Import data wizards in the Azure portal
Azure AI Search has two import wizards that automate indexing and object creation so that you can begin querying immediately. If you're new to Azure AI Search, these wizards are one of the most powerful features at your disposal. With minimal effort, you can create an indexing or enrichment pipeline that exercises most of the functionality of Azure AI Search.
Import data wizard supports nonvector workflows. You can extract text and numbers from raw documents. You can also configure applied AI and built-in skills that infer structure and generate text searchable content from image files and unstructured data.
Import and vectorize data wizard adds chunking and vectorization. You must specify an existing deployment of an embedding model, but the wizard makes the connection, formulates the request, and handles the response. It generates vector content from text or image content.
If you're using the wizard for proof-of-concept testing, this article explains the internal workings of the wizards so that you can use them more effectively.
This article isn't a step by step. For help with using the wizard with sample data see:
- Quickstart: Create a search index
- Quickstart: Create a text translation and entity skillset
- Quickstart: Create a vector index
- Quickstart: image search (vectors)
Supported data sources and scenarios
The wizards support most of the data sources supported by indexers.
| Data | Import data wizard | Import and vectorize data wizard |
|---|---|---|
| ADLS Gen2 | ✅ | ✅ |
| Azure Blob Storage | ✅ | ✅ |
| Azure File Storage | ❌ | ❌ |
| Azure Table Storage | ✅ | ✅ |
| Azure SQL database and managed instance | ✅ | ✅ |
| Cosmos DB for NoSQL | ✅ | ✅ |
| Cosmos DB for MongoDB | ✅ | ✅ |
| Cosmos DB for Apache Gremlin | ✅ | ✅ |
| MySQL | ❌ | ❌ |
| OneLake | ✅ | ✅ |
| SharePoint Online | ❌ | ❌ |
| SQL Server on virtual machines | ✅ | ✅ |
Sample data
Microsoft hosts sample data so that you can omit a data source configuration step on a wizard workflow.
| Sample data | Import data wizard | Import and vectorize data wizard |
|---|---|---|
| hotels | ✅ | ❌ |
| real estate | ✅ | ❌ |
Skills
This section lists the skills that might appear in a skillset generated by a wizard. Wizards generate a skillset and output field mappings based on options you select. After the skillset is created, you can modify its JSON definition to add more skills.
Here are some points to keep in mind about the skills in the following list:
- OCR and image analysis options are available for blobs in Azure Storage and files in OneLake, assuming the default parsing mode. Images are either an image content type (such as PNG or JPG) or an embedded image in an application file (such as PDF).
- Shaper is added if you configure a knowledge store.
- Text Split and Text Merge are added for data chunking if you choose an embedding model. They are added for other non-embedding skills if the source field granularity is set to pages or sentences.
| Skills | Import data wizard | Import and vectorize data wizard |
|---|---|---|
| AI Vision multimodal | ❌ | ✅ |
| Azure OpenAI embedding | ❌ | ✅ |
| Azure Machine Learning (Azure AI Foundry model catalog) | ❌ | ✅ |
| Document layout | ❌ | ✅ |
| Entity recognition | ✅ | ❌ |
| Image analysis (applies to blobs, default parsing, whole file indexing | ✅ | ❌ |
| Keyword extraction | ✅ | ❌ |
| Language detection | ✅ | ❌ |
| Text translation | ✅ | ❌ |
| OCR (applies to blobs, default parsing, whole file indexing) | ✅ | ✅ |
| PII detection | ✅ | ❌ |
| Sentiment analysis | ✅ | ❌ |
| Shaper (applies to knowledge store) | ✅ | ❌ |
| Text Split | ✅ | ✅ |
| Text Merge | ✅ | ✅ |
Knowledge store
You can generate a knowledge store for secondary storage of enriched (skills-generated) content. You might want a knowledge store for information retrieval workflows that don't require a search engine.
| Knowledge store | Import data wizard | Import and vectorize data wizard |
|---|---|---|
| storage | ✅ | ❌ |
What the wizards create
The import wizards create the objects described in the following table. After the objects are created, you can review their JSON definitions in the Azure portal or call them from code.
