Incremental refresh and real-time data for semantic models
Incremental refresh and real-time data for semantic models in Power BI provide efficient ways to handle dynamic data and improve model refresh performance. By automating partition creation and management, incremental refresh reduces the amount of data that needs to be refreshed and allows for the inclusion of real-time data. This article explains how to configure and use incremental refresh features in Power BI to capture fast-moving data and enhance performance.
Incremental refresh extends scheduled refresh operations by providing automated partition creation and management for semantic model tables that frequently load new and updated data. For most models, one or more tables contain transaction data that changes often and can grow exponentially, like a fact table in a relational or star database schema. An incremental refresh policy to partition the table, refreshing only the most recent import partitions, and optionally using another DirectQuery partition for real-time data can significantly reduce the amount of data that has to be refreshed. At the same time, this policy ensures that the latest changes at the data source are included in the query results.
With incremental refresh and real-time data:
- Fewer refresh cycles for fast-changing data are needed. DirectQuery mode gets the latest data updates as queries are processed, without requiring a high refresh cadence.
- Refreshes are faster. Only the most recent data that has changed needs to be refreshed.
- Refreshes are more reliable. Long-running connections to volatile data sources aren't necessary. Queries to source data run faster, reducing potential for network problems to interfere.
- Resource consumption is reduced. Less data to refresh reduces overall consumption of memory and other resources in both Power BI and data source systems.
- Large semantic models are enabled. Semantic models with potentially billions of rows can grow without the need to fully refresh the entire model with each refresh operation.
- Setup is easy. Incremental refresh policies are defined in Power BI Desktop with just a few tasks. When Power BI Desktop publishes the report, the service automatically applies those policies with each refresh.
When you publish a Power BI Desktop model to the service, each table in the new model has a single partition. That single partition contains all rows for that table. If the table is large, say with tens of millions of rows or more, a refresh for that table can take a long time and consume an excessive amount of resources.
With incremental refresh, the service dynamically partitions and separates data that needs to be refreshed frequently from data that can be refreshed less frequently. Table data is filtered by using Power Query date/time parameters with the reserved, case-sensitive names RangeStart and RangeEnd. When you configure incremental refresh in Power BI Desktop, these parameters are used to filter only a small period of data that's loaded into the model. When Power BI Desktop publishes the report to the Power BI service, with the first refresh operation the service creates incremental refresh and historical partitions, and optionally a real-time DirectQuery partition based on the incremental refresh policy settings. The service then overrides the parameter values to filter and query data for each partition based on date/time values for each row.
With each subsequent refresh, the query filters return only those rows within the refresh period dynamically defined by the parameters. Those rows with a date/time within the refresh period are refreshed. Rows with a date/time no longer within the refresh period then become part of the historical period, which isn't refreshed. If a real-time DirectQuery partition is included in the incremental refresh policy, its filter is also updated so that it picks up any changes that occur after the refresh period. Both the refresh and historical periods are rolled forward. As new incremental refresh partitions are created, refresh partitions no longer in the refresh period become historical partitions. Over time, historical partitions become less granular as they're merged together. When a historical partition is no longer in the historical period defined by the policy, it's removed from the model entirely. This behavior is known as a rolling window pattern.
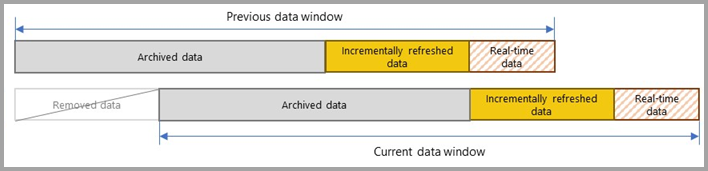
The beauty of incremental refresh is that the service handles all of it for you based on the incremental refresh policies you define. In fact, the process and partitions created from it aren't visible in the service. In most cases, a well-defined incremental refresh policy is all that's necessary to significantly improve model refresh performance. However, the real-time DirectQuery partition is only supported for models in Premium capacities. Power BI Premium also enables more advanced partition and refresh scenarios through the XML for Analysis (XMLA) endpoint.
