a continual lag for whatever reason, then you might need to pause your publishers in order for lag to reach zero and your mode to be able to switch to synchronous.
The general reasons to have synchronous replication enabled are tied to the importance of the data, specific business needs, or compliance reasons. If your primary goal is application availability rather than data assurance, then asynchronous consistency is likely the better choice.
Secondary region selection
To enable the Geo-replication feature, you need to use a primary and secondary region where the Geo-replication feature is enabled. You also need to have Event Hubs cluster already existing in both the primary and secondary regions.
The Geo-replication feature depends on being able to replicate published events from the primary to the secondary region. If the secondary region is on another continent, it has a major impact on replication lag from the primary to the secondary region. If using Geo-replication for availability and reliability reasons, you're best off with secondary regions being at least on the same continent where possible. To get a better understanding of the latency induced by geographic distance, you can learn more from Azure network round-trip latency statistics | Microsoft Learn.
Geo-replication management
The Geo-replication feature enables you to configure a secondary region to replicate configuration and data to. You can:
- Configure Geo-replication - Secondary regions can be configured on any existing namespace in a self-serve dedicated cluster in a region with the Geo-replication feature set enabled. It can also be configured during namespace creation on the same dedicated clusters. To select a secondary region, you must have a dedicated cluster available in that secondary region and the secondary region also must have the Geo-replication feature set enabled for that region.
- Configure the replication consistency - Synchronous and asynchronous replication is set when Geo-replication is configured but can also be switched afterwards. With asynchronous consistency, you can configure the amount of time that a secondary region is allowed to lag.
- Trigger promotion/failover - All promotions, or failovers are customer initiated. During promotion you can choose to make it Forced from the start, or even change your mind after a promotion has started and make it forced.
- Remove a secondary - If at any time you want to remove the geo-pairing between primary and secondary regions, you can do so and the data in the secondary region will be deleted.
Monitoring data replication
Users can monitor the progress of the replication job by monitoring the replication lag metric in Application Metrics logs.
Enable Application Metrics logs in your Event Hubs namespace following Monitoring Azure Event Hubs - Azure Event Hubs | Microsoft Learn.
Once Application Metrics logs are enabled, you need to produce and consume data from namespace for a few minutes before you start to see the logs.
To view Application Metrics logs, navigate to Monitoring section of Event Hubs page, and select Logs on the left menu. You can use the following query to find the replication lag (in seconds) between the primary and secondary namespaces.
AzureDiagnostics | where TimeGenerated > ago(1h) | where Category == "ApplicationMetricsLogs" | where ActivityName_s == "ReplicationLagThe column
count_dindicates the replication lag in seconds between the primary and secondary region.
Publishing Data
Event publishing applications can publish data to geo-replicated namespaces via stable namespace FQDN of the geo replicated namespace. The event publishing approach is the same as the non-Geo DR case and no changes to client applications are required.
Event publishing might not be available during the following circumstances:
- During Failover grace period, the existing primary region rejects any new events that are published to the event hub.
- When replication lag between primary and secondary regions reaches the max replication lag duration, the publisher ingress workload might get throttled. Publisher applications can't directly access any namespaces in the secondary regions.
Consuming Data
Event consuming applications can consume data using the stable namespace FQDN of a geo-replicated namespace. The consumer operations aren't supported, from when the failover is initiated until it's completed.
Checkpointing/Offset Management
Event consuming applications can continue to maintain offset management as they would do it with a single namespace.
Kafka
Offsets are committed to Event Hubs directly and offsets are replicated across regions. Therefore, consumers can start consuming from where it left off in the primary region.
Event Hubs SDK/AMQP
Clients that use the Event Hubs SDK need to upgrade to the April 2024 version of the SDK. The latest version of the Event Hubs SDK supports failover with an update to the checkpoint. The checkpoint is managed by users with a checkpoint store such as Azure Blob storage, or a custom storage solution. If there's a failover, the checkpoint store must be available from the secondary region so that clients can retrieve checkpoint data and avoid loss of messages.
Pricing
Event Hubs dedicated clusters are priced independently of geo-replication. Use of geo-replication with Event Hubs dedicated requires you to have at least two dedicated clusters in separate regions. The dedicated clusters used as secondary instances for geo-replication can be used for other workloads. There's a charge for geo-replication based on the published bandwidth * the number of secondary regions. The geo-replication charge is waived in early public preview.
Related content
To learn how to use the Geo-replication feature, see Use Geo-replication.