Configuración de MLOps con Azure DevOps
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Azure Machine Learning permite la integración con la canalización de Azure DevOps para automatizar el ciclo de vida del aprendizaje automático. Algunas de las operaciones que puede automatizar son:
- Implementación de la infraestructura de Azure Machine Learning
- Preparación de datos (extracción, transformación, operaciones de carga)
- Entrenamiento de modelos de aprendizaje automático con escalabilidad horizontal y escalabilidad vertical a petición
- Implementación de modelos de Machine Learning como servicios web públicos o privados
- Supervisión de modelos de Machine Learning implementados (por ejemplo, para el análisis de rendimiento)
En este artículo, obtendrá información sobre el uso de Azure Machine Learning para configurar una canalización de MLOps de un extremo a otro que ejecuta una regresión lineal para predecir tarifas de taxi en Nueva York. La canalización se compone de componentes, cada uno de los cuales atiende diferentes funciones que se pueden registrar con el área de trabajo, el control de versiones y la reutilización con varias entradas y salidas. Va a usar la arquitectura de Azure recomendada para MLOps y el acelerador de soluciones de Azure MLOps (v2) para configurar rápidamente un proyecto de MLOps en Azure Machine Learning.
Sugerencia
Se recomienda comprender algunas de las arquitecturas de Azure recomendadas para MLOps antes de implementar cualquier solución. Deberá elegir la mejor arquitectura para el proyecto de Machine Learning determinado.
Requisitos previos
- Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
- Un área de trabajo de Azure Machine Learning.
- Git que se ejecuta en la máquina local.
- Una organización en Azure DevOps.
- Proyecto de Azure DevOps que hospedará los repositorios y canalizaciones de origen.
- La extensión de Terraform para Azure DevOps si usa Azure DevOps + Terraform para poner en marcha la infraestructura.
Nota
Se requiere la versión 2.27 de Git o posterior. Para obtener más información sobre cómo instalar el comando Git, consulte https://git-scm.com/downloads y seleccione el sistema operativo
Importante
Los comandos de la CLI de este artículo se probaron mediante Bash. Si usa un shell diferente, es posible que encuentre errores.
Configuración de la autenticación con Azure y DevOps
Para poder configurar un proyecto de MLOps con Azure Machine Learning, debe configurar la autenticación para Azure DevOps.
Creación de una entidad de servicio
Para el uso de la demostración, se requiere la creación de uno o dos principios de servicio, en función del número de entornos en los que quiera trabajar (desarrollo o producción, o ambos). Estos principios se pueden crear mediante uno de los métodos siguientes:
Inicie Azure Cloud Shell.
Sugerencia
La primera vez que inicie el Cloud Shell, se le pedirá que cree una cuenta de almacenamiento para el mismo.
Si se le solicita, elija Bash como entorno usado en el Cloud Shell. También puede cambiar los entornos de la lista desplegable de la barra de navegación superior
Copie los comandos de Bash siguientes en el equipo y actualice las variables projectName, subscriptionId y environment con los valores del proyecto. Si va a crear un entorno de desarrollo y producción, deberá ejecutar este script una vez para cada entorno, de forma que se crea una entidad de servicio para cada uno. Este comando también concederá el rol Colaborador a la entidad de servicio de la suscripción proporcionada. Esto es necesario para que Azure DevOps use correctamente los recursos de esa suscripción.
projectName="<your project name>" roleName="Contributor" subscriptionId="<subscription Id>" environment="<Dev|Prod>" #First letter should be capitalized servicePrincipalName="Azure-ARM-${environment}-${projectName}" # Verify the ID of the active subscription echo "Using subscription ID $subscriptionID" echo "Creating SP for RBAC with name $servicePrincipalName, with role $roleName and in scopes /subscriptions/$subscriptionId" az ad sp create-for-rbac --name $servicePrincipalName --role $roleName --scopes /subscriptions/$subscriptionId echo "Please ensure that the information created here is properly save for future use."Copie los comandos editados en Azure Shell y ejecútelos (Ctrl + Mayús + v).
Después de ejecutar estos comandos, se le presentará información relacionada con la entidad de servicio. Guarde esta información en una ubicación segura; se usará más adelante en la demostración para configurar Azure DevOps.
{ "appId": "<application id>", "displayName": "Azure-ARM-dev-Sample_Project_Name", "password": "<password>", "tenant": "<tenant id>" }Repita el Paso 3 si va a crear entidades de servicio para entornos de desarrollo y producción. Para esta demostración, vamos a crear solo un entorno, el de producción.
Cierre el Cloud Shell una vez creadas las entidades de servicio.
Configurar Azure DevOps
Vaya a Azure DevOps.