To view these objects after the wizard runs:
Select Search management on the menu to find pages for indexes, indexers, data sources, and skillsets.
| Object | Description |
|---|---|
| Indexer | A configuration object specifying a data source, target index, an optional skillset, optional schedule, and optional configuration settings for error handing and base-64 encoding. |
| Data Source | Persists connection information to a supported data source on Azure. A data source object is used exclusively with indexers. |
| Index | Physical data structure used for full text search and other queries. |
| Skillset | Optional. A complete set of instructions for manipulating, transforming, and shaping content, including analyzing and extracting information from image files. Skillsets are also used for integrated vectorization. Unless the volume of work fall under the limit of 20 transactions per indexer per day, the skillset must include a reference to an Azure AI multiservice resource that provides enrichment. For integrated vectorization, you can use either Azure AI Vision or an embedding model in the Azure AI Foundry model catalog. |
| Knowledge store | Optional. Available only in the Import data wizard. Stores enriched skillset output from in tables and blobs in Azure Storage for independent analysis or downstream processing in nonsearch scenarios. |
Benefits
Before writing any code, you can use the wizards for prototyping and proof-of-concept testing. The wizards connect to external data sources, sample the data to create an initial index, and then import and optionally vectorize the data as JSON documents into an index on Azure AI Search.
If you're evaluating skillsets, the wizard handles output field mappings and adds helper functions to create usable objects. Text split is added if you specify a parsing mode. Text merge is added if you chose image analysis so that the wizard can reunite text descriptions with image content. Shaper skills are added to support valid projections if you chose the knowledge store option. All of the above tasks come with a learning curve. If you're new to enrichment, the ability to have these steps handled for you allows you to measure the value of a skill without having to invest much time and effort.
Sampling is the process by which an index schema is inferred, and it has some limitations. When the data source is created, the wizard picks a random sample of documents to decide what columns are part of the data source. Not all files are read, as this could potentially take hours for very large data sources. Given a selection of documents, source metadata, such as field name or type, is used to create a fields collection in an index schema. Depending on the complexity of source data, you might need to edit the initial schema for accuracy, or extend it for completeness. You can make your changes inline on the index definition page.
Overall, the advantages of using the wizard are clear: as long as requirements are met, you can create a queryable index within minutes. Some of the complexities of indexing, such as serializing data as JSON documents, are handled by the wizards.
Limitations
The import wizards aren't without limitations. Constraints are summarized as follows:
The wizards don't support iteration or reuse. Each pass through the wizard creates a new index, skillset, and indexer configuration. Only data sources can be persisted and reused within the wizard. To edit or refine other objects, either delete the objects and start over, or use the REST APIs or .NET SDK to modify the structures.
Source content must reside in a supported data source.
Sampling is over a subset of source data. For large data sources, it's possible for the wizard to miss fields. You might need to extend the schema, or correct the inferred data types, if sampling is insufficient.
AI enrichment, as exposed in the Azure portal, is limited to a subset of built-in skills.
A knowledge store, which can be created by the Import data wizard, is limited to a few default projections and uses a default naming convention. If you want to customize names or projections, you'll need to create the knowledge store through REST API or the SDKs.
Secure connections
The import wizards make outbound connections using the Azure portal controller and public endpoints. You can't use the wizards if Azure resources are accessed over a private connection or through a shared private link.
You can use the wizards over restricted public connections, but not all functionality is available.
On a search service, importing the built-in sample data requires a public endpoint and no firewall rules.
Sample data is hosted by Microsoft on specific Azure resources. the Azure portal controller connects to those resources over a public endpoint. If you put your search service behind a firewall, you get this error when attempting to retrieve the builtin sample data:
Import configuration failed, error creating Data Source, followed by"An error has occured.".On supported Azure data sources protected by firewalls, you can retrieve data if you have the right firewall rules in place.
