¿Qué es Azure Chaos Studio?
Azure Chaos Studio es un servicio administrado que usa ingeniería de caos para ayudarle a medir, comprender y mejorar la resistencia de las aplicaciones y servicios en la nube. La ingeniería del caos es una metodología por la que se insertan errores reales en la aplicación para ejecutar experimentos de inserción de errores controlados.
La resistencia es la capacidad de un sistema de controlar las interrupciones y recuperarse de ellas. Las interrupciones de la aplicación pueden provocar errores que pueden afectar negativamente a la empresa o misión. Tanto si desarrolla, migra o usa aplicaciones de Azure, es importante validar y mejorar su resistencia.
Chaos Studio le ayuda a evitar consecuencias negativas mediante la validación de la respuesta eficaz a interrupciones y errores de la aplicación. Puede usar Chaos Studio para probar la resistencia frente a incidentes reales, como interrupciones o un uso elevado de la CPU en máquinas virtuales (VM).
En el vídeo siguiente se proporciona más información sobre Chaos Studio:
Escenarios de Chaos Studio
Puede usar la ingeniería de caos para varios escenarios de validación de resistencia que abarcan el ciclo de vida de desarrollo y operaciones del servicio. Hay dos tipos de escenarios:
- Desplazamiento a la derecha: estos escenarios usan un entorno de producción o preproducción. Normalmente, se realiza el desplazamiento a la derecha de los escenarios con tráfico real del cliente o cargas simuladas.
- Desplazamiento a la izquierda: estos escenarios pueden usar un entorno de prueba compartido o de desarrollo. Puede realizar el desplazamiento a la izquierda de escenarios sin tráfico real del cliente.
Puede usar Chaos Studio para los siguientes escenarios comunes de ingeniería de caos:
- Reproducir un incidente que afecte a la aplicación para comprender mejor el error. Asegurarse de que las reparaciones posteriores al incidente impiden que el incidente se repita.
- Prepararse para un evento o temporada importante con carga "día del partido", escala, rendimiento y validación de resistencia.
- Realizar simulacros de continuidad empresarial y recuperación ante desastres para asegurarse de que la aplicación se pueda recuperar rápidamente y conservar los datos críticos en caso de desastre.
- Ejecutar simulacros de alta disponibilidad para probar la resistencia de la aplicación frente a interrupciones de la región, errores de configuración de red, eventos de gran esfuerzo o problemas de vecinos ruidosos.
- Desarrollar puntos de referencia de rendimiento de aplicaciones.
- Panificar las necesidades de capacidad de los entornos de producción.
- Ejecutar pruebas de esfuerzo o pruebas de carga.
- Asegurarse de que los servicios migrados desde un entorno local u otro entorno en la nube sigan siendo resistentes a los errores conocidos.
- Generar confianza en los servicios basados en arquitecturas nativas de nube.
- Validar que las herramientas de sitio en directo, los datos de observabilidad y los procesos disponibles todavía funcionan en condiciones inesperadas.
Para muchos de estos escenarios, primero se crea resistencia mediante experimentos de caos ad hoc. A continuación, valide continuamente que las nuevas implementaciones no retroceden en la resistencia. Para comprobarlo, ejecute experimentos de caos como puertas de implementación en las canalizaciones de integración continua o implementación continua.
Funcionamiento de Chaos Studio
Con Chaos Studio, puede organizar la inserción de errores segura y controlada en los recursos de Azure. La base de Chaos Studio son los experimentos de caos. Un experimento de caos describe los errores que se van a ejecutar y los recursos sobre los que se van a ejecutar. Puede organizar los errores para que se ejecuten en paralelo o de forma secuencial, en función de las necesidades.
Chaos Studio admite dos tipos de errores:
- Errores directos del servicio: estos errores se ejecutan directamente en un recurso de Azure, sin instalación ni instrumentación. Algunos ejemplos son el reinicio de un clúster de Azure Cache for Redis o la adición de latencia de red a pods de Azure Kubernetes Service (AKS).
- Errores basados en agente: estos errores se ejecutan en máquinas virtuales o en conjuntos de escalado de máquinas virtuales para realizar errores de invitado. Entre los ejemplos se incluyen la aplicación de presión de memoria virtual o la eliminación de un proceso.
Cada error tiene parámetros específicos que puede configurar, como el proceso que se va a terminar o cuánta presión de memoria se va a generar.
Al crear un experimento de caos, se definen uno o varios pasos que se ejecutan secuencialmente. Cada paso contiene una o varias ramas que se ejecutan en paralelo dentro del paso. Cada rama contiene una o varias acciones, como insertar un error o esperar una duración determinada.
Los destinos de recursos con los que se ejecutará cada error se organizan en grupos denominados selectores para que pueda hacer referencia fácilmente a un grupo de recursos en cada acción.
En el diagrama siguiente se muestra el diseño de un experimento de caos en Chaos Studio:
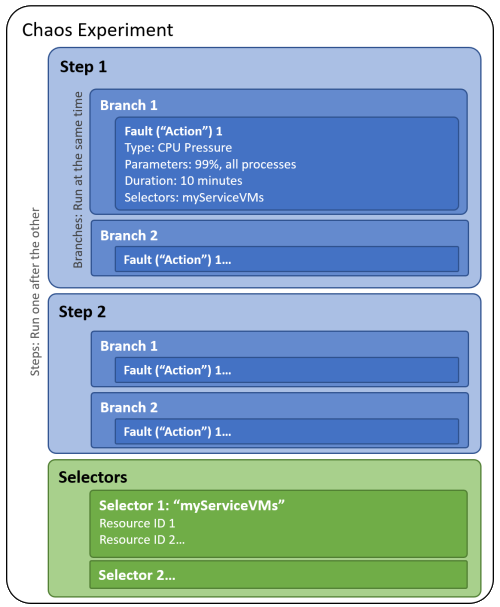
Un experimento de caos es un recurso de Azure que reside en una suscripción y un grupo de recursos. Puede usar Azure Portal o la API REST de Chaos Studio para crear, actualizar, iniciar, cancelar y ver el estado de los experimentos.
Pasos siguientes
Ahora que comprende cómo usar la ingeniería de caos, está listo para: