MSDTC Supported Configurations
The MSDTC Configuration Conundrum
MSDTC configuration is not as straight forward as you might think. It's a different choice if you are using a local MSDTC, clustered MSDTC, on-premises, Azure, Failover Cluster, or Availability Group. Every one of those variables leads you down a different path with different choices. The goal of this article is to clarify those choices.
If you think you do not use the MSDTC, you better check again. I frequently see folks using it that do not realize it. The most common is Linked Servers. You got it. If you are using Linked Servers, you're using the MSDTC.
You are no longer required to install an MSDTC with a SQL Failover Cluster starting in SQL Server 2008. That does not mean you do not need an MSDTC configuration. If you wanted to make your application database highly available, but your application did not use the MSDTC you were being required to install one anyway. That limitation is what was removed, not that you simply didn't need a clustered MSDTC.
How it Works
Let's start with a simple description of the purpose of the MSDTC. First the application starts a transaction that queries two different servers. That's a distributed transaction. Since parts of the query are going to two different locations, something has to monitor it to ensure transaction consistency. That's the job of the MSDTC. What we do not want is for the transaction to go make updates to the first destination and commit that without making sure the updates to the second destination also commit. If either one of them fails we want to roll it back and if they succeed we want to commit them.
The MSDTC logs the transactions in its own log so it can track them. This is key to remember. It's the availability of this log that we care about.
Stand-alone
We will continue with a stand-alone server to see how this works and then we'll work through Failover Cluster Instances and Availability Groups. On a stand-alone all we have is the local MSDTC. When our application runs a transaction that inserts rows in a database on this server and also on another server, the local MSDTC enlists in the transaction. Its job is to log the transactions and ensure any in-doubt transactions are either aborted (rolled back) or committed (rolled forward). There is not much ambiguity in this scenario since it is not designed to be highly available, but it gives us a basis on which to build.
[caption id="attachment_2018" align="aligncenter" width="262"]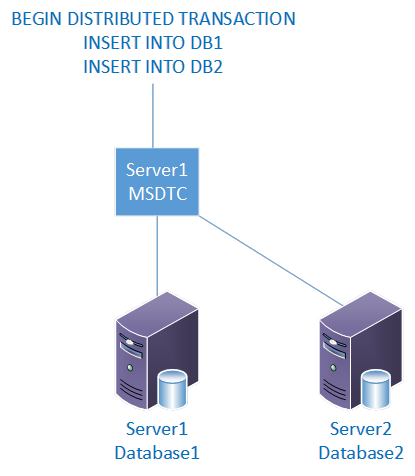
Failover Cluster
Here is where things get a bit more interesting. We have a choice to use either a local MSDTC or a clustered MSDTC. Using a clustered MSDTC configuration is straightforward. If Node1 fails, both the SQL Failover Cluster Instance and the Clustered MSDTC fail over to Node2. Since the Clustered MSDTC is using shared storage, it still has its log and can handle any in-doubt transactions.
[caption id="attachment_2020" align="aligncenter" width="300"]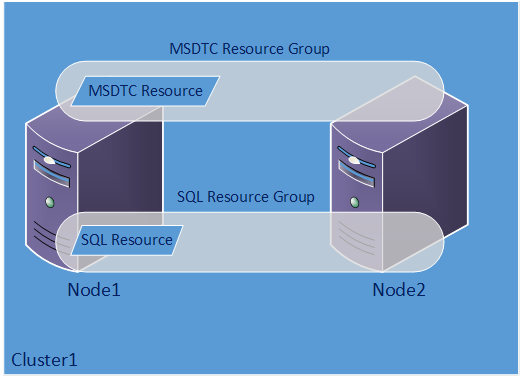
What happens if we choose a Local MSDTC? This will mean that your MSDTC is not highly available, but it's more available than you might think. If Node1 fails and the local MSDTC on that node has an in-doubt transaction, the local MSDTC on Node2 kicks in after the failover. The local MSDTC on Node2 tries to contact the local MSDTC on Node1 and retrieve the status of any in-doubt transactions. This process is attempted 3 times. If the old primary (Node1) still cannot be contacted, SQL takes its direction from the In-doubt Transaction Configuration or "in-doubt xact resolution" in sp_configure.