The Azure resource must admit network requests from the IP address of the device used on the connection. You should also list Azure AI Search as a trusted service on the resource's network configuration. For example, in Azure Storage, you can list
Microsoft.Search/searchServicesas a trusted service.On connections to an Azure AI multi-service account that you provide, or on connections to embedding models deployed in Azure AI Foundry portal or Azure OpenAI, public internet access must be enabled unless your search service meets the creation date, tier, and region requirements for private connections. For more information about these requirements, see Make outbound connections through a shared private link.
Connections to Azure AI multi-service are for billing purposes. Billing occurs when API calls exceed the free transaction count (20 per indexer run) for built-in skills called by the Import data wizard or integrated vectorization in the Import and vectorize data wizard.
If Azure AI Search can't connect:
In the Import and vectorize data wizard, the error is
"Access denied due to Virtual Network/Firewall rules."In the Import data wizard, there's no error, but the skillset won't be created.
If firewall settings prevent your wizard workflows from succeeding, consider scripted or programmatic approaches instead.
Workflow
The wizard is organized into four main steps:
Connect to a supported Azure data source.
Create an index schema, inferred by sampling source data.
Optionally, it adds skills to extract or generate content and structure. Inputs for creating a knowledge store are collected in this step.
Run the wizard to create objects, optionally vectorize data, load data into an index, set a schedule and other configuration options.
