Supervisión de máquinas virtuales con Azure Monitor: alertas
Este artículo forma parte de la guía Supervisión de máquinas virtuales y sus cargas de trabajo en Azure Monitor. Las alertas de Azure Monitor notifican al usuario proactivamente sobre datos y patrones interesantes en los datos de supervisión. No hay reglas de alerta preconfiguradas para las máquinas virtuales, pero puede crear las suyas propias en función de los datos recopilados por el agente de Azure Monitor. En este artículo se presentan conceptos de alerta específicos de las máquinas virtuales y las reglas de alerta comunes que usan otros clientes de Azure Monitor.
En este escenario se describe cómo implementar una supervisión completa del entorno de máquina virtual híbrida y de Azure:
Para empezar a supervisar la primera máquina virtual de Azure, consulte Supervisión de máquinas virtuales de Azure.
Para habilitar rápidamente un conjunto recomendado de alertas, consulte Habilitación de reglas de alerta recomendadas para máquinas virtuales de Azure.
Importante
La mayoría de las reglas de alertas tienen un coste que depende del tipo de regla, del número de dimensiones que incluyen y de la frecuencia con que se ejecutan. Antes de crear reglas de alerta, consulte la sección Reglas de alerta en Precios de Azure Monitor.
datos, recopilación
Las reglas de alerta inspeccionan los datos que ya se han recopilado en Azure Monitor. Debe asegurarse de que los datos se recopilan para un escenario determinado antes de poder crear una regla de alertas. Consulte Supervisión de máquinas virtuales con Azure Monitor: recopilación de datos para obtener instrucciones sobre cómo configurar la recopilación de datos para varios escenarios, incluidas todas las reglas de alerta de este artículo.
Reglas de alertas recomendadas
Azure Monitor proporciona un conjunto de reglas de alertas recomendadas que puede habilitar rápidamente para cualquier máquina virtual de Azure. Estas reglas son un excelente punto de partida para la supervisión básica. Pero por sí solas, no proporcionarán alertas suficientes para la mayoría de las implementaciones empresariales por los siguientes motivos:
- Las alertas recomendadas solo se aplican a las máquinas virtuales de Azure y no a las máquinas híbridas.
- Las alertas recomendadas solo incluyen métricas de host y no métricas o registros de invitado. Estas métricas son útiles para supervisar el estado de la propia máquina. Pero ofrecen una visibilidad mínima de las cargas de trabajo y las aplicaciones que se ejecutan en la máquina.
- Las alertas recomendadas están asociadas a máquinas individuales que crean un número excesivo de reglas de alerta. En lugar de confiar en este método para cada máquina, consulte Escalado de reglas de alertas para ver estrategias sobre el uso de un número mínimo de reglas de alerta para varias máquinas.
Tipos de alerta
Los tipos más comunes de reglas de alertas de Azure Monitor son las alertas de métricas y las alertas de búsqueda de registros. El tipo de regla de alertas que cree para un escenario determinado depende de dónde se encuentran los datos sobre los que genera alertas.
Es posible que haya casos en los que los datos para un escenario de alerta concreto estén disponibles tanto en las métricas como en los registros. Si es así, debe determinar qué tipo de regla usar. También puede tener flexibilidad en la forma de recopilar ciertos datos y dejar que su decisión sobre el tipo de regla de alerta dirija su decisión sobre el método de recopilación de datos.
Alertas de métricas
Usos comunes de las alertas de métricas:
- Alertar cuando una métrica determinada supera un umbral. Por ejemplo, cuando se consumen muchos recursos de CPU en una máquina.
Orígenes de datos para las alertas de métricas:
- Métricas de host para máquinas virtuales de Azure, que se recopilan automáticamente
- Métricas recopiladas por el agente de Azure Monitor del sistema operativo invitado
Alertas de búsqueda de registros
Usos comunes de las alertas de búsqueda de registros:
- Alertar cuando se encuentra un evento o patrón de eventos concretos del registro de eventos de Windows o Syslog. Estas reglas de alerta normalmente miden las filas de tabla devueltas de la consulta.