Requirements
The next sections describe the supported plans and data sources.
Supported plans
Incremental refresh is supported for Power BI Premium, Premium per user, Power BI Pro, and Power BI Embedded models.
Getting the latest data in real time with DirectQuery is only supported for Power BI Premium, Premium per user, and Power BI Embedded models.
Supported data sources
Incremental refresh and real-time data works best for structured, relational data sources like SQL Database and Azure Synapse, but can also work for other data sources. In any case, your data source must support the following:
Date filtering - The data source must support some mechanism to filter data by date. For a relational source, this is typically a date column of the date/time or integer data type on the target table. The RangeStart and RangeEnd parameters, which must be the date/time data type, filter table data based on the date column. For date columns of integer surrogate keys in the form of yyyymmdd, you can create a function that converts the date/time value in the RangeStart and RangeEnd parameters to match the integer surrogate keys of the date column. To learn more, see Configure incremental refresh and real-time data - Convert DateTime to integer.
For other data sources, the RangeStart and RangeEnd parameters must be passed to the data source in some way that enables filtering. For file-based data sources where files and folders are organized by date, the RangeStart and RangeEnd parameters can be used to filter the files and folders to select which files to load. For web-based data sources, the RangeStart and RangeEnd parameters can be integrated into the HTTP request. For example, the following query can be used for incremental refresh of the traces from an AppInsights instance:
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
When incremental refresh is configured, a Power Query expression that includes a date/time filter based on the RangeStart and RangeEnd parameters is executed against the data source. If the filter is specified in a query step after the initial source query, it's important that query folding combines the initial query step with the steps that reference the RangeStart and RangeEnd parameters. For example, in the following query expression, Table.SelectRows will fold because it immediately follows the Sql.Database step, and SQL Server supports folding:
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
There's no requirement for final query to support folding. For example, in the following expression, we use a non-folding NativeQuery but integrate the RangeStart and RangeEnd parameters directly into SQL:
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
However, if the incremental refresh policy includes getting real-time data with DirectQuery, non-folding transformations can't be used. If it’s a pure Import mode policy without real-time data, the query mashup engine might compensate and apply the filter locally, which requires retrieving all rows for the table from the data source. This can cause incremental refresh to be slow, and the process can run out of resources either in the Power BI service or in an on-premises data gateway - effectively defeating the purpose of incremental refresh.
Because support for query folding is different for different types of data sources, verification should be performed to ensure the filter logic is included in the queries being run against the data source. In most cases, Power BI Desktop attempts to perform this verification for you when defining the incremental refresh policy. For SQL-based data sources such as SQL Database, Azure Synapse, Oracle, and Teradata, this verification is reliable. However, other data sources may be unable to verify without tracing the queries. If Power BI Desktop is unable to confirm the queries, a warning is shown in the Incremental refresh policy configuration dialog.
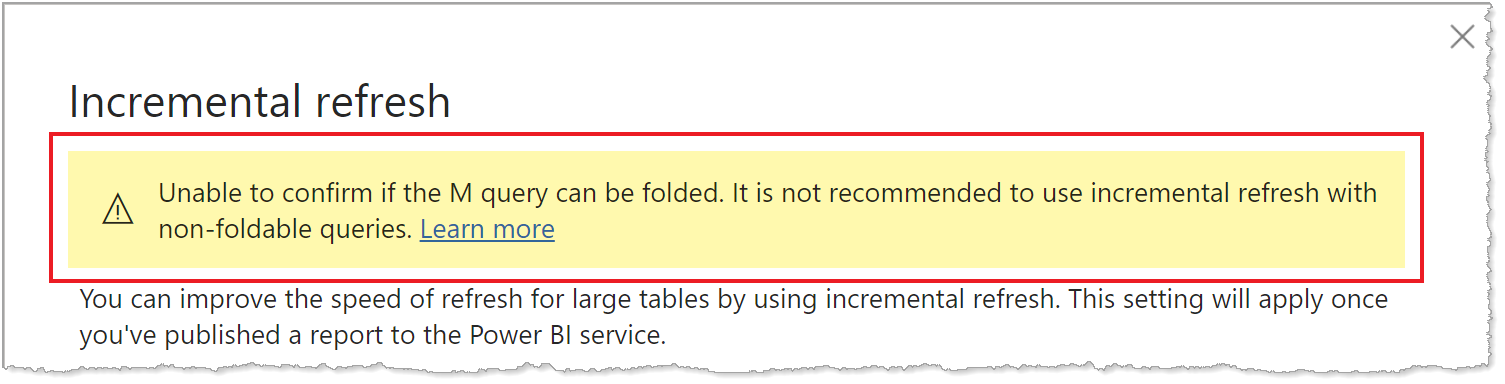
If you see this warning and want to verify the necessary query folding is occurring, use the Power Query Diagnostics feature, or trace queries by using a tool supported by the data source, such as SQL Profiler. If query folding isn't occurring, verify the filter logic is included in the query being passed to the data source. If not, it's likely the query includes a transformation that prevents folding.
