Reglas de alertas recomendadas para clústeres de Kubernetes
Las alertas en Azure Monitor identifican proactivamente los problemas relacionados con el estado y el rendimiento de los recursos de Azure. En este artículo se describe cómo habilitar y editar un conjunto de reglas de alertas de métricas recomendadas y predefinidas para los clústeres de Kubernetes.
Habilitación de reglas de alerta recomendadas
Use uno de los métodos siguientes para habilitar las reglas de alertas recomendadas para el clúster. Puede habilitar las reglas de alertas de métricas de Prometheus y de la plataforma para el mismo clúster.
Nota:
Las plantillas de ARM son el único método admitido para habilitar las alertas recomendadas en los clústeres de Kubernetes habilitados para Arc.
Al usar Azure Portal, el grupo de reglas de Prometheus se creará en la misma región que el clúster.
En el menú Alertas del clúster, seleccione Configurar recomendaciones.
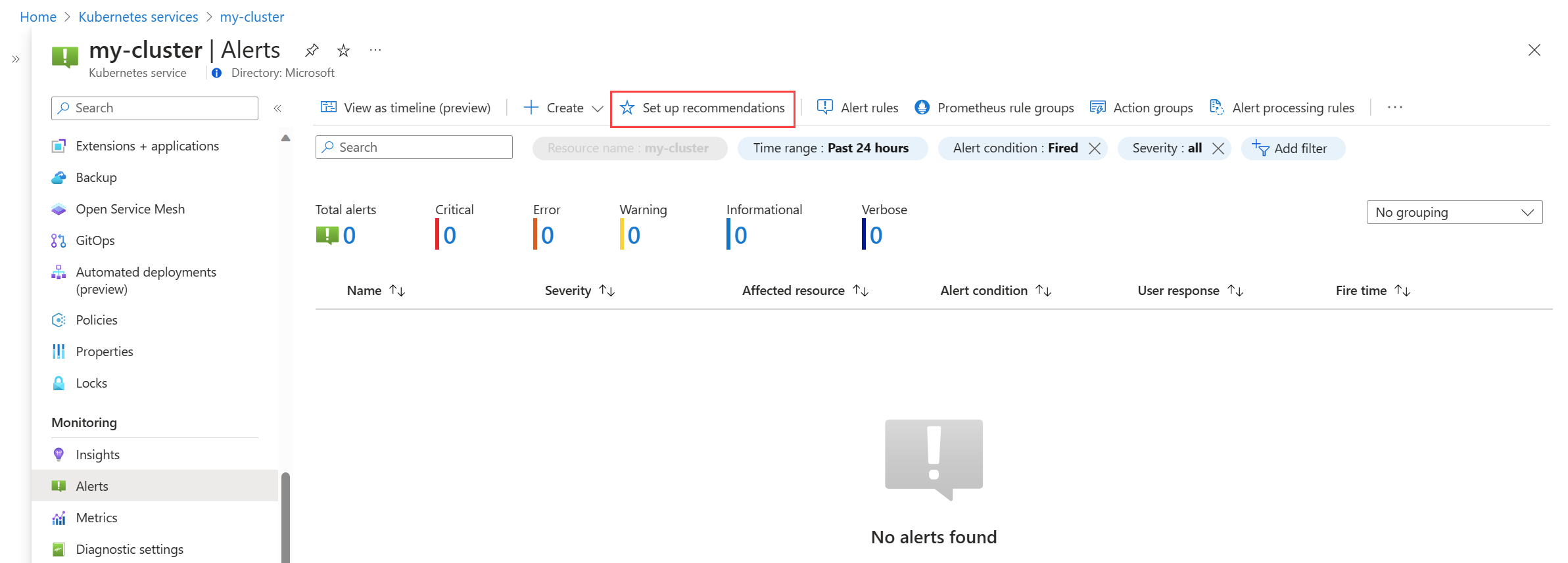
Las reglas de alertas disponibles de la plataforma y de Prometheus se muestran con las reglas de Prometheus organizadas por nivel de pod, clúster y nodo. Active un grupo de reglas de Prometheus para habilitar ese conjunto de reglas. Expanda el grupo para ver las reglas individuales. Puede dejar los valores predeterminados o deshabilitar reglas individuales y editar su nombre y su gravedad.

