Limits & FAQ for Git integration with Databricks Git folders
Databricks Git folders and Git integration have limits specified in the following sections. For general information, see Databricks limits.
Jump to:
File and repo limits
Azure Databricks doesn’t enforce a limit on the size of a repo. However:
- Working branches are limited to 1 gigabyte (GB).
- Files larger than 10 MB can’t be viewed in the Azure Databricks UI.
- Individual workspace files are subject to a separate size limit. For more details, read Limitations.
Databricks recommends that in a repo:
- The total number of all workspace assets and files not exceed 20,000.
For any Git operation, memory usage is limited to 2 GB, and disk writes are limited to 4 GB. Since the limit is per-operation, you get a failure if you attempt to clone a Git repo that is 5 GB in current size. However, if you clone a Git repo that is 3 GB in size in one operation and then add 2 GB to it later, the next pull operation will succeed.
You might receive an error message if your repo exceeds these limits. You might also receive a timeout error when you clone the repo, but the operation might complete in the background.
To work with repo larger than the size limits, try sparse checkout.
If you must write temporary files that you do not want to keep after the cluster is shut down, writing the temporary files to $TEMPDIR avoids exceeding branch size limits and yields better performance than writing to the current working directory (CWD) if the CWD is in the workspace filesystem. For more information, see Where should I write temporary files on Azure Databricks?.
Maximum number of Git folders per workspace
You can have a maximum of 2,000 Git folders per workspace. If you require more, contact Databricks support.
Monorepo support
Databricks recommends that you do not create Git folders backed by monorepos, where a monorepo is a large, single-organization Git repository with many thousands of files across many projects.
Asset types supported in Git folders
Only certain Azure Databricks asset types are supported by Git folders. A supported asset type can be serialized, version-controlled, and pushed to the backing Git repo.
Currently, the supported asset types are:
| Asset Type | Details |
|---|---|
| File | Files are serialized data, and can include anything from libraries to binaries to code to images. For more information, read What are workspace files? |
| Notebook | Notebooks are specifically the notebook file formats supported by Databricks. Notebooks are considered a separate Azure Databricks asset type from files because they are not serialized. Git folders determine a notebook by the file extension (such as .ipynb) or by file extensions combined with a special marker in file content (for example, a # Databricks notebook source comment at the beginning of .py source files). |
| Folder | A folder is a Azure Databricks-specific structure that represents serialized information about a logical grouping of files in Git. As expected, the user experiences this as a “folder” when viewing a Azure Databricks Git folder or accessing it with the Azure Databricks CLI. |
Azure Databricks asset types that are currently not supported in Git folders include the following:
- DBSQL queries
- Alerts
- Dashboards (including legacy dashboards)
- Experiments
- Genie spaces
When working with your assets in Git, observe the following limitations in file naming:
- A folder cannot contain a notebook with the same name as another notebook, file, or folder in the same Git repository, even if the file extension differs. (For source-format notebooks, the extension is
.pyfor python,.scalafor Scala,.sqlfor SQL, and.rfor R. For IPYNB-format notebooks, the extension is.ipynb.) For example, you can’t use a source-format notebook namedtest1.pyand an IPYNB notebook namedtest1in the same Git folder because the source-format Python notebook file (test1.py) will be serialized astest1and a conflict will occur. - The character
/is not supported in file names. For example, you can’t have a file namedi/o.pyin your Git folder.
If you attempt to perform Git operations on files that have names that have these patterns, you will get an “Error fetching Git status” message. If you receive this error unexpectedly, review the filenames of the assets in your Git repository. If you find files with names that have these conflicting patterns, rename them and try the operation again.
Note
You can move existing unsupported assets into a Git folder, but cannot commit changes to these assets back to the repo. You cannot create new unsupported assets in a Git folder.
Notebook formats
Databricks considers two kinds of high-level, Databricks-specific notebook formats: “source” and “ipynb”. When a user commits a notebook in the “source” format, the Azure Databricks platform commits a flat file with a language suffix, such as .py, .sql, .scala, or .r. A “source”-format notebook contains only source code and does not contain outputs such as table displays and visualizations that are the results of running the notebook.
The “ipynb” format, however, does have outputs associated with it, and those artifacts are automatically pushed to the Git repo backing the Git folder when pushing the .ipynb notebook that generated them. If you want to commit outputs along with the code, use the “ipynb” notebook format and set up the configuration to allow a user to commit any generated outputs. As a result, “ipynb” also supports a better viewing experience in Databricks for notebooks pushed to remote Git repos through Git folders.
| Notebook source format | Details |
|---|---|
| source | Can be any code file with a standard file suffix that signals the code language, such as .py, .scala, .r and .sql. “source” notebooks are treated as text files and will not include any associated outputs when committed back to a Git repo. |
| ipynb | “ipynb” files end with .ipynb and can, if configured, push outputs (such as visualizations) from the Databricks Git folder to the backing Git repo. An .ipnynb notebook can contain code in any language supported by Databricks notebooks (despite the py part of .ipynb). |
If you want outputs pushed back to your repo after running a notebook, use a .ipynb (Jupyter) notebook. If you just want to run the notebook and manage it in Git, use a “source” format like .py.
For more details on supported notebook formats, read Export and import Databricks notebooks.
Note
What are “outputs”?
Outputs are the results of running a notebook on the Databricks platform, including table displays and visualizations.
How do I tell what format a notebook is using, other than the file extension?
At the top of a notebook managed by Databricks, there is usually a single-line comment that indicates the format. For example, for a .py “source” notebook, you will see a line that looks like this:
# Databricks notebook source
For .ipynb files, the file suffix is used to indicate that it is the “ipynb” notebook format.
IPYNB notebooks in Databricks Git folders
Support for Jupyter notebooks (.ipynb files) is available in Git folders. You can clone repositories with .ipynb notebooks, work with them in Azure Databricks, and then commit and push them as .ipynb notebooks. Metadata, such as the notebook dashboard, is preserved. Admins can control whether outputs can be committed or not.
Allow committing .ipynb notebook output
By default, the admin setting for Git folders doesn’t allow .ipynb notebook output to be committed. Workspace admins can change this setting:
Go to Admin settings > Workspace settings.
Under Git folders > Allow Git folders to Export IPYNB outputs, select Allow: IPYNB outputs can be toggled on.

Important
When outputs are included, the visualization and dashboard configs are preserved with the .ipynb file format.
Control IPYNB notebook output artifact commits
When you commit an .ipynb file, Databricks creates a config file that lets you control how you commit outputs: .databricks/commit_outputs.
If you have a
.ipynbnotebook file but no config file in your repo, open the Git Status modal.In the notification dialog, click Create commit_outputs file.
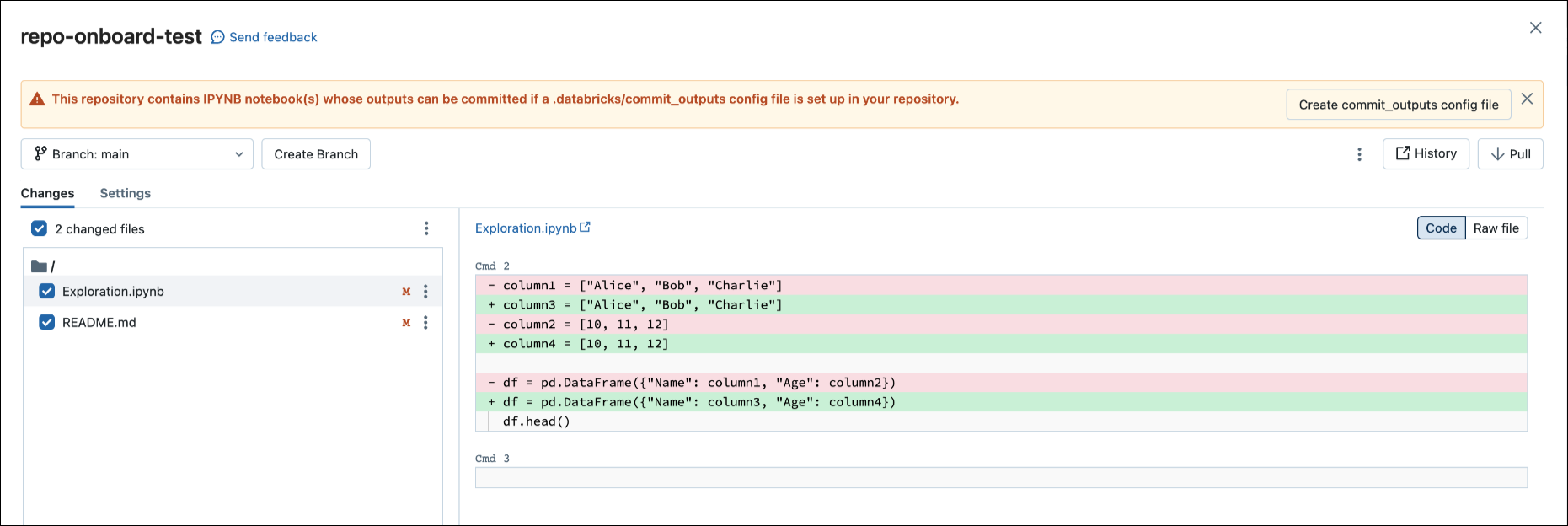
You can also generate config files from the File menu. The File menu has a control that lets you automatically update the config file to specify the inclusion or exclusion of outputs for a specific notebook.
