High availability Kubernetes cluster pattern
This article describes how to architect and operate a highly available Kubernetes-based infrastructure using Azure Kubernetes Service (AKS) Engine on Azure Stack Hub. This scenario is common for organizations with critical workloads in highly restricted and regulated environments. Organizations in domains such as finance, defense, and government.
Context and problem
Many organizations are developing cloud-native solutions that leverage state-of-the-art services and technologies like Kubernetes. Although Azure provides datacenters in most regions of the world, sometimes there are edge use-cases and scenarios where business critical applications must run in a specific location. Considerations include:
- Location sensitivity
- Latency between the application and on-premises systems
- Bandwidth conservation
- Connectivity
- Regulatory or statutory requirements
Azure, in combination with Azure Stack Hub, addresses most of these concerns. A broad set of options, decisions, and considerations for a successful implementation of Kubernetes running on Azure Stack Hub is described below.
Solution
This pattern assumes that we have to deal with a strict set of constraints. The application must run on-premises and all personal data must not reach public cloud services. Monitoring and other non-PII data can be sent to Azure and be processed there. External services like a public Container Registry or others can be accessed but might be filtered through a firewall or proxy server.
The sample application shown here is designed to use Kubernetes-native solutions whenever possible. This design avoids vendor lock-in, instead of using platform-native services. As an example, the application uses a self-hosted MongoDB database backend instead of a PaaS service or external database service. For more information see the Introduction to Kubernetes on Azure learning path.

The preceding diagram illustrates the application architecture of the sample application running on Kubernetes on Azure Stack Hub. The app consists of several components, including:
- An AKS Engine based Kubernetes cluster on Azure Stack Hub.
- cert-manager, which provides a suite of tools for certificate management in Kubernetes, used to automatically request certificates from Let's Encrypt.
- A Kubernetes namespace that contains the application components for the front end (ratings-web), api (ratings-api), and database (ratings-mongodb).
- The Ingress Controller that routes HTTP/HTTPS traffic to endpoints within the Kubernetes cluster.
The sample application is used to illustrate the application architecture. All components are examples. The architecture contains only a single application deployment. To achieve high availability (HA), we'll run the deployment at least twice on two different Azure Stack Hub instances - they can run either in the same location or in two (or more) different sites:
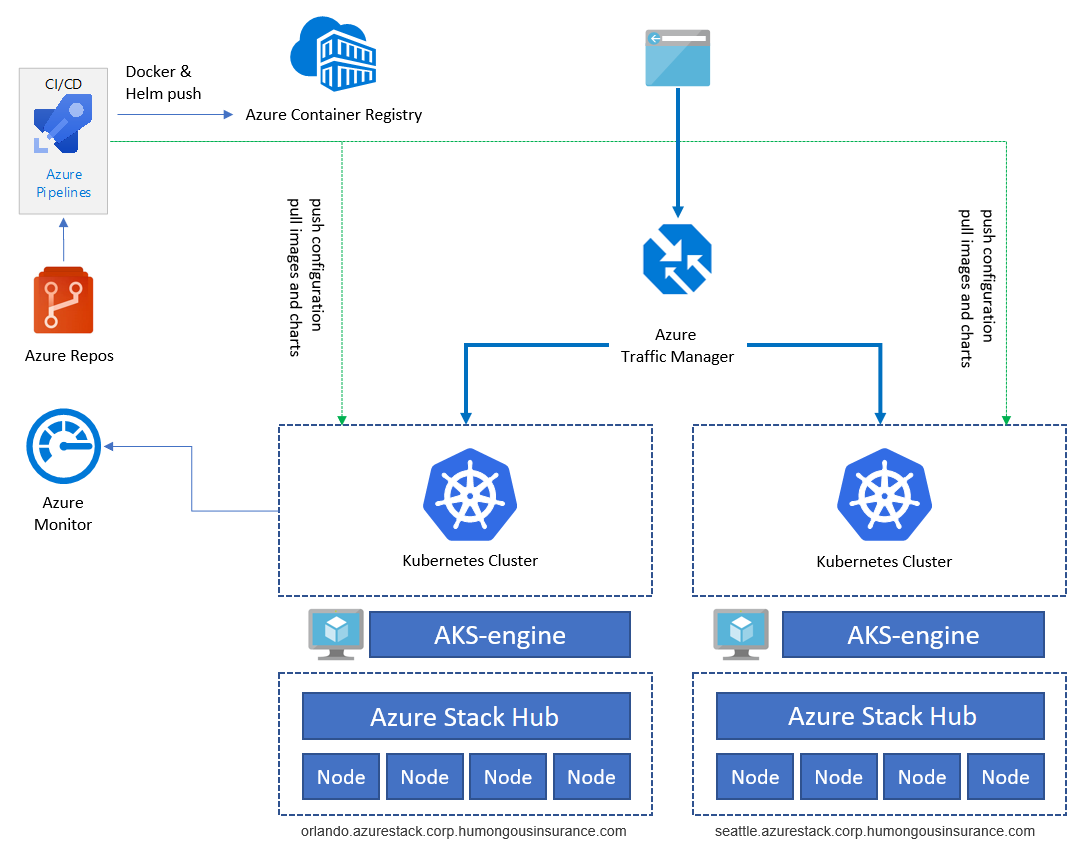
Services like Azure Container Registry, Azure Monitor, and others, are hosted outside Azure Stack Hub in Azure or on-premises. This hybrid design protects the solution against outage of a single Azure Stack Hub instance.
