Comprobaciones de estado
CycleCloud ofrece dos mecanismos para comprobar el estado de las máquinas virtuales: las comprobaciones de estado del nodo son características más recientes que realizan las comprobaciones durante la fase de aprovisionamiento e impiden que las máquinas virtuales con estado incorrecto se unan, mientras que HealthCheck las ejecuta periódicamente después de que la máquina virtual se haya unido al clúster como un nodo.
Comprobaciones de estado del nodo
Las comprobaciones de estado del nodo pueden detectar hardware incorrecto antes de que se permita que una máquina virtual se una al clúster de CycleCloud. La versión actual de esta característica ejecutará scripts de comprobación de estado integrados en las imágenes oficiales de AzureHPC que se pueden encontrar en /opt/azurehpc/test/azurehpc-health-checks/. El origen de estos scripts se encuentra en el repositorio AzureHPC Node Health Checks, pero tenga en cuenta que es posible que la versión integrada en la versión del clúster de la imagen de AzureHPC no sea la más reciente disponible en el repositorio.
Requisitos
La versión actual de Node Health Checks solo admite imágenes de AzureHPC publicadas después del 7 de noviembre de 2023 (que contienen la versión v2.0.6 o posterior de azurehpc-health-checks) y las imágenes personalizadas derivadas de ellas. Las comprobaciones de estado del nodo no se admiten actualmente en Windows.
Habilitación de comprobaciones de estado de nodo para clústeres de Slurm
El formulario de creación de clústeres de Slurm ofrece una casilla para habilitar las comprobaciones de estado del nodo ubicadas en la pestaña Configuración avanzada . Al activar la casilla se habilitan las comprobaciones de estado del nodo de Node en la matriz de nodos de HPC del clúster. Si desea habilitar las comprobaciones de estado de node en otras matrices de nodos (o para otros tipos de clúster), debe usar una plantilla de clúster personalizada.
Las comprobaciones de estado del nodo se pueden deshabilitar en un clúster en ejecución simplemente desactivando la casilla. No es necesario reducir verticalmente la matriz de nodos para que los cambios surtan efecto.
Descripción de los resultados de las comprobaciones de estado del nodo
Una vez que una máquina virtual supera las comprobaciones de estado, pasará a la fase de configuración de software.
Si una máquina virtual produce un error en cualquiera de los scripts de comprobación de estado, se enviará un mensaje de error a CycleCloud y la máquina virtual se impedirá automáticamente unirse al clúster.
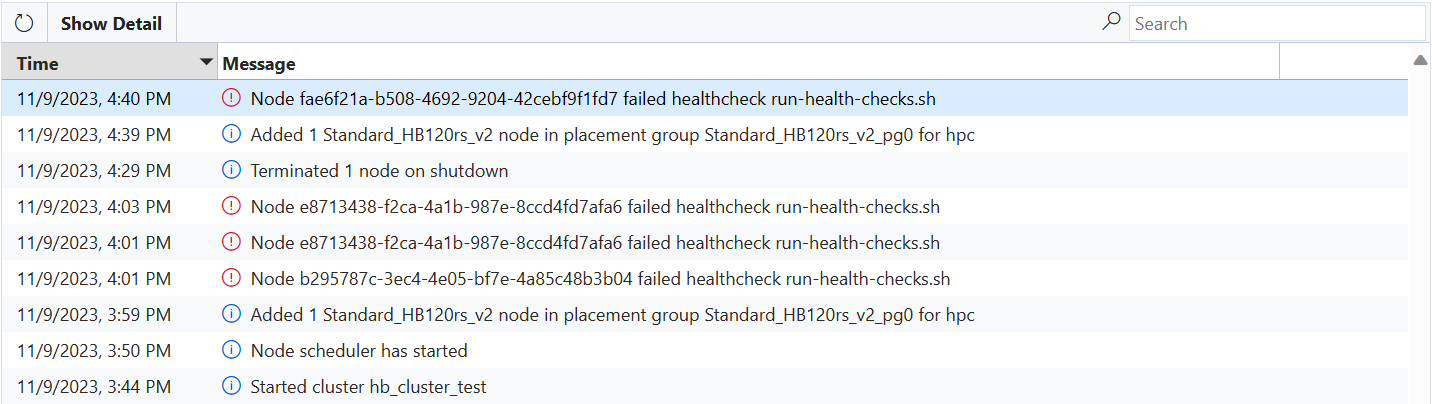
Si la máquina virtual se inicia en nodeArray con el aprovisionamiento excesivo habilitado (por ejemplo, la matriz de nodos hpc de Slurm), la máquina virtual se debe reemplazar automáticamente como parte del aprovisionamiento excesivo. En ese caso, no se requiere ninguna acción y se seleccionarán las máquinas virtuales correctas para unirse al clúster (aunque verá un mensaje de error en la página del clúster que indica que una o varias máquinas virtuales han producido errores).
