Store vectors in Azure Database for PostgreSQL
Recall that you require embedding vectors stored in a vector database to run a semantic search. Azure Database for PostgreSQL flexible server can be used as a vector database with the vector extension.
Introduction to vector
The open-source vector extension provides vector storage, similarity querying, and other vector operations for PostgreSQL. Once enabled, you can create vector columns to store embeddings (or other vectors) alongside other columns.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
You can add vector columns to existing tables:
ALTER TABLE documents ADD COLUMN embedding vector(3);
Once you have some vector data, you can see it alongside normal table data:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
The vector extension supports several languages, such as .NET, Python, Java, and many others. See their GitHub repositories for more.
To insert a document with vector [1, 2, 3] using Npgsql in C#, run code like this:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
Insert and update vectors
Once a table has a vector column, rows can be added with vector values, as previously noted.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
You can also load vectors in bulk using the COPY statement (see complete example in Python):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
Vector columns can be updated like standard columns:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
Perform a cosine distance search
The vector extension provides the v1 <=> v2 operator to calculate the cosine distance between vectors v1 and v2. The result is a number between 0 and 2, where 0 means "semantically identical" (no distance) and two means "semantically opposite" (maximum distance).
You can see the terms cosine distance and similarity. Recall that cosine similarity is between -1 and 1, where -1 means "semantically opposite" and 1 means "semantically identical." Note that similarity = 1 - distance.
The upshot is that a query ordered by distance ascending returns the least distant (most similar) results first, while a query ordered by similarity descending returns the most similar (least distant) results first.
Here are some vectors and their distances and similarities to illustrate the concepts. You can compute this calculation yourself by running something like:
SELECT '[1,1]' <=> '[-1,-1]';
Consider these vectors:
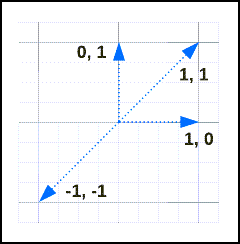
Their similarities and distances are:
| v1 | V2 | distance | similarity |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
To get the documents in order of closeness to the vector [2, 3, 4], run this query:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Results:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
The document with id=3 is the most similar to the query, followed shortly by id=1, and lastly by id=2.
Add a LIMIT N clause to the SELECT query to return the top N most similar documents. For example, to get the most similar document:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Results:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535