Components
The overall architecture consists of the following components:
Azure Stack Hub is an extension of Azure that can run workloads in an on-premises environment by providing Azure services in your datacenter. Go to Azure Stack Hub overview to learn more.
Azure Kubernetes Service Engine (AKS Engine) is the engine behind the managed Kubernetes service offering, Azure Kubernetes Service (AKS), that is available in Azure today. For Azure Stack Hub, AKS Engine allows us to deploy, scale, and upgrade fully featured, self-managed Kubernetes clusters using Azure Stack Hub's IaaS capabilities. Go to AKS Engine Overview to learn more.
Go to Known Issues and Limitations to learn more about the differences between AKS Engine on Azure and AKS Engine on Azure Stack Hub.
Azure Virtual Network (VNet) is used to provide the network infrastructure on each Azure Stack Hub for the Virtual Machines (VMs) hosting the Kubernetes cluster infrastructure.
Azure Load Balancer is used for the Kubernetes API Endpoint and the Nginx Ingress Controller. The load balancer routes external (for example, Internet) traffic to nodes and VMs offering a specific service.
Azure Container Registry (ACR) is used to store private Docker images and Helm charts, which are deployed to the cluster. AKS Engine can authenticate with the Container Registry using an Azure AD identity. Kubernetes doesn't require ACR. You can use other container registries, such as Docker Hub.
Azure Repos is a set of version control tools that you can use to manage your code. You can also use GitHub or other git-based repositories. Go to Azure Repos Overview to learn more.
Azure Pipelines is part of Azure DevOps Services and runs automated builds, tests, and deployments. You can also use third-party CI/CD solutions such as Jenkins. Go to Azure Pipeline Overview to learn more.
Azure Monitor collects and stores metrics and logs, including platform metrics for the Azure services in the solution and application telemetry. Use this data to monitor the application, set up alerts and dashboards, and perform root cause analysis of failures. Azure Monitor integrates with Kubernetes to collect metrics from controllers, nodes, and containers, as well as container logs and master node logs. Go to Azure Monitor Overview to learn more.
Azure Traffic Manager is a DNS-based traffic load balancer that enables you to distribute traffic optimally to services across different Azure regions or Azure Stack Hub deployments. Traffic Manager also provides high availability and responsiveness. The application endpoints must be accessible from the outside. There are other on-premises solutions available as well.
Kubernetes Ingress Controller exposes HTTP(S) routes to services in a Kubernetes cluster. Nginx or any suitable ingress controller can be used for this purpose.
Helm is a package manager for Kubernetes deployment, providing a way to bundle different Kubernetes objects like Deployments, Services, Secrets, into a single "chart". You can publish, deploy, control version management, and update a chart object. Azure Container Registry can be used as a repository to store packaged Helm Charts.
Design considerations
This pattern follows a few high-level considerations explained in more detail in the next sections of this article:
- The application uses Kubernetes-native solutions, to avoid vendor lock-in.
- The application uses a microservices architecture.
- Azure Stack Hub doesn't need inbound but allows outbound Internet connectivity.
These recommended practices will apply to real-world workloads and scenarios as well.
Scalability considerations
Scalability is important to provide users consistent, reliable, and well-performing access to the application.
The sample scenario covers scalability on multiple layers of the application stack. Here's a high-level overview of the different layers:
| Architecture level | Affects | How? |
|---|---|---|
| Application | Application | Horizontal scaling based on the number of Pods/Replicas/Container Instances* |
| Cluster | Kubernetes cluster | Number of Nodes (between 1 and 50), VM-SKU-sizes, and Node Pools (AKS Engine on Azure Stack Hub currently supports only a single node pool); using AKS Engine's scale command (manual) |
| Infrastructure | Azure Stack Hub | Number of nodes, capacity, and scale units within an Azure Stack Hub deployment |
* Using Kubernetes' Horizontal Pod Autoscaler (HPA); automated metric-based scaling or vertical scaling by sizing the container instances (cpu/memory).
Azure Stack Hub (infrastructure level)
The Azure Stack Hub infrastructure is the foundation of this implementation, because Azure Stack Hub runs on physical hardware in a datacenter. When selecting your Hub hardware, you need to make choices for CPU, memory density, storage configuration, and number of servers. To learn more about Azure Stack Hub's scalability, check out the following resources:
Kubernetes cluster (cluster level)
The Kubernetes cluster itself consists of, and is built on top of Azure (Stack) IaaS components including compute, storage, and network resources. Kubernetes solutions involve master and worker nodes, which are deployed as VMs in Azure (and Azure Stack Hub).