[caption id="attachment_2021" align="aligncenter" width="300"]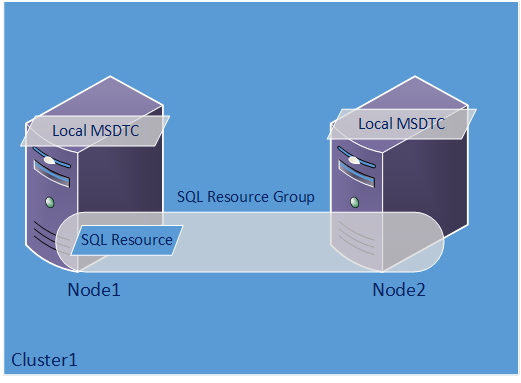
You can configure the In-doubt Transaction Configuration for either Abort(2) which rolls the transactions back, or Commit(1) which rolls the transactions forward. If this setting is not configured (default) then the database is put into suspect mode. You can manually resolve the in-doubt transactions using the KILL command and bring the database online. See this article for specific instructions for this scenario.
[caption id="attachment_2022" align="aligncenter" width="521"]
Availability Group
The MSDTC works exactly the same in an Availability Group as it does in a Failover Cluster Instance, with a couple of distinctions. The first is on what versions it is supported. The versions also differ in the features they support. Here is what that looks like.
- No support in Availability Groups until SQL 2016
- SQL 2016
- Cross instance transactions are supported
- Cross database transactions within same SQL AG Instance are NOT supported
- SQL 2016 SP2
- Cross instance transactions are supported
- Cross database transactions within same SQL AG Instance are supported
- SQL 2017
- Cross instance transactions are supported
- Cross database transactions within same SQL AG Instance are supported
The second distinction is that you need to create the availability group using the WITH clause of DTC_SUPPORT = PER_DB. In SQL Server 2017 and SQL Server 2016 SP2 you can now use the ALTER statement to change this after AG creation. Read here for details on its usage. What's important about this distinction is what it means under the hood. In a Failover Cluster Instance, the instance itself becomes the Resource Manager, but in an Availability Group each database becomes its own Resource Manager. Remember that in an AG we have completely different instances of SQL running on each replica so we cannot use an instance level Resource Manager as the ID would be different. The RMID comes over with the database when it fails over allowing it to resolve in-doubt transactions. An FCI is a single instance so we don't have this problem as the RMID is consistent across failovers. Read this to get a better understanding of the role of the Resource Manager.
Availability Group Local MSDTC versus Clustered MSDTC
- We created database DB1 in an Availability Group with the primary on Node1 and secondary on Node2
- We did some DTC transactions and Node1 went down. There were some in-doubt transactions. DB1 will fail over to Node2.
- If using a local DTC:
- What really happens
- SQL Server uses agile recovery to recover in-doubt transactions. The Agile Recovery concept actually happens at recovery time, when the resource manager provides the PrepareInfo back to the MSDTC it is connected to at recovery time. If the PrepareInfo provided by the resource manager at recovery time indicates that the PrepareInfo came from a DIFFERENT MSDTC than the MSDTC the RM is currently connected to, the MSDTC proxy will connect to the “original” MSDTC “under the covers” to find out the outcome of the transaction. So, if an RM is connected to DTC1 at Prepare time, the PrepareInfo identifies DTC1. If the RM is connected to DTC2 at Recovery time, the DTC proxy will ALSO connect to DTC1 to find out the outcome because DTC2 doesn’t know anything about the transaction.
- An easier way to think about it
- SQL Server on Node2 asks MSDTC on Node2 about the outcome for the transactions. MSDTC on Node2 figures out that the MSDTC on Node1 knows the outcome of the transaction from the prepare info and hence MSDTC on Node2 asks MSDTC on Node1 for the outcome
- If MSDTC on Node1 is not available then MSDTC on Node2 cannot get the outcome until MSDTC on Node1 is available (because these outcomes are present in the MSDTC log). At this point SQL follows the In-doubt Transaction Configuration setting. The database will be put in SUSPECT mode if the setting is not configured
- What really happens
- If using a clustered MSDTC:
- SQL directly connects to the clustered MSDTC (as this also would have failed over to Node2) to recover the outcome
Azure
In Azure IaaS, the functionality described above does not change. What gets more complicated is the storage for a clustered MSDTC, as it requires the storage to be shared. Microsoft has partners that offer options for shared storage in Azure, which include solutions like iSCSI among others. We also have a native Microsoft solution when using Storage Spaces Direct (S2D). Although you can use this for SQL Failover Cluster Instance Resources in Windows Server 2016, you cannot use it for the MSDTC Resource until Windows Server 2016 Release Build Version 1709. Windows Server 2016 Release Build Version 1709 and 1803 are core builds and do not have the Desktop Experience (GUI). Windows Server 2019 is the first build to support this functionality and also contain the Desktop Experience.
