Describe normalization
Database normalization is a design process used to organize a given set of data into tables and columns in a database. Each table should contain data relating to a specific ‘thing’ and only have data that supports that same ‘thing’ included in the table. The goal of this process is to reduce duplicate data contained within your database, to reduce performance degradation of database inserts and updates. For example, a customer address change is much easier to implement if the only place the customer address is stored is in the Customers table. The most common forms of normalization are first, second, and third normal form and are described below.
First normal form
First normal form has the following specifications:
- Create a separate table for each set of related data
- Eliminate repeating groups in individual tables
- Identify each set of related data with a primary key
In this model, you shouldn't use multiple columns in a single table to store similar data. For example, if product can come in multiple colors, you shouldn't have multiple columns in a single row containing the different color values. The first table, below (ProductColors), isn't in first normal form as there are repeating values for color. For products with only one color, there's wasted space. And what if a product came in more than three colors? Rather than having to set a maximum number of colors, we can recreate the table as shown in the second table, ProductColor. We also have a requirement for first normal form that there's a unique key for the table, which is column (or columns) whose value uniquely identifies the row. Neither of the columns in the second table is unique, but together, the combination of ProductID and Color is unique. When multiple columns are needed, we call that a composite key.
| ProductID | Color1 | Color2 | Color3 |
|---|---|---|---|
| 1 | Red | Green | Yellow |
| 2 | Yellow | ||
| 3 | Blue | Red | |
| 4 | Blue | ||
| 5 | Red |
| ProductID | Color |
|---|---|
| 1 | Red |
| 1 | Green |
| 1 | Yellow |
| 2 | Yellow |
| 3 | Blue |
| 3 | Red |
| 4 | Blue |
| 5 | Red |
The third table, ProductInfo, is in first normal form because each row refers to a particular product, there are no repeating groups, and we have the column ProductID to use as a Primary Key.
| ProductID | ProductName | Price | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15.95 | United States | US |
| 2 | Foop | 41.95 | United Kingdom | UK |
| 3 | Glombit | 49.95 | United Kingdom | UK |
| 4 | Sorfin | 99.99 | Republic of the Philippines | RepPhil |
| 5 | Stem Bolt | 29.95 | United States | US |
Second normal form
Second normal form has the following specification, in addition to those required by first normal form:
- If the table has a composite key, all attributes must depend on the complete key and not just part of it.
Second normal form is only relevant to tables with composite keys, like in the table ProductColor, which is the second table above. Consider the case where the ProductColor table also includes the product’s price. This table has a composite key on ProductID and Color, because only using both column values can we uniquely identify a row. If a product’s price doesn't change with the color, we might see data as shown in this table:
| ProductID | Color | Price |
|---|---|---|
| 1 | Red | 15.95 |
| 1 | Green | 15.95 |
| 1 | Yellow | 15.95 |
| 2 | Yellow | 41.95 |
| 3 | Blue | 49.95 |
| 3 | Red | 49.95 |
| 4 | Blue | 99.95 |
| 5 | Red | 29.95 |
The table above is not in second normal form. The price value is dependent on the ProductID but not on the Color. There are three rows for ProductID 1, so the price for that product is repeated three times. The problem with violating second normal form is that if we have to update the price, we have to make sure we update it everywhere. If we update the price in the first row, but not the second or third, we would have something called an ‘update anomaly’. After the update, we wouldn’t be able to tell what the actual price for ProductID 1 was. The solution is to move the Price column to a table that has ProductID as a single column key, because that is the only column that Price depends on. For example, we could use Table 3 to store the Price.
If the price for a product was different based on its color, the fourth table would be in the second normal form, since the price would depend on both parts of the key: the ProductID and the Color.
Third normal form
Third normal form is typically the aim for most OLTP databases. Third normal form has the following specification, in addition to those required by second normal form:
- All nonkey columns are non-transitively dependent on the primary key.
The transitive relationship implies that one column in a table is related to other columns, through a second column. Dependency means that a column can derive its value from another, as a result of a dependency. For example, your age can be determined from your date of birth, making your age dependent on your date of birth. Refer back to the third table, ProductInfo. This table is in second normal form, but not in third. The ShortLocation column is dependent on the ProductionCountry column, which isn't the key. Like second normal form, violating third normal form can lead to update anomalies. We would end up with inconsistent data if we updated the ShortLocation in one row but didn't update it in all the rows where that location occurred. To prevent this, we could create a separate table to store country/region names and their shortened forms.
Denormalization
While the third normal form is theoretically desirable, it isn't always possible for all data. In addition, a normalized database doesn't always give you the best performance. Normalized data frequently requires multiple join operations to get all the necessary data returned in a single query. There's a tradeoff between normalizing data when the number of joins required to return query results has high CPU utilization, and denormalized data that has fewer joins and less CPU required, but opens up the possibility of update anomalies.
Note
Denormalized data is not the same as unnormalized. For denormalization, we start by designing tables that are normalized. Then we can add additional columns to some tables to reduce the number of joins required, but as we do so, we are aware of the possible update anomalies. We then make sure we have triggers or other kinds of processing that will make sure that when we perform an update, all the duplicate data is also updated.
Denormalized data can be more efficient to query, especially for read heavy workloads like a data warehouse. In those cases, having extra columns may offer better query patterns and/or more simplistic queries.
Star schema
While most normalization is aimed at OLTP workloads, data warehouses have their own modeling structure, which is usually a denormalized model. This design uses fact tables, which record measurements or metrics for specific events like a sale, and joins them to dimension tables, which are smaller in terms of row count, but may have a large number of columns to describe the fact data. Some example dimensions would include inventory, time, and/or geography. This design pattern is used to make the database easier to query and offer performance gains for read workloads.