Before configuring your incremental refresh solution, be sure to thoroughly read and understand Query folding guidance in Power BI Desktop and Power Query query folding. These articles can help you determine whether your data source and queries support query folding.
Single data source
When you configure incremental refresh and real-time data by using Power BI Desktop, or configure an advanced solution by using Tabular Model Scripting Language (TMSL) or Tabular Object Model (TOM) through the XMLA endpoint, all partitions, whether import or DirectQuery, must query data from a single source.
Other data source types
By using more custom query functions and query logic, incremental refresh can be used with other types of data sources if filters based on RangeStart and RangeEnd can be passed in a single query, like with data sources such as Excel workbook files stored in a folder, files in SharePoint, and RSS feeds. Keep in mind these are advanced scenarios that require further customization and testing beyond what is described here. Be sure to check the Community section later in this article for suggestions on how you can find more information about using incremental refresh for unique scenarios.
Time limits
Regardless of incremental refresh, Power BI Pro models have a refresh time limit of two hours and don't support getting real-time data with DirectQuery. For models in a Premium capacity, the time limit is five hours. Refresh operations are process- and memory-intensive. A full refresh operation can use as much as double the amount of memory required by the model alone, because the service maintains a snapshot of the model in memory until the refresh operation is complete. Refresh operations can also be process-intensive, consuming a significant amount of available CPU resources. Refresh operations must also rely on volatile connections to data sources, and the ability of those data source systems to quickly return query output. The time limit is a safeguard to limit over-consumption of your available resources.
Note
With Premium capacities, refresh operations performed through the XMLA endpoint have no time limit. To learn more, see Advanced incremental refresh with the XMLA endpoint.
Because incremental refresh optimizes refresh operations at the partition level in the model, resource consumption can be significantly reduced. At the same time, even with incremental refresh, unless they go through the XMLA endpoint, refresh operations are bound by those same two-hour and five-hour limits. An effective incremental refresh policy not only reduces the amount of data processed with a refresh operation, but also reduces the amount of unnecessary historical data stored in your model.
Queries can also be limited by a default time limit for the data source. Most relational data sources allow overriding time limits in the Power Query M expression. For example, the following expression uses the SQL Server data-access function to set CommandTimeout to two hours. Each period defined by the policy ranges submits a query observing the command timeout setting:
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
For very large models in Premium capacities that likely contain billions of rows, the initial refresh operation can be bootstrapped. Bootstrapping allows the service to create table and partition objects for the model, but doesn't load and process data into any of the partitions. By using SQL Server Management Studio, you can set partitions to be processed individually, sequentially, or in parallel, to both reduce the amount of data returned in a single query, and also bypass the five-hour time limit. To learn more, see Advanced incremental refresh - Prevent timeouts on initial full refresh.
Current date and time
By default, the current date and time is determined based on Coordinated Universal Time (UTC) at the time of refresh. For on-demand, scheduled and REST API refreshes, you can configure a different time zone under 'Refresh' that will be taken into account when determining the current date and time. For example, a refresh that occurs at 8:00 PM Pacific Time (US and Canada) with a time zone configured determines the current date and time based on Pacific Time, not UTC, which would return the next day.
