En este artículo se describe el uso de métricas para encontrar cuellos de botella y mejorar el rendimiento de un sistema distribuido por parte de un equipo de desarrollo. El artículo se basa en la prueba de carga real que se realizó para una aplicación de ejemplo. La aplicación es de la base de referencia de Azure Kubernetes Service (AKS) para los microservicios.
Este artículo forma parte de una serie. Puede consultar la primera parte aquí.
Escenario: Una aplicación cliente inicia una transacción empresarial que implica varios pasos.
Este escenario implica una aplicación de entrega con drones que se ejecuta en AKS. Los clientes usan una aplicación web para programar las entregas por dron. Cada transacción requiere varios pasos que realizan microservicios independientes en el back-end:
- El servicio Delivery administra las entregas.
- El servicio Dron Scheduler programa drones para la recogida.
- El servicio Package administra los paquetes.
Hay otros dos servicios: El servicio Ingestion, que acepta las solicitudes de los clientes y las coloca en una cola para su procesamiento, y un servicio Workflow, que coordina los pasos del flujo de trabajo.
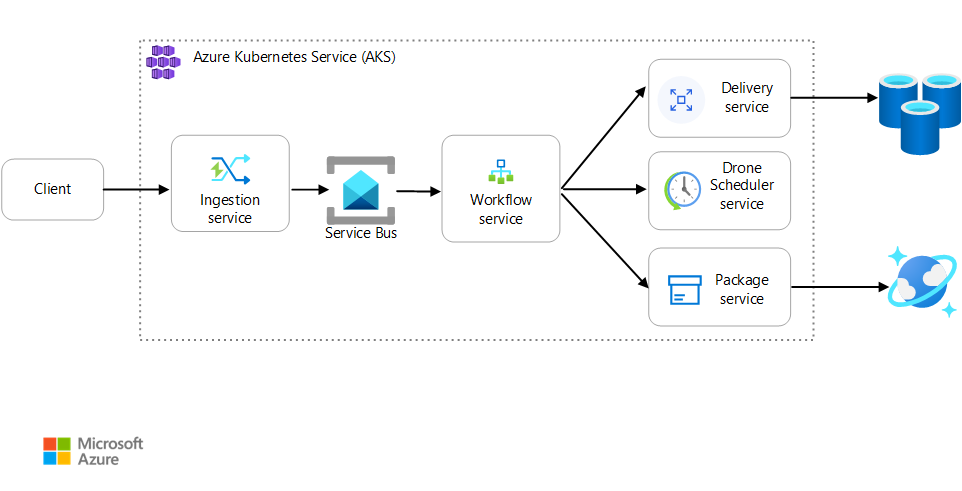
Para más información sobre este escenario, consulte Diseño de una arquitectura de microservicios.
Prueba 1: Línea base
En la primera prueba de carga, el equipo creó un clúster AKS de seis nodos e implementó tres réplicas de cada microservicio. La prueba de carga fue una prueba de carga por pasos, se empezó por dos usuarios simulados y se fue incrementando hasta 40 usuarios simulados.
| Configuración | Value |
|---|---|
| Nodos de clúster | 6 |
| Pods | 3 por servicio |
En el siguiente gráfico se muestran los resultados de la prueba de carga, tal como aparecen en Visual Studio. La línea púrpura traza la carga de usuarios y la línea naranja traza el total de solicitudes.
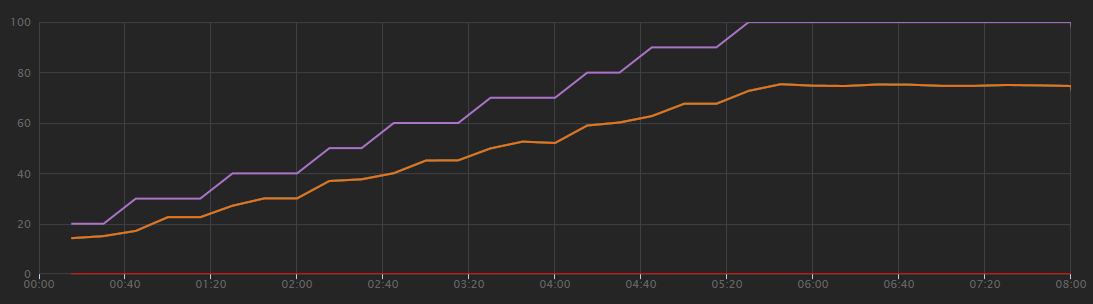
Lo primero que hay que saber sobre este escenario es que las solicitudes de clientes por segundo no son una métrica útil de rendimiento. Esto se debe a que la aplicación procesa las solicitudes de forma asincrónica, por lo que el cliente recibe una respuesta inmediatamente. El código de respuesta es siempre HTTP 202 (Aceptado), lo que significa que se aceptó la solicitud, pero el procesamiento no se ha completado.
Lo que realmente queremos saber es si el back-end mantiene el ritmo de la velocidad de solicitudes. La cola de Service Bus puede absorber picos, pero si el back-end no puede controlar una carga sostenida, el procesamiento se retrasará cada vez más.
Este es un gráfico más informativo. Traza el número de mensajes entrantes y salientes en la cola de Service Bus. Los mensajes entrantes se muestran en azul claro y los mensajes salientes se muestran en azul oscuro:

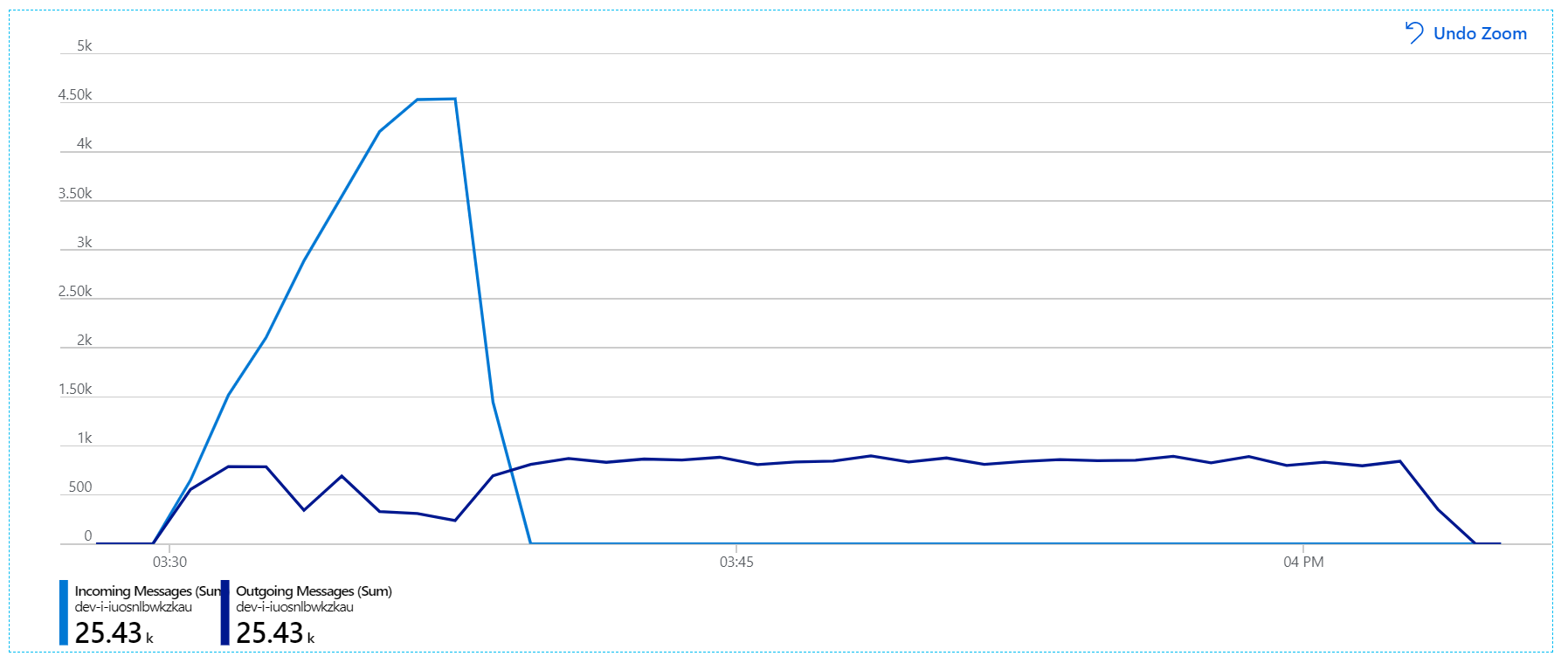
En este gráfico se muestra que la velocidad de los mensajes entrantes aumenta, alcanzando un pico y, a continuación, vuelve a bajar a cero al final de la prueba de carga. Pero el número de mensajes salientes tiene un pico en la fase inicial de la prueba y, a continuación, cae sorprendentemente. Esto significa que el servicio Workflow, que controla las solicitudes, no sigue el ritmo. Incluso después de que finalice la prueba de carga (a alrededor de las 9:22 en el gráfico), los mensajes se siguen procesando, ya que el servicio Workflow continúa drenando la cola.