Seleccione Crear un nuevo proyecto (asigne un nombre al proyecto
mlopsv2para este tutorial).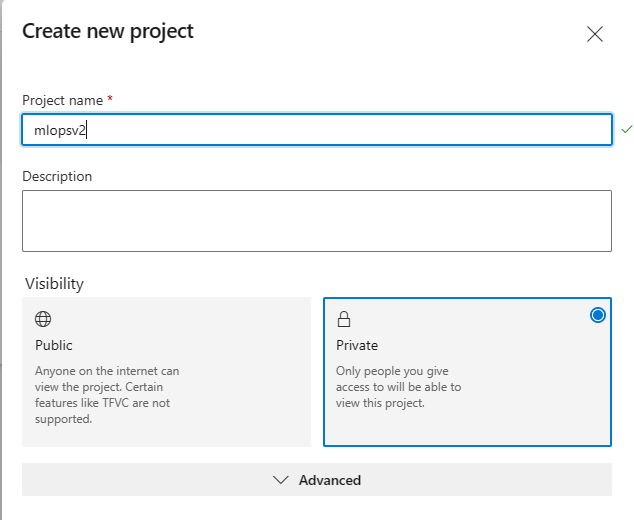
En el proyecto, en Configuración del proyecto (en la parte inferior izquierda de la página del proyecto), seleccione Conexiones de servicio.
Seleccione Crear conexión de servicio.
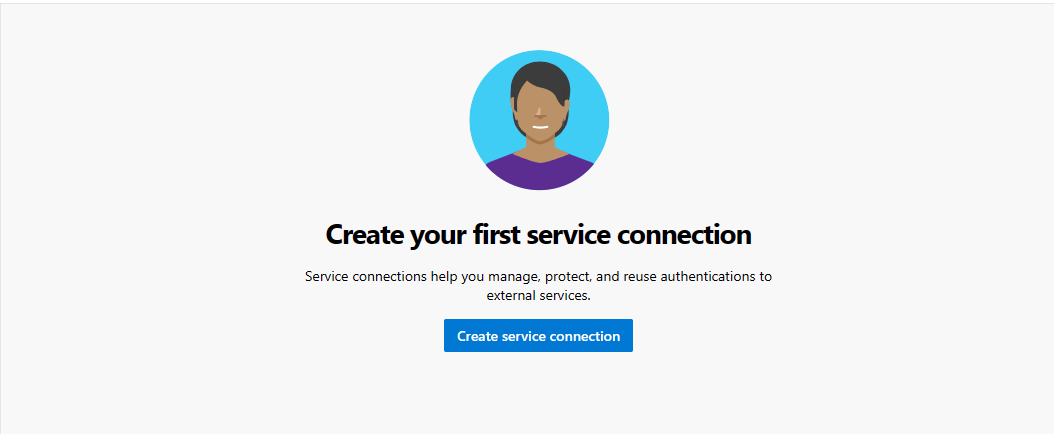
Seleccione Azure Resource Manager, seleccione Siguiente, seleccione Entidad de servicio (manual), seleccione Siguiente y seleccione el nivel de ámbito Suscripción.
- Nombre de la suscripción: use el nombre de la suscripción donde se almacena la entidad de servicio.
- Identificador de suscripción: Use el
subscriptionIdque usó en el Paso 1 entrada como id. de suscripción - Id. de entidad de servicio: use el
appIddel Paso 1 salida como id. de entidad de servicio - Clave de entidad de servicio: use la
passworddel Paso 1 salida como clave de entidad de servicio - Id. de inquilino: Use el
tenantdel Paso 1. salida como id. de inquilino
Nombre la conexión de servicio como Azure-ARM-Prod.
Seleccione Conceder permiso de acceso a todas las canalizaciones y, a continuación, seleccione Comprobar y guardar.
La configuración de Azure DevOps ha finalizado correctamente.
Configuración del repositorio de origen con Azure DevOps
Abra el proyecto que creó en Azure DevOps
Abra la sección Repos y seleccione Importar repositorio
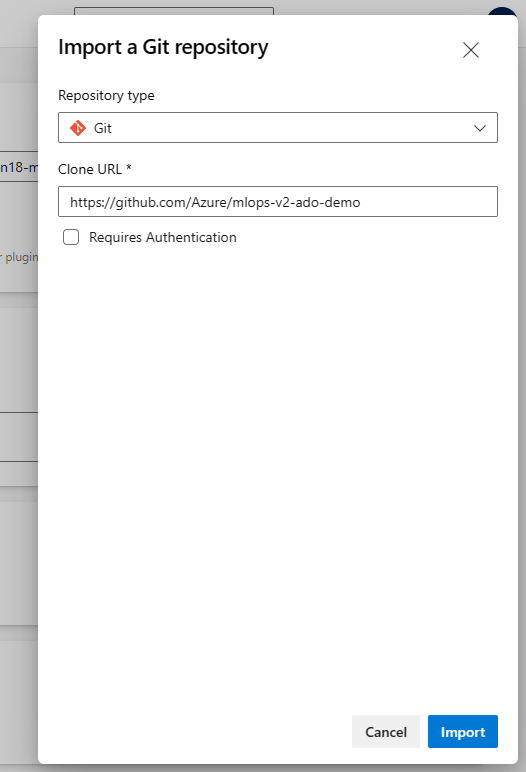
Escriba https://github.com/Azure/mlops-v2-ado-demo en el campo Dirección URL de clonación. Seleccione la opción de importación en la parte inferior de la página.