- Control plane nodes (master) provide the core Kubernetes services and orchestration of application workloads.
- Worker nodes (worker) run your application workloads.
When selecting VM sizes for the initial deployment, there are several considerations:
Cost - When planning your worker nodes, keep in mind the overall cost per VM you'll incur. For example, if your application workloads require limited resources, you should plan to deploy smaller sized VMs. Azure Stack Hub, like Azure, is normally billed on a consumption basis, so appropriately sizing the VMs for Kubernetes roles is crucial to optimizing consumption costs.
Scalability - Scalability of the cluster is achieved by scaling in and out the number of master and worker nodes, or by adding additional node pools (not available on Azure Stack Hub today). Scaling the cluster can be done based on performance data, collected using Container Insights (Azure Monitor + Log Analytics).
If your application needs more (or fewer) resources, you can scale out (or in) your current nodes horizontally (between 1 and 50 nodes). If you need more than 50 nodes, you can create an additional cluster in a separate subscription. You can't scale up the actual VMs vertically to another VM size without redeploying the cluster.
Scaling is done manually using the AKS Engine helper VM that was used to deploy the Kubernetes cluster initially. For more information, see Scaling Kubernetes clusters
Quotas - Consider the quotas you've configured when planning out an AKS deployment on your Azure Stack Hub. Make sure each subscription has the proper plans and the quotas configured. The subscription will need to accommodate the amount of compute, storage, and other services needed for your clusters as they scale out.
Application workloads - Refer to the Clusters and workloads concepts in the Kubernetes core concepts for Azure Kubernetes Service document. This article will help you scope the proper VM size based on the compute and memory needs of your application.
Application (application level)
On the application layer, we use Kubernetes Horizontal Pod Autoscaler (HPA). HPA can increase or decrease the number of Replicas (Pod/Container Instances) in our deployment based on different metrics (like CPU utilization).
Another option is to scale container instances vertically. This can be accomplished by changing the amount of CPU and Memory requested and available for a specific deployment. See Managing Resources for Containers on kubernetes.io to learn more.
Networking and connectivity considerations
Networking and connectivity also affect the three layers mentioned previously for Kubernetes on Azure Stack Hub. The following table shows the layers and which services they contain:
| Layer | Affects | What? |
|---|---|---|
| Application | Application | How is the application accessible? Will it be exposed to the Internet? |
| Cluster | Kubernetes cluster | Kubernetes API, AKS Engine VM, Pulling container images (egress), Sending monitoring data and telemetry (egress) |
| Infrastructure | Azure Stack Hub | Accessibility of the Azure Stack Hub management endpoints like the portal and Azure Resource Manager endpoints. |
Application
For the application layer, the most important consideration is whether the application is exposed and accessible from the Internet. From a Kubernetes perspective, Internet accessibility means exposing a deployment or pod using a Kubernetes Service or an Ingress Controller.
Exposing an application using a public IP via a Load Balancer or an Ingress Controller doesn't nessecarily mean that the application is now accessible via the Internet. It's possible for Azure Stack Hub to have a public IP address that is only visible on the local intranet - not all public IPs are truly Internet-facing.
The previous block considers ingress traffic to the application. Another topic that must be considered for a successful Kubernetes deployment is outbound/egress traffic. Here are a few use cases that require egress traffic:
- Pulling Container Images stored on DockerHub or Azure Container Registry
- Retrieving Helm Charts
- Emitting Application Insights data (or other monitoring data)
Some enterprise environments might require the use of transparent or non-transparent proxy servers. These servers require specific configuration on various components of our cluster. The AKS Engine documentation contains various details on how to accommodate network proxies. For more details, see AKS Engine and proxy servers