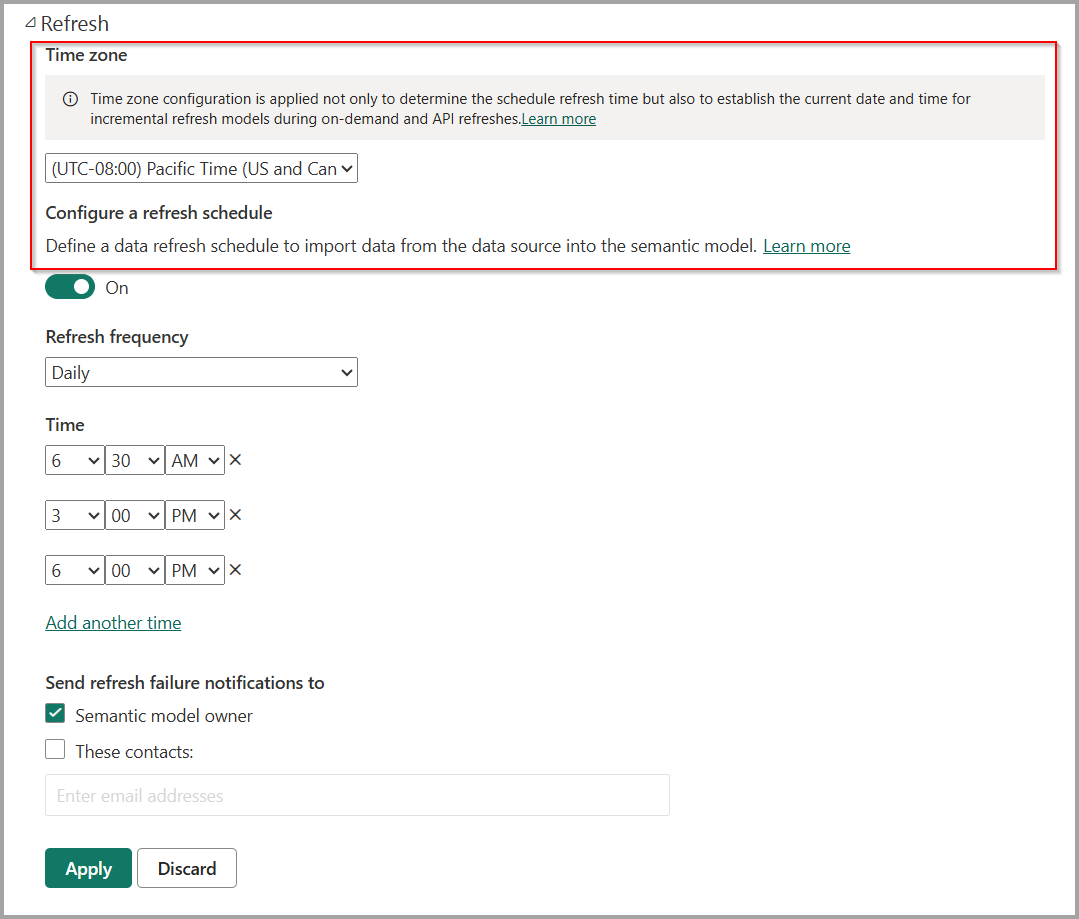
Refresh operations not invoked through the Power BI service, such as the XMLA TMSL refresh command, do not consider the time zone configuration and default to UTC.
Configure incremental refresh and real-time data
This section describes important concepts of configuring incremental refresh and real-time data. When you're ready for more detailed step-by-step instructions, see Configure incremental refresh and real-time data.
Configuring incremental refresh is done in Power BI Desktop. For most models, only a few tasks are required. However, keep the following points in mind:
- After publishing to the Power BI service, you can't publish the same model again from Power BI Desktop. Republishing removes any existing partitions and data already in the model. If you're publishing to a Premium capacity, subsequent metadata schema changes can be made with tools such as the open-source ALM Toolkit, or by using TMSL. To learn more, see Advanced incremental refresh - Metadata-only deployment.