In the File menu, select Commit notebooks outputs.
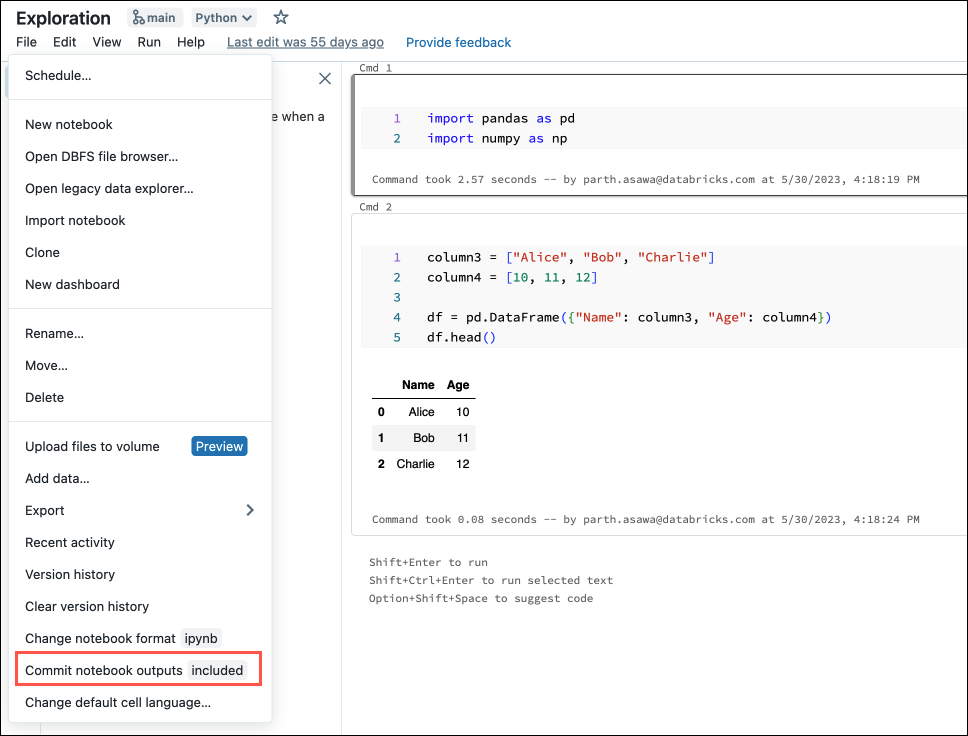
In the dialog box, confirm your choice to commit notebook outputs.
Convert a source notebook to IPYNB
You can convert an existing source notebook in a Git folder to an IPYNB notebook through the Azure Databricks UI.
Open a source notebook in your workspace.
