Select the right MPI library
HB120_v2, HB60, and HC44 SKUs support InfiniBand network interconnects. Because the PCI express is virtualized via single-root input/output (SR-IOV) virtualization, all popular MPI libraries (HPCX, OpenMPI, Intel MPI, MVAPICH, and MPICH) are available on these HPC VMs.
The current limitation for an HPC cluster that can communicate over InfiniBand is 300 VMs. The following table lists the maximum number of parallel processes that are supported in tightly coupled MPI applications that are communicating over InfiniBand.
| SKU | Maximum parallel processes |
|---|---|
| HB120_v2 | 36,000 processes |
| HC44 | 13,200 processes |
| HB60 | 18,000 processes |
Note
These limits might change in the future. If you have a tightly coupled MPI job that requires a higher limit, submit a support request. It might be possible to raise the limits for your situation.
If an HPC application recommends a particular MPI library, try that version first. If you have flexibility regarding which MPI you can choose and you want the best performance, try HPCX. Overall, the HPCX MPI performs the best by using the UCX framework for the InfiniBand interface, and takes advantage of all the Mellanox InfiniBand hardware and software capabilities.
The following illustration compares the popular MPI library architectures.
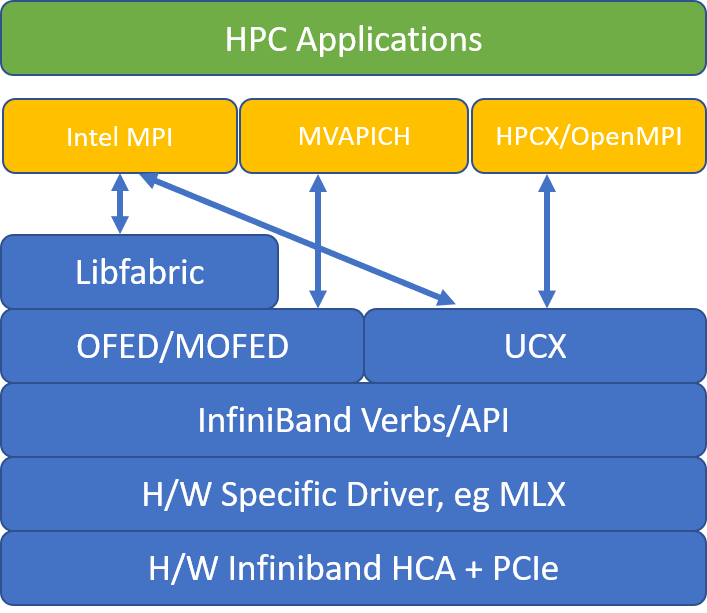
HPCX and OpenMPI are ABI compatible, so you can dynamically run an HPC application with HPCX that was built with OpenMPI. Similarly, Intel MPI, MVAPICH, and MPICH are ABI compatible.
The queue pair 0 isn't accessible to the guest VM, in order to prevent any security vulnerability via low-level hardware access. This shouldn't have any effect on end-user HPC applications, but it might prevent some low-level tools from functioning correctly.
HPCX and OpenMPI mpirun arguments
The following command illustrates some recommended mpirun arguments for HPCX and OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
In that command:
| Parameter | Description |
|---|---|
$NPROCS |
Specifies the number of MPI processes. For example: -n 16. |
$HOSTFILE |
Specifies a file containing the hostname or IP address, to indicate the location of where the MPI processes run. For example: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Specifies the number of MPI processes that run in each NUMA domain. For example, to specify four MPI processes per NUMA, you use --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Specifies the number of threads per MPI process. For example, to specify one MPI process and four threads per NUMA, you use --map-by ppr:1:numa:pe=4. |
-report-bindings |
Prints MPI processes mapping to cores, which is useful to verify that your MPI process pinning is correct. |
$MPI_EXECUTABLE |
Specifies the MPI executable built linking in MPI libraries. MPI compiler wrappers do this automatically. For example: mpicc or mpif90. |
If you suspect your tightly coupled MPI application is doing an excessive amount of collective communication, you can try enabling hierarchical collectives (HCOLL). To enable those features, use the following parameters:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Intel MPI mpirun arguments
The Intel MPI 2019 release switched from the Open Fabrics Alliance (OFA) framework to the Open Fabrics Interfaces (OFI) framework, and currently supports libfabric. There are two providers for InfiniBand support: mlx and verbs. The provider mlx is the preferred provider on HB and HC VMs.
Here are some suggested mpirun arguments for Intel MPI 2019 update 5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
In those arguments:
| Parameters | Description |
|---|---|
FI_PROVIDER |
Specifies which libfabric provider to use, which affects the API, protocol, and network used. verbs is another option, but generally mlx gives you better performance. |
I_MPI_DEBUG |
Specifies the level of extra debug output, which can provide details about where processes are pinned, and which protocol and network are used. |
I_MPI_PIN_DOMAIN |
Specifies how you want to pin your processes. For example, you can pin to cores, sockets, or NUMA domains. In this example, you set this environmental variable to numa, which means processes are pinned to NUMA node domains. |
There are some other options that you can try, especially if collective operations are consuming a significant amount of time. Intel MPI 2019 update 5+ supports the provide mlx and uses the UCX framework to communicate with InfiniBand. It also supports HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
MVAPICH mpirun arguments
The following list contains several recommended mpirun arguments:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
In those arguments:
| Parameters | Description |
|---|---|
MV2_CPU_BINDING_POLICY |
Specifies which binding policy to use, which will affect how processes are pinned to core IDs. In this case, you specify scatter, so processes are evenly scattered among the NUMA domains. |
MV2_CPU_BINDING_LEVEL |
Specifies where to pin processes. In this case, you set it to numanode, which means processes are pinned to units of NUMA domains. |
MV2_SHOW_CPU_BINDING |
Specifies if you want to get debug information about where the processes are pinned. |
MV2_SHOW_HCA_BINDING |
Specifies if you want to get debug information about which host channel adapter each process is using. |