- After publishing to the Power BI service, you can't download the model back as a .pbix to Power BI Desktop. Because models in the service can grow so large, it's impractical to download and open them on a typical desktop computer.
- When getting real-time data with DirectQuery, you can't publish the model to a non-Premium workspace. Incremental refresh with real-time data is only supported with Power BI Premium.
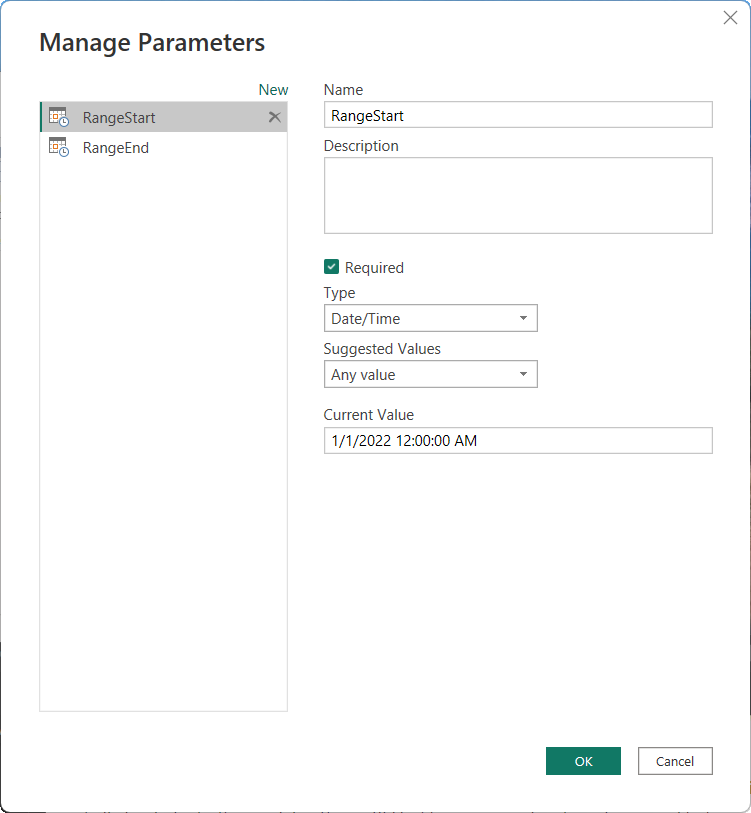
Create parameters
To configure incremental refresh in Power BI Desktop, you first create two Power Query date/time parameters with the reserved, case-sensitive names RangeStart and RangeEnd. These parameters, defined in the Manage Parameters dialog in Power Query Editor, are initially used to filter the data loaded into the Power BI Desktop model table to include only those rows with a date/time within that period. RangeStart represents the oldest, or earliest date/time, and RangeEnd represents the newest, or latest date/time. After the model is published to the service, RangeStart and RangeEnd are overridden automatically by the service to query data defined by the refresh period specified in the incremental refresh policy settings.
For example, the FactInternetSales data source table averages 10,000 new rows per day. To limit the number of rows initially loaded into the model in Power BI Desktop, specify a two-day period between RangeStart and RangeEnd.
Filter data
With the RangeStart and RangeEnd parameters defined, you apply custom date filters on your table's date column. The filters you apply select a subset of data that's loaded into the model when you select Apply.
With our FactInternetSales example, after creating filters based on the parameters and applying steps, two days of data (roughly 20,000 rows) are loaded into the model.
