CycleCloud: Core Concepts
At its most basic, a High Performance Computing (HPC) system is a pool of computational resources backed by performant file systems and interconnected by low-latency networks. These computational resources are usually managed by HPC Schedulers, software applications that schedule jobs.
Building individual HPC systems on Azure from basic infrastructure units such as Virtual Machines, Disks, and Network Interfaces can be cumbersome, especially if these resources are ephemeral — existing only for the time required to solve the HPC task at hand. Additionally, operators want to create multiple, separate HPC environments that can be tailored to various business units, research teams, or individuals. Managing these multiple HPC systems can be operationally complexity.
What is CycleCloud?
Azure CycleCloud is a tool that helps construct HPC systems on Azure. It orchestrates these systems so that they size elastically according to the HPC tasks at hand, without the hassle of managing basic Azure building blocks. CycleCloud is designed by a team of experienced HPC professionals for HPC administrators and users, particularly users who are looking build HPC systems in Azure that resemble internal HPC infrastructure that they are familiar with.
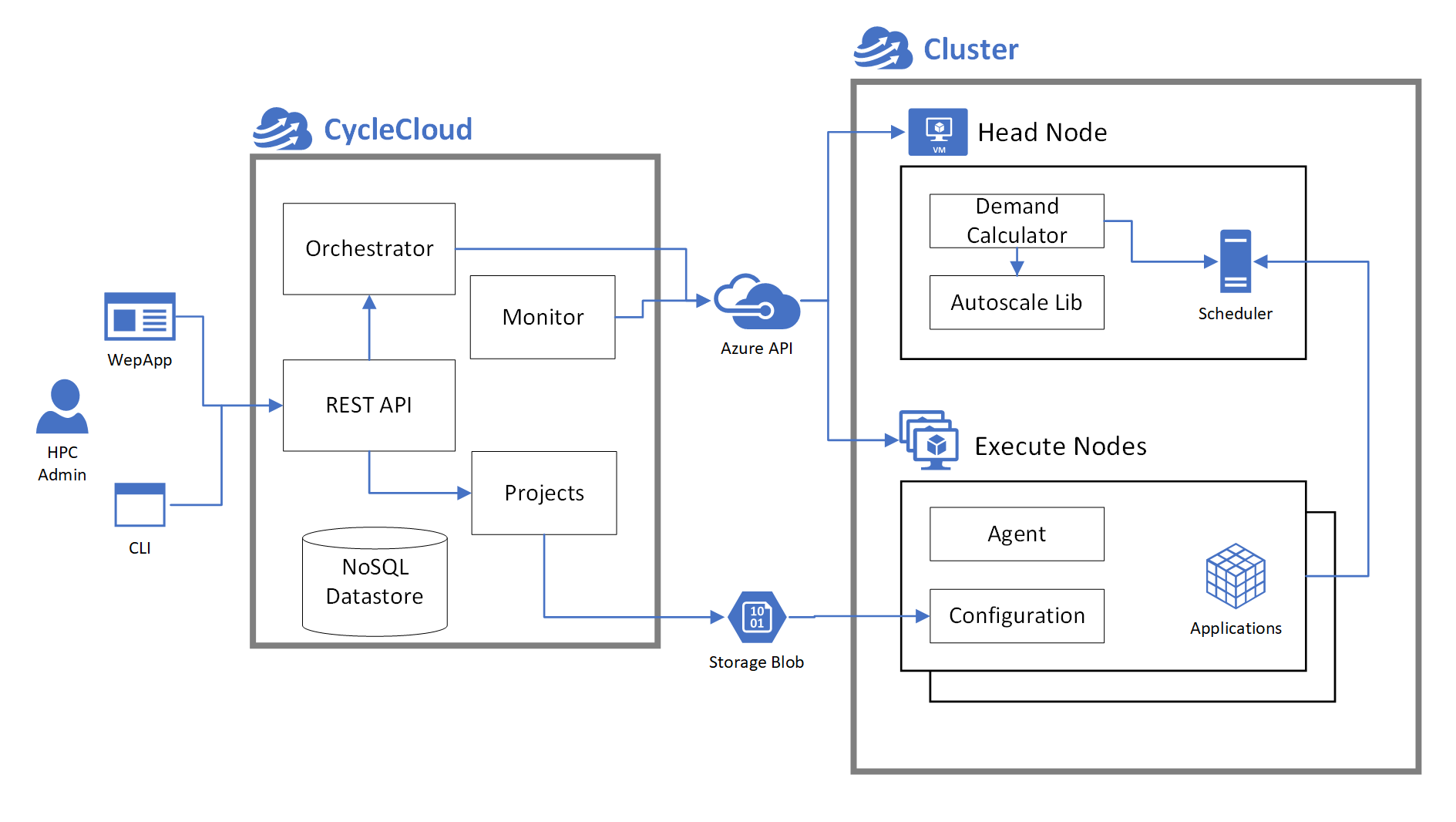
Operationally, CycleCloud is an application server that is installed in a Linux VM on Azure, or on an on-premise server that has access to Azure APIs and resources. CycleCloud acquires and provisions Azure VMs to construct CycleCloud clusters that can integrate schedulers and user applications. CycleCloud also provides autoscaling integrations for a number of HPC schedulers and a CycleCloud agent that runs on Azure VMs.