Abra la configuración del proyecto en la parte inferior del panel de navegación izquierdo
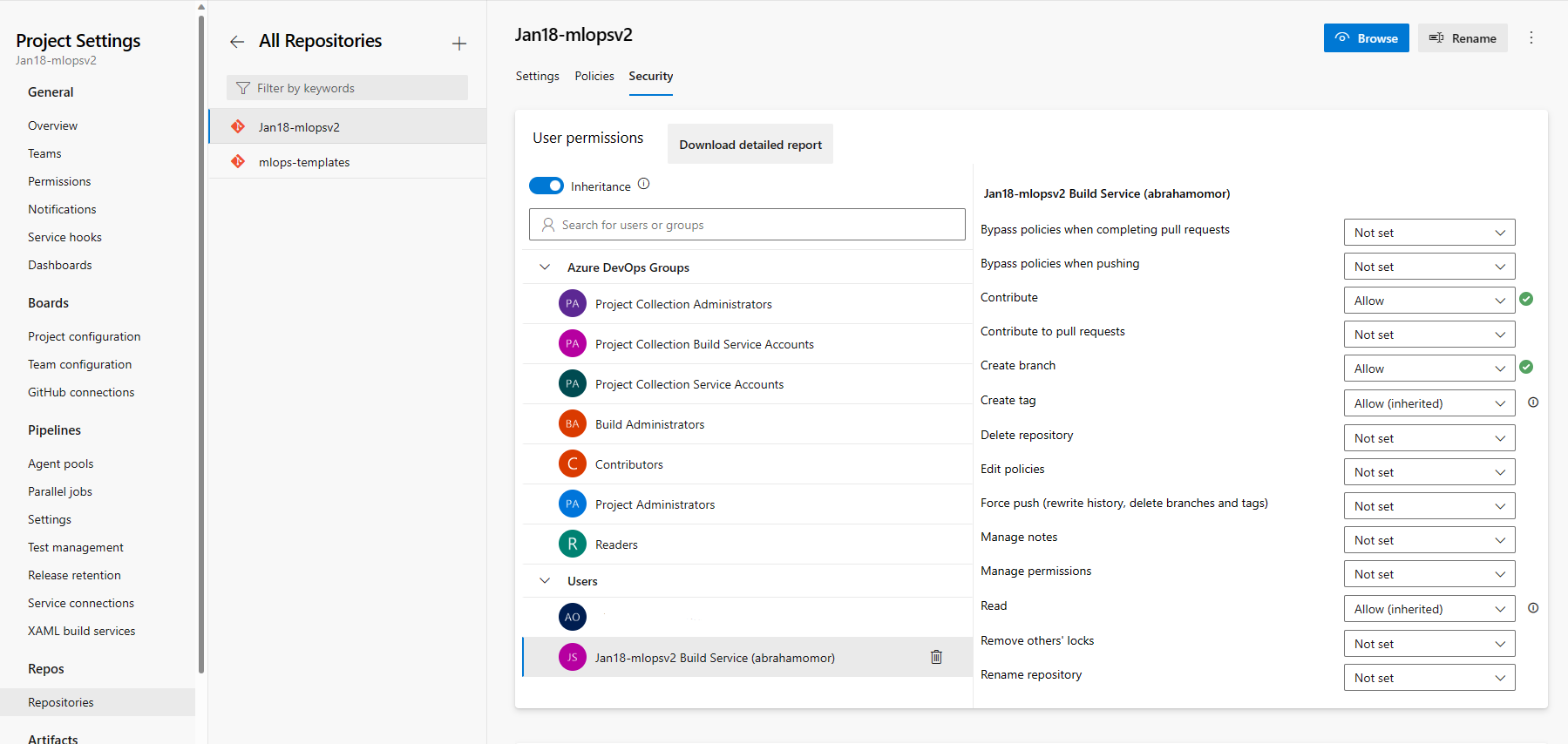
En la sección "Repositorios", seleccione Repositorios. Seleccione el repositorio que creó en el paso anterior Seleccione la pestaña Seguridad
En la sección Permisos de usuario, seleccione el usuario mlopsv2 Build Service. Cambie el permiso Contribuir a Permitir y el permiso Crear rama a Permitir.