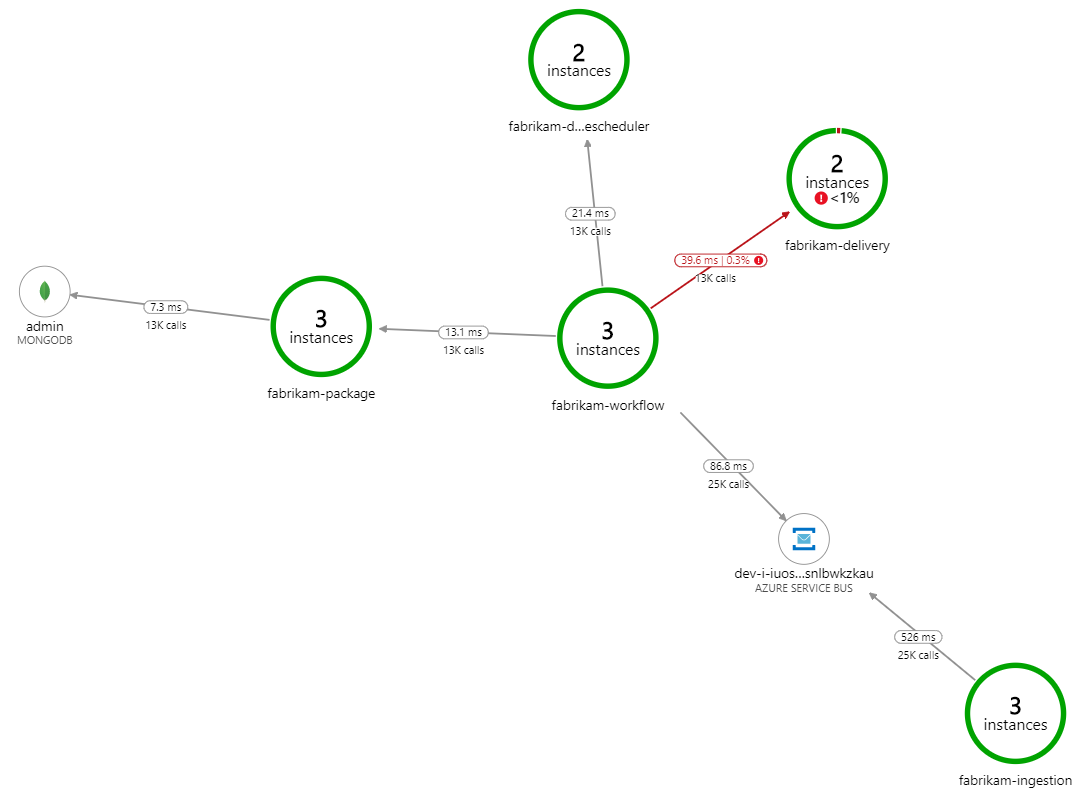
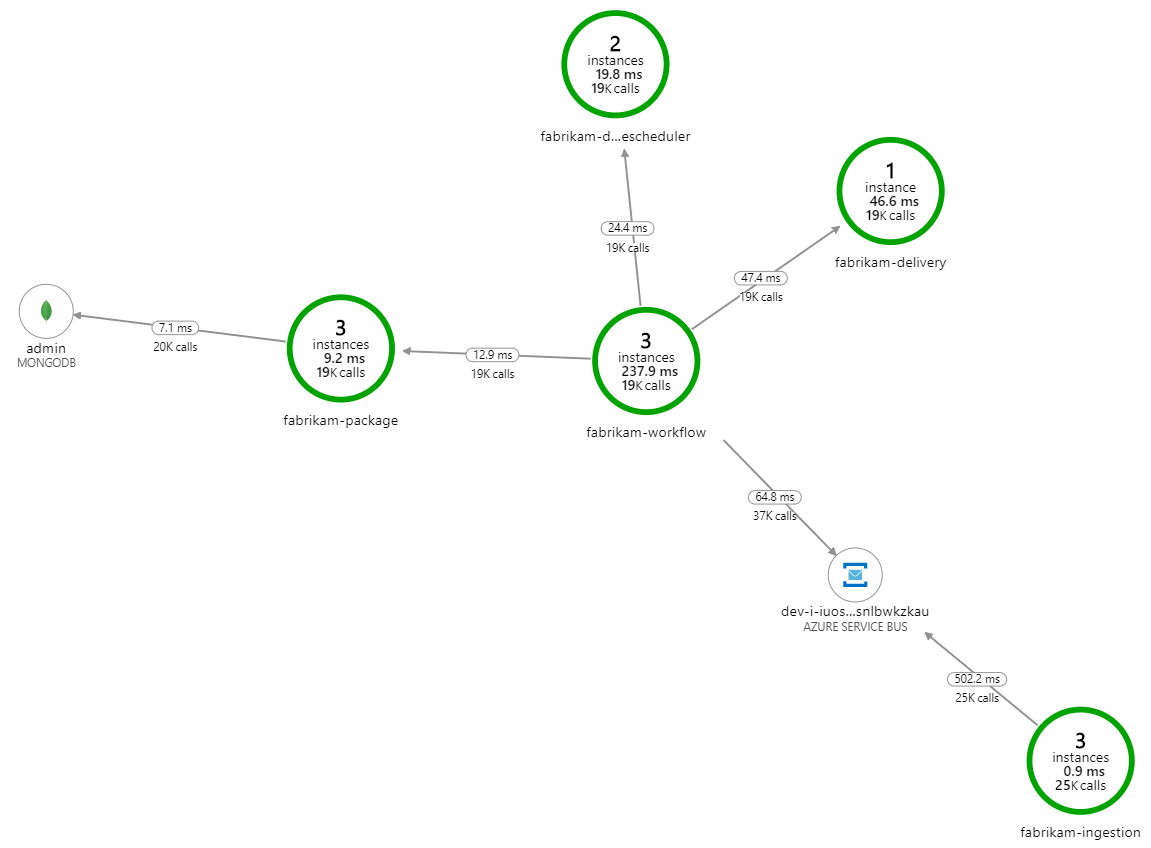
¿Qué ralentiza el procesamiento? Lo primero que hay que buscar son errores o excepciones que podrían indicar un problema sistemático. El Mapa de aplicación de Azure Monitor muestra el gráfico de llamadas entre componentes, que es una forma rápida de detectar problemas y donde se puede hacer clic para obtener más detalles.
Asegúrese de que el mapa de aplicación muestra que el servicio Workflow recibe errores del servicio de entrega:
Para ver más detalles, puede seleccionar un nodo en el gráfico y hacer clic en una vista de transacciones de un extremo a otro. En este caso, se muestra que el servicio de entrega devuelve errores HTTP 500. Los mensajes de error indican que se está produciendo una excepción debido a límites de memoria de Azure Cache for Redis.
