Assess the model performance
Evaluating your model's performance at different phases is crucial to ensure its effectiveness and reliability. Before exploring the various options you have to evaluate your model, let's explore the aspects of your application you can evaluate.
When you develop a generative AI app, you use a language model in your chat application to generate a response. To help you decide which model you want to integrate into your application, you can evaluate the performance of an individual language model:
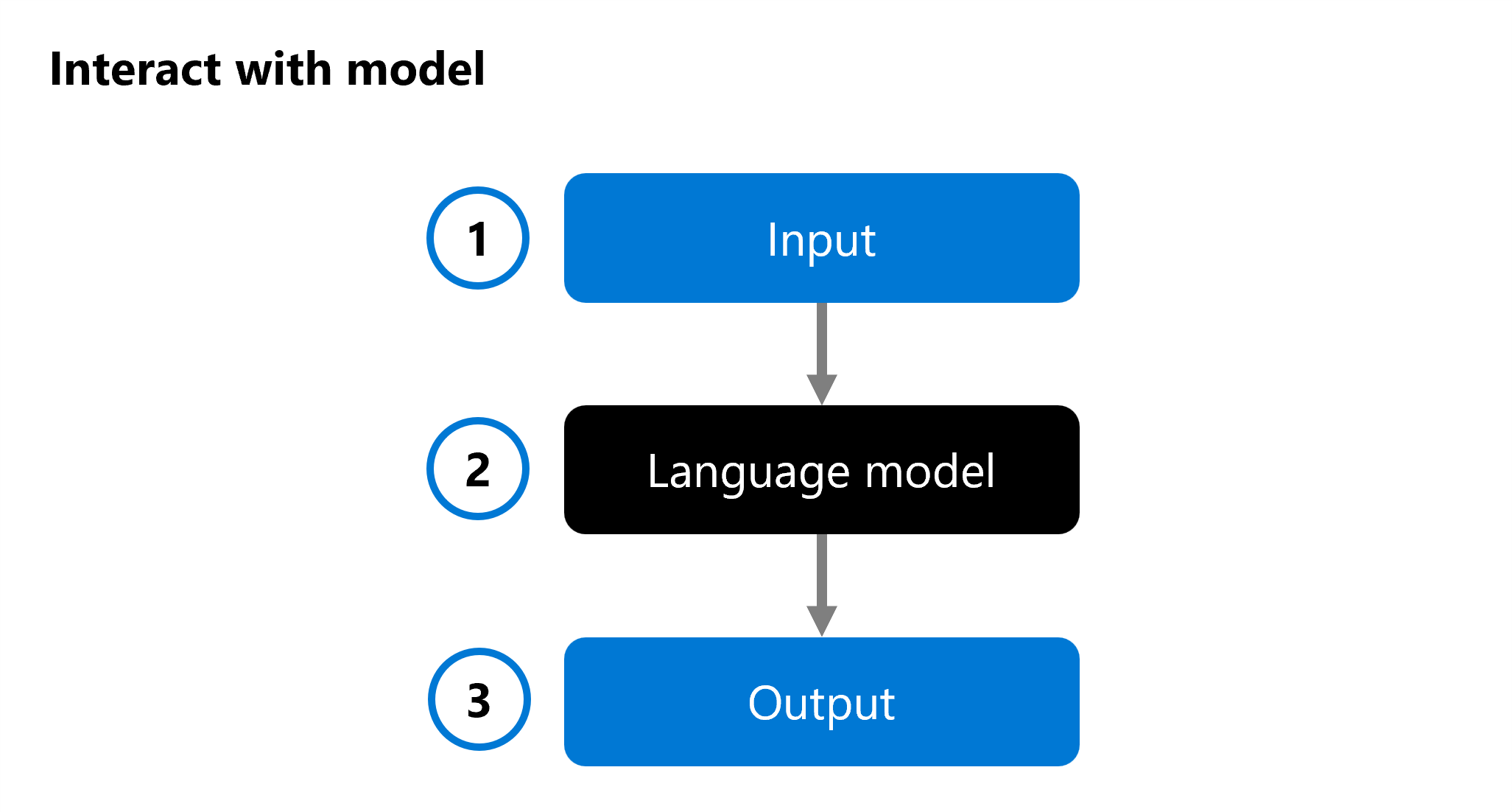
An input (1) is provided to a language model (2), and a response is generated as output (3). The model is then evaluated by analyzing the input, the output, and optionally comparing it to predefined expected output.