Lastly, cross-cluster traffic must flow between Azure Stack Hub instances. The sample deployment consists of individual Kubernetes clusters running on individual Azure Stack Hub instances. Traffic between them, such as the replication traffic between two databases, is "external traffic". External traffic must be routed through either a Site-to-Site VPN or Azure Stack Hub Public IP addresses to connect Kubernetes on two Azure Stack Hub instances:
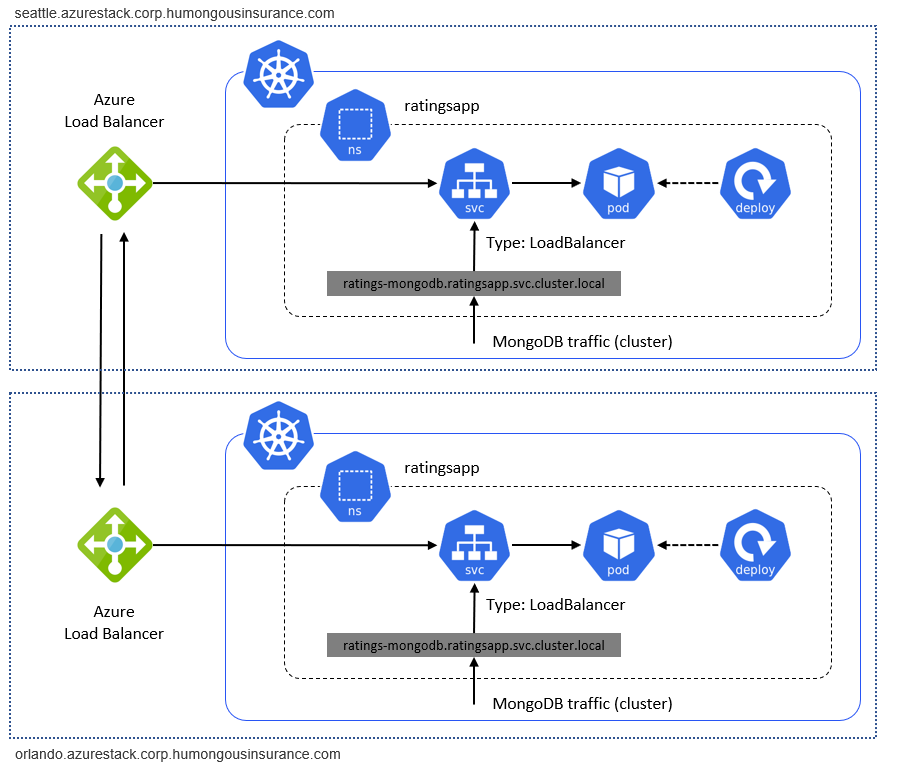
Cluster
The Kubernetes cluster doesn't necessarily need to be accessible via the Internet. The relevant part is the Kubernetes API used to operate a cluster, for example, using kubectl. The Kubernetes API endpoint must be accessible to everyone who operates the cluster or deploys applications and services on top of it. This topic is covered in more detail from a DevOps-perspective in the Deployment (CI/CD) considerations section below.
On the cluster level, there are also a few considerations around egress-traffic:
- Node updates (for Ubuntu)
- Monitoring data (sent to Azure LogAnalytics)
- Other agents requiring outbound traffic (specific to each deployer's environment)
Before you deploy your Kubernetes cluster using AKS Engine, plan for the final networking design. Instead of creating a dedicated Virtual Network, it may be more efficient to deploy a cluster into an existing network. For example, you might leverage an existing Site-to-Site VPN connection already configured in your Azure Stack Hub environment.
Infrastructure
Infrastructure refers to accessing the Azure Stack Hub management endpoints. Endpoints include the tenant and admin portals, and the Azure Resource Manager admin and tenant endpoints. These endpoints are required to operate Azure Stack Hub and its core services.
Data and storage considerations
Two instances of our application will be deployed, on two individual Kubernetes clusters, across two Azure Stack Hub instances. This design will require us to consider how to replicate and synchronize data between them.
With Azure, we have the built-in capability to replicate storage across multiple regions and zones within the cloud. Currently with Azure Stack Hub there are no native ways to replicate storage across two different Azure Stack Hub instances - they form two independent clouds with no overarching way to manage them as a set. Planning for resiliency of applications running across Azure Stack Hub forces you to consider this independence in your application design and deployments.
In most cases, storage replication won't be necessary for a resilient and highly available application deployed on AKS. But you should consider independent storage per Azure Stack Hub instance in your application design. If this design is a concern or road block to deploying the solution on Azure Stack Hub, there are possible solutions from Microsoft Partners that provide storage attachments. Storage attachments provide a storage replication solution across multiple Azure Stack Hubs and Azure. For more information, see the Partner solutions.
In our architecture, these layers were considered:
Configuration
Configuration includes the configuration of Azure Stack Hub, AKS Engine, and the Kubernetes cluster itself. The configuration should be automated as much as possible, and stored as Infrastructure-as-Code in a Git-based version control system like Azure DevOps or GitHub. These settings cannot easily be synchronized across multiple deployments. Therefore we recommend storing and applying configuration from the outside, and using DevOps pipeline.
Application
The application should be stored in a Git-based repository. Whenever there's a new deployment, changes to the application, or disaster recovery, it can be easily deployed using Azure Pipelines.
Data
Data is the most important consideration in most application designs. Application data must stay in sync between the different instances of the application. Data also needs a backup and disaster recovery strategy if there's an outage.
Achieving this design depends heavily on technology choices. Here are some solution examples for implementing a database in a highly available fashion on Azure Stack Hub:
- Deploy a SQL Server 2016 availability group to Azure and Azure Stack Hub
- Deploy a highly available MongoDB solution to Azure and Azure Stack Hub
Considerations when working with data across multiple locations is an even more complex consideration for a highly available and resilient solution. Consider:
- Latency and network connectivity between Azure Stack Hubs.
