Use data entities for data management and integration
Data entities provide conceptual abstraction and encapsulation (de-normalized view) of underlying table schema that represent data concepts and functionalities.
After data entities are created, you should be able to reuse them for Excel add-ins, import and export, or integration scenarios. A data entity is an abstraction from the physical implementation of database tables.
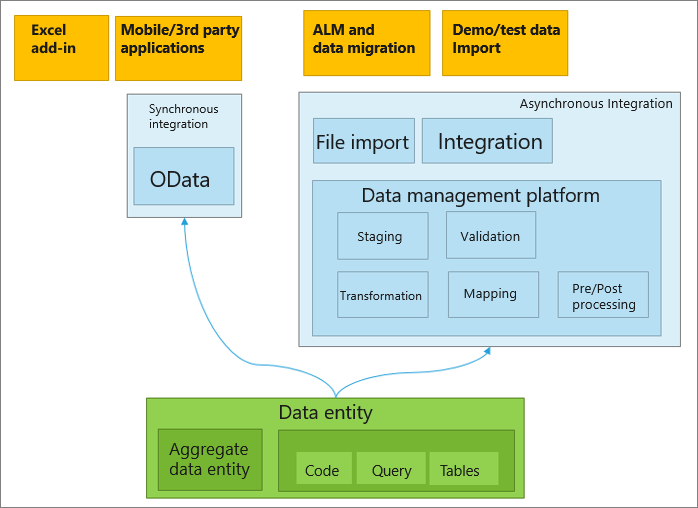
This image presents data entity integration scenarios.
For example, in normalized tables, a lot of the data for each customer might be stored in a customer table, and then the rest might be spread across a small set of related tables. In this case, the data entity for the customer concept appears as one de-normalized view, in which each row contains all the data from the customer table and its related tables.
A data entity encapsulates a business concept into a format that makes development and integration easier. The abstracted nature of a data entity can simplify application development and customization. Later, the abstraction also insulates application code from the inevitable churn of the physical tables between versions.
A data entity has the following capabilities:
- It provides a single stack to capture business logic, enable scenarios such as import and export, and integration, and support additional logics by a developer adding code.
- It becomes the primary mechanism for exporting and importing data packages for Application Lifecycle Management (ALM) and demo data scenarios.
- It can be exposed as OData services, and then used in tabular-style synchronous integration scenarios and Microsoft Office integrations.
Entity example
A consumer wants to access data that is related to a customer object, but this data is currently scattered across multiple normalized tables, such as DirParty, CustTable, LogisticsPostalAddress, and LogisticsElectronicAddress.
Therefore, the process of reading and writing customer data is tedious. Instead, the following customer entity can be designed to encapsulate the entire underlying physical schema into a single de-normalized view. This enables simpler read and write operations, and enables abstraction of any internal interaction between the tables.
Categories of entities
Entities are categorized based on their functions and the type of data that they serve. The following are five categories for data entities:
- Parameters
- Reference
- Master
- Document
- Transactions
Parameters
- Functional or behavioral parameters.
- Required to set up a deployment or a module for a specific build or customer.
- Can include data that is specific to an industry or business. The data can also apply to a broader set of customers.
- Tables that contain only one record, where the columns are values for settings. Examples of such tables exist for Accounts payable (AP), General ledger (GL), client performance options, workflows, and so on.
Reference
- Simple reference data, of small quantity, that is required to operate a business process.
- Data that is specific to an industry or a business process.
- Examples include units, dimensions, and tax codes.
Master
- Data assets of the business. Generally, these are the "nouns" of the business, which typically fall into categories such as people, places, and concepts.
- Complex reference data, of large quantity. Examples include customers, vendors, and projects.
Document
- Worksheet data that is converted into transactions later.
- Documents that have complex structures, such as several line items for each header record. Examples include sales orders, purchase orders, open balances, and journals.
- The operational data of the business.
Transactions
- The operational transaction data of the business.
- Posted transactions. These are non-idempotent items such as posted invoices and balances. Typically, these items are excluded during a full dataset copy.
- Examples include pending invoices.
Configuration keys and data entities
Before you use data entities to import or export data, we recommended that you first determine the impact of configuration keys on the data entities that you are planning to use.
To learn more about configuration keys in finance and operations apps, refer to the License codes and configuration keys report.
Configuration key assignments
Configuration keys can be assigned to one or all of the following artifacts.
- Data entities
- Tables used as data sources
- Table fields
- Data entity fields
Supported integrations
Data management by using data entities can support the following integrations:
- Synchronous service (OData) – Data entities enable public application programming interfaces (APIs) on entities to be exposed, which enables synchronous services. This method is used for Office integration and third-party mobile app integrations
- Asynchronous integration – Data entities also support asynchronous integration through a data management pipeline. This enables asynchronous and high-performing data insertion and extraction scenarios. This method is used for interactive file-based import/export and recurring integrations.
- Business intelligence – By using the aggregate measures available in finance and operations apps, built-in controls such as charts and integration with Microsoft Power Platform, provides reports to offer insights to business data.
Data migration from legacy or external systems
After the initial deployment is up and running, the system implementer will migrate existing data assets of the customer into finance and operations apps, such as:
- Master data (for example, customers and vendors)
- Subsets of documents (for example, sales orders)
You can use the data management framework to copy configurations between companies or environments, and configure processes or modules by using Lifecycle Services.
Copying configurations is intended to make it easier to start a new implementation, even if your team doesn't deeply understand the structure of data that needs to be entered, data dependencies, or which sequence to add data to an implementation.
The data management framework allows you to:
Move data between two similar systems.
- Discover entities and dependencies between entities for a given business process or module.
- Maintain a reusable library of data templates and datasets.
- Use data packages to create incremental data entities. Data entities can be sequenced inside the packages. You can name data packages, which can be easily identifiable during import or export. When building data packages, data entities can be mapped to staging tables in grids or by using a visual mapping tool. You can also drag-and-drop columns manually.
- View data during imports, so you can compare data and ensure that it is valid.