Active una regla de métricas de la plataforma para habilitar esa regla. Puede expandir la regla para modificar sus detalles, como el nombre, la gravedad y el umbral.
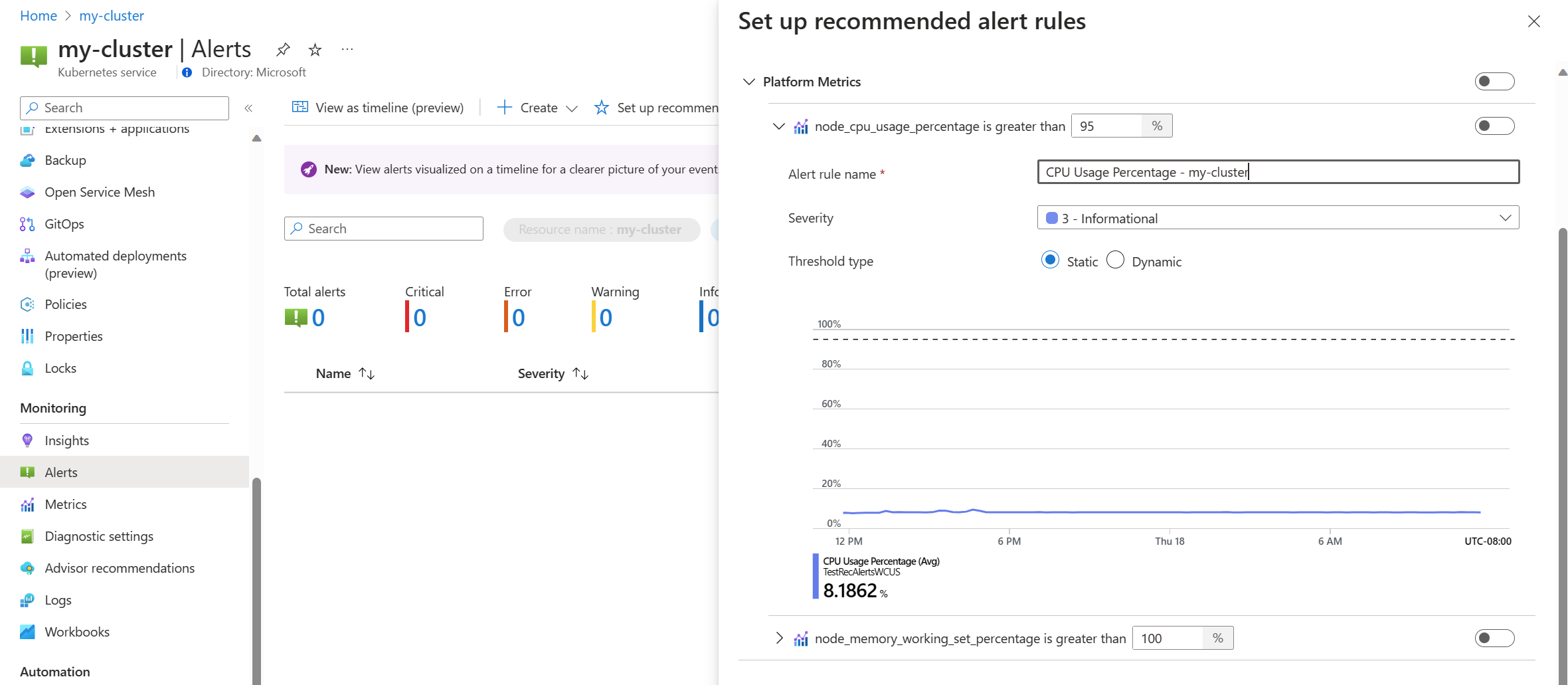
Seleccione uno o varios métodos de notificación para crear un nuevo grupo de acciones o seleccione un grupo de acciones existente con los detalles de notificación de este conjunto de reglas de alertas.