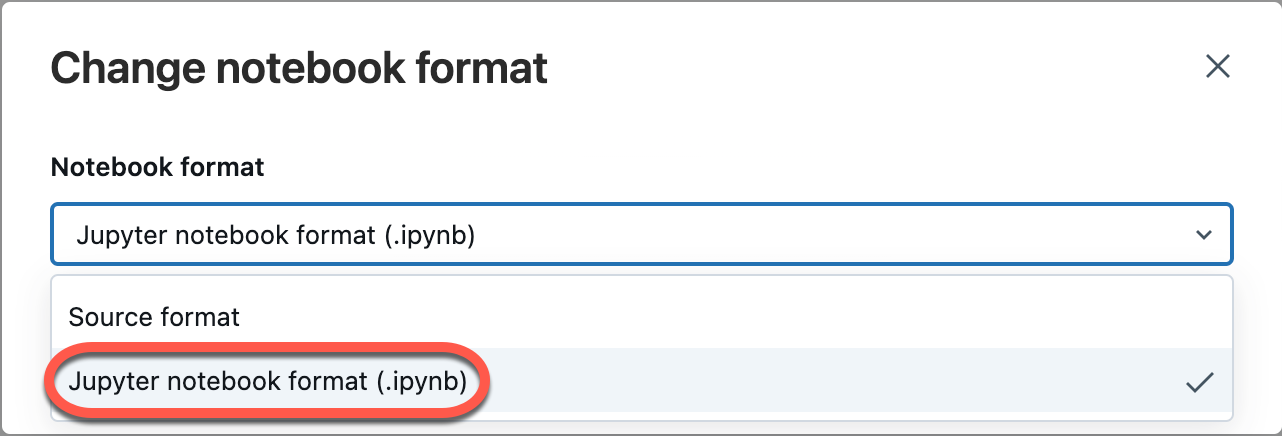
Select File from the workspace menu, and then select Change notebook format [source]. If the notebook is already in IPYNB format, [source] will be [ipynb] in the menu element.
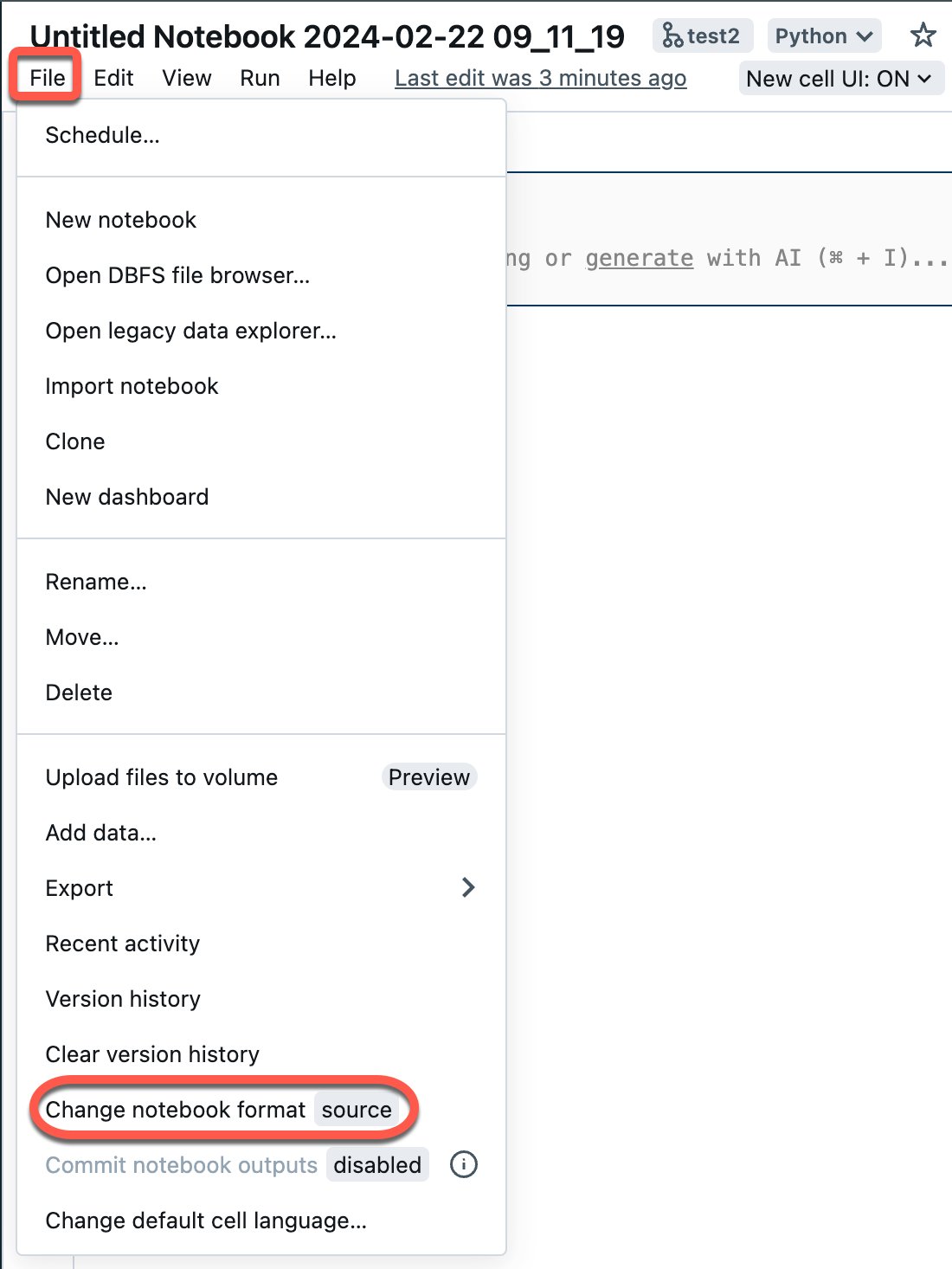
In the modal dialog, select “Jupyter notebook format (.ipynb)” and click Change.