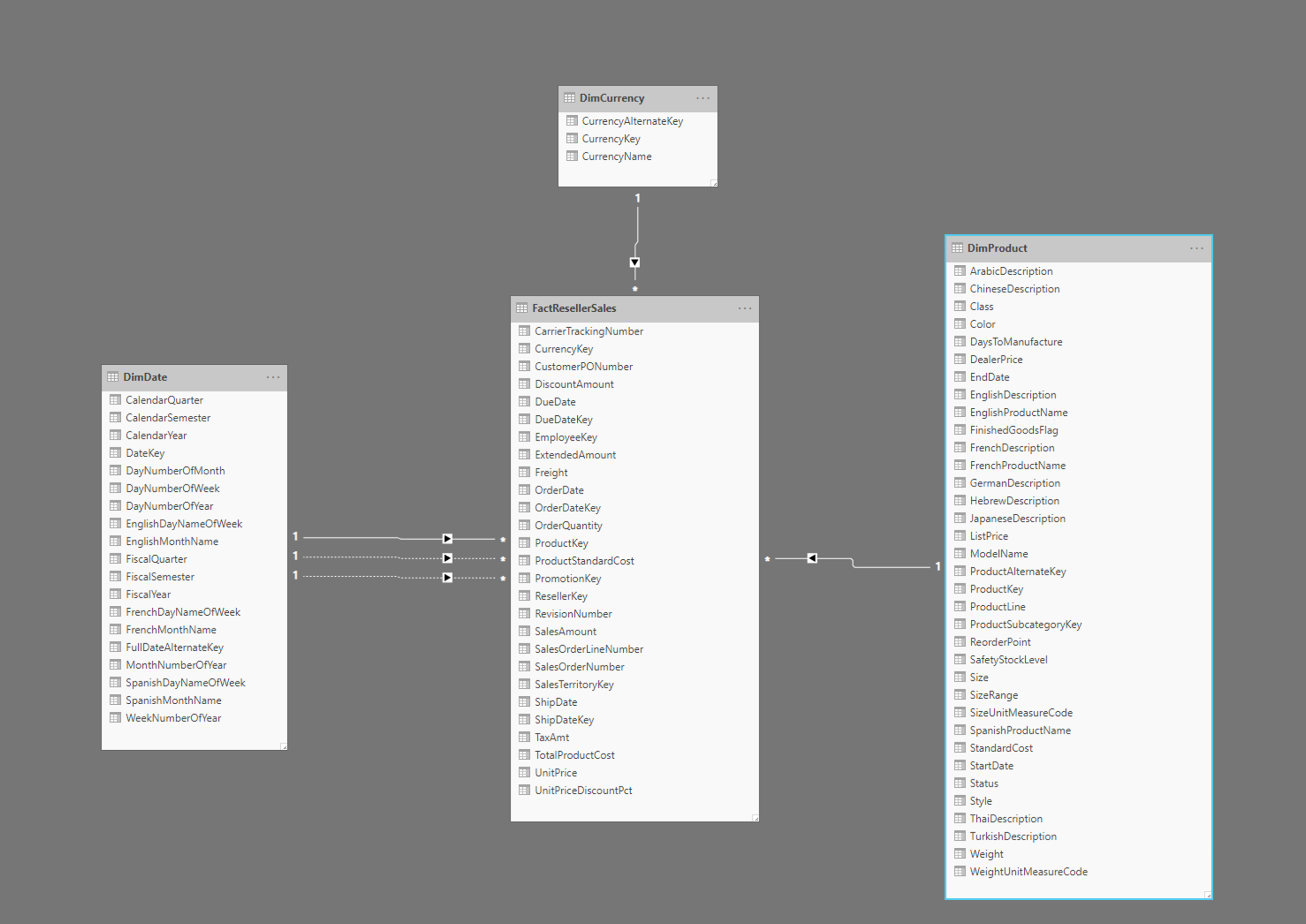
The above image shows an example of a star schema, including a FactResellerSales fact table, and dimensions for date, currency, and products. The fact table contains data related to the sales transactions, and the dimensions only contain data related to a specific element of the sales data. For example, the FactResellerSales table contains only a ProductKey to indicate which product was sold. All of the details about each product are stored in the DimProduct table, and related back to the fact table with the ProductKey column.
Related to star schema design is a snowflake schema, which uses a set of more normalized tables for a single business entity. The following image shows an example of a single dimension for a snowflake schema. The Products dimension is normalized and stored in three tables called DimProductCategory, DimProductSubcategory, and DimProduct.
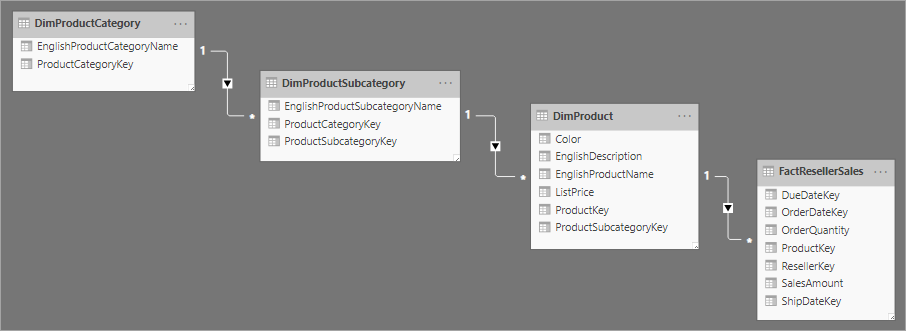
The main difference between star and snowflake schemas is that the dimensions in a snowflake schema are normalized to reduce redundancy, which saves storage space. The tradeoff is that your queries require more joins, which can increase your complexity and decrease performance.