Haga clic en Guardar para guardar el grupo de reglas.



Edición de las reglas de alertas recomendadas
Una vez creado el grupo de reglas, no puede usar la misma página en el portal para editar las reglas. En el caso de las métricas de Prometheus, debe editar el grupo de reglas para modificar cualquiera de las reglas que contiene, incluido para habilitar reglas que aún no estaban habilitadas. En el caso de las métricas de la plataforma, puede editar cada regla de alertas.
En el menú Alertas del clúster, seleccione Configurar recomendaciones. Las reglas o grupos de reglas que ya se han creado se etiquetarán como Ya creadas.
Expanda la regla o el grupo de reglas. Haga clic en Ver grupo de reglas para Prometheus y Ver regla de alertas para las métricas de la plataforma.
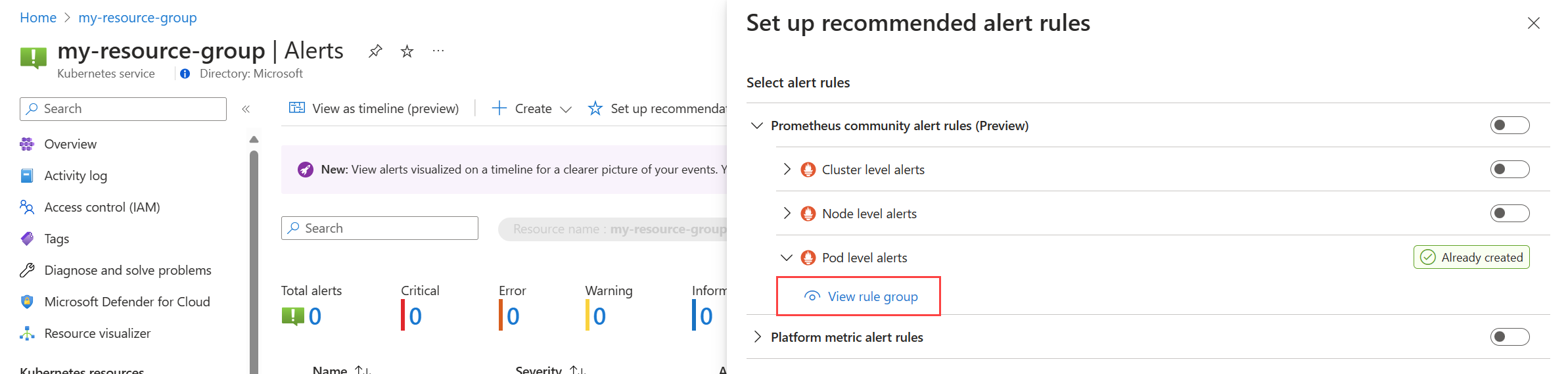
Para los grupos de reglas de Prometheus:
Seleccione Reglas para ver las reglas de alertas en el grupo.
Haga clic en el icono Editar junto a la regla que quiera modificar. Siga las instrucciones que se indican en Configuración de las reglas en el grupo para modificar la regla.

Cuando termine de editar las reglas del grupo, haga clic en Guardar para guardar el grupo de reglas.
