Stream bot messages
Note
- Streaming bot messages is available only for one-on-one chats and in public developer preview.
- Streaming bot messages isn't available with function calling and the OpenAI
o1model. - Streaming bot messages is supported on web, desktop, and mobile (Android). It isn't supported on iOS.
You can stream bot messages to deliver a bot's responses to the user as small updates while the complete response is being generated to enhance the user experience. Often, bots take a long time to generate responses without updating the user interface, leading to a less engaging experience.
When users observe the bot processing their request in real time, it can increase their satisfaction and trust. This perceived responsiveness and transparency enhances user engagement and decreases conversation abandonment with the bot.
Streaming bot messages has two types of updates:
Informative updates: Informative updates appear as a blue progress bar at the bottom of the chat. It informs the user about the bot's ongoing actions while a response is being generated.

Response streaming: Response streaming is displayed as a typing indicator. It reveals the bot's response to the user as small updates while the complete response is being generated.

You can implement streaming bot messages in your app in one of the following ways:
Stream message through Teams AI library
The Teams AI library provides the capability to stream messages for AI-powered bots. Streaming bot messages helps to ease the response time lag while the Large Language Model (LLM) generates the complete response. The primary factors contributing to slow response time include multiple preprocessing steps, such as Retrieval-Augmented Generation (RAG) or function calls, and the time required by the LLM to generate a full response.
Note
Streaming bot messages is not available with function calling.
Through streaming, your AI bot can offer an experience that is engaging and responsive for the user. Configure the following features for streaming messages for your AI-powered app::
Enable streaming for AI bot:
Bot messages can be streamed through AI SDK. The AI-powered bot sends chunks to the user as the model generates the response. Streaming messages support text. However, attachment, AI-label, feedback loop, and sensitivity labels are available only for the final streaming message.
Set informative message:
You can define an informative message for your AI-powered bot. This message appears for the user every time the bot sends an update. Here are some examples for informative messages that you can set in your app:
- Scanning through documents
- Summarizing content
- Finding relevant work items
The following example shows the information updates in an AI-powered bot:
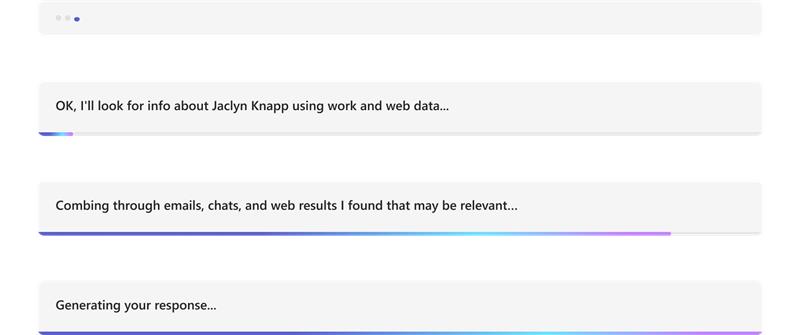
Format the final streamed message:
Using AI SDK, text messages and simple markdown can be formatted while they're being streamed. However, for Adaptive Cards, images, or rich HTML, the formatting can be applied once the final message is complete. The bot can send attachments only in the final streamed chunk.
The following example shows the streaming response in an AI-powered bot:

The following example shows the final streamed response in an AI-powered bot:

Enable AI-powered features for final message:
You can enable the following AI-powered features for the final message sent by the bot:
- Citations: The Teams AI library automatically includes citations in the bot's responses. It provides references for the sources that the bot used to generate the response. It allows users to refer to the source through in-text citations and references.
- Sensitivity Label: Use sensitivity label to help users understand the confidentiality of a message.
- Feedback loop: This allows users to provide positive or negative feedback on the bot messages.
- Generated by AI: The Teams AI library automatically includes a Generated by AI label in the bot's responses. This label helps users identify that a message was generated using AI.
For more information about formatting AI bot messages, see bot messages with AI-generated content.
Configure streaming bot messages
Follow these steps to configure streaming bot messages:
Enable streaming for AI bot:
a. Use the
DefaultAugmentationclass in theconfig.jsonfile, and in one of the following main application classes of your bot app:- For a C# bot app: Update
Program.cs. - For a JavaScript app: Update
index.ts. - For a Python app: Update
bot.py.
b. Set
streamto true in theOpenAIModeldeclaration.- For a C# bot app: Update
Set informative message: Specify the informative message in the
ActionPlannerdeclaration using theStartStreamingMessageconfiguration.Format the final streamed message:
- Set the feedback loop toggle in the
AIOptionsobject within the app declaration and specify a handler.- For a bot app built using Python, set the feedback loop toggle in the
ActionPlannerOptionsobject in addition to theAIOptionsobject.
- For a bot app built using Python, set the feedback loop toggle in the
- Set attachments in the final chunk using the
EndStreamHandlerwithin theActionPlannerdeclaration.
- Set the feedback loop toggle in the
The following code snippet shows an example of streaming bot messages:
// Create OpenAI Model
builder.Services.AddSingleton<OpenAIModel > (sp => new(
new OpenAIModelOptions(config.OpenAI.ApiKey, "gpt-4o")
{
LogRequests = true,
Stream = true, // Set stream toggle
},
sp.GetService<ILoggerFactory>()
));
ResponseReceivedHandler endStreamHandler = new((object sender, ResponseReceivedEventArgs args) =>
{
StreamingResponse? streamer = args.Streamer;
if (streamer == null)
{
return;
}
AdaptiveCard adaptiveCard = new("1.6")
{
Body = [new AdaptiveTextBlock(streamer.Message) { Wrap = true }]
};
var adaptiveCardAttachment = new Attachment()
{
ContentType = "application/vnd.microsoft.card.adaptive",
Content = adaptiveCard,
};
streamer.Attachments = [adaptiveCardAttachment]; // Set attachments
});
// Create ActionPlanner
ActionPlanner<TurnState> planner = new(
options: new(
model: sp.GetService<OpenAIModel>()!,
prompts: prompts,
defaultPrompt: async (context, state, planner) =>
{
PromptTemplate template = prompts.GetPrompt("Chat");
return await Task.FromResult(template);
}
)
{
LogRepairs = true,
StartStreamingMessage = "Loading stream results...", // Set informative message
EndStreamHandler = endStreamHandler // Set final chunk handler
},
loggerFactory: loggerFactory
);
Custom Planner and Model Development
The StreamingResponse class is the helper class for streaming responses to the client. It allows you to send a series of updates in a single response, making the interaction smoother. If you're using your own custom model, you can easily use this class to stream responses seamlessly. It's a great way to keep the user engaged.
Streaming bot messages must use the following sequence:
queueInformativeUpdate()queueTextChunk()endStream()
After your model calls endStream(), the stream ends and the bot can't send any further updates.
Here's a list of other methods that you can use to customize the app experience:
setAttachmentssetSensitivityLabelsetFeedbackLoopsetGeneratedByAILabel
Limitations for Azure OpenAI or OpenAI
- When your bot calls the streaming API too fast, it can cause issues and interrupt the streaming experience. To avoid this, stream one message at a time at a consistent pace. If you don't, the request might be throttled. Buffer the tokens from the model for 1.5 to 2 seconds to ensure smooth streaming.
- AI-powered features like citations, sensitivity label, feedback loop, and Generated by AI label are supported only in the final chunk. Citations are set per each text chunk queued.
- Only rich text can be streamed.
- You can set only one informative message. Your bot reuses this message for each update. Examples include:
- Scanning through documents
- Summarizing content
- Finding relevant work items
- The model renders the informative message only at the beginning of each message returned from the LLM.
- Attachments can be sent only in the final chunk.
- Streaming isn't available with AI SDK's function calls and AOAI or OAI's
o1model yet. - Here are the requirements to use
streamSequencefor AI SDK:- The sequence must start with number '1'.
- Subsequent numbers (except final) must be a monotonic increasing integer (for example, 1->2->3).
- For the final message,
streamSequencemustn't be set.
Stream message through REST API
Bot messages can be streamed through REST API. Streaming messages support rich text and citation. Attachment, AI-label, feedback button, and sensitivity labels are available only for the final streaming message. For more information, see attachments and bot messages with AI-generated content.
When your bot invokes streaming through REST API, ensure to call the next streaming API only after receiving a successful response from the initial API call. If your bot uses SDK, verify that you receive a null response object from the send activity method to confirm that the previous call was successfully transmitted.
When your bot calls streaming API too fast, you may encounter issues and streaming experience can be interrupted. We recommend that your bot streams one message at a time to ensure that it calls the streaming API at a consistent pace. If not, the request might be throttled. Buffer the tokens from the model for 1.5 to two seconds to ensure a smooth streaming process. We recommend that your bot streams one message at a time to ensure that it calls the streaming API at a consistent pace. If not, the request might be throttled. Buffer the tokens from the model for 1.5 to two seconds to ensure a smooth streaming process.
The following are the properties for streaming bot messages:
| Property | Required | Description |
|---|---|---|
type |
✔️ | Supported values are either typing or message. • typing: Use when streaming the message. • message: Use for the final streamed message. |
text |
✔️ | The contents of the message that is to be streamed. |
entities.type |
✔️ | Must be streamInfo |
entities.streamId |
✔️ | streamId from the initial streaming request, start streaming. |
entities.streamType |
Type of streaming updates. Supported values are either informative, streaming, or final. The default value is streaming. final is used only in the final message. |
|
entities.streamSequence |
✔️ | Incremental integer for each request. |
Note
Here are the requirements for using streamSequence for REST APIs:
- First one must be number '1'.
- Subsequent numbers (except final) must be a monotonic increasing integer (for example, 1->2->3).
- For the final message,
streamSequencemust not be set.
To enable streaming in bots, follow these steps:
Start streaming
The bot can send either an informative or a streaming message as its initial communication. The response includes the streamId, which is important for executing subsequent calls.
Your bot can send multiple informative updates while processing the user's request such as, Scanning through documents, Summarizing Content, and Found relevant work items. You can send these updates before your bot generates its final response to the user.
//Ex: A bot sends the first request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
"serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id": "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text": "Searching through documents...", //(required) first informative loading message.
"entities":[
{
"type": "streaminfo",
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 1 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
201 created { "id": "a-0000l" } // return stream id
The following image is an example of start streaming:

