Query the SQL analytics endpoint of your SQL database in Fabric
Applies to: ✅ SQL database in Microsoft Fabric
Every Fabric SQL database is created with a paired SQL analytics endpoint. This allows you to run all of your reporting queries against the OneLake copy of the data without worrying about impacting production. You should run all reporting queries against the SQL analytics endpoint. Query the SQL database directly only for those reports that require the most current data.
Prerequisites
- You need an existing Fabric capacity. If you don't, start a Fabric trial.
- Make sure that you Enable SQL database in Fabric using Admin Portal tenant settings.
- Create a new workspace or use an existing Fabric workspace.
- Create a new SQL database or use an existing SQL database.
- Consider loading the AdventureWorks sample data in a new SQL database.
Access the SQL analytics endpoint
The SQL analytics endpoint can be queried with T-SQL multiple ways:
The first is via the workspace. Every SQL database is paired with a default semantic model and a SQL analytics endpoint. The semantic model and the SQL analytics endpoint always show up together with the SQL database in item listing of the workspace. You can access any of them by selecting them by name from the list.
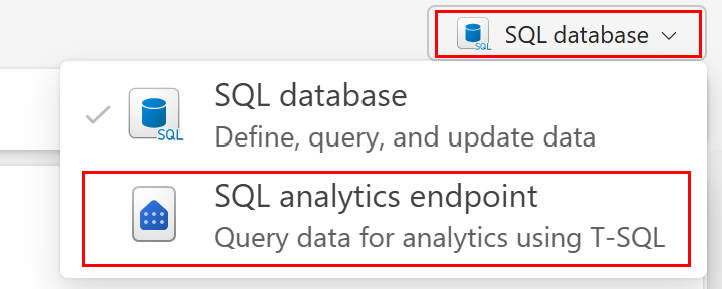
The SQL analytics endpoint can also be accessed from within the SQL query editor. This can be especially useful when toggling between the database and the SQL analytics endpoint. Use the pulldown in the upper right corner to change from the editor to the analytics endpoint.
The SQL analytics endpoint also has its own SQL connection string if you want to query it directly from tools like SQL Server Management Studio or the mssql extension with Visual Studio Code. To get the connection strings, see Find SQL connection strings.
Query the SQL analytics endpoint
Open an existing database with some data, or create a new database and load it with sample data.