Read here for more on builds that support the MSDTC on S2D in Azure. That article includes a video walk through of building the entire solution with an FCI on a Windows Cluster with the MSDTC on S2D in an Azure VM.
Another difference in Azure is outside of the servers and MSDTC, but is required to make it work properly. A clustered MSDTC has a network name and in Azure we need an internal load balancer to direct that traffic. This is important because you need to use a standard load balancer (not basic) which in turn means you need to use standard IP addresses. You will need to keep that in mind when building your VMs. Make sure to check out the article in the above paragraph as it describes and demonstrates this configuration.
MSDTC Throughput
I do want to mention one other noteworthy thing to think about as you design your architecture. If you have multiple instances of SQL Server running and you create one clustered MSDTC in its own resource group, every instance uses that same MSDTC. If you have a lot of distributed transactions this can become a bottleneck. The other issue that can get introduced with a single clustered MSDTC in its own role, is that you cannot guarantee it will run on the same node as your SQL instance. You could easily have an instance running on Node2 and using an MSDTC running on Node1. This can introduce network latency. Refer back to the second diagram in this post titled, "FCI with a Clustered MSDTC Configuration" and imagine the SQL Resource is running on Node2 while the MSDTC Resource remains on Node1.
The best practice is to have 1 MSDTC per instance and put it in the same role as the instance. This makes sure the MSDTC for that instance is running on the same node and spreads the load out. Here is how that would look with two instances of SQL Server and each of them having their own MSDTC.
[caption id="attachment_2029" align="aligncenter" width="300"]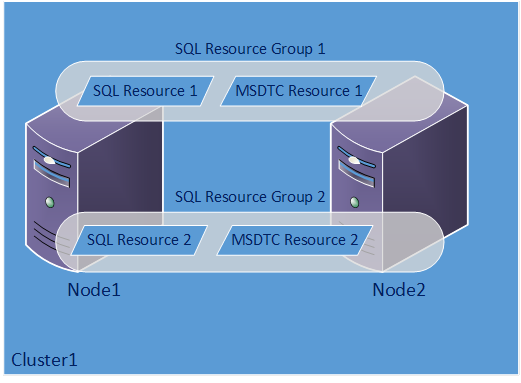
MSDTC Precedence
It is wise to verify which MSDTC service each SQL instance is using. Below is the precedence in which SQL Server chooses which MSDTC it will use. Note that SQL Server makes this decision at startup. If you make a change, you have to restart SQL Server for it to take effect. You can manually map an instance of SQL Server to an instance of the MSDTC, and the first instance installed of the MSDTC is considered the default instance.
- MSDTC in same role
- Mapped Instance of MSDTC
- Cluster Default MSDTC Instance
- Local MSDTC
Support Matrix
This matrix should help guide you as you design your architecture and decide on versions and features.
| Configuration | Cross Instance | Cross Database | Local MSDTC | Clustered MSDTC |
| SQL 2014 and Below AG | MSDTC Not Supported | MSDTC Not Supported | MSDTC Not Supported | MSDTC Not Supported |
| SQL 2016 AG | Yes | No | Yes* | Yes |
| SQL 2016 SP2 AG | Yes | Yes | Yes* | Yes |
| SQL 2017 AG | Yes | Yes | Yes* | Yes |
| SQL 2016 FCI | Yes | Yes | Yes* | Yes |
| SQL 2017 FCI | Yes | Yes | Yes* | Yes |
| Azure VM FCI | =SQL Version | =SQL Version | No Load Balancer | Standard Load Balancer, Shared Storage, Windows Build 1709 or Greater |
| Azure VM AG | =SQL Version | =SQL Version | No Load Balancer | Standard Load Balancer, Shared Storage, Windows Build 1709 or Greater |
Legend
Yes* ----> In-doubt Transaction Manager Policy
Comments
- Anonymous
November 03, 2018
Great article