- Alertar según un cálculo de datos numéricos en varias máquinas. Estas reglas de alerta normalmente miden el cálculo de una columna numérica en los resultados de la consulta.
Orígenes de datos para alertas de búsqueda de registros:
- Todos los datos recopilados en un área de trabajo de Log Analytics
Escalado de reglas de alertas
Dado que es posible que tenga muchas máquinas virtuales que requieran la misma supervisión, no es necesario crear reglas de alerta individuales para cada una. También quiere asegurarse de que hay diferentes estrategias para limitar el número de reglas de alerta que necesita administrar, en función del tipo de regla. Cada una de estas estrategias depende de comprender el recurso de destino de la regla de alertas.
Reglas de alertas de métricas
Las máquinas virtuales admiten varias reglas de alertas de métricas de recursos, como se describe en Supervisión de varios recursos. Esta capacidad le permite crear una única regla de alerta de métricas que se aplique a todas las máquinas virtuales de un grupo de recursos o una suscripción dentro de la misma región.
Comience con las alertas recomendadas y cree una regla correspondiente para cada una mediante la suscripción o un grupo de recursos como recurso de destino. Debe crear reglas duplicadas para cada región si tiene máquinas en varias regiones.
A medida que identifique requisitos para más reglas de alerta de métricas, siga esta misma estrategia utilizando una suscripción o un grupo de recursos como recurso de destino para:
- Minimice el número de reglas de alerta que necesita administrar.
- Asegúrese de que se aplican automáticamente a las máquinas nuevas.