- Availability of identities for services and permissions. Each Azure Stack Hub instance integrates with an external directory. During deployment, you choose to use either Azure Active Directory (Azure AD) or Active Directory Federation Services (ADFS). As such, there's potential to use a single identity that can interact with multiple independent Azure Stack Hub instances.
Business continuity and disaster recovery
Business continuity and disaster recovery (BCDR) is an important topic in both Azure Stack Hub and Azure. The main difference is that in Azure Stack Hub, the operator must manage the whole BCDR process. In Azure, parts of BCDR are automatically managed by Microsoft.
BCDR affects the same areas mentioned in the previous section Data and storage considerations:
- Infrastructure / Configuration
- Application Availability
- Application Data
And as mentioned in the previous section, these areas are the responsibility of the Azure Stack Hub operator and can vary between organizations. Plan BCDR according to your available tools and processes.
Infrastructure and configuration
This section covers the physical and logical infrastructure and the configuration of Azure Stack Hub. It covers actions in the admin and the tenant spaces.
The Azure Stack Hub operator (or administrator) is responsible for maintenance of the Azure Stack Hub instances. Including components such as the network, storage, identity, and other topics that are outside the scope of this article. To learn more about the specifics of Azure Stack Hub operations, see the following resources:
- Recover data in Azure Stack Hub with the Infrastructure Backup Service
- Enable backup for Azure Stack Hub from the administrator portal
- Recover from catastrophic data loss
- Infrastructure Backup Service best practices
Azure Stack Hub is the platform and fabric on which Kubernetes applications will be deployed. The application owner for the Kubernetes application will be a user of Azure Stack Hub, with access granted to deploy the application infrastructure needed for the solution. Application infrastructure in this case means the Kubernetes cluster, deployed using AKS Engine, and the surrounding services. These components will be deployed into Azure Stack Hub, constrained by an Azure Stack Hub offer. Make sure the offer accepted by the Kubernetes application owner has sufficient capacity (expressed in Azure Stack Hub quotas) to deploy the entire solution. As recommended in the previous section, the application deployment should be automated using Infrastructure-as-Code and deployment pipelines like Azure DevOps Azure Pipelines.
For more information on Azure Stack Hub offers and quotas, see Azure Stack Hub services, plans, offers, and subscriptions overview
It's important to securely save and store the AKS Engine configuration including its outputs. These files contain confidential information used to access the Kubernetes cluster, so it must be protected from being exposed to non-administrators.
Application availability
The application shouldn't rely on backups of a deployed instance. As a standard practice, redeploy the application completely following Infrastructure-as-Code patterns. For example, redeploy using Azure DevOps Azure Pipelines. The BCDR procedure should involve the redeployment of the application to the same or another Kubernetes cluster.
Application data
Application data is the critical part to minimize data loss. In the previous section, techniques to replicate and synchronize data between two (or more) instances of the application were described. Depending on the database infrastructure (MySQL, MongoDB, MSSQL or others) used to store the data, there will be different database availability and backup techniques available to choose from.
The recommended ways to achieve integrity are to use either:
- A native backup solution for the specific database.
- A backup solution that officially supports backup and recovery of the database type used by your application.
Important
Do not store your backup data on the same Azure Stack Hub instance where your application data resides. A complete outage of the Azure Stack Hub instance would also compromise your backups.
Availability considerations
Kubernetes on Azure Stack Hub deployed via AKS Engine isn't a managed service. It's an automated deployment and configuration of a Kubernetes cluster using Azure Infrastructure-as-a-Service (IaaS). As such, it provides the same availability as the underlying infrastructure.
Azure Stack Hub infrastructure is already resilient to failures, and provides capabilities like Availability Sets to distribute components across multiple fault and update domains. But the underlying technology (failover clustering) still incurs some downtime for VMs on an impacted physical server, if there's a hardware failure.
It's a good practice to deploy your production Kubernetes cluster as well as the workload to two (or more) clusters. These clusters should be hosted in different locations or datacenters, and use technologies like Azure Traffic Manager to route users based on cluster response time or based on geography.
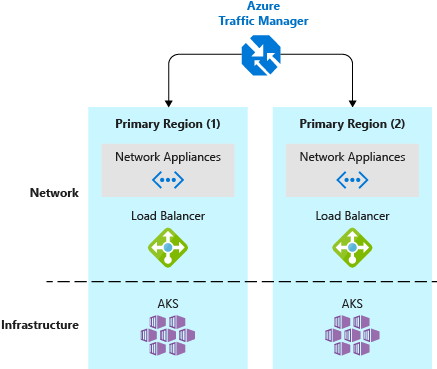
Customers who have a single Kubernetes cluster typically connect to the service IP or DNS name of a given application. In a multi-cluster deployment, customers should connect to a Traffic Manager DNS name that points to the services/ingress on each Kubernetes cluster.