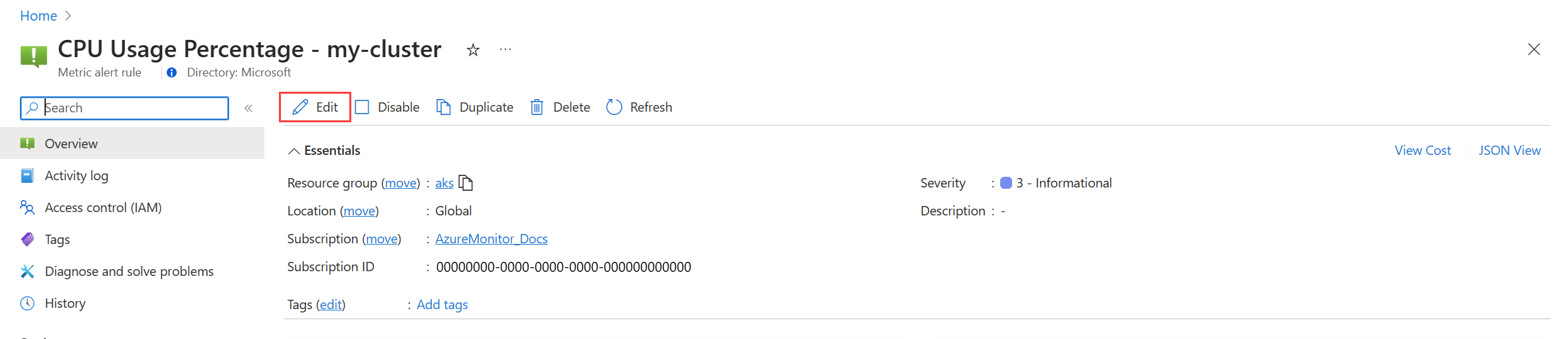
Para las métricas de la plataforma:
Haga clic en Editar para abrir los detalles de la regla de alertas. Siga las instrucciones que se indican en Configuración de las condiciones de la regla de alertas para modificar la regla.



Deshabilitación de un grupo de reglas de alertas
Deshabilite el grupo de reglas para dejar de recibir alertas de las reglas que contiene.
Acceda al grupo de reglas de alertas de Prometheus o a la regla de alertas de la plataforma tal como se describe en la sección Edición de las reglas de alertas recomendadas.
En el menú Información general, seleccione Deshabilitar.


Detalles de las reglas de alertas recomendadas
En las tablas siguientes se enumeran los detalles de cada regla de alertas recomendada. El código fuente de cada regla está disponible en GitHub junto con guías de solución de problemas de la comunidad de Prometheus.
Reglas de alertas de la comunidad de Prometheus
Alertas de nivel de clúster
| Nombre de la alerta | Descripción | Umbral predeterminado | Período de tiempo (minutos) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | La cuota de recursos de CPU asignada a los espacios de nombres ha superado los recursos de CPU disponibles en los nodos del clúster en más del 50 % durante los últimos 5 minutos. | >1,5 | 5 |
| KubeMemoryQuotaOvercommit | La cuota de recursos de memoria asignada a los espacios de nombres ha superado los recursos de memoria disponibles en los nodos del clúster en más del 50 % durante los últimos 5 minutos. | >1,5 | 5 |
| KubeContainerOOMKilledCount | Se han eliminado uno o varios contenedores dentro de los pods debido a eventos de memoria insuficiente durante los últimos 5 minutos. | >0 | 5 |
| KubeClientErrors | La tasa de errores de cliente (códigos de estado HTTP a partir de 5xx) en las solicitudes de API de Kubernetes ha superado el 1 % de la tasa total de solicitudes de API durante los últimos 15 minutos. | >0,01 | 15 |
| KubePersistentVolumeFillingUp | El volumen persistente se está llenando y se espera que se agote el espacio disponible teniendo en cuenta la proporción de espacio disponible, el espacio usado y la tendencia lineal prevista del espacio disponible en las últimas 6 horas. Estas condiciones se evalúan durante los últimos 60 minutos. | N/D | 60 |
| KubePersistentVolumeInodesFillingUp | Menos del 3 % de los inodes dentro de un volumen persistente han estado disponibles durante los últimos 15 minutos. | <0,03 | 15 |
| KubePersistentVolumeErrors | Uno o varios volúmenes persistentes han estado en una fase con errores o en espera durante los últimos 5 minutos. | >0 | 5 |
| KubeContainerWaiting | Uno o varios contenedores en pods de Kubernetes han estado en un estado de espera durante los últimos 60 minutos. | >0 | 60 |
| KubeDaemonSetNotScheduled | Uno o varios pods no se han programado en ningún nodo en los últimos 15 minutos. | >0 | 15 |
| KubeDaemonSetMisScheduled | Uno o varios pods se han programado incorrectamente en el clúster durante los últimos 15 minutos. | >0 | 15 |
| KubeQuotaAlmostFull | El uso de cuotas de recursos de Kubernetes ha estado comprendido entre el 90 % y el 100 % de los límites estrictos durante los últimos 15 minutos. | >0,9 <1 | 15 |
Alertas de nivel de nodo
| Nombre de la alerta | Descripción | Umbral predeterminado | Período de tiempo (minutos) |
|---|---|---|---|
| KubeNodeUnreachable | Un nodo ha estado inaccesible durante los últimos 15 minutos. | 1 | 15 |
| KubeNodeReadinessFlapping | El estado de preparación de un nodo ha cambiado más de dos veces en los últimos 15 minutos. | 2 | 15 |
Alertas de nivel de pod
