Database snapshots (SQL Server)
Applies to: ![]() SQL Server
SQL Server
A database snapshot is a read-only, static view of a SQL Server database (the source database). It's transactionally consistent with the source database as of the snapshot's creation and always resides on the same server instance as its source database. While database snapshots provide a read-only view of the data in the same state as when the snapshot was created, the size of the snapshot file grows as changes are made to the source database.
While database snapshots can be beneficial during major schema upgrades and allow for reverting to a previous state, it's crucial to understand that snapshots don't replace the need for regular backups. You can't back up or restore database snapshots, which means they should be used with a robust backup strategy to ensure data protection and recovery if there is data loss or corruption.
Database snapshots are created with the CREATE DATABASE T-SQL syntax, using the AS SNAPSHOT OF syntax.
Multiple snapshots can exist on a given source database. Each database snapshot persists until the database owner explicitly drops it.
Note
Database snapshots are unrelated to snapshot backups, Transact-SQL snapshot backups, snapshot isolation of transactions, or snapshot replication.
Feature Overview
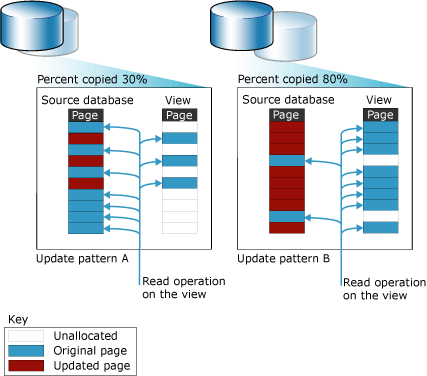
Database snapshots operate at the data page level. Before a page of the source database is modified for the first time, the original page is copied from the source database to the snapshot. The snapshot stores the original page, preserving the data records as they existed when the snapshot was created. The same process is repeated for every page being modified for the first time. To the user, a database snapshot appears never to change because read operations on a database snapshot always access the original data pages, regardless of where they reside.
The snapshot stores the copied original pages using one or more sparse files. Initially, a sparse file is an empty file that contains no user data and hasn't yet been allocated disk space for user data. The file size grows as more pages are updated in the source database. The following figure illustrates the effects of two contrasting update patterns on the size of a snapshot. Update pattern A reflects an environment in which only 30 percent of the original pages are updated during the life of the snapshot. Update pattern B reflects an environment in which 80 percent of the original pages are updated during the life of the snapshot.
Benefits
Snapshots can be used for reporting purposes.
- Clients can query a database snapshot, which helps write reports based on the data when the snapshot is created.
Maintaining historical data for report generation.
- A snapshot can extend user access to data from a particular point in time. For example, you can create a database snapshot for later reporting at the end of a given period (such as a financial quarter). You can then run end-of-period reports on the snapshot. If disk space permits, you can also maintain end-of-period snapshots indefinitely, allowing queries against the results from these periods, for example, to investigate organizational performance.
Using a mirror database you maintain for availability purposes to offload reporting.
- Using database snapshots with database mirroring permits you to make the data on the mirror server accessible for reporting. Additionally, running queries on the mirror database can free up resources for the principal. For more information, see Database Mirroring and Database Snapshots (SQL Server).
Safeguarding data against administrative error.
If a user error occurs in a source database, you can revert it to its state when a database snapshot is created. Data loss is confined to updates to the database since the snapshot's creation.
For example, before doing major updates, such as a bulk update or a schema change, create a database snapshot on the database to protect data. If you make a mistake, you can use the snapshot to recover by reverting the database to the snapshot. Reverting is faster than restoring from a backup; however, you can't roll forward afterward.
Important
Reverting does not work in an offline or corrupted database. Therefore, regular backups and testing your restore plan are necessary to protect a database.
Note
Database snapshots are dependent on the source database. Therefore, using snapshots to revert a database is not a substitute for your backup and restore strategy. Performing all your scheduled backups remains essential. If you must restore the source database to the point where you created a database snapshot, implement a backup policy that enables you to do that.
Safeguarding data against user error.