Application Server
This application server provides:
- A REST API for creating and managing HPC systems on Azure.
- A graphical user interface that allows a user to manage and monitor HPC systems.
- A CLI that facilitates integration of CycleCloud into existing workflows.
- An internal NoSQL datastore that caches cluster and node state.
- An allocation and orchestration system that acquires and manages Azure VMs
- A node monitoring system for existing VMs that alerts of status changes.
Integrations
CycleCloud also provides a number of integrations into common schedulers and the Azure VMs. Thee provide:
- A node preparation and configuration system for converting a provisioned VM into an HPC node.
- Autoscaling for HPC schedulers that translate HPC scheduler task requirements into Azure resources.
What can CycleCloud do
CycleCloud is targeted at HPC operators (administrators and users) who are deploying HPC systems on Azure and who want to replicate infrastructure they have been running internally, from the HPC scheduler to file-system mount points for application installs and data access. These users are particularly looking at supporting applications, workflow engines, and computational pipelines without having to retool their internal processes.
CycleCloud provides a rich and declarative templating syntax that enables users to describe their HPC system, from the cluster topology (the number and types of cluster nodes), down to the mount points and applications that will be deployed on each node. CycleCloud is designed to work with HPC schedulers such as PBSPro, Slurm, IBM LSF, Grid Engine, and HT Condor, allowing users to create different queues in each scheduler and map them to compute nodes of different VM sizes on Azure. Additionally, autoscale plugins are integrated with the scheduler head nodes that listen to job queues in each system, and size the compute cluster accordingly by interacting with the autoscale REST API running on the application server.
Besides provisioning and creating HPC nodes, CycleCloud also provides a framework for preparing and configuring a virtual machine, in essence providing a system for converting a bare VM into a functional component of an HPC system. Through this framework, users can do last-mile configuration on a VM.
Additionally, CycleCloud provides the following features:
User Access
CycleCloud comes with built-in support for creating local user accounts on each node of an HPC system. With this system, user access can be controlled through a single management plane without deploying a directory service.
Monitoring
Node-level metrics are collected and displayed in the CycleCloud UI. These are useful for monitoring the load on the system, and can be hooked into reporting and alerting services.
Logging
CycleCloud provides a system for logging activities and events at the node and application server level.
Portability
The system does not mandate that a specific VM image or operating system be used. CycleCloud supports the major Windows and Linux operating systems on HPC nodes. Additionally, users can build their own VM image and use that in their HPC system.
Infrastructure as code
Since everything created in CycleCloud is defined in templates and configuration scripts, HPC systems deployed through CycleCloud are repeatable and portable. This provides operators consistency in deploying HPC systems in different environments: Sandbox, Development, Test, and Production. Operators can also deploy identical HPC systems for different business groups or teams to separate accounting concerns.
Loosely coupled or tightly coupled workloads
HPC clusters created by CycleCloud are designed not only to support loosely coupled or embarrassingly parallel jobs where scale (the size of the cluster) is the primary concern. CycleCloud clusters are also designed with Azure's Infiniband backbone in mind, supporting tightly coupled or MPI-based workloads where node proximity and network latency is critical. These scale-out and tightly coupled concepts are ingrained in the scheduler integrations that CycleCloud supports.