| Nombre de la alerta | Descripción | Umbral predeterminado | Período de tiempo (minutos) |
|---|---|---|---|
| KubePVUsageHigh | La utilización media de volúmenes persistentes en pod ha superado el 80 % durante los últimos 15 minutos. | >0,8 | 15 |
| KubeDeploymentReplicasMismatch | Ha habido una discrepancia entre el número deseado de réplicas y el número de réplicas disponibles durante los últimos 10 minutos. | N/D | 10 |
| KubeStatefulSetReplicasMismatch | El número de réplicas listas en StatefulSet no ha coincidido con el número total de réplicas en StatefulSet durante los últimos 15 minutos. | N/D | 15 |
| KubeHpaReplicasMismatch | Horizontal Pod Autoscaler en el clúster no ha coincidido con el número deseado de réplicas durante los últimos 15 minutos. | N/D | 15 |
| KubeHpaMaxedOut | Horizontal Pod Autoscaler (HPA) en el clúster se ha estado ejecutando en el número máximo de réplicas durante los últimos 15 minutos. | N/D | 15 |
| KubePodCrashLooping | Uno o varios pods han estado en una condición CrashLoopBackOff, donde se bloquean continuamente después del inicio y no se pueden recuperar correctamente, durante los últimos 15 minutos. | >=1 | 15 |
| KubeJobStale | Al menos una instancia de trabajo no se ha completado correctamente durante las últimas 6 horas. | >0 | 360 |
| KubePodContainerRestart | Uno o varios contenedores dentro de pods en el clúster de Kubernetes se han reiniciado al menos una vez durante la última hora. | >0 | 15 |
| KubePodReadyStateLow | El porcentaje de pods en un estado listo ha estado por debajo del 80 % para cualquier implementación o daemonset en el clúster de Kubernetes durante los últimos 5 minutos. | <0,8 | 5 |
| KubePodFailedState | Uno o varios pods han tenido un estado de error durante los últimos 5 minutos. | >0 | 5 |
| KubePodNotReadyByController | Uno o varios pods no han tenido un estado Listo (es decir, han estado en la fase "Pendiente" o "Desconocida") durante los últimos 15 minutos. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | La generación observada de un objeto StatefulSet de Kubernetes no ha coincidido con su generación de metadatos durante los últimos 15 minutos. | N/D | 15 |
| KubeJobFailed | Se ha producido un error en uno o varios trabajos de Kubernetes en los últimos 15 minutos. | >0 | 15 |
| KubeContainerAverageCPUHigh | La utilización media de CPU por contenedor ha superado el 95 % durante los últimos 5 minutos. | >0,95 | 5 |
| KubeContainerAverageMemoryHigh | La utilización media de memoria por contenedor ha superado el 95 % durante los últimos 5 minutos. | >0,95 | 10 |
| KubeletPodStartUpLatencyHigh | El percentil 99 de la latencia de inicio del pod ha superado los 60 segundos durante los últimos 10 minutos. | >60 | 10 |
Reglas de alertas de métricas de la plataforma
| Nombre de la alerta | Descripción | Umbral predeterminado | Período de tiempo (minutos) |
|---|---|---|---|
| El porcentaje de CPU del nodo es superior al 95 % | El porcentaje de CPU del nodo ha sido superior al 95 % durante los últimos 5 minutos. | 95 | 5 |
| El porcentaje de espacio de trabajo de memoria del nodo es superior al 100 % | El porcentaje del conjunto de trabajo de memoria del nodo es mayor que el 100 % durante los últimos 5 minutos. | 100 | 5 |
Alertas de métricas heredadas de Container Insights (versión preliminar)
Las reglas de métricas de Container Insights se retiraron el 31 de mayo de 2024. Estas reglas estaban en versión preliminar pública, pero se retiraron sin llegar a ser de disponibilidad general, ya que ahora están disponibles las nuevas alertas de métricas recomendadas descritas en este artículo.