When you develop a generative AI app, you integrate a language model into a chat flow:
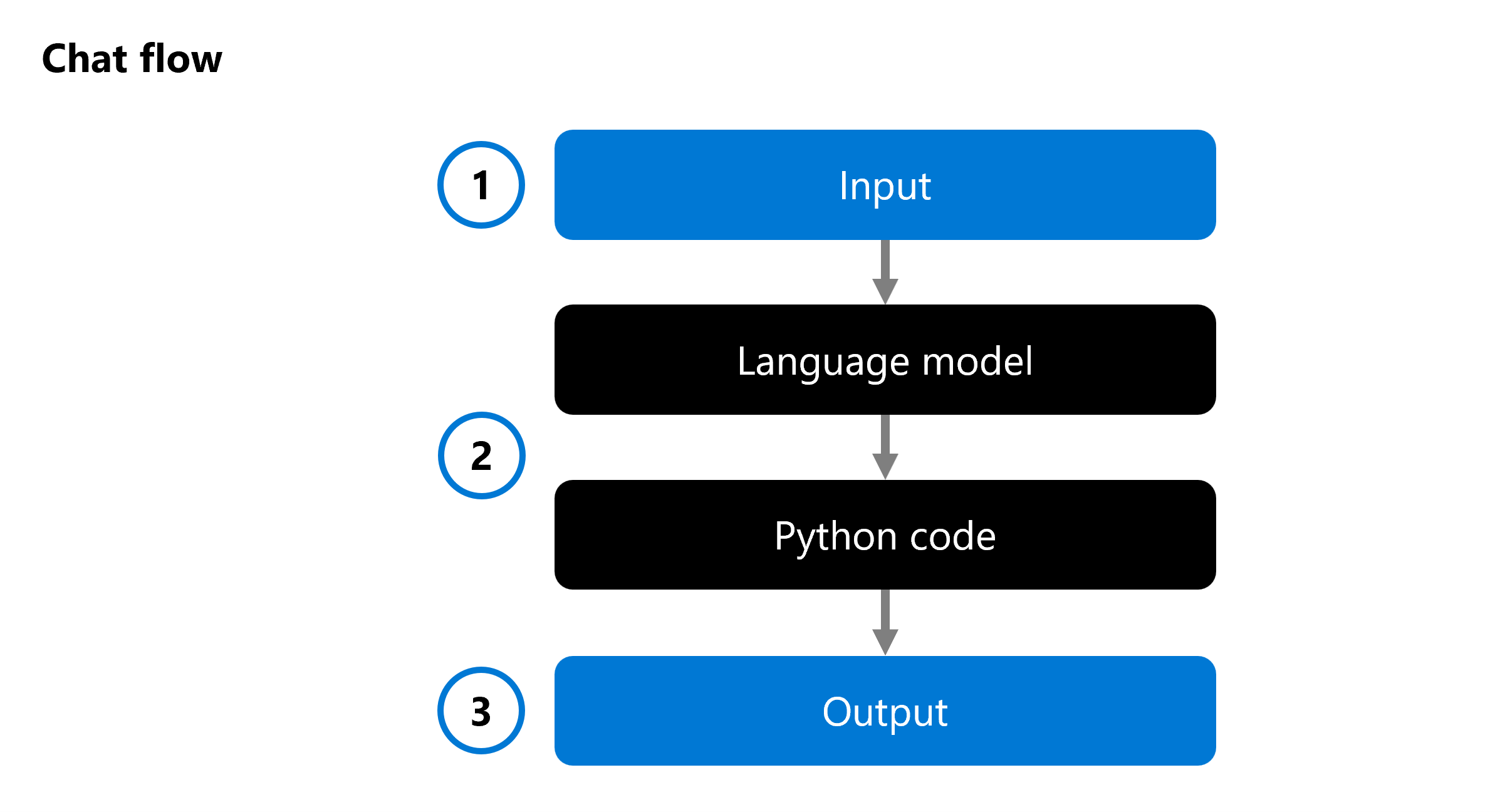
A chat flow allows you to orchestrate executable flows that can combine multiple language models and Python code. The flow expects an input (1), processes it through executing various nodes (2), and generates an output (3). You can evaluate a complete chat flow, and its individual components.
When evaluating your solution, you can start with testing an individual model, and eventually test a complete chat flow to validate whether your generative AI app is working as expected.
Let's explore several approaches to evaluate your model and chat flow, or generative AI app.
Model benchmarks
Model benchmarks are publicly available metrics across models and datasets. These benchmarks help you understand how your model performs relative to others. Some commonly used benchmarks include:
- Accuracy: Compares model generated text with correct answer according to the dataset. Result is one if generated text matches the answer exactly, and zero otherwise.
- Coherence: Measures whether the model output flows smoothly, reads naturally, and resembles human-like language
- Fluency: Assesses how well the generated text adheres to grammatical rules, syntactic structures, and appropriate usage of vocabulary, resulting in linguistically correct and natural-sounding responses.
- GPT similarity: Quantifies the semantic similarity between a ground truth sentence (or document) and the prediction sentence generated by an AI model.
In the Azure AI Foundry portal, you can explore the model benchmarks for all available models, before deploying a model:

Manual evaluations
Manual evaluations involve human raters who assess the quality of the model's responses. This approach provides insights into aspects that automated metrics might miss, such as context relevance and user satisfaction. Human evaluators can rate responses based on criteria like relevance, informativeness, and engagement.
Traditional machine learning metrics
Traditional machine learning metrics are also valuable in evaluating model performance. One such metric is the F1-score, which measures the ratio of the number of shared words between the generated and ground truth answers. The F1-score is useful for tasks like text classification and information retrieval, where precision and recall are important.
AI-assisted metrics
AI-assisted metrics use advanced techniques to evaluate model performance. These metrics can include:
- Risk and safety metrics: These metrics assess the potential risks and safety concerns associated with the model's outputs. They help ensure that the model doesn't generate harmful or biased content.
- Generation quality metrics: These metrics evaluate the overall quality of the generated text, considering factors like creativity, coherence, and adherence to the desired style or tone.