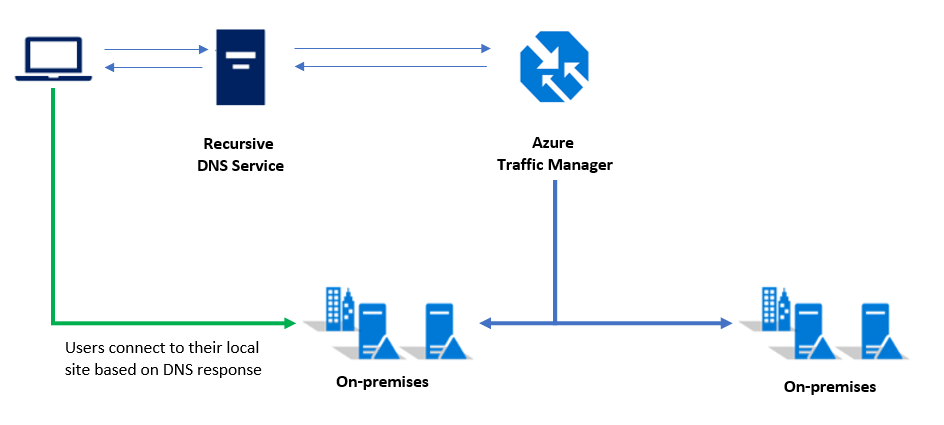
Note
This pattern is also a best practice for (managed) AKS clusters in Azure.
The Kubernetes cluster itself, deployed via AKS Engine, should consist of at least three master nodes and two worker nodes.
Identity and security considerations
Identity and security are important topics. Especially when the solution spans independent Azure Stack Hub instances. Kubernetes and Azure (including Azure Stack Hub) both have distinct mechanisms for role-based access control (RBAC):
- Azure RBAC controls access to resources in Azure (and Azure Stack Hub), including the ability to create new Azure resources. Permissions can be assigned to users, groups, or service principals. (A service principal is a security identity used by applications.)
- Kubernetes RBAC controls permissions to the Kubernetes API. For example, creating pods and listing pods are actions that can be authorized (or denied) to a user through RBAC. To assign Kubernetes permissions to users, you create roles and role bindings.
Azure Stack Hub identity and RBAC
Azure Stack Hub provides two identity provider choices. The provider you use depends on the environment and whether running in a connected or disconnected environment:
- Azure AD - can only be used in a connected environment.
- ADFS to a traditional Active Directory forest - can be used in both a connected or disconnected environment.
The identity provider manages users and groups, including authentication and authorization for accessing resources. Access can be granted to Azure Stack Hub resources like subscriptions, resource groups, and individual resources like VMs or load balancers. To have a consistent access model, you should consider using the same groups (either direct or nested) for all Azure Stack Hubs. Here's a configuration example:
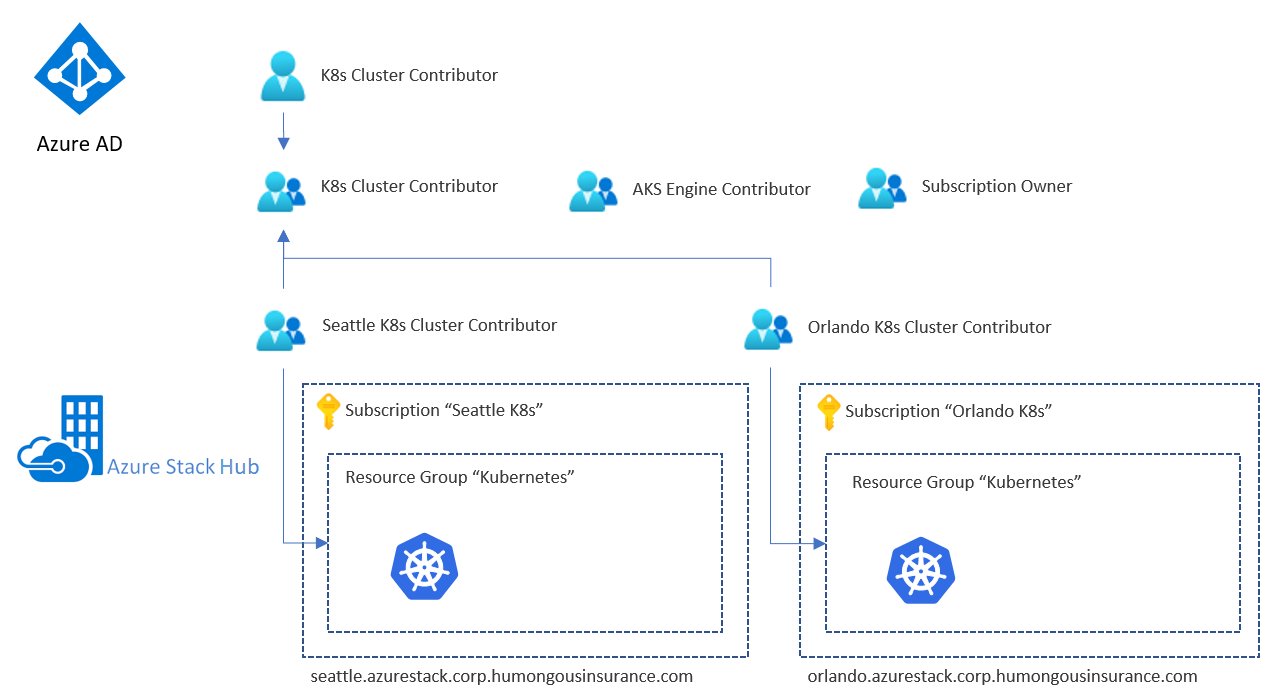
The example contains a dedicated group (using AAD or ADFS) for a specific purpose. For example, to provide Contributor permissions for the Resource Group that contains our Kubernetes cluster infrastructure on a specific Azure Stack Hub instance (here "Seattle K8s Cluster Contributor"). These groups are then nested into an overall group that contains the "subgroups" for each Azure Stack Hub.