Reglas de alerta de búsqueda de registros
Si establece el recurso de destino de una regla de alerta de búsqueda de registros en un equipo específico, las consultas se limitan a los datos asociados a esa máquina, con lo que recibirá alertas individuales. Esta disposición requiere una regla de alerta independiente para cada máquina.
Si establece el recurso de destino de una regla de alerta de búsqueda de registros en un área de trabajo de Log Analytics, tendrá acceso a todos los datos de esa área de trabajo. Por este motivo, puede alertar sobre los datos de todas las máquinas del grupo de trabajo con una sola regla. Esta disposición le ofrece la opción de crear una única alerta para todas las máquinas. A continuación, puede usar dimensiones para crear una alerta independiente para cada máquina.
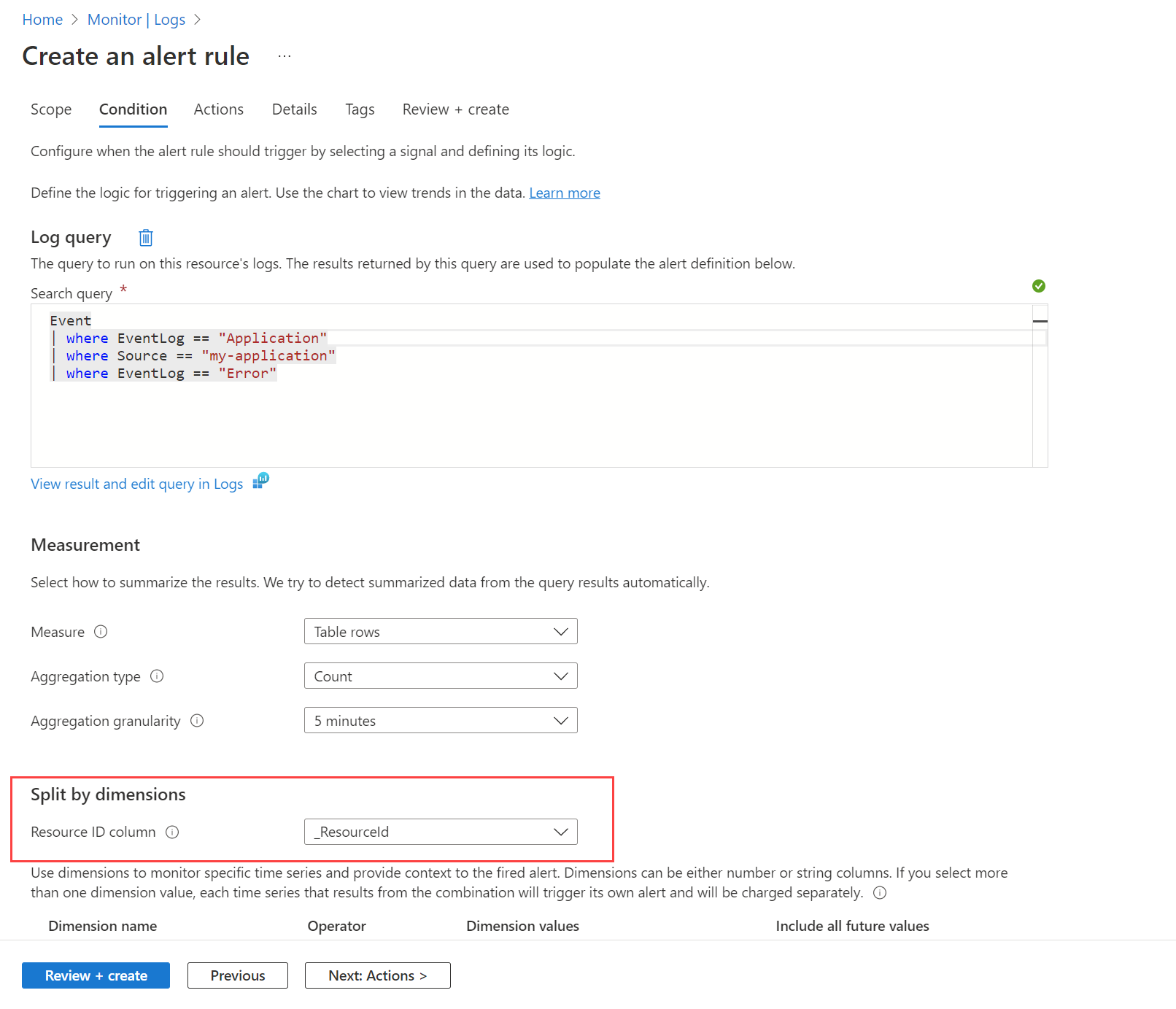
Por ejemplo, puede que quiera recibir una alerta cuando cualquier máquina cree un evento de error en el registro de eventos de Windows. En primer lugar, debe crear una regla de recopilación de datos como se describe en Recopilación de datos con el agente de Azure Monitor para enviar estos eventos a la tabla Event en el área de trabajo de Log Analytics. A continuación, cree una regla de alerta que consulte esta tabla utilizando el área de trabajo como recurso de destino y la condición que se muestra en la siguiente imagen.
La consulta devuelve un registro para los mensajes de error de cualquier máquina. Use la opción Dividir por dimensiones y especifique _ResourceId para indicar a la regla que cree una alerta para cada máquina si se devuelven varias máquinas en los resultados.