Si ya ha habilitado estas reglas de alertas heredadas, debe deshabilitarlas y habilitar la nueva experiencia.
Deshabilitar reglas de alertas de métricas
- En el menú Insights del clúster, seleccione Alertas recomendadas (versión preliminar).
- Cambie el estado de cada regla de alertas a Deshabilitada.
Asignación de alertas heredada
En la tabla siguiente se asigna cada una de las alertas de métricas heredadas de Container Insights a sus alertas de métricas recomendadas equivalentes de Prometheus.
| Alerta recomendada de métrica personalizada | Alerta recomendada equivalente de métrica de Prometheus/Plataforma | Condición |
|---|---|---|
| Completed job count (Recuento de trabajos completados) | KubeJobStale (alertas de nivel de pod) | Al menos una instancia de trabajo no se ha completado correctamente durante las últimas 6 horas. |
| Porcentaje de CPU del contenedor | KubeContainerAverageCPUHigh (alertas de nivel de pod) | La utilización media de CPU por contenedor ha superado el 95 % durante los últimos 5 minutos. |
| Porcentaje de memoria del espacio de trabajo del contenedor | KubeContainerAverageMemoryHigh (alertas de nivel de pod) | La utilización media de memoria por contenedor ha superado el 95 % durante los últimos 5 minutos. |
| Recuentos de pod con errores | KubePodFailedState (alertas de nivel de pod) | Uno o varios pods han tenido un estado de error durante los últimos 5 minutos. |
| Porcentaje de CPU del nodo | El porcentaje de CPU del nodo es mayor que el 95 % (métrica de Plataforma) | El porcentaje de CPU del nodo ha sido superior al 95 % durante los últimos 5 minutos. |
| Porcentaje de uso de disco de nodo | N/D | El uso medio de disco para un nodo es mayor que el 80 %. |
| Node NotReady status (Estado de nodo NotReady) | KubeNodeUnreachable (alertas de nivel de nodo) | Un nodo ha estado inaccesible durante los últimos 15 minutos. |
| Porcentaje de memoria del conjunto de trabajo del nodo | El porcentaje de espacio de trabajo de memoria del nodo es superior al 100 % | El porcentaje del conjunto de trabajo de memoria del nodo es mayor que el 100 % durante los últimos 5 minutos. |
| OOM Killed Containers (Contenedores eliminados con memoria insuficiente) | KubeContainerOOMKilledCount (alertas de nivel de clúster) | Se han eliminado uno o varios contenedores dentro de los pods debido a eventos de memoria insuficiente durante los últimos 5 minutos. |
| Porcentaje de uso de volumen persistente | KubePVUsageHigh (alertas de nivel de pod) | La utilización media de volúmenes persistentes en pod ha superado el 80 % durante los últimos 15 minutos. |
| Pods ready % (% de pods listos) | KubePodReadyStateLow (alertas de nivel de pod) | El porcentaje de pods en un estado listo ha estado por debajo del 80 % para cualquier implementación o daemonset en el clúster de Kubernetes durante los últimos 5 minutos. |
| Restarting container count (Reiniciando recuento de contenedores) | KubePodContainerRestart (alertas de nivel de pod) | Uno o varios contenedores dentro de pods en el clúster de Kubernetes se han reiniciado al menos una vez durante la última hora. |
Pasos siguientes
- Obtenga información sobre los diferentes tipos de reglas de alerta en Azure Monitor.
- Consulte los grupos de reglas en el servicio administrado de Azure Monitor para Prometheus.