Continue streaming
Use the streamId that you've received from the initial request to send either informative or streaming messages. You can start with informative updates and later switch to response streaming when the final response is ready.
Start with informative updates
As your bot generates a response send informative updates to the user such as, Scanning through documents, Summarizing Content, and Found relevant work items. Ensure that you make subsequent calls only after the bot receives successful response from the previous calls.
// Ex: A bot sends the second request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en -US",
"text ": "Searching through emails...", // (required) second informative loading message.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 2 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K { }
The following image is an example of a bot providing informative updates:

Switch to response streaming
After your bot is ready to generate its final message for the user, switch from providing informative updates to response streaming. For every response streaming update, the message content should be the latest version of the final message. This means that your bot should incorporate any new tokens generated by the Large Language Models (LLMs). Append these tokens to the previous message version and then send it to the user.
When the bot dispatches a streaming request, ensure that the bot sends the request at a minimum rate of one request per second.
// Ex: A bot sends the third request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 3 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
// Ex: A bot sends the fourth request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox jumped over the fence", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 4 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
The following image is an example of a bot providing updates in chunks:

Final Streaming
After your bot completes generating its message, send the end streaming signal along with the final message. For the final message, the type of activity is message. Here, the bot sets any fields that are allowed for the regular message activity but final is the only allowed value for streamType.
// Ex: A bot sends the second request with content && the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "message",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text ": "A brown fox jumped over the fence.", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "final", // (required) final is only allowed for the last message of the streaming.
}
],
}
202 0K{ }
The following image is an example of the bot's final response:

Response codes
The following are the success and error codes:
Success codes
| Http status code | Return value | Description |
|---|---|---|
201 |
streamId, this is the same as activityId such as {"id":"1728640934763"} |
The bot returns this value after sending the initial streaming request. For any subsequent streaming requests, the streamId is required. |
202 |
{} |
Success code for any subsequent streaming requests. |
Error codes
| Http status code | Error code | Error message | Description |
|---|---|---|---|
202 |
ContentStreamSequenceOrderPreConditionFailed |
PreCondition failed exception when processing streaming activity. |
Few streaming requests might arrive out of sequence and get dropped. The most recent streaming request, determined by streamSequence, is used when requests are received in a disordered manner. Ensure to send each request in a sequential manner. |
400 |
BadRequest |
Depending on the scenario, you might encounter various error messages such as Start streaming activities should include text |
The incoming payload doesn't adhere to or contain the necessary values. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed |
The streaming API feature isn't allowed for the user or bot. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed on an already completed streamed message |
A bot can't continuously stream on a message that has already streamed and completed. |
403 |
ContentStreamNotAllowed |
Content stream finished due to exceeded streaming time. |
The bot failed to complete the streaming process within the strict time limit of two minutes. |
403 |
ContentStreamNotAllowed |
Message size too large |
The bot sent a message that exceeds the current message size restriction. |
429 |
NA | API calls quota exceeded |
The number of messages streamed by the bot has exceeded quota. |
Code sample
| Sample name | Description | Node.js | C# | Python |
|---|---|---|---|---|
| Teams streaming bot sample | This code sample demonstrates how to build a bot connected to an LLM and send messages through Teams. | NA | View | NA |
| Conversational streaming bot | This is a conversational streaming bot with Teams AI library. | View | View | View |
See also
Platform Docs