Define policy
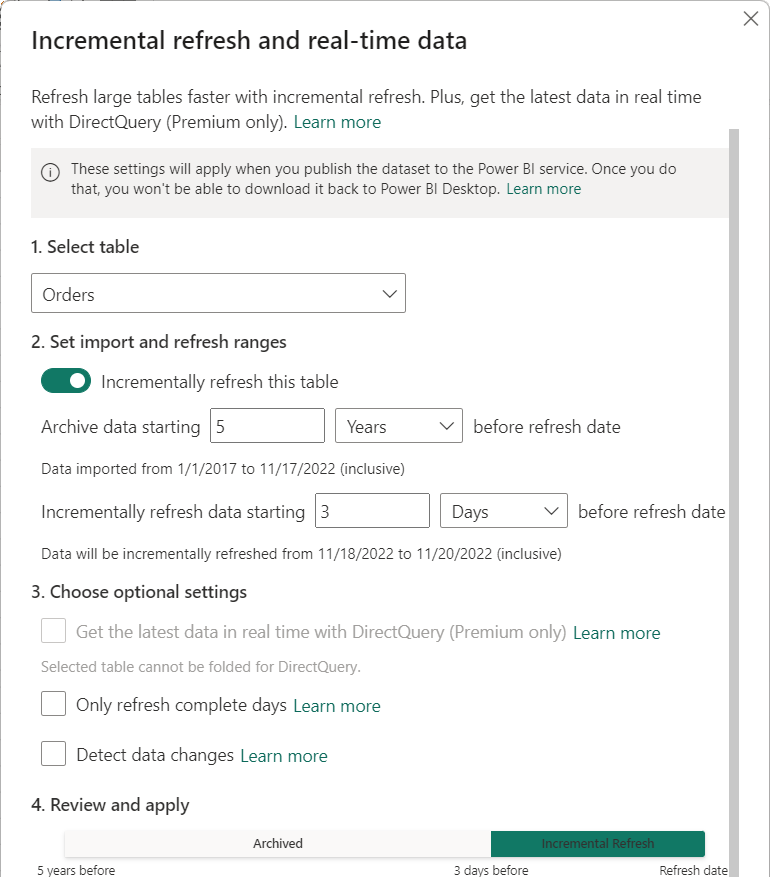
After filters have been applied and a subset of data has been loaded into the model, you define an incremental refresh policy for the table. After the model is published to the service, the policy is used by the service to create and manage table partitions and perform refresh operations. To define the policy, you use the Incremental refresh and real-time data dialog box to specify both required and optional settings.
Table
The Select table listbox defaults to the table you selected in Data view. Enable incremental refresh for the table with the slider. If the Power Query expression for the table doesn't include a filter based on the RangeStart and RangeEnd parameters, the toggle isn't available.
Required settings
The Archive data starting before refresh date setting determines the historical period in which rows with a date/time in that period are included in the model, plus rows for the current incomplete historical period, plus rows in the refresh period up to the current date and time.
For example, if you specify five years, the table stores the last five whole years of historical data in year partitions. The table will also include rows for the current year in quarter, month, or day partitions, up to and including the refresh period.
For models in Premium capacities, backdated historical partitions can be selectively refreshed at a granularity determined by this setting. To learn more, see Advanced incremental refresh - Partitions.
The Incrementally refresh data starting before refresh date setting determines the incremental refresh period in which all rows with a date/time in that period are included in the refresh partitions and refreshed with each refresh operation.
For example, if you specify a refresh period of three days, with each refresh operation, the service overrides the RangeStart and RangeEnd parameters to create a query for rows with a date/time within a three-day period, with the beginning and ending dependent on the current date and time. Rows with a date/time in the last three days up to the current refresh operation time are refreshed. With this type of policy, you can expect our FactInternetSales model table in the service, which averages 10,000 new rows per day, to refresh roughly 30,000 rows with each refresh operation.
Specify a period that includes only the minimum number of rows required to ensure accurate reporting. When you define policies for more than one table, the same RangeStart and RangeEnd parameters must be used even if different store and refresh periods are defined for each table.
Optional settings
The Get the latest data in real time with DirectQuery (Premium only) setting enables fetching the latest changes from the selected table at the data source beyond the incremental refresh period by using DirectQuery. All rows with a date/time later than the incremental refresh period are included in a DirectQuery partition and fetched from the data source with every model query.
For example, if this setting is enabled, with each refresh operation, the service still overrides the RangeStart and RangeEnd parameters to create a query for rows with a date/time after the refresh period, with the beginning dependent on the current date and time. Rows with a date/time after the current refresh operation time are also included. With this type of policy, the FactInternetSales model table in the service includes the latest data updates.