Expand the Object Explorer and make note of the tables in the database.
Select the replication menu at the top of the editor, select Monitor Replication.
A list containing the tables in the database will appear. If this is a new database, you'll want to wait until all of the tables have been replicated. There is a refresh button in the toolbar. If there are any problems replicating your data, it is displayed on this page.
Once your tables are replicated, close the Monitor Replication page.
Select the SQL analytics endpoint from the dropdown in the SQL query editor.
You now see that the Object Explorer changed over to the warehouse experience.
Select some of your tables to see the data appear, reading directly from OneLake.
Select the context menu (
...) for any table, and select Properties from the menu. Here you can see the OneLake information andABFSfile path.Close the Properties page and select the context menu (
...) for one the tables again.Select New Query and SELECT TOP 100. Run the query to see the top 100 rows of data, queried from the SQL analytics endpoint, a copy of the database in OneLake.
If you have other databases in your workspace, you can also run queries with cross-database joins. Select the + Warehouse button in the Object Explorer to add the SQL analytics endpoint for another database. You can write T-SQL queries similar to the following that join different Fabric data stores together:
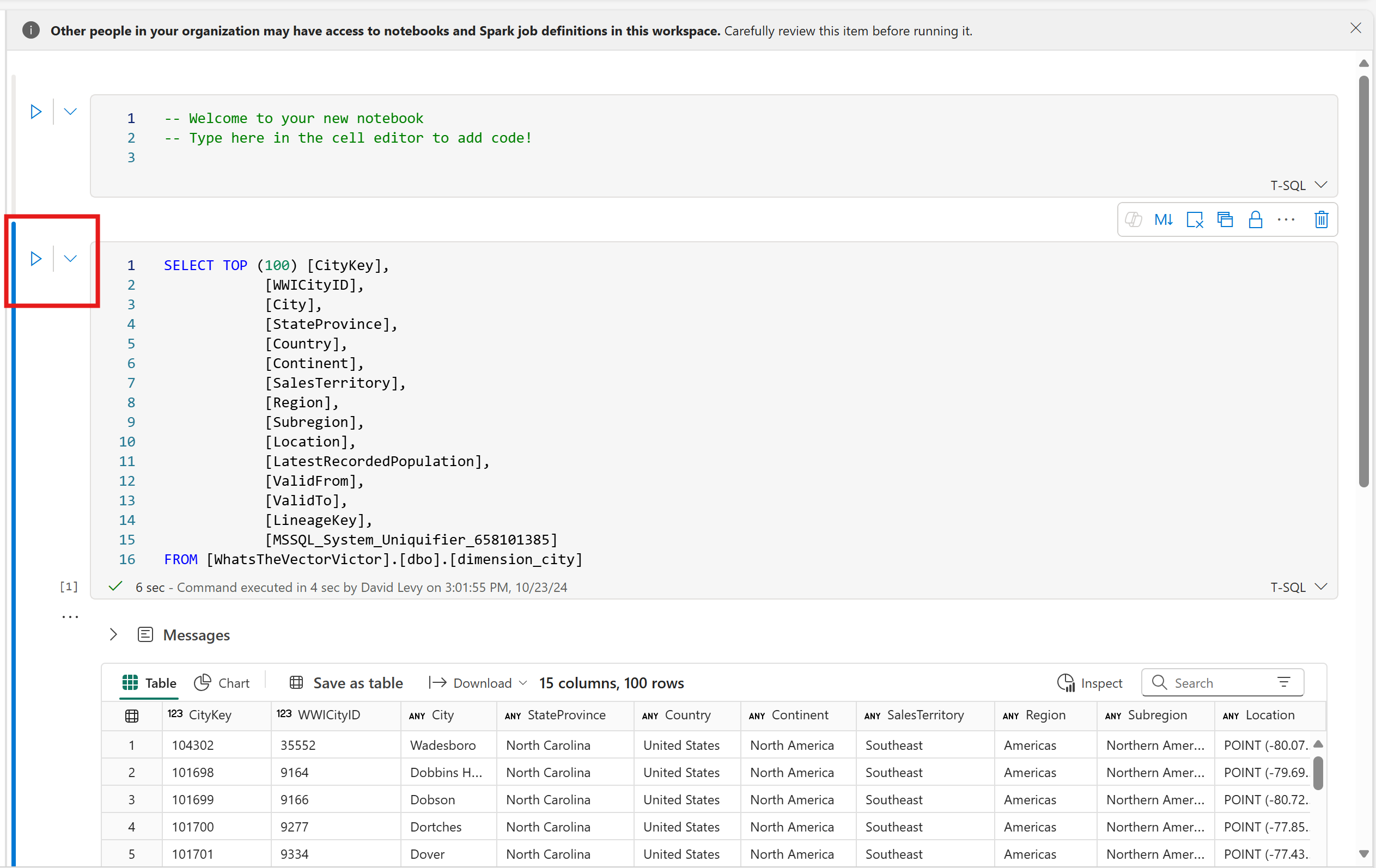
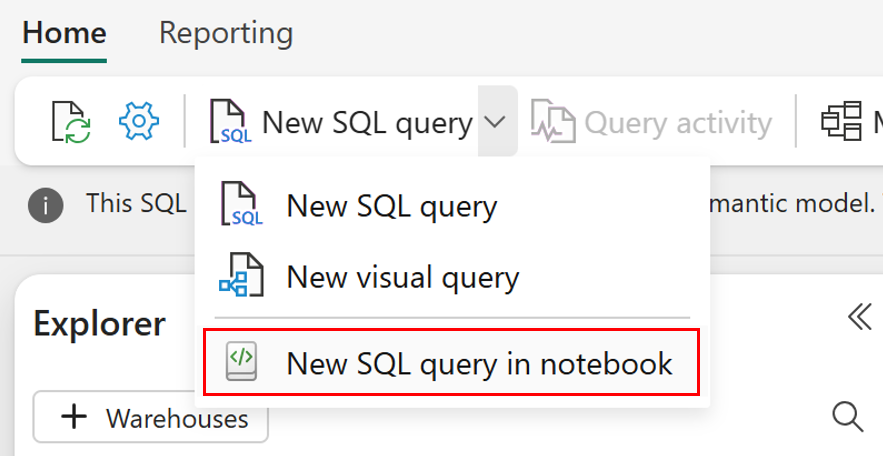
SELECT TOP (100) [a.AccountID], [a.Account_Name], [o.Order_Date], [o.Order_Amount] FROM [Contoso Sales Database].[dbo].[dbo_Accounts] a INNER JOIN [Contoso Order History Database].[dbo].[dbo_Orders] o ON a.AccountID = o.AccountID;Next, select the New Query dropdown from the toolbar, and choose New SQL query in notebook
Once in the notebook experience, select context menu (
...) next to a table, then select SELECT TOP 100.
To run the T-SQL query, select the play button next to the query cell in the notebook.