The workflow is a pipeline, so it's one way. You can't use the wizard to edit any of the objects that were created, but you can use other portal tools, such as the index or indexer designer or the JSON editors, for allowed updates.
Starting the wizards
Here's how you start the wizards.
In the Azure portal, open the search service page from the dashboard or find your service in the service list.
In the service Overview page at the top, select Import data or Import and vectorize data.

The wizards open fully expanded in the browser window so that you have more room to work.
If you selected Import data, you can select the Samples option to index a Microsoft-hosted dataset from a supported data source.
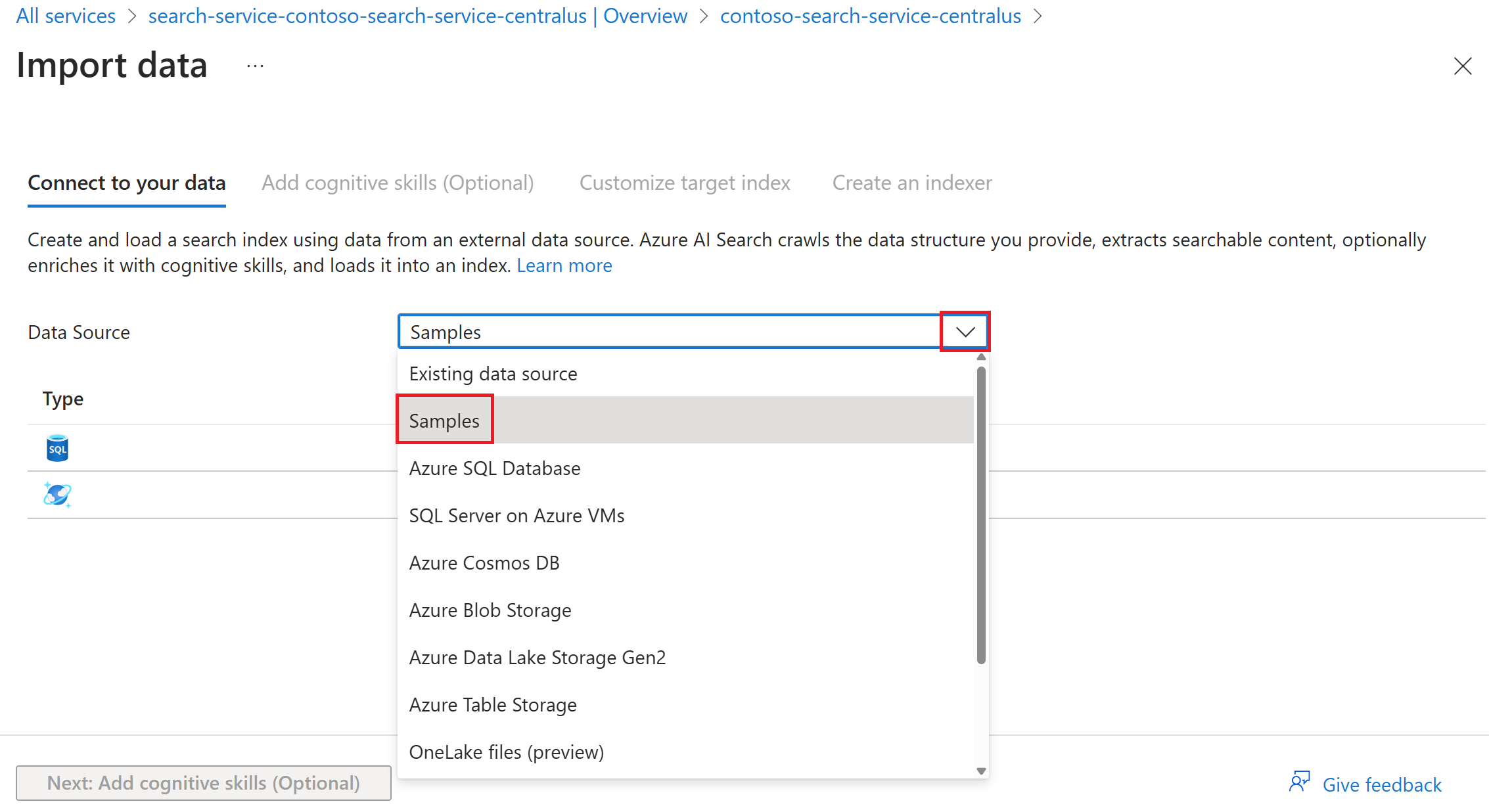
Follow the remaining steps in the wizard to create the index and indexer.
You can also launch Import data from other Azure services, including Azure Cosmos DB, Azure SQL Database, SQL Managed Instance, and Azure Blob Storage. Look for Add Azure AI Search in the left-navigation pane on the service overview page.
Data source configuration in the wizard
The wizards connect to an external supported data source using the internal logic provided by Azure AI Search indexers, which are equipped to sample the source, read metadata, crack documents to read content and structure, and serialize contents as JSON for subsequent import to Azure AI Search.
You can paste in a connection to a supported data source in a different subscription or region, but the Choose an existing connection picker is scoped to the active subscription.
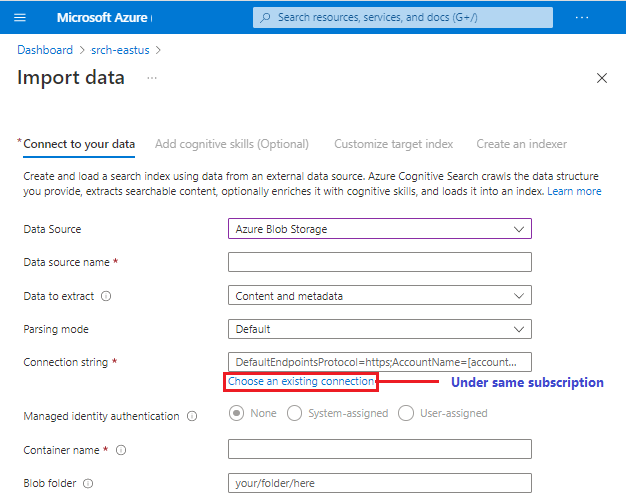
Not all preview data sources are guaranteed to be available in the wizard. Because each data source has the potential for introducing other changes downstream, a preview data source will only be added to the data sources list if it fully supports all of the experiences in the wizard, such as skillset definition and index schema inference.