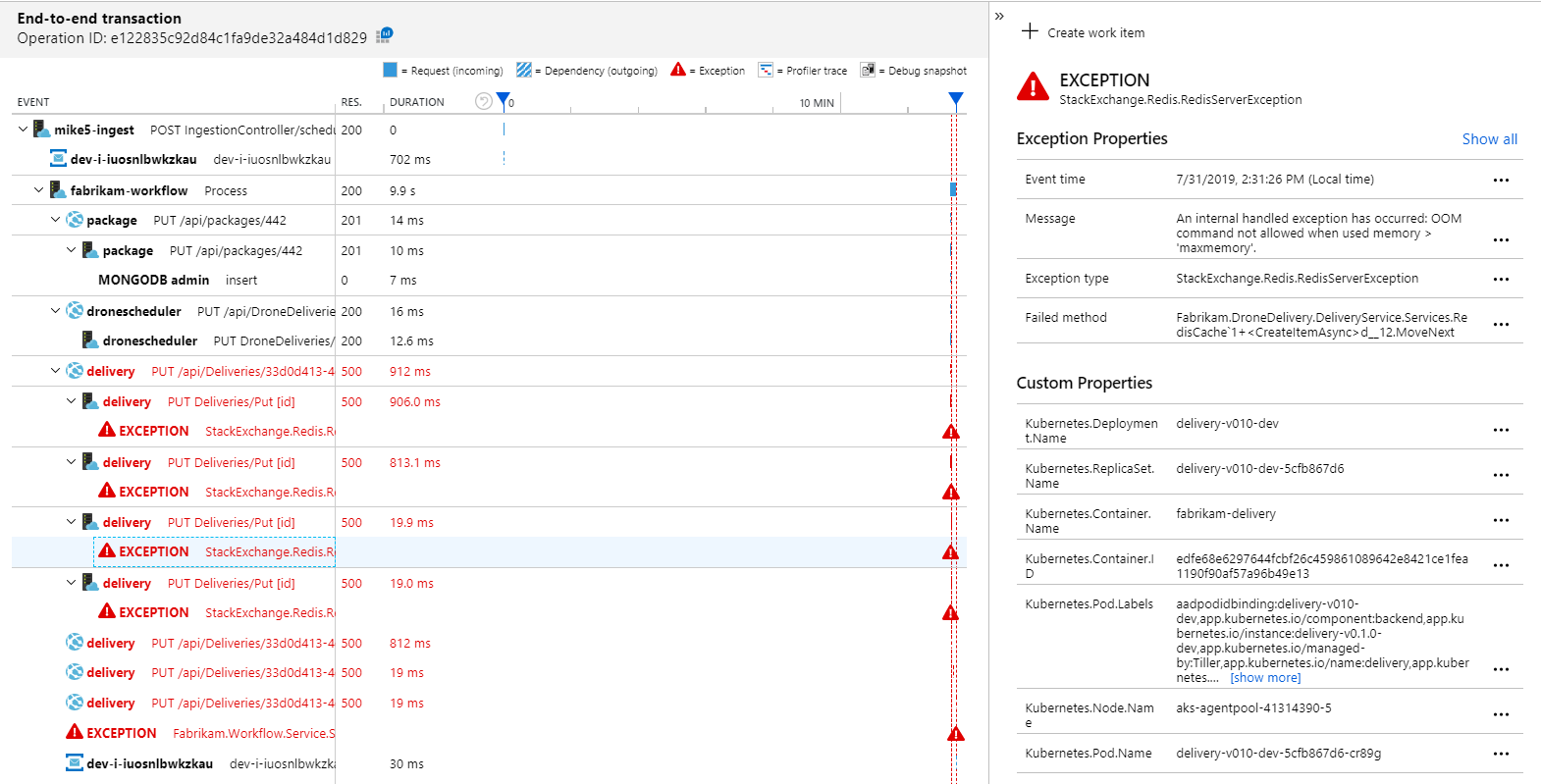
Puede observar que estas llamadas a Redis no aparecen en el mapa de aplicación. Esto se debe a que la biblioteca de .NET para Application Insights no tiene compatibilidad integrada para realizar el seguimiento de Redis como una dependencia. (Para obtener una lista de lo que es compatible y listo para usar, vea Recopilación automática de dependencias). Como alternativa, puede usar la API TrackDependency para realizar el seguimiento de cualquier dependencia. Las pruebas de carga suelen revelar estos tipos de brechas en la telemetría, que se pueden corregir.
Prueba 2: Mayor tamaño de caché
Para la segunda prueba de carga, el equipo de desarrollo aumentó el tamaño de la caché en Azure Cache for Redis. (Consulte Escalado de Azure Cache for Redis). Este cambio resolvió las excepciones de memoria insuficiente y ahora el mapa de aplicación muestra cero errores:
Sin embargo, sigue habiendo un retraso drástico en el procesamiento de mensajes. En el pico de la prueba de carga, la velocidad de los mensajes entrantes es 5 veces superior a la velocidad de salida:
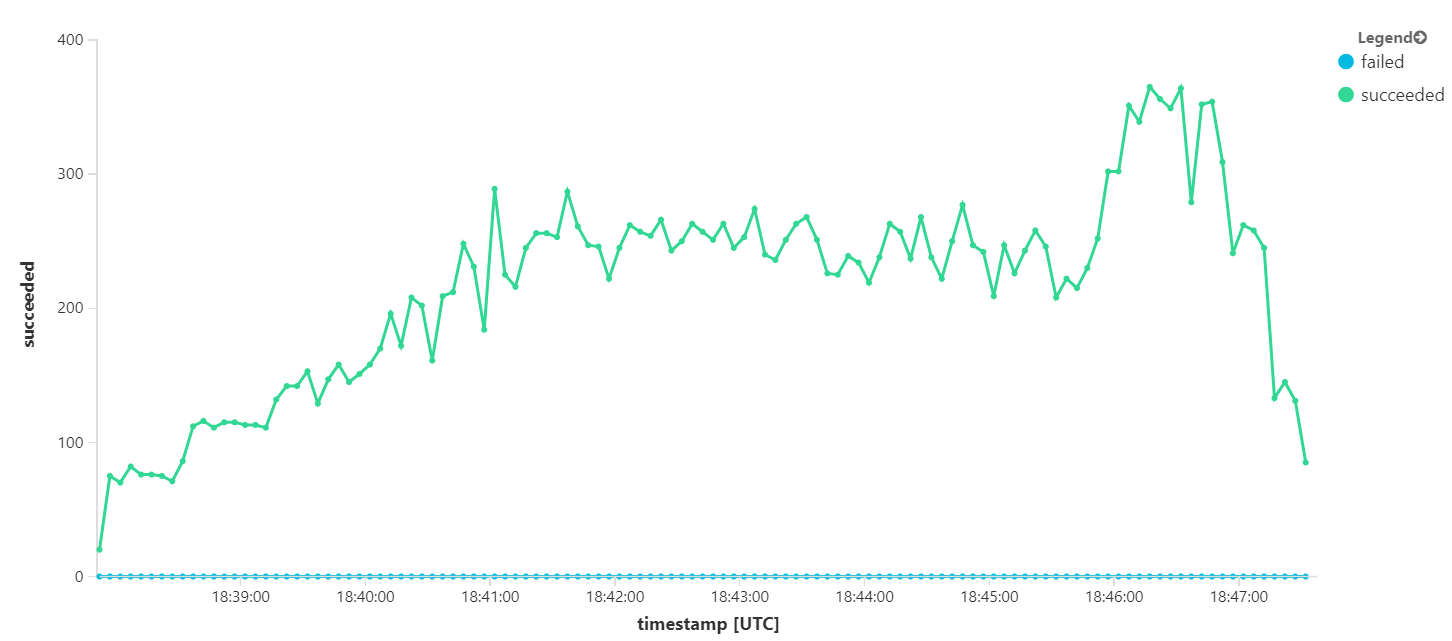
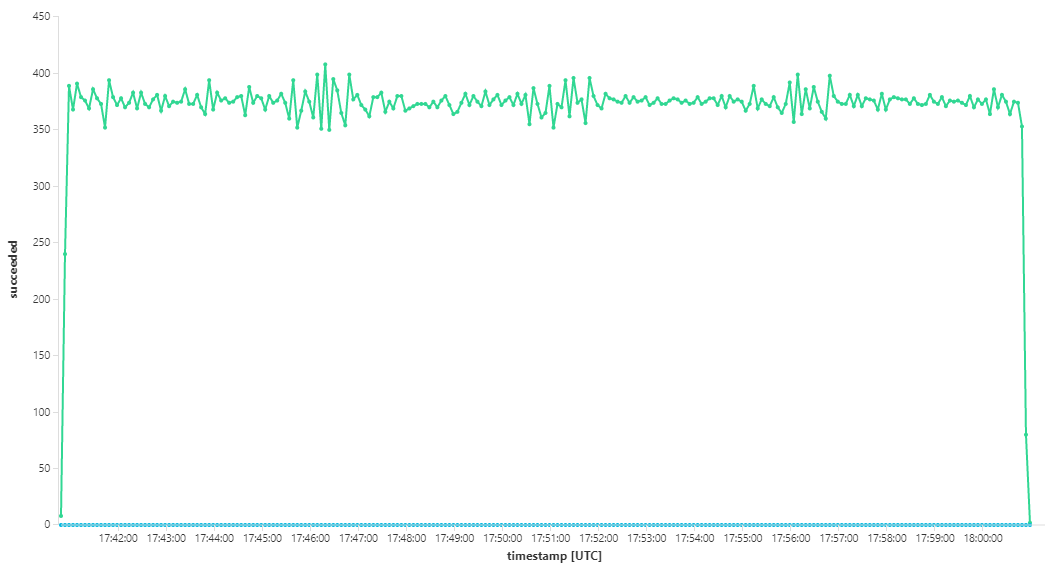
En el siguiente gráfico se mide el rendimiento en términos de finalización de mensajes; es decir, la velocidad a la que el servicio Workflow marca los mensajes de Service Bus como completados. Cada punto del gráfico representa 5 segundos de datos, que muestra el rendimiento máximo de ~16/s.