By creating database snapshots regularly, you can mitigate the impact of a major user error, such as a dropped table. For a high level of protection, you can create a series of database snapshots spanning enough time to recognize and respond to most user errors. For instance, depending on your disk resources, you might maintain 6 to 12 rolling snapshots spanning a 24-hour interval. Then, each time a new snapshot is created, the earliest snapshot can be deleted.
To recover from a user error, you can revert the database to the snapshot immediately before the error. Reverting is potentially much faster than restoring from a backup; however, you can't roll forward afterward.
Alternatively, you can manually reconstruct a dropped table or other lost data from the information in a snapshot. For instance, you could bulk copy the data from the snapshot into the database and manually merge the data back into the database.
Note
Your reasons for using database snapshots determine how many concurrent snapshots you need on a database, how frequently to create a new snapshot, and how long to keep it.
Managing a test database.
- In a testing environment, it can be useful for the database to contain identical data at the start of each round of testing when repeatedly running a test protocol. Before running the first round, an application developer or tester can create a snapshot of the test database. After each test run, the database can be quickly returned to its prior state by reverting the database snapshot.
Terms and definitions
Database snapshots in SQL Server involve several key terms and definitions. A database snapshot is a read-only, static view of a database (referred to as the source database) at a specific point in time. The source database is the original database on which the snapshot is based, and it must remain online and accessible for the snapshot to be usable. Sparse files store the original pages of the source database that have been modified since the snapshot was created. These files are initially empty and grow as changes occur in the source database. Understanding these terms is essential for effectively managing and utilizing database snapshots in SQL Server.
Database snapshot
A transactionally consistent, read-only, static view of a database (the source database).
Source database
For a database snapshot, the database on which the snapshot was created. Database snapshots are dependent on the source database. The snapshots of a database must be on the same server instance as the database. Furthermore, if that database becomes unavailable for any reason, its snapshots become unavailable.
Sparse file
The NTFS file system provides a file that requires much less disk space than would otherwise be needed. A sparse file is used to store pages copied to a database snapshot. When first created, a sparse file takes up little disk space. As data is written to a database snapshot, NTFS allocates disk space gradually to the corresponding sparse file.
Prerequisites
The source database, which can use any recovery model, must meet the following prerequisites:
The server instance must run on an edition of SQL Server that supports database snapshots.
- For more information, see Features Supported by the Editions of SQL Server 2016.
The source database must be online unless it's a mirror database within a database mirroring session.
You can create a database snapshot in an availability group on any primary or secondary database. The replica role must be either PRIMARY or SECONDARY, not in the RESOLVING state.
We recommend that the database synchronization state be SYNCHRONIZING or SYNCHRONIZED when you create a database snapshot. However, database snapshots can be created when the state is NOT SYNCHRONIZING.
- For more information, see Database Snapshots with Always On Availability Groups (SQL Server).
To create a database snapshot on a mirror database, the database must be in the SYNCHRONIZED mirroring state.
The source database can't be configured as a scalable shared database.
Before SQL Server 2019, the source database couldn't contain a MEMORY_OPTIMIZED_DATA filegroup. Support for in-memory database snapshots was added in SQL Server 2019.
All recovery models support database snapshots.
Limitations on the source database
As long as a database snapshot exists, the following limitations exist on the snapshot's source database:
The database can't be dropped, detached, or restored.
Backing up the source database usually works, but it isn't affected by database snapshots.
Performance is reduced due to increased I/O on the source database resulting from a copy-on-write operation to the snapshot every time a page is updated.
Files can't be dropped from the source database or any snapshots.
Limitations on Database snapshots
Database snapshots depend on the source database and don't protect against disk errors or corruption. Therefore, while they can be useful for reporting purposes or during schema changes, they should complement, not replace, regular backup practices. If you need to restore the source database to the point where you created a database snapshot, implement a backup policy that enables you to do that.
The following limitations apply to database snapshots:
A database snapshot must be created and remain on the same server instance as the source database.
Database snapshots always work on an entire database.
Database snapshots depend on the source database and aren't redundant storage. They don't protect against disk errors or other types of corruption. Therefore, using snapshots to revert a database isn't a substitute for your backup and restore strategy. Performing all your scheduled backups remains essential. If you must restore the source database to the point where you created a database snapshot, implement a backup policy that enables you to do that.