You can only import from a single table, database view, or equivalent data structure, however the structure can include hierarchical or nested substructures. For more information, see How to model complex types.
Skillset configuration in the wizard
Skillset configuration occurs after the data source definition because the type of data source informs the availability of certain built-in skills. In particular, if you're indexing files from Blob storage, your choice of parsing mode of those files determine whether sentiment analysis is available.
The wizard adds the skills you choose. It also adds other skills that are necessary for achieving a successful outcome. For example, if you specify a knowledge store, the wizard adds a Shaper skill to support projections (or physical data structures).
Skillsets are optional and there's a button at the bottom of the page to skip ahead if you don't want AI enrichment.
Index schema configuration in the wizard
The wizards sample your data source to detect the fields and field type. Depending on the data source, it might also offer fields for indexing metadata.
Because sampling is an imprecise exercise, review the index for the following considerations:
Is the field list accurate? If your data source contains fields that weren't picked up in sampling, you can manually add any new fields that sampling missed, and remove any that don't add value to a search experience or that won't be used in a filter expression or scoring profile.
Is the data type appropriate for the incoming data? Azure AI Search supports the entity data model (EDM) data types. For Azure SQL data, there's mapping chart that lays out equivalent values. For more background, see Field mappings and transformations.
Do you have one field that can serve as the key? This field must be Edm.string and it must uniquely identify a document. For relational data, it might be mapped to a primary key. For blobs, it might be the
metadata-storage-path. If field values include spaces or dashes, you must set the Base-64 Encode Key option in the Create an Indexer step, under Advanced options, to suppress the validation check for these characters.Set attributes to determine how that field is used in an index.
Take your time with this step because attributes determine the physical expression of fields in the index. If you want to change attributes later, even programmatically, you'll almost always need to drop and rebuild the index. Core attributes like Searchable and Retrievable have a negligible effect on storage. Enabling filters and using suggesters increase storage requirements.
Searchable enables full-text search. Every field used in free form queries or in query expressions must have this attribute. Inverted indexes are created for each field that you mark as Searchable.
Retrievable returns the field in search results. Every field that provides content to search results must have this attribute. Setting this field doesn't appreciably affect index size.
Filterable allows the field to be referenced in filter expressions. Every field used in a $filter expression must have this attribute. Filter expressions are for exact matches. Because text strings remain intact, more storage is required to accommodate the verbatim content.
Facetable enables the field for faceted navigation. Only fields also marked as Filterable can be marked as Facetable.
Sortable allows the field to be used in a sort. Every field used in an $Orderby expression must have this attribute.
Do you need lexical analysis? For Edm.string fields that are Searchable, you can set an Analyzer if you want language-enhanced indexing and querying.
The default is Standard Lucene but you could choose Microsoft English if you wanted to use Microsoft's analyzer for advanced lexical processing, such as resolving irregular noun and verb forms. Only language analyzers can be specified in the Azure portal. If you use a custom analyzer or a non-language analyzer like Keyword, Pattern, and so forth, you must create it programmatically. For more information about analyzers, see Add language analyzers.
Do you need typeahead functionality in the form of autocomplete or suggested results? Select the Suggester the checkbox to enable typeahead query suggestions and autocomplete on selected fields. Suggesters add to the number of tokenized terms in your index, and thus consume more storage.
Indexer configuration in the wizard
The last page of the wizard collects user inputs for indexer configuration. You can specify a schedule and set other options that will vary by the data source type.
Internally, the wizard also sets up the following definitions, which aren't visible in the indexer until after it's created:
- field mappings between the data source and index
- output field mappings between skill output and an index
Try the wizards
The best way to understand the benefits and limitations of the wizard is to step through it. Here are some quickstarts that are based on the wizard.