Our sample user will now have "Contributor" permissions to both Resources Groups that contain the entire set of Kubernetes infrastructure resources. The user will have access to resources on both Azure Stack Hub instances, because the instances share the same identity provider.
Important
These permissions affect only Azure Stack Hub and some of the resources deployed on top of it. A user who has this level of access can do a lot of harm, but cannot access the Kubernetes IaaS VMs nor the Kubernetes API without additional access to the Kubernetes deployment.
Kubernetes identity and RBAC
A Kubernetes cluster, by default, doesn't use the same Identity Provider as the underlaying Azure Stack Hub. The VMs hosting the Kubernetes cluster, the master, and worker nodes, use the SSH Key that is specified during the deployment of the cluster. This SSH key is required to connect to these nodes using SSH.
The Kubernetes API (for example, accessed by using kubectl) is also protected by service accounts including a default "cluster admin" service account. The credentials for this service account are initially stored in the .kube/config file on your Kubernetes master nodes.
Secrets management and application credentials
To store secrets like connection strings or database credentials there are several choices, including:
- Azure Key Vault
- Kubernetes Secrets
- 3rd-Party solutions like HashiCorp Vault (running on Kubernetes)
Do not store secrets or credentials in plaintext in your configuration files, application code, or within scripts. And do not store them in a version control system. Instead, the deployment automation should retrieve the secrets as needed.
Patch and update
The Patch and Update (PNU) process in Azure Kubernetes Service is partially automated. Kubernetes version upgrades are triggered manually, while security updates are applied automatically. These updates can include OS security fixes or kernel updates. AKS doesn't automatically reboot these Linux nodes to complete the update process.
The PNU process for a Kubernetes cluster deployed using AKS Engine on Azure Stack Hub is unmanaged, and is the responsibility of the cluster operator.
AKS Engine helps with the two most important tasks:
Newer base OS images contain the latest OS security fixes and kernel updates.
The Unattended Upgrade mechanism automatically installs security updates that are released before a new base OS image version is available in the Azure Stack Hub Marketplace. Unattended upgrade is enabled by default and installs security updates automatically, but does not reboot the Kubernetes cluster nodes. Rebooting the nodes can be automated using the open-source KUbernetes REboot Daemon (kured)). Kured watches for Linux nodes that require a reboot, then automatically handle the rescheduling of running pods and node reboot process.
Deployment (CI/CD) considerations
Azure and Azure Stack Hub expose the same Azure Resource Manager REST APIs. These APIs are addressed like any other Azure cloud (Azure, Azure China 21Vianet, Azure Government). There may be differences in API versions between clouds, and Azure Stack Hub provides only a subset of services. The management endpoint URI is also different for each cloud, and each instance of Azure Stack Hub.
Aside from the subtle differences mentioned, Azure Resource Manager REST APIs provide a consistent way to interact with both Azure and Azure Stack Hub. The same set of tools can be used here as would be used with any other Azure cloud. You can use Azure DevOps, tools like Jenkins, or PowerShell, to deploy and orchestrate services to Azure Stack Hub.
Considerations
One of the major differences when it comes to Azure Stack Hub deployments is the question of Internet accessibility. Internet accessibility determines whether to select a Microsoft-hosted or a self-hosted build agent for your CI/CD jobs.
A self-hosted agent can run on top of Azure Stack Hub (as an IaaS VM) or in a network subnet that can access Azure Stack Hub. Go to Azure Pipelines agents to learn more about the differences.