Si la máquina virtual se inicia para un solo nodo, una matriz de nodos con exceso de aprovisionamiento deshabilitado (por ejemplo, la matriz de nodos Slurm htc) o si más máquinas virtuales producen comprobaciones de estado de las admitidas por el aprovisionamiento excesivo, el nodo pasará al estado Error y se producirá un error en la asignación. CycleCloud puede intentar volver a imagenar la máquina virtual para corregir el problema, pero si se produce un error en la nueva imagen, el nodo tendrá que terminarse y reemplazarse (manualmente por un administrador o automáticamente por el escalador automático).
Nota
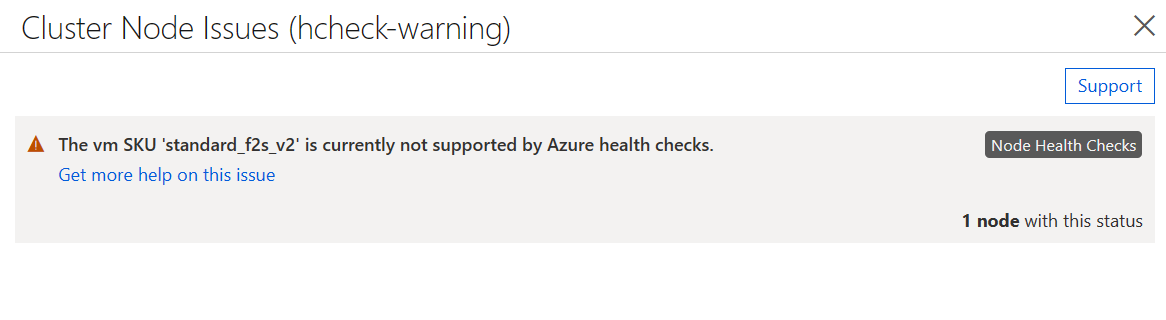
Si ha habilitado las comprobaciones de estado del nodo, pero la imagen de máquina virtual no cumple los requisitos anteriores, se permitirá que todas las máquinas virtuales se unan al clúster, pero el estado contendrá una advertencia que indica que no se admiten las comprobaciones.
Referencia de atributo
| Atributo | Tipo | Definición |
|---|---|---|
| EnableNodeHealthChecks | Boolean | (Opcional) Habilitar comprobaciones de estado del nodo de arranque para este nodo o matriz de nodos |
Healthcheck
Azure CycleCloud proporciona un mecanismo para terminar máquinas virtuales (VM) que están en un estado incorrecto denominado HealthCheck. Los scripts definidos por el sistema y el usuario (Python y Bash) se ejecutan periódicamente (5 minutos en Windows, 10 minutos en Linux) para determinar el estado general de una máquina virtual. HealthCheck permite a los administradores definir condiciones en las que se deben finalizar las máquinas virtuales sin tener que supervisar y corregir manualmente.
Scripts de HealthCheck integrados
Las máquinas virtuales habilitadas para CycleCloud incluyen dos scripts de HealthCheck predeterminados:
- El script converge_timeout finalizará una instancia que no haya finalizado la configuración de software en un plazo de cuatro horas después del inicio. Este período de tiempo de espera se puede controlar con la
cyclecloud.keepalive.timeoutconfiguración (definida en segundos). - El script de scheduled_shutdown busca archivos de creador en $JETPACK_HOME/run/scheduled_shutdown que contienen una sola línea que da un tiempo de apagado en segundos de marca de tiempo de Unix y una segunda línea opcional con una explicación. Cuando la hora actual es posterior a la marca de tiempo más antigua de los archivos, la máquina virtual se considera incorrecta.
Cómo funciona
Los scripts healthCheck se encuentran en el directorio $JETPACK_HOME/config/healthcheck.d . Linux admite scripts de Python y Bash, mientras que Windows solo admite scripts de Python. El script debe determinar el estado de la máquina virtual. Si se encuentra que la máquina virtual tiene un estado incorrecto, el script debe salir con un estado de 254, lo que indica a CycleCloud que la máquina virtual está en mal estado y debe finalizarse.
Cuando haya iniciado sesión en una máquina virtual que ejecute HealthCheck, puede impedir que la máquina virtual se apague mediante la ejecución del comando jetpack keepalive. En las instancias de Linux, puede especificar un período de tiempo en horas o forever mientras en Windows forever es la única opción.
Nota
Cuando se determina que una máquina virtual es incorrecta, el agente healthCheck realizará una solicitud para que CycleCloud finalice la máquina virtual, la máquina virtual nunca se apagará localmente a través shutdown del comando . En caso de que la máquina virtual no pueda comunicarse con CycleCloud, la máquina virtual permanecerá activa aunque esté en mal estado hasta que se pueda acceder a CycleCloud.
Ejemplo
Como ejemplo sencillo, escribiremos un script HealthCheck que garantizará que una máquina virtual Linux no esté activa durante más de 24 horas. Este script se podría usar para simular expulsiones de prioridad baja para probar cómo reacciona un flujo de trabajo a una máquina virtual expulsada. Este script se colocaría en /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Nota
Este script se puede colocar en una máquina virtual a través de CycleCloud Project o agregándolo directamente al crear una imagen personalizada.