Dimensions
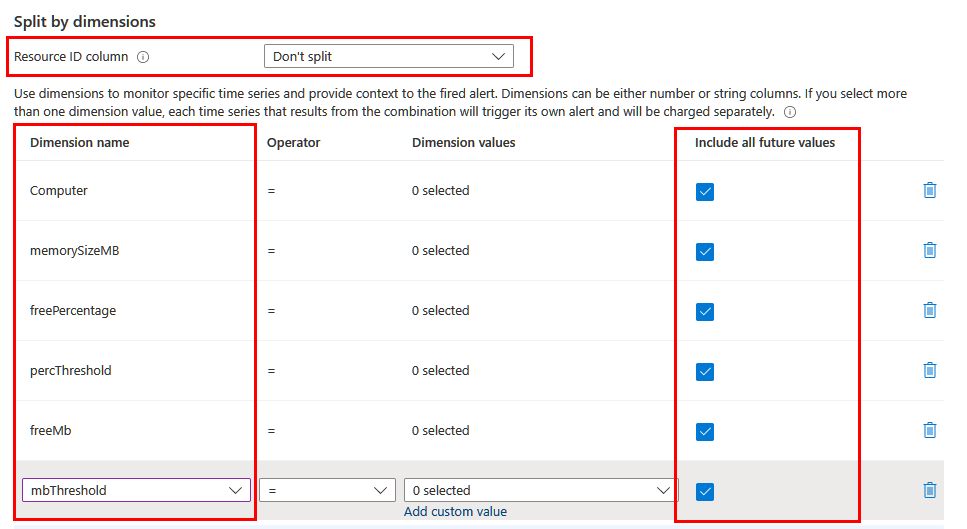
En función de la información que desee incluir en la alerta, puede que tenga que dividirla utilizando diferentes dimensiones. En este caso, asegúrese de que las dimensiones necesarias se proyectan en la consulta mediante el operador project o extend. Establezca el valor del campo Columna de id. de recurso en No dividir e incluya todas las dimensiones significativas de la lista. Asegúrese de que la opción Incluir todos los valores futuros está seleccionada, de forma que se incluya cualquier valor devuelto por la consulta.
Umbrales dinámicos
Una ventaja adicional de usar las reglas de alerta de búsqueda de registros es la posibilidad de incluir lógica compleja en la consulta para determinar el valor de umbral. Puede codificar el umbral de forma rígida, aplicarlo a todos los recursos o calcularlo dinámicamente en función de algún campo o valor calculado. El umbral se aplica a los recursos solo en función de condiciones específicas. Por ejemplo, puede crear una alerta basada en la memoria disponible, pero solo para las máquinas con una cantidad determinada de memoria total.
Reglas de alerta comunes
En la sección siguiente se enumeran las reglas de alertas comunes para las máquinas virtuales en Azure Monitor. Se proporcionan detalles sobre las alertas de métricas y las alertas de búsqueda de registros para cada una. Para saber qué tipo de alerta usar, consulte Tipos de alertas. Si no está familiarizado con el proceso de creación de reglas de alertas en Azure Monitor, consulte las instrucciones para crear una nueva regla de alertas.
Nota:
Los detalles de las alertas de búsqueda de registros que se proporcionan aquí usan los datos recopilados mediante VM Insights, que proporciona un conjunto de contadores de rendimiento comunes para el sistema operativo cliente. Este nombre es independiente del tipo de sistema operativo.
Disponibilidad de la máquina
Uno de los requisitos de supervisión más comunes para una máquina virtual es crear una alerta si deja de ejecutarse. El mejor método para esto es crear una regla de alerta de métricas en Azure Monitor mediante la métrica de disponibilidad de la máquina virtual, que se encuentra actualmente en versión preliminar pública. Para ver un tutorial sobre esta métrica, consulte Creación de una regla de alerta de disponibilidad para la máquina virtual de Azure.
Una regla de alerta se limita a una señal de registro de actividad. Por lo tanto, para cada condición, se debe crear una regla de alerta. Por ejemplo, "inicia o detiene la máquina virtual" requiere dos reglas de alerta. Sin embargo, para recibir alertas cuando se reinicia la máquina virtual, solo se necesita una regla de alerta.
Como se describe en Escalado de reglas de alerta, cree una regla de alerta de disponibilidad mediante una suscripción o un grupo de recursos como recurso de destino. La regla se aplica a varias máquinas virtuales, incluidas las nuevas que se crean después de la regla de alerta.
