RedPrairie: Removing Unneeded Table Indices
By David Erickson, RedPrairie
I wrote some internal notes to our developers recently, that I called "Lessons from the Lab”. I had the pleasure of joining RedPrairie’s WM Product Development team at a Microsoft testing lab in Dallas, Texas, with the intent of benchmarking WM 2009.2 and 2010.1 on SQL Server 2008 with various database configurations.
Along the way, we knocked out several known performance issues and discovered (and fixed) a few more that were below the radar. (I guess this is the point in the movies where the voiceover would say, “and we learned a little something about ourselves, too.”) An additional benefit of the visit came in the form of new tricks and tips, learned straight from the source: a Microsoft DBA.
I discovered the benefits of Index Reduction. Our products must distribute indexes to anticipate many different uses of the application. Since no one customer uses every feature and every field, it stands to reason that, for any given customer, some indexes will never be used.
Microsoft supplied a handy SQL statement to identify unused indexes:
-- To view index usage
select OBJECT_NAME(object_id) index_name, *
from sys.dm_db_index_usage_stats
order by 5 desc
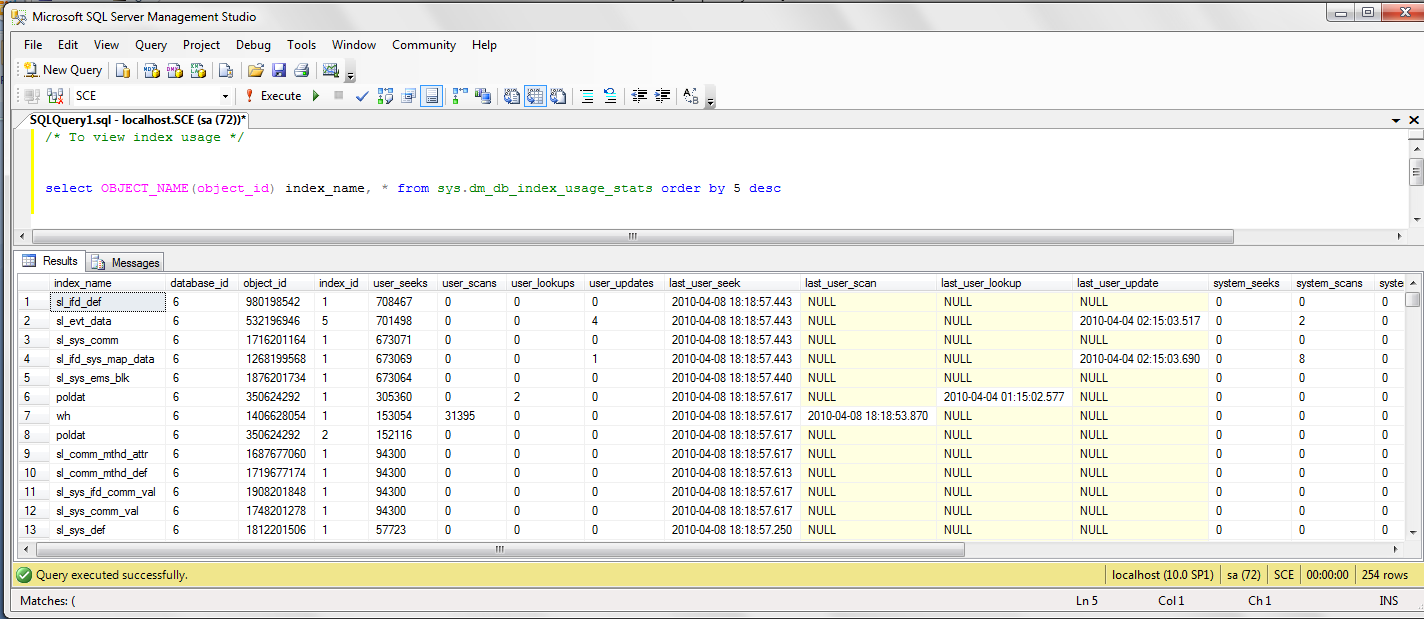
Make sure to run this from the application database! Also, this is of course only a wise endeavor after the system has been live for quite a while and the normal usage patterns have stabilized. Only indexes that the customer will never need (for instance, indexes on fields you are sure they will never use) can safely be disabled.
Disabling Indexes
SQL Server supports the disabling of an index, which is a better option than simply dropping it. A disabled index stays in the schema, which can be nice for support purposes (rather than making some poor troubleshooter wonder why this instance is missing standard indexes). Another practical example is a massive data load that happens outside of normal operations. The load will go faster if the indexes can be ignored during the “inserts” and then re-built when the batch is complete. Since the index definition stays in the schema, writing scripts to find all the indexes on a table and then either disabling or re-building them can be done without the specific DDL that created them in the first place.
-- To disable an index
[alter index <index name> disable]
-- To re-enable an index, it must be re-built
[alter index <index name> rebuild]
Ken Lassesen wrote about this earlier on this blog. He has supplied an updated version of his script below which disables instead of dropping the indices.
DECLARE @MinCount int = 10000,
@Index int =1,
@Cmd nvarchar(max)
DECLARE @IndexToDisAble TABLE(TName SysName, SName SysName, IName SysName, ID Int Identity(1,1))
INSERT INTO @IndexToDisAble
SELECT TableName = OBJECT_NAME(s.[object_id]),
SchemaName=SCHEMA_NAME(o.[schema_id]),
IndexName = i.name
FROM sys.dm_db_index_usage_stats s
JOIN sys.objects O ON s.[object_id] = O.[object_id]
JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
WHERE OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0 -- Only ISV defined.
AND user_seeks = 0
AND user_scans = 0
AND user_lookups = 0
AND i.name IS NOT NULL -- Ignore HEAP indexes.
AND user_updates > @MinCount
AND is_primary_key = 0
ORDER BY user_updates DESC
-- Do not disable any index used for referential integrity
DELETE FROM @IndexToDisAble
FROM @IndexToDisAble JOIN INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
ON UNIQUE_CONSTRAINT_NAME=IName
AND UNIQUE_CONSTRAINT_SCHEMA=SNAME
WHILE EXISTS(SELECT 1 FROM @IndexToDisAble )
BEGIN
SELECT @CMD= 'ALTER INDEX ['+IName+'] ON ['+SName+'].['+TName+'] DISABLE'
FROM @IndexToDisAble WHERE @Index=ID
BEGIN TRY
EXEC (@CMD)
END TRY
BEGIN CATCH
SET @CMD='Error: '+@CMD
END CATCH
DELETE FROM @IndexToDisAble WHERE @Index=ID
SET @Index=@Index+1
END
Older Versions
Regardless of which version you are running, disabling unused indexes may improve performance.
Comments
Anonymous
January 01, 2003
Thanks, Roman. The two most important columns are user_seeks and user_scans. User_lookups will be populated for clustered_indexes, you can assume it will be zero for non-clustered indexes. So if user_scans + user_seeks + user_lookups = 0, the index is a good candidate for disabling, especially if user_updates > 0 (this would indicate that you are paying the cost for updating the index for literally no benefit). Note that I used the word "candidate" - as you still need to confirm that the usage patterns of the past, reasonably predict the future. In other words, this method yields a first indicator, not a final decision. I found a good link on MSDN that explains the whole view: msdn.microsoft.com/.../ms188755.aspx DaveAnonymous
October 05, 2011
Very interesting post David. In the script that you are using to identify how many times the users have used indexes, which fields are important in determining an index that is not being used? Could you explain the seek, scan, lookup, and update fields?