The following image helps you to decide if you need a self-hosted or a Microsoft-hosted build agent:
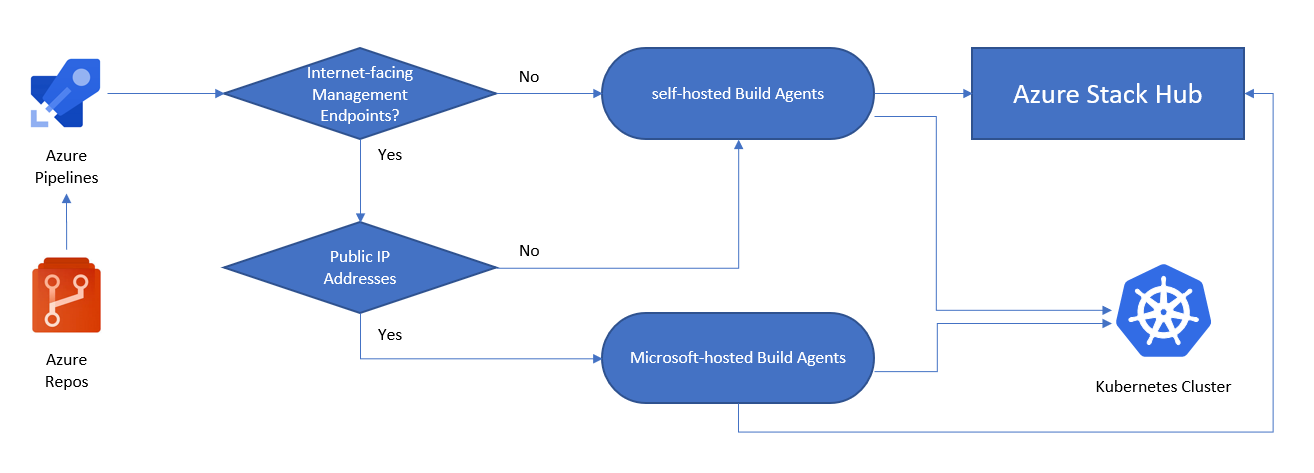
- Are the Azure Stack Hub management endpoints accessible via Internet?
- Yes: We can use Azure Pipelines with Microsoft-hosted agents to connect to Azure Stack Hub.
- No: We need self-hosted agents that can connect to Azure Stack Hub's management endpoints.
- Is our Kubernetes cluster accessible via the Internet?
- Yes: We can use Azure Pipelines with Microsoft-hosted agents to interact directly with Kubernetes API endpoint.
- No: We need self-hosted Agents that can connect to the Kubernetes cluster API endpoint.
In scenarios where the Azure Stack Hub management endpoints and Kubernetes API are accessible via the internet, the deployment can use a Microsoft-hosted agent. This deployment will result in an application architecture as follows:

If the Azure Resource Manager endpoints, Kubernetes API, or both aren't directly accessible via the Internet, we can leverage a self-hosted build agent to run the pipeline steps. This design needs less connectivity, and can be deployed with only on-premises network connectivity to Azure Resource Manager endpoints and the Kubernetes API:

Note
What about disconnected scenarios? In scenarios where either Azure Stack Hub or Kubernetes or both of them do not have internet-facing management endpoints, it is still possible to use Azure DevOps for your deployments. You can either use a self-hosted Agent Pool (which is a DevOps Agent running on-premises or on Azure Stack Hub itself) or a completly self-hosted Azure DevOps Server on-premises. The self-hosted agent needs only outbound HTTPS (TCP/443) Internet connectivity.
The pattern can use a Kubernetes cluster (deployed and orchestrated with AKS engine) on each Azure Stack Hub instance. It includes an application consisting of a frontend, a mid-tier, backend services (for example MongoDB), and an nginx-based Ingress Controller. Instead of using a database hosted on the K8s cluster, you can leverage "external data stores". Database options include MySQL, SQL Server, or any kind of database hosted outside of Azure Stack Hub or in IaaS. Configurations like this aren't in scope here.
Partner solutions
There are Microsoft Partner solutions that can extend the capabilities of Azure Stack Hub. These solutions have been found useful in deployments of applications running on Kubernetes clusters.
Storage and data solutions
As described in Data and storage considerations, Azure Stack Hub currently doesn't have a native solution to replicate storage across multiple instances. Unlike Azure, the capability of replicating storage across multiple regions does not exist. In Azure Stack Hub, each instance is its own distinct cloud. However, solutions are available from Microsoft Partners that enable storage replication across Azure Stack Hubs and Azure.
SCALITY
Scality delivers web-scale storage that has powered digital businesses since 2009. The Scality RING, our software-defined storage, turns commodity x86 servers into an unlimited storage pool for any type of data –file and object– at petabyte scale.
CLOUDIAN
Cloudian simplifies enterprise storage with limitless scalable storage that consolidates massive data sets to a single, easily managed environment.
Next steps
To learn more about concepts introduced in this article:
- Cross-cloud scaling and Geo-distributed app patterns in Azure Stack Hub.
- Microservices architecture on Azure Kubernetes Service (AKS).
When you're ready to test the solution example, continue with the High availability Kubernetes cluster deployment guide. The deployment guide provides step-by-step instructions for deploying and testing its components.