Kusto Query Language (KQL) graph semantics overview
Applies to: ✅ Microsoft Fabric ✅ Azure Data Explorer ✅ Azure Monitor ✅ Microsoft Sentinel
Graph semantics in Kusto Query Language (KQL) allows you to model and query data as graphs. The structure of a graph comprises nodes and edges that connect them. Both nodes and edges can have properties that describe them.
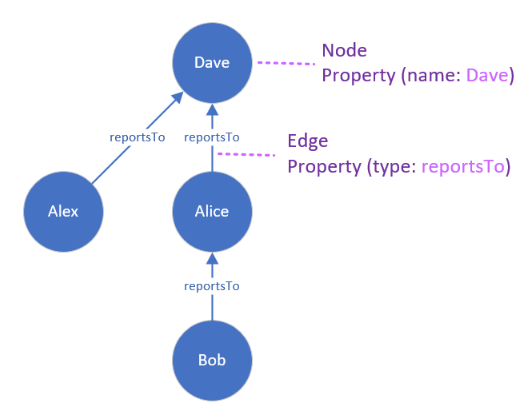
Graphs are useful for representing complex and dynamic data that involve many-to-many, hierarchical, or networked relationships, such as social networks, recommendation systems, connected assets, or knowledge graphs. For example, the following graph illustrates a social network that consists of four nodes and three edges. Each node has a property for its name, such as Bob, and each edge has a property for its type, such as reportsTo.
Graphs store data differently from relational databases, which use tables and need indexes and joins to connect related data. In graphs, each node has a direct pointer to its neighbors (adjacency), so there's no need to index or join anything, making it easy and fast to traverse the graph. Graph queries can use the graph structure and meaning to do complex and powerful operations, such as finding paths, patterns, shortest distances, communities, or centrality measures.
You can create and query graphs using KQL graph semantics, which has a simple and intuitive syntax that works well with the existing KQL features. You can also mix graph queries with other KQL features, such as time-based, location-based, and machine-learning queries, to do more advanced and powerful data analysis. By using KQL with graph semantics, you get the speed and scale of KQL queries with the flexibility and expressiveness of graphs.
For example, you can use:
- Time-based queries to analyze the evolution of a graph over time, such as how the network structure or the node properties change
- Geospatial queries to analyze the spatial distribution or proximity of nodes and edges, such as how the location or distance affects the relationship
- Machine learning queries to apply various algorithms or models to graph data, such as clustering, classification, or anomaly detection
How does it work?
Every query of the graph semantics in Kusto requires creating a new graph representation. You use a graph operator that converts tabular expressions for edges and optionally nodes into a graph representation of the data. Once the graph is created, you can apply different operations to further enhance or examine the graph data.
The graph semantics extension uses an in-memory graph engine that works on the data in the memory of your cluster, making graph analysis interactive and fast. The memory consumption of a graph representation is affected by the number of nodes and edges and their respective properties. The graph engine uses a property graph model that supports arbitrary properties for nodes and edges. It also integrates with all the existing scalar operators of KQL, which gives users the ability to write expressive and complex graph queries that can use the full power and functionality of KQL.
Why use graph semantics in KQL?
There are several reasons to use graph semantics in KQL, such as the following examples:
KQL doesn't support recursive joins, so you have to explicitly define the traversals you want to run (see Scenario: Friends of a friend). You can use the make-graph operator to define hops of variable length, which is useful when the relationship distance or depth isn't fixed. For example, you can use this operator to find all the resources that are connected in a graph or all the places you can reach from a source in a transportation network.
Time-aware graphs are a unique feature of graph semantics in KQL that allow users to model graph data as a series of graph manipulation events over time. Users can examine how the graph evolves over time, such as how the graph's network structure or the node properties change, or how the graph events or anomalies happen. For example, users can use time series queries to discover trends, patterns, or outliers in the graph data, such as how the network density, centrality, or modularity change over time
The intellisense feature of the KQL query editor assists users in writing and executing queries in the query language. It provides syntax highlighting, autocompletion, error checking, and suggestions. It also helps users with the graph semantics extension by offering graph-specific keywords, operators, functions, and examples to guide users through the graph creation and querying process.
Limits
The following are some of the main limits of the graph semantics feature in KQL:
- You can only create or query graphs that fit into the memory of one cluster node.
- Graph data isn't persisted or distributed across cluster nodes, and is discarded after the query execution.
Therefore, When using the graph semantics feature in KQL, you should consider the memory consumption and performance implications of creating and querying large or dense graphs. Where possible, you should use filters, projections, and aggregations to reduce the graph size and complexity.