¿Qué es la observabilidad de red de Azure Kubernetes Service (AKS)?
Kubernetes es una herramienta eficaz para administrar aplicaciones contenedorizadas. A medida que los entornos contenedorizados crecen en complejidad, puede ser difícil identificar y solucionar problemas de red en un clúster de Kubernetes.
La observabilidad de red es una parte importante del mantenimiento de un clúster de Kubernetes correcto y eficaz. Al recopilar y analizar datos sobre el tráfico de red, puede obtener información sobre cómo funciona el clúster e identificar posibles problemas antes de que causen interrupciones o degradación del rendimiento.
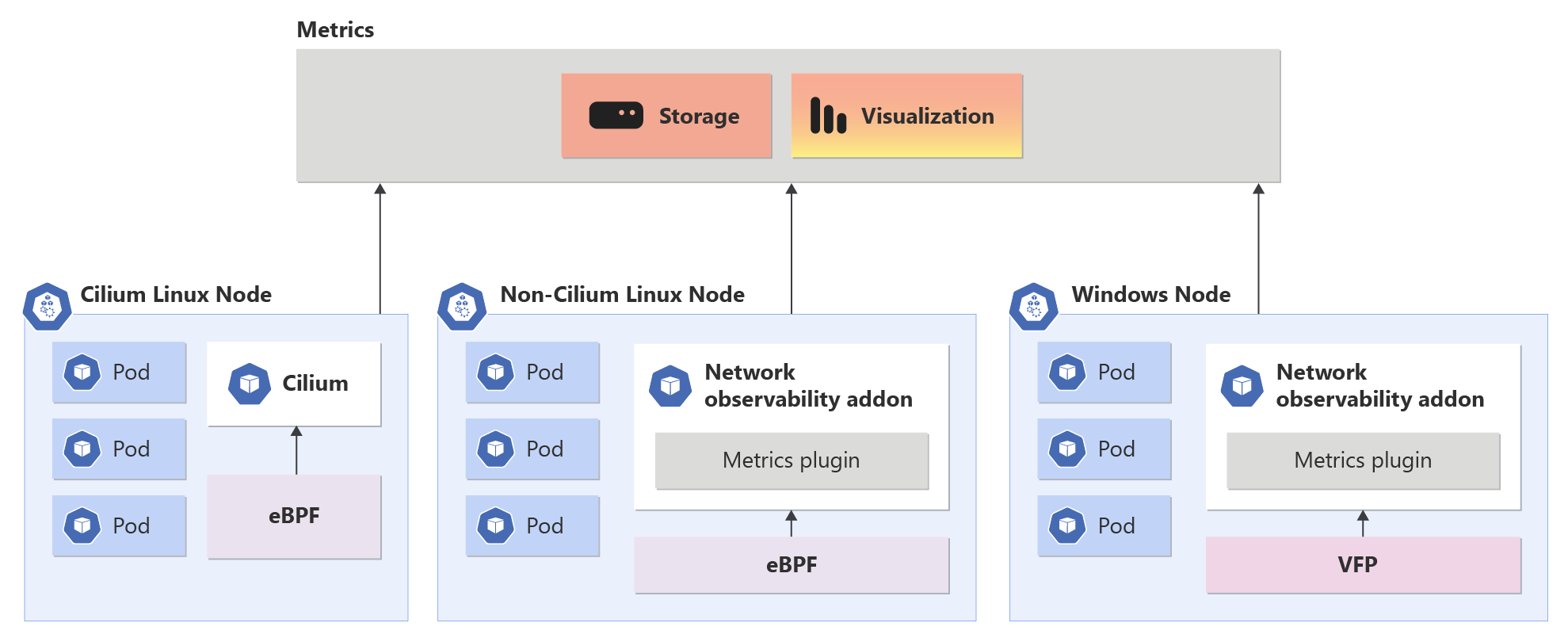
Información general sobre el complemento de observabilidad de red en AKS
El complemento de observabilidad de red funciona sin problemas en planos de datos que no son Cilium y Cilium. Proporciona a los clientes funciones de nivel empresarial para DevOps y SecOps. Esta solución ofrece una manera centralizada de supervisar los problemas de red en el clúster para los administradores de red del clúster, los administradores de seguridad del clúster y los ingenieros de DevOps.
Cuando el complemento Observabilidad de red está habilitado, permite la recopilación y conversión de métricas útiles en formato Prometheus, que luego se puede visualizar en Grafana. Azure dispone de ofertas administradas para Prometheus y Grafana.
Prometheus y Grafana administrados por Azure: un servicio administrado proporcionado por Azure, que se encarga de la infraestructura y el mantenimiento de Prometheus y Grafana, lo que le permite centrarse en la configuración y visualización de las métricas.
Compatibilidad con varios CNI: el complemento de observabilidad de red admite complementos de red de Azure CNI y Kubenet.
Métricas
Actualmente, el complemento Observabilidad de red solo admite métricas de nivel de nodo. Los planos de datos Cilium y no Cilium tienen diferentes métricas, pero el panel de Grafana funciona sin problemas para ambos.
Todas las métricas tienen las etiquetas siguientes:
clusterinstance(nombre del nodo)
En el plan de datos no Cilium, el complemento Observabilidad de red proporciona métricas en plataformas Linux y Windows. En la tabla siguiente, se describen las distintas métricas generadas.
| Nombre de la métrica | Descripción | Etiquetas adicionales | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Recuento total de paquetes reenviados | direction |
✅ | ✅ |
| networkobservability_forward_bytes | Recuento total de bytes reenviados | direction |
✅ | ✅ |
| networkobservability_drop_count | Recuento total de paquetes descartados | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | Recuento total de bytes descartados | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | Recuento de sockets activos de TCP por estado TCP. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | Recuento de sockets activos de TCP por IP/puerto remotos. | address (IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | Estadísticas de conexión TCP. (por ejemplo: ACK retrasados, TCPKeepAlive, TCPSackFailures) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | Recuento de paquetes TCP por marca. | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | Estadísticas de conexión IP. | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | Estadísticas de conexión UDP. | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | Recuento de sockets activos de UDP | ✅ | ❌ | |
| networkobservability_interface_stats | Estadísticas de interfaz. | InterfaceName, statistic |
✅ | ✅ |
Limitaciones
- No se admiten las métricas de nivel de pod.
Escala
Se aplican ciertas limitaciones de escala cuando se utilizan Prometheus y Grafana administrados por Azure. Para más información, consulte Extracción de métricas de Prometheus a escala en Azure Monitor
Pasos siguientes
Para obtener más información sobre Azure Kubernetes Service (AKS), consulte ¿Qué es Azure Kubernetes Service (AKS)?.
Para crear un clúster de AKS con observabilidad de red y Prometheus y Grafana administrados por Azure, consulte Configuración de observabilidad de red para Azure Kubernetes Service (AKS): Azure Managed Prometheus y Grafana.

Azure Kubernetes Service