Transform data with Apache Spark and query with SQL
In this guide, you will:
Upload data to OneLake with the OneLake file explorer.
Use a Fabric notebook to read data on OneLake and write back as a Delta table.
Analyze and transform data with Spark using a Fabric notebook.
Query one copy of data on OneLake with SQL.
Prerequisites
Before you begin, you must:
Download and install OneLake file explorer.
Create a workspace with a Lakehouse item.
Download the WideWorldImportersDW dataset. You can use Azure Storage Explorer to connect to
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityand download the set of csv files. Or you can use your own csv data and update the details as required.
Note
Always create, load, or create a shortcut to Delta-Parquet data directly under the Tables section of the lakehouse. Do not nest your tables in subfolders under the Tables section as the lakehouse will not recognize it as a table and will label it as Unidentified.
Upload, read, analyze, and query data
In OneLake file explorer, navigate to your lakehouse and under the
/Filesdirectory, create a subdirectory nameddimension_city.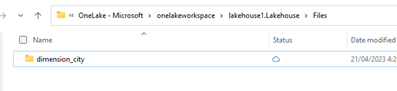
Copy your sample csv files to the OneLake directory
/Files/dimension_cityusing OneLake file explorer.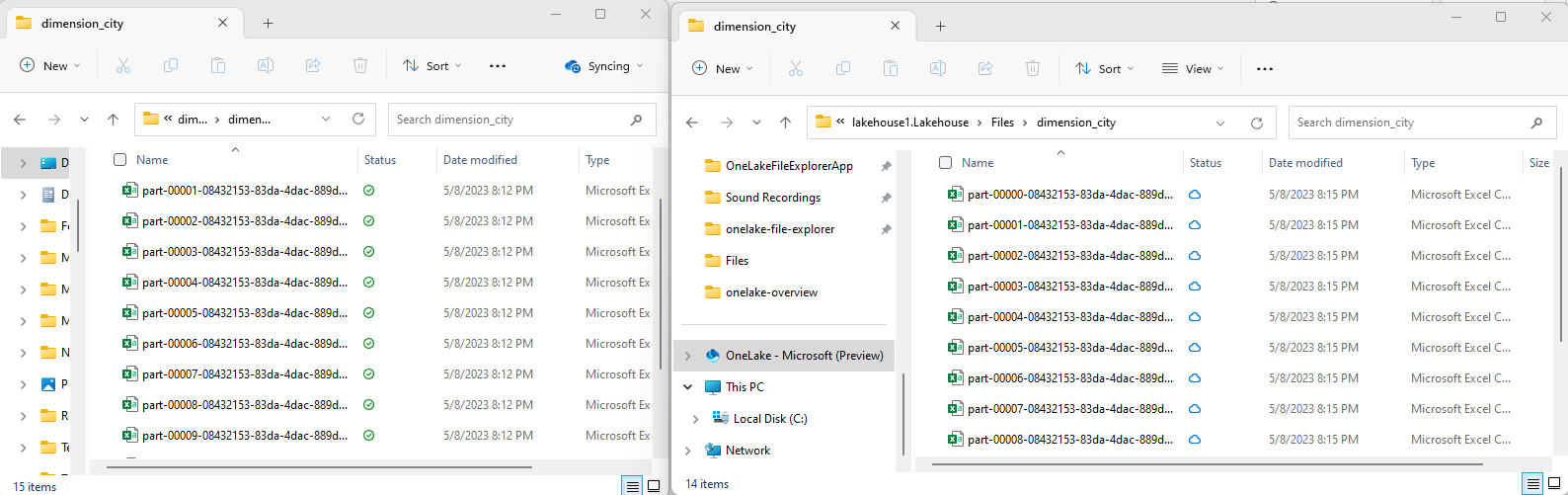
Navigate to your lakehouse in the Power BI service and view your files.
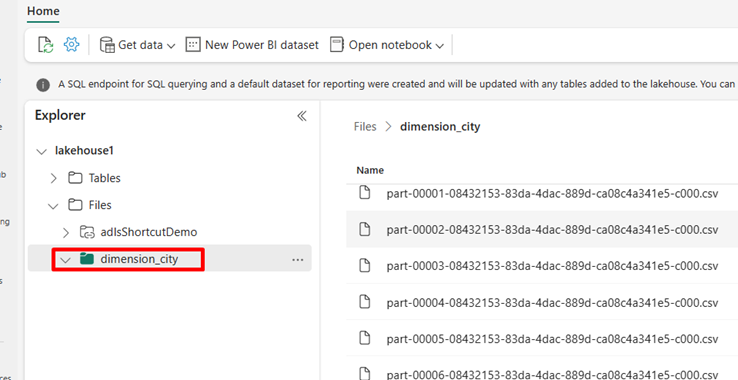
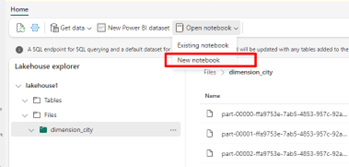
Select Open notebook, then New notebook to create a notebook.
Using the Fabric notebook, convert the CSV files to Delta format. The following code snippet reads data from user created directory
/Files/dimension_cityand converts it to a Delta tabledim_city.import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")To see your new table, refresh your view of the
/Tablesdirectory.
Query your table with SparkSQL in the same Fabric notebook.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Modify the Delta table by adding a new column named newColumn with data type integer. Set the value of 9 for all the records for this newly added column.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;You can also access any Delta table on OneLake via a SQL analytics endpoint. A SQL analytics endpoint references the same physical copy of Delta table on OneLake and offers the T-SQL experience. Select the SQL analytics endpoint for lakehouse1 and then select New SQL Query to query the table using T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