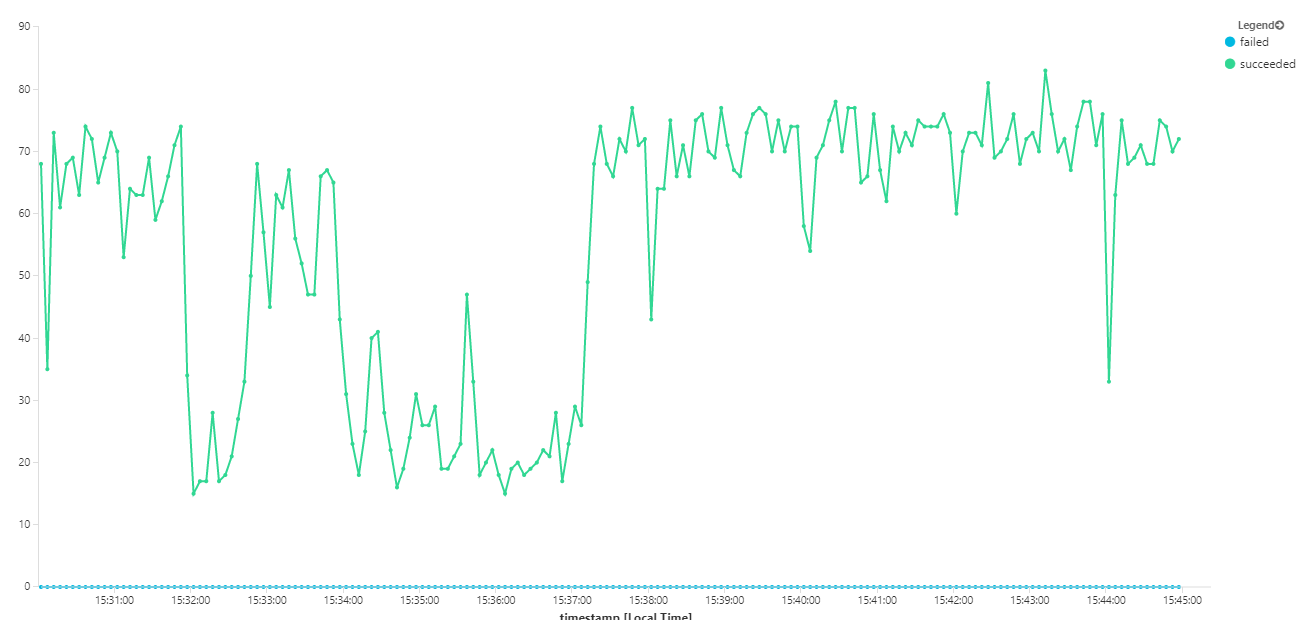
Este gráfico se generó mediante la ejecución de una consulta en el área de trabajo de Log Analytics, con el lenguaje de consulta Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Prueba 3: Escalado horizontal de los servicios del back-end
Parece que el back-end es el cuello de botella. Un paso sencillo es escalar horizontalmente los servicios empresariales (Package, Delivery, and Drone Scheduler) y ver si mejora el rendimiento. Para la siguiente prueba de carga, el equipo escaló estos servicios de tres réplicas a seis réplicas.
| Configuración | Value |
|---|---|
| Nodos de clúster | 6 |
| Servicio Ingestion | 3 réplicas |
| Servicio Workflow | 3 réplicas |
| Servicios Package, Delivery y Drone Scheduler | 6 réplicas cada uno |
Desafortunadamente, esta prueba de carga solo muestra una modesta mejora. Los mensajes salientes siguen sin seguir el ritmo de los mensajes entrantes:
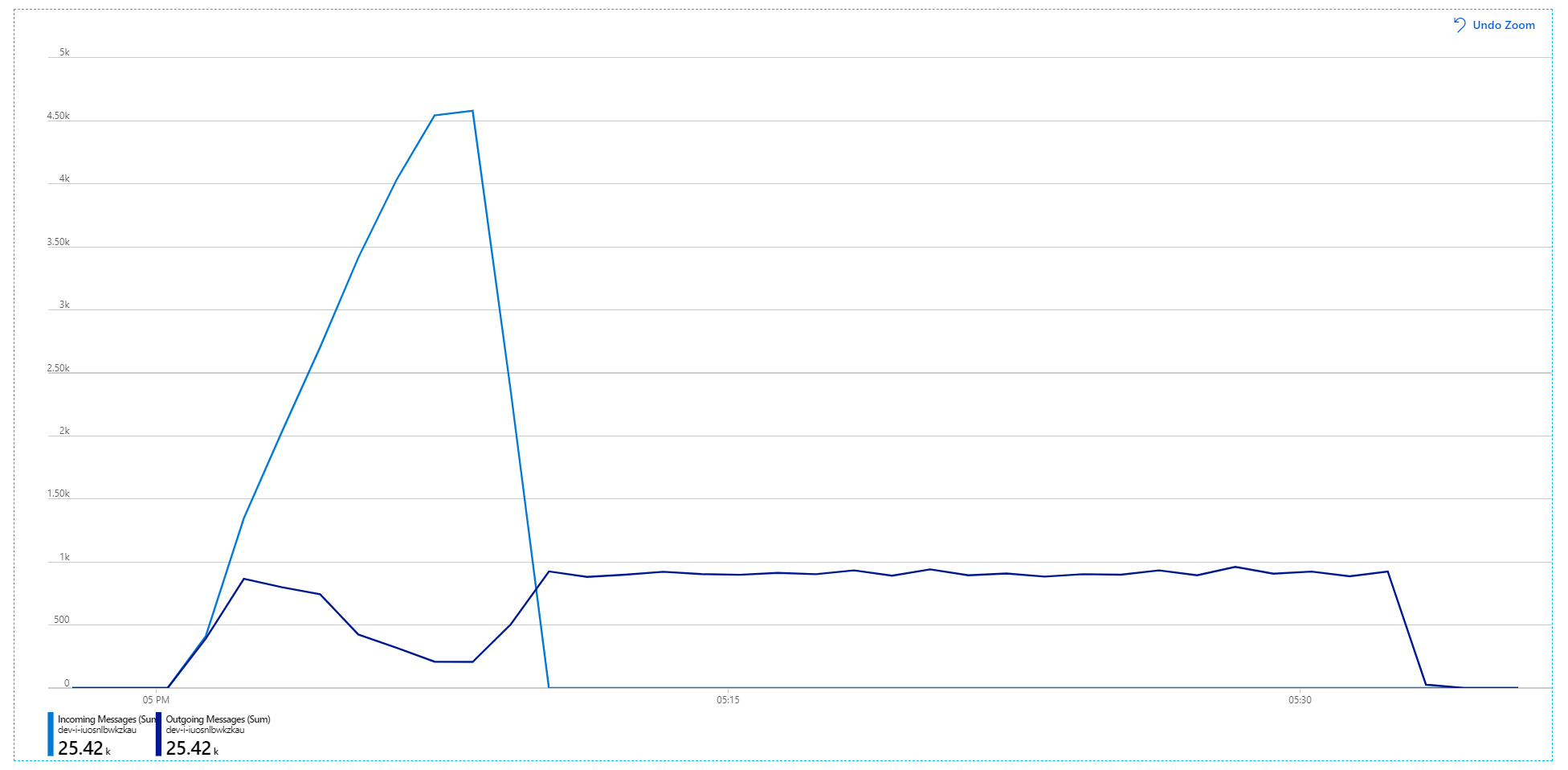
El rendimiento es más coherente, pero el máximo obtenido es aproximadamente el mismo que el de la prueba anterior:
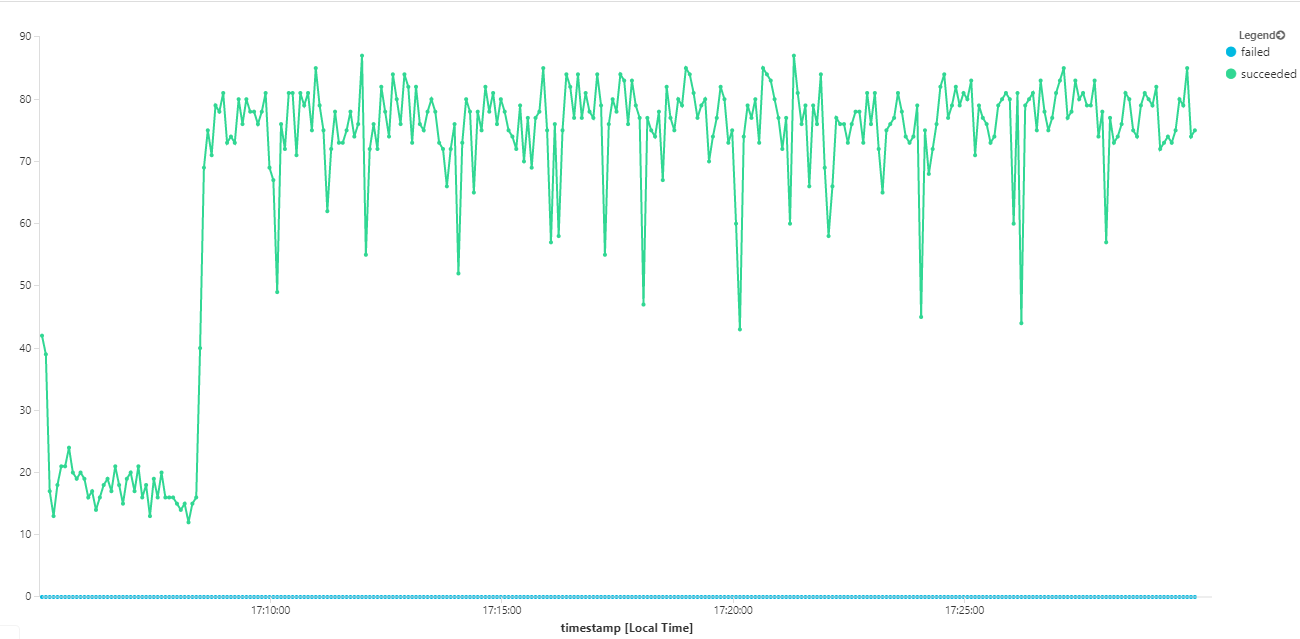
Además, al consultar Azure Monitor Container Insights, parece que el problema no se debe a un agotamiento de los recursos del clúster. En primer lugar, las métricas de nivel de nodo muestran que el uso de CPU permanece por debajo del 40 %, incluso en el percentil 95, y el uso de memoria es aproximadamente del 20 %.
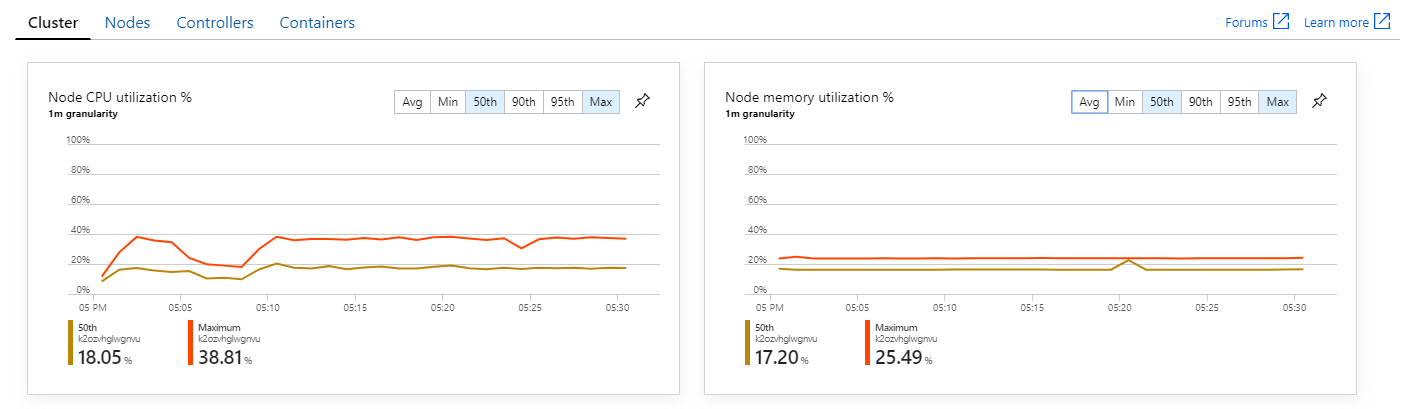
En un entorno Kubernetes, es posible que los pods individuales tengan restringidos los recursos, incluso si no lo están. Pero la vista de nivel de pod muestra que todos los pods están en buen estado.
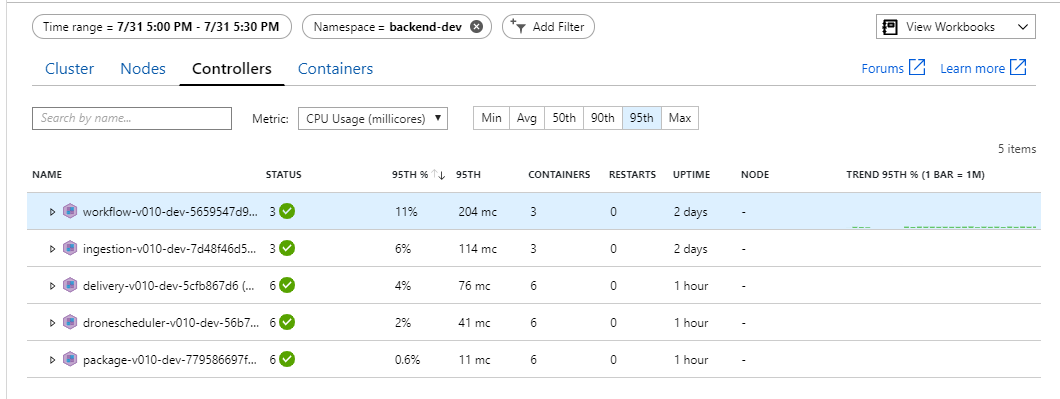
A partir de esta prueba, parece que no va a servir de ayuda agregar más pods al back-end. El siguiente paso consiste en examinar más detenidamente en el servicio Workflow para comprender lo que ocurre cuando se procesan los mensajes. Application Insights muestra que la duración media de la operación de Process del servicio Workflow es de 246 ms.