You can also:
- Create new
.ipynbnotebooks. - View diffs as Code diff (code changes in cells) or Raw diff (code changes are presented as JSON syntax, which includes notebook outputs as metadata).
For more information on the kinds of notebooks supported in Azure Databricks, read Export and import Databricks notebooks.
Frequently Asked Questions: Git folder configuration
Where is Azure Databricks repo content stored?
The contents of a repo are temporarily cloned onto disk in the control plane. Azure Databricks notebook files are stored in the control plane database just like notebooks in the main workspace. Non-notebook files are stored on disk for up to 30 days.
Do Git folders support on-premises or self-hosted Git servers?
Databricks Git folders supports GitHub Enterprise, Bitbucket Server, Azure DevOps Server, and GitLab Self-managed integration, if the server is internet accessible. For details on integrating Git folders with an on-prem Git server, read Git Proxy Server for Git folders.
To integrate with a Bitbucket Server, GitHub Enterprise Server, or a GitLab self-managed subscription instance that is not internet-accessible, get in touch with your Azure Databricks account team.
What Databricks asset types are supported by Git folders?
For details on supported asset types, read Asset types supported in Git folders.
Do Git folders support .gitignore files?
Yes. If you add a file to your repo and do not want it to be tracked by Git, create a .gitignore file or use one cloned from your remote repository and add the filename, including the extension.
.gitignore works only for files that are not already tracked by Git. If you add a file that is already tracked by Git to a .gitignore file, the file is still tracked by Git.
Can I create top-level folders that are not user folders?
Yes, admins can create top-level folders to a single depth. Git folders do not support additional folder levels.
Do Git folders support Git submodules?
No. You can clone a repo that contains Git submodules, but the submodule is not cloned.
Does Azure Data Factory (ADF) support Git folders?
Yes.
Source management
Why do notebook dashboards disappear when I pull or checkout a different branch?
This is currently a limitation because Azure Databricks notebook source files don’t store notebook dashboard information.
If you want to preserve dashboards in the Git repository, change the notebook format to .ipynb (the Jupyter notebook format). By default, .ipynb supports dashboard and visualization definitions. If you want to preserve graph data (data points), you must commit the notebook with outputs.
To learn about committing .ipynb notebook outputs, see Allow committing .ipynb notebook output.
Do Git folders support branch merging?
Yes. You can also create a pull request and merge through your Git provider.
Can I delete a branch from an Azure Databricks repo?
No. To delete a branch, you must work in your Git provider.
If a library is installed on a cluster, and a library with the same name is included in a folder within a repo, which library is imported?
The library in the repo is imported. For more information about library precedence in Python, see Python library precedence.
Can I pull the latest version of a repository from Git before running a job without relying on an external orchestration tool?
No. Typically you can integrate this as a pre-commit on the Git server so that every push to a branch (main/prod) updates the Production repo.
Can I export a repo?
You can export notebooks, folders, or an entire repo. You cannot export non-notebook files. If you export an entire repo, non-notebook files are not included. To export, use the workspace export command in the Databricks CLI or use the Workspace API.
Security, authentication, and tokens
Issue with a conditional access policy (CAP) for Microsoft Entra ID
When you try to clone a repo, you might get a “denied access” error message when:
- Azure Databricks is configured to use Azure DevOps with Microsoft Entra ID authentication.
- You have enabled a conditional access policy in Azure DevOps and an Microsoft Entra ID conditional access policy.
To resolve this, add an exclusion to the conditional access policy (CAP) for the IP address or users of Azure Databricks.
For more information, see Conditional access policies.