Latido de agente
El latido del agente es ligeramente diferente de la alerta no disponible de la máquina porque se basa en el agente de Azure Monitor para enviar un latido. El latido del agente puede avisarle si la máquina se está ejecutando, pero el agente no responde.
Reglas de alertas de métricas
Se incluye una métrica denominada Latido en cada área de trabajo de Log Analytics. Cada máquina virtual conectada a esa área de trabajo envía un valor de métrica de latido cada minuto. Dado que el equipo es una dimensión de la métrica, puede activar una alerta cuando un equipo no pueda enviar un latido. Establezca Tipo de agregación en Recuento y el valor de Umbral para que coincida con la granularidad de la evaluación.
Reglas de alerta de búsqueda de registros
Las alertas de búsqueda de registros usan la tabla Latido, que debe tener un registro de latido cada minuto de cada máquina.
Use una regla con la consulta siguiente:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Alertas de CPU
En esta sección se describen las alertas de CPU.
Reglas de alertas de métricas
| Destino | Métrica |
|---|---|
| Host | Porcentaje de CPU (incluido en las alertas recomendadas) |
| Invitado de Windows | \Información del procesador(_Total)% de tiempo de procesador |
| Invitado de Linux | cpu/usage_active |
Reglas de alerta de búsqueda de registros
Uso de CPU
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertas de memoria
En esta sección se describen las alertas de memoria.
Reglas de alertas de métricas
| Destino | Métrica |
|---|---|
| Host | Bytes de memoria disponibles (versión preliminar) (incluido en las alertas recomendadas) |
| Invitado de Windows | \Memoria% de bytes confirmados en uso \Memoria\Bytes disponibles |
| Invitado de Linux | mem/available mem/available_percent |
Reglas de alerta de búsqueda de registros
Nota:
Si necesita especificar la alerta en un disco, puede agregarla a la consulta: | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"Memoria disponible en MB
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Memoria disponible en porcentaje
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertas de disco
En esta sección se describen las alertas de disco.
Reglas de alertas de métricas
| Destino | Métrica |
|---|---|
| Invitado de Windows | \Disco lógico(_Total)% de espacio libre \Disco lógico(_Total)\Megabytes libres |
| Invitado de Linux | disk/free disk/free_percent |
Reglas de alerta de búsqueda de registros
Disco lógico usado: todos los discos de cada equipo
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Disco lógico usado: discos individuales
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
IOPS de disco lógico
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Velocidad de datos de disco lógico
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Alertas de red
Reglas de alertas de métricas
| Destino | Métrica |
|---|---|
| Host | Entrada de red total, Salida de red total (incluido en las alertas recomendadas) |
| Invitado de Windows | \Rendimiento de interfaz de red\Bytes enviados/s \Disco lógico(_Total)\Megabytes libres |
| Invitado de Linux | disk/free disk/free_percent |
Reglas de alerta de búsqueda de registros
Bytes de interfaces de red recibidos: todas las interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Bytes de interfaces de red recibidos: interfaces individuales
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Bytes de interfaces de red enviados: todas las interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Bytes de interfaces de red enviados: interfaces individuales
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Eventos de Windows y Linux
En el ejemplo siguiente se crea una alerta al crear un evento específico de Windows. Usa una regla de alertas de unidades métricas para crear una alerta independiente para cada equipo.
Crear una regla de alertas para un evento específico de Windows. En este ejemplo se muestra un evento en el registro de aplicaciones. Especifique un umbral de 0 e infracciones consecutivas superior a 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Crear una regla de alerta en eventos de Syslog con una gravedad determinada. En el ejemplo siguiente se muestran los eventos de autorización de errores. Especifique un umbral de 0 e infracciones consecutivas superior a 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Contadores de rendimiento personalizados
Crear una alerta sobre el valor máximo de un contador.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerCrear una alerta sobre el valor promedio de un contador.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Pasos siguientes
Análisis de los datos de supervisión recopilados para las máquinas virtuales