The Only refresh complete days setting ensures all rows for the entire day are included in the refresh operation. This setting is optional unless you enable the Get the latest data in real time with DirectQuery (Premium only) setting. For example, say your refresh is scheduled to run at 4:00 AM every morning. If new rows of data appear in the data source table during those four hours between midnight and 4:00 AM, you don't want to account for them. Some business metrics, like barrels per day in the oil and gas industry, make no sense with partial days. Another example is refreshing data from a financial system where data for the previous month is approved on the twelfth calendar day of the month. You could set the refresh period to one month and schedule the refresh to run on the twelfth day of the month. With this option selected, it would, for example, refresh January data on February 12.
Keep in mind, unless time zone under 'Refresh' is configured for a non-UTC one, refresh operations in the service run under UTC time, which can determine the effective date and complete periods.
The Detect data changes setting enables even more selective refresh. You can select a date/time column used to identify and refresh only those days where the data has changed. This setting assumes such a column exists in the data source, which is typically for auditing purposes. This column shouldn't be the same column used to partition the data with the RangeStart and RangeEnd parameters. The maximum value of this column is evaluated for each of the periods in the incremental range. If it hasn't changed since the last refresh, there's no need to refresh the period, which could potentially further reduce the days incrementally refreshed from three to one.
The current design requires that the column to detect data changes is persisted and cached into memory. The following techniques can be used to reduce cardinality and memory consumption:
- Persist only the maximum value of the column at the time of refresh, perhaps by using a Power Query function.
- Reduce the precision to an acceptable level, given your refresh-frequency requirements.
- Define a custom query for detecting data changes by using the XMLA endpoint, and avoid persisting the column value altogether.
In some cases, enabling the Detect data changes option can be further enhanced. For example, you may want to avoid persisting a last-update column in the in-memory cache, or enable scenarios where a configuration/instruction table is prepared by extract-transform-load (ETL) processes for flagging only those partitions that need to be refreshed. In cases like these, for Premium capacities, use TMSL and/or the TOM to override the detect data changes behavior. To learn more, see Advanced incremental refresh - Custom queries for detect data changes.
Publish
After configuring the incremental refresh policy, you publish the model to the service. When publishing is complete, you can perform the initial refresh operation on the model.
Note
Semantic models with an incremental refresh policy to get the latest data in real time with DirectQuery can only be published to a Premium workspace.
For models published to workspaces assigned to Premium capacities, if you think the model will grow beyond 1 GB, you can improve refresh operation performance and ensure the model doesn't max out size limits by enabling the Large semantic model storage format setting before performing the first refresh operation in the service. To learn more, see Large models in Power BI Premium.
Important
After Power BI Desktop publishes the model to the service, you can't download that .pbix back.
Refresh
After publishing to the service, you perform an initial refresh operation on the model. This refresh should be an individual (manual) refresh so you can monitor progress. The initial refresh operation can take quite a while to complete. Partitions must be created, historical data loaded, objects such as relationships and hierarchies built or rebuilt, and calculated objects recalculated.
Subsequent refresh operations, either individual or scheduled, are much faster because only the incremental refresh partitions are refreshed. Other processing operations must still occur, like merging partitions and recalculation, but it usually takes much less time than the initial refresh.
Automatic report refresh
For reports that use a model with an incremental refresh policy to get the latest data in real time with DirectQuery, it's a good idea to enable automatic page refresh at a fixed interval or based on change detection so that the reports include the latest data without delay. To learn more, see Automatic page refresh in Power BI.
Advanced incremental refresh
If your model is on a Premium capacity with an XMLA endpoint enabled, incremental refresh can be further extended for advanced scenarios. For example, you can use SQL Server Management Studio to view and manage partitions, bootstrap the initial refresh operation, or refresh backdated historical partitions. To learn more, see Advanced incremental refresh with the XMLA endpoint.
Community
Power BI has a vibrant community where MVPs, BI pros, and peers share expertise in discussion groups, videos, blogs, and more. When learning about incremental refresh, refer to these resources:
- Power BI Community
- Search "Power BI incremental refresh" on Bing
- Search "Incremental refresh for files" on Bing
- Search "Keep existing data using incremental refresh" on Bing