When a page getting updated on the source database is pushed to a snapshot, if the snapshot runs out of disk space or encounters some other error, it becomes suspect and must be deleted.
Snapshots are read-only. Since they're read-only, they can't be upgraded. Therefore, database snapshots aren't expected to be viable after an upgrade.
Snapshots of the
model,master, andtempdbdatabases are prohibited.You can't change any of the specifications of the database snapshot files.
You can't drop files from a database snapshot.
You can't back up or restore database snapshots.
You can't attach or detach database snapshots.
You can't create database snapshots on the FAT32 file system or RAW partitions. The NTFS file system provides the sparse files used by database snapshots.
Full-text indexing isn't supported on database snapshots. Full-text catalogs aren't propagated from the source database.
A database snapshot inherits the security constraints of its source database at the time of snapshot creation. Because snapshots are read-only, inherited permissions can't be changed, and permission changes made to the source won't be reflected in existing snapshots.
A snapshot always reflects the state of filegroups at the time of snapshot creation: online filegroups remain online, and offline filegroups remain offline. For more information, see "Database Snapshots with Offline Filegroups" later in this article.
If a source database becomes RECOVERY_PENDING, its snapshots might become inaccessible. However, after the issue on the source database is resolved, its snapshots should become available again.
Reverting is unsupported for any NTFS read-only or NTFS compressed files in the database. Attempts to revert a database containing either of these types of filegroups fail.
In a log shipping configuration, database snapshots can be created only on the primary database, not a secondary one. Suppose you switch roles between the primary and secondary server instances. In that case, you must drop all the database snapshots before setting up the primary database as a secondary one.
A database snapshot can't be configured as a scalable shared database.
Database snapshots don't support FILESTREAM filegroups. If FILESTREAM filegroups exist in a source database, they're marked as offline in its database snapshots, and the snapshots can't be used to revert the database.
Note
A SELECT statement that is executed on a database snapshot must not specify a FILESTREAM column; otherwise, the following error message will be returned: Could not continue scan with NOLOCK due to data movement.
- When statistics on a read-only snapshot are missing or stale, the Database Engine creates and maintains temporary statistics in
tempdb. See Statistics for more information.
Disk space
Database snapshots consume disk space. If a database snapshot runs out of disk space, it's marked as suspect and must be dropped. (The source database, however, isn't affected; actions on it continue normally.)
However, snapshots are highly space-efficient compared to a full copy of a database. A snapshot requires only enough storage for the pages that change during its lifetime. Generally, snapshots are kept for a limited time, so their size isn't a significant concern.
However, the longer you keep a snapshot, the more likely it's to use up available space. The maximum size to which a sparse file can grow is the corresponding source database file size at the time of the snapshot creation. A database snapshot must be deleted (dropped) if it runs out of disk space.
Note
Except for file space, a database snapshot consumes roughly as many resources as a database.
Offline filegroups
Offline filegroups in the source database affect database snapshots when you try to do any of the following:
Create a snapshot.
- When a source database has one or more offline filegroups, snapshot creation succeeds with the filegroups offline. Sparse files aren't created for the offline filegroups.
Take a filegroup offline
- You can take a file offline in the source database. However, the filegroup remains online in database snapshots if it was online when the snapshot was created. If the queried data has changed since the snapshot creation, the original data page is accessible in the snapshot. However, queries that use the snapshot to access unmodified data in the filegroup are likely to fail with input/output (I/O) errors.
Bring a filegroup online
- You can't bring a filegroup online in a database that has any database snapshots. If a filegroup is offline at the time of snapshot creation or is taken offline while a database snapshot exists, it remains offline. This is because bringing a file back online involves restoring it, which isn't possible if a database snapshot exists on the database.
Revert the source database to the snapshot
- Reverting a source database to a database snapshot requires that all of the filegroups be online except for those that were offline when the snapshot was created.
Related content
- Database Mirroring and Database Snapshots (SQL Server)
- CREATE DATABASE - Database Snapshots
- Create a Database Snapshot (Transact-SQL)
- View a Database Snapshot (SQL Server)
- View the Size of the Sparse File of a Database Snapshot (Transact-SQL)
- Revert a Database to a Database Snapshot
- Drop a Database Snapshot (Transact-SQL)