Allow list with Azure AD tokens
If you use Azure Active Directory (AAD) for authenticating with Azure DevOps, the default allow list restricts Git URLs to:
dev.azure.comvisualstudio.com
For more information, see Allow lists restrict remote repo usage.
Are the contents of Azure Databricks Git folders encrypted?
The contents of Azure Databricks Git folders are encrypted by Azure Databricks using a default key. Encryption using customer-managed keys is not supported except when encrypting your Git credentials.
How and where are the GitHub tokens stored in Azure Databricks? Who would have access from Azure Databricks?
- The authentication tokens are stored in the Azure Databricks control plane, and an Azure Databricks employee can only gain access through a temporary credential that is audited.
- Azure Databricks logs the creation and deletion of these tokens, but not their usage. Azure Databricks has logging that tracks Git operations that can be used to audit the usage of the tokens by the Azure Databricks application.
- GitHub enterprise audits token usage. Other Git services might also have Git server auditing.
Do Git folders support GPG signing of commits?
No.
Do Git folders support SSH?
No, only HTTPS.
Error connecting Azure Databricks to an Azure DevOps repo in a different tenancy
When trying to connect to DevOps in a separate tenancy, you might receive the message Unable to parse credentials from Azure Active Directory account. If the Azure DevOps project is in a different Microsoft Entra ID tenancy from Azure Databricks, you need to use an access token from Azure DevOps. See Connect to Azure DevOps using a DevOps token.
CI/CD and MLOps
Incoming changes clear the notebook state
Git operations that alter the notebook source code result in the loss of the notebook state, including cell outputs, comments, version history, and widgets. For example, git pull can change the source code of a notebook. In this case, Databricks Git folders must overwrite the existing notebook to import the changes. git commit and push or creating a new branch do not affect the notebook source code, so the notebook state is preserved in these operations.
Important
MLflow experiments don’t work in Git folders with DBR 14.x or lower versions.
Can I create an MLflow experiment in a repo?
There are two types of MLflow experiments: workspace and notebook. For details on the two types of MLflow experiments, see Organize training runs with MLflow experiments.
In Git folders, you can call mlflow.set_experiment("/path/to/experiment") for an MLflow experiment of either type and log runs to it, but that experiment and the associated runs will not be checked into source control.
Workspace MLflow experiments
You cannot create workspace MLflow experiments in a Databricks Git folder (Git folder). If multiple users use separate Git folders to collaborate on the same ML code, log MLflow runs to an MLflow experiment created in a regular workspace folder.
Notebook MLflow experiments
You can create notebook experiments in a Databricks Git folder. If you check your notebook into source control as an .ipynb file, you can log MLflow runs to an automatically created and associated MLflow experiment. For more details, read about creating notebook experiments.
Prevent data loss in MLflow experiments
Notebook MLflow experiments created using Databricks Jobs with source code in a remote repository are stored in a temporary storage location. These experiments persist initially after workflow execution but are at risk of deletion later during scheduled removal of files in temporary storage. Databricks recommends using workspace MLflow experiments with Jobs and remote Git sources.
Warning
Any time you switch to a branch that does not contain the notebook, you risk losing the associated MLflow experiment data. This loss becomes permnanent if the prior branch is not accessed within 30 days.
To recover missing experiment data before the 30 day expiry, rename the notebook back to the original name, open the notebook, click the “experiment” icon on the right side pane (this also effectively calls the mlflow.get_experiment_by_name() API), and you will be able to see the recovered experiment and runs. After 30 days, any orphaned MLflow experiments will be purged to meet GDPR compliance policies.
To prevent this situation, Databricks recommends you either avoid renaming notebooks in repos altogether, or if you do rename a notebook, click the “experiment” icon on the right side pane immediately after renaming a notebook.
What happens if a notebook job is running in a workspace while a Git operation is in progress?
At any point while a Git operation is in progress, some notebooks in the repo might have been updated while others have not. This can cause unpredictable behavior.
For example, suppose notebook A calls notebook Z using a %run command. If a job running
during a Git operation starts the most recent version of notebook A, but notebook Z has not
yet been updated, the %run command in notebook A might start the older version of notebook Z.
During the Git operation, the notebook states are not predictable and the job might fail or run
notebook A and notebook Z from different commits.
To avoid this situation, use Git-based jobs (where the source is a Git provider and not a workspace path) instead. For more details, read Use Git with jobs.
Resources
For details on Databricks workspace files, see What are workspace files?.