También se puede ejecutar una consulta para obtener métricas de las operaciones individuales dentro de cada transacción:
| Destino | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| entrega | 37 | 57 |
| Paquete | 12 | 17 |
| dronescheduler | 21 | 41 |
La primera fila de esta tabla representa la cola de Service Bus. Las demás filas son las llamadas a los servicios del back-end. Como referencia, esta es la consulta de Log Analytics para esta tabla:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
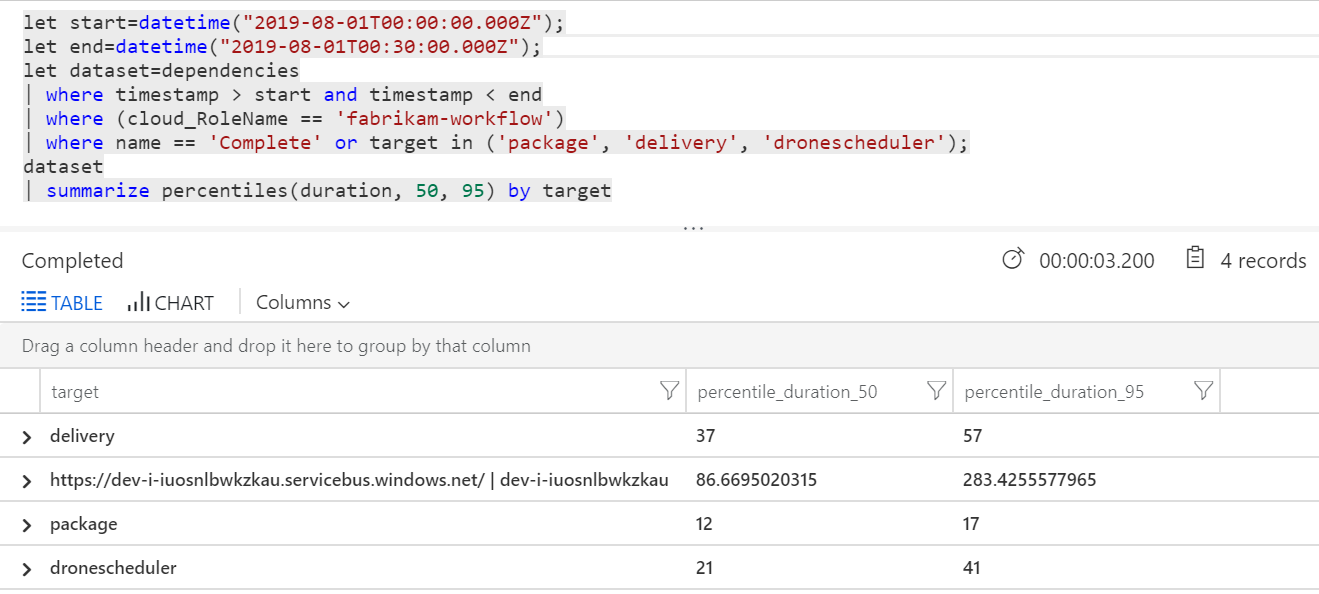
Estas latencias parecen razonables. Pero esta es la información clave: Si el tiempo total de operación es de ~250 ms, se coloca un límite superior estricto para la rapidez con la que se pueden procesar los mensajes en serie. La clave para mejorar el rendimiento, por lo tanto, es un paralelismo mayor.
Esto debería ser posible en este escenario, por dos motivos:
- Se trata de llamadas de red, por lo que la mayor parte del tiempo se dedica a esperar la finalización de E/S.
- Los mensajes son independientes y no es necesario procesarlos en orden.
Prueba 4: Aumento de paralelismo
Para esta prueba, el equipo se centró en aumentar el paralelismo. Para ello, ajustaron dos valores en el cliente de Service Bus usado por el servicio Workflow:
| Configuración | Descripción | Valor predeterminado | Valor nuevo |
|---|---|---|---|
MaxConcurrentCalls |
El número máximo de mensajes que se van a procesar simultáneamente. | 1 | 20 |
PrefetchCount |
El número de mensajes que el cliente capturará con anticipación en su caché local. | 0 | 3000 |
Para más información sobre estos valores, consulte Procedimientos recomendados para mejorar el rendimiento mediante la mensajería de Service Bus. La ejecución de la prueba con esta configuración produjo el siguiente gráfico:
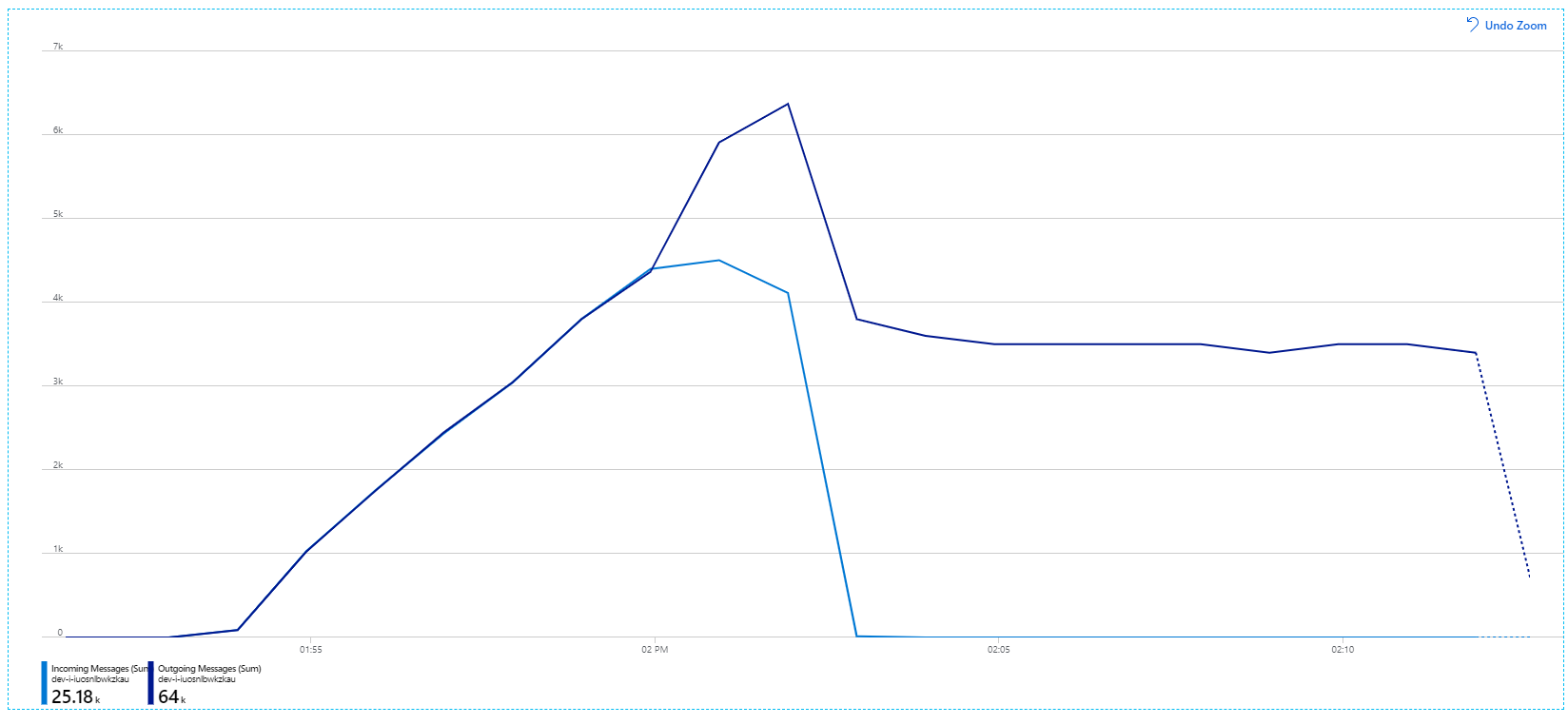
Recuerde que los mensajes entrantes se muestran en azul claro y los mensajes salientes se muestran en azul oscuro.
A primera vista, se trata de un gráfico muy raro. Durante un tiempo, la velocidad del mensaje saliente sigue exactamente la velocidad de entrada. Sin embargo, a partir de la marca 2:03, la velocidad de los mensajes entrantes se nivela, mientras que el número de mensajes salientes sigue aumentando, lo que realmente supera el número total de mensajes entrantes. Parece imposible.
La pista de este misterio puede encontrarse en la vista Dependencias de Application Insights. En este gráfico se resumen todas las llamadas que el servicio Workflow ha realizado para Service Bus:
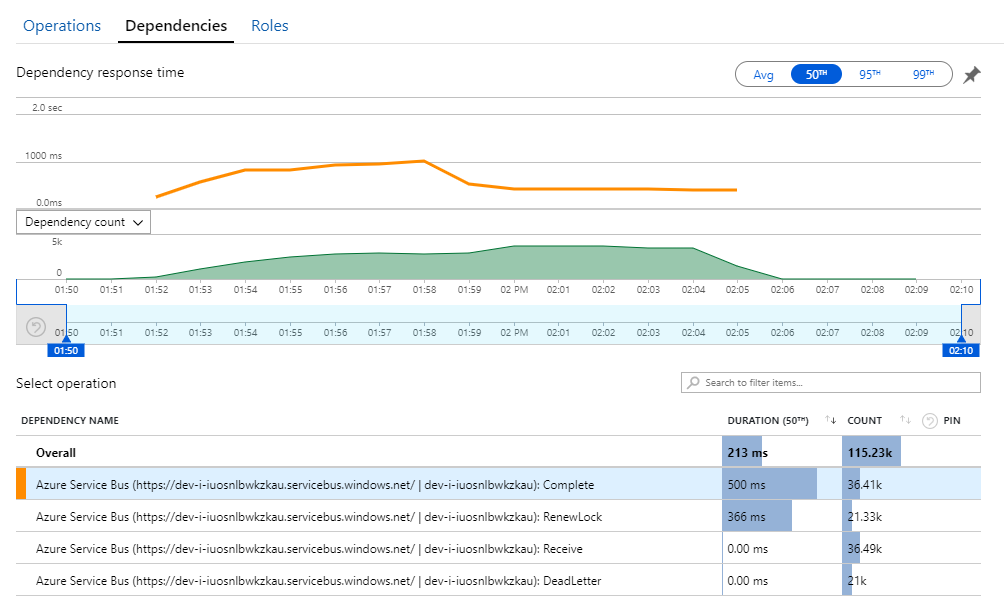
Observe la entrada para DeadLetter. Estas llamadas indican los mensajes que entran en la cola de mensajes fallidos de Service Bus.
Para comprender lo que está ocurriendo, debe comprender la semántica de Bloqueo por pico en Service Bus. Cuando un cliente utiliza el bloqueo por pico, Service Bus recupera y bloquea automáticamente un mensaje. Mientras se mantiene el bloqueo, se garantiza que el mensaje no se va a entregar a otros destinatarios. Si expira el bloqueo, el mensaje pasa a estar disponible para otros destinatarios. Después de un número máximo de intentos de entrega (que es configurable), Service Bus colocará los mensajes en una cola de mensajes fallidos, donde se puede examinar más adelante.
Recuerde que el servicio Workflow captura previamente lotes grandes de mensajes, 3000 mensajes a la vez). Esto significa que el tiempo total de procesamiento de cada mensaje es mayor, lo que hace que se agote el tiempo de espera de los mensajes, que vuelvan a la cola y, finalmente, que se pasen a la cola de mensajes fallidos.
También puede ver este comportamiento en las excepciones, donde se registran numerosas excepciones de MessageLostLockException:
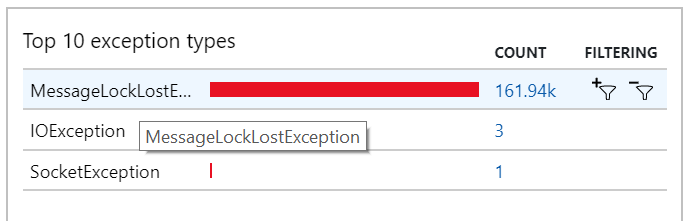
Prueba 5: Aumento de la duración del bloqueo
Para esta prueba de carga, la duración del bloqueo de mensaje se estableció en 5 minutos para evitar tiempos de espera de bloqueo. El gráfico de mensajes entrantes y salientes muestra ahora que el sistema sigue el ritmo de la velocidad de mensajes entrantes:
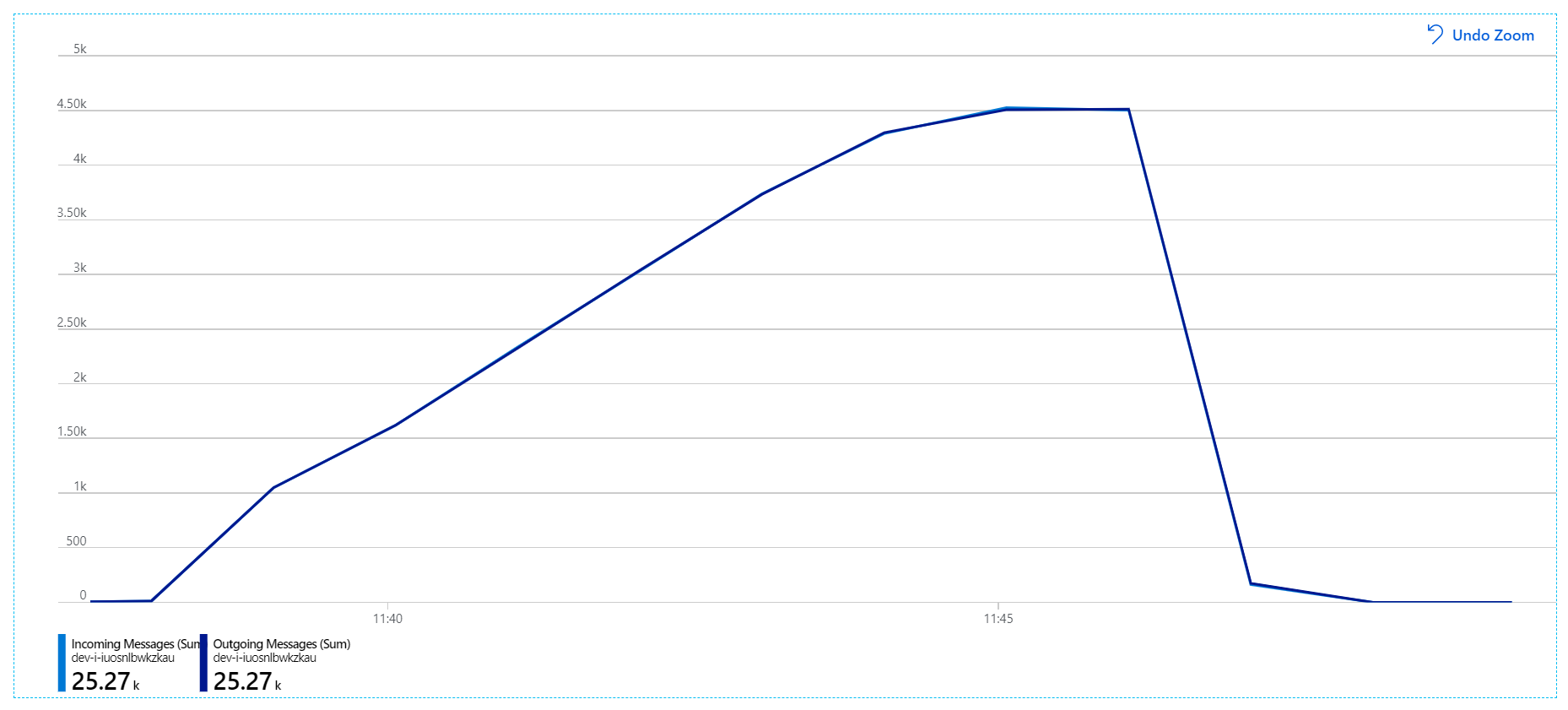
Durante toda la prueba de carga de 8 minutos, la aplicación completó 25 000 operaciones, con un rendimiento pico de 72 operaciones/s, que representa un aumento del 400 % del rendimiento máximo.
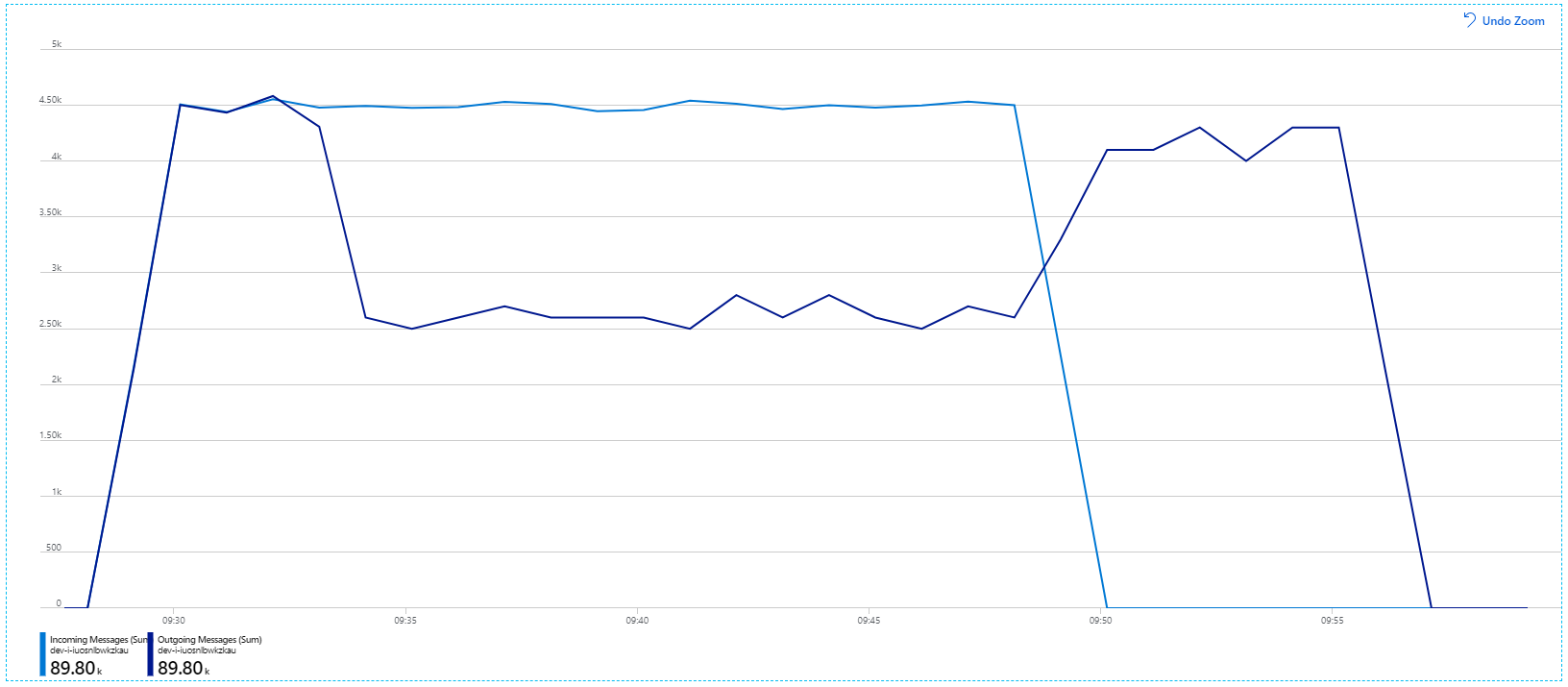
Sin embargo, al ejecutar la misma prueba con una duración más larga, se demostró que la aplicación no pudo sostener esta velocidad:
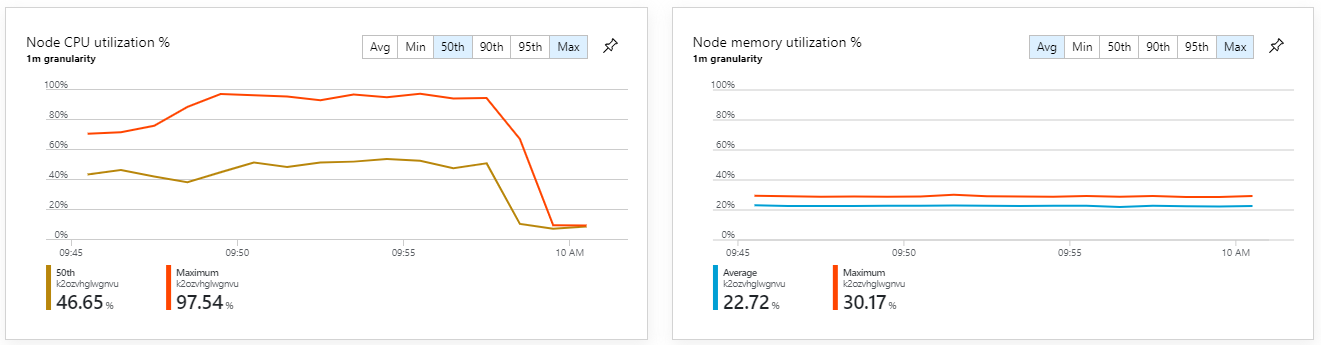
Las métricas de contenedor muestran que el uso máximo de CPU era cerca del 100 %. En este punto, la aplicación parece estar enlazada a la CPU. El escalado del clúster podría mejorar el rendimiento ahora, a diferencia del intento anterior de escalado horizontal.
Prueba 6: Escalado horizontal de los servicios del back-end (otra vez)
Para la prueba de carga final de la serie, el equipo escaló horizontalmente el clúster de Kubernetes y pods de la manera siguiente:
| Configuración | Value |
|---|---|
| Nodos de clúster | 12 |
| Servicio Ingestion | 3 réplicas |
| Servicio Workflow | 6 réplicas |
| Servicios Package, Delivery y Drone Scheduler | 9 réplicas cada uno |
Esta prueba dio como resultado un mayor rendimiento sostenido, sin retrasos significativos en el procesamiento de mensajes. Además, el uso de CPU del nodo permaneció por debajo del 80 %.
Resumen
En este escenario, se identificaron los siguientes cuellos de botella:
- Excepciones de memoria insuficiente en Azure Cache for Redis.
- Falta de paralelismo en el procesamiento de mensajes.
- Duración insuficiente del bloqueo de mensaje, que conduce a tiempos de espera de bloqueo y que se coloquen los mensajes en la cola de mensajes fallidos.
- Agotamiento de CPU.
Para diagnosticar estos problemas, el equipo de desarrollo se basó en las siguientes métricas:
- La velocidad de los mensajes de Service Bus entrantes y salientes.
- Mapa de aplicación en Application Insights.
- Errores y excepciones.
- Consultas personalizadas de Log Analytics.
- El uso de CPU y memoria en Azure Monitor Container Insights.
Pasos siguientes
Para más información sobre el diseño de este escenario, consulte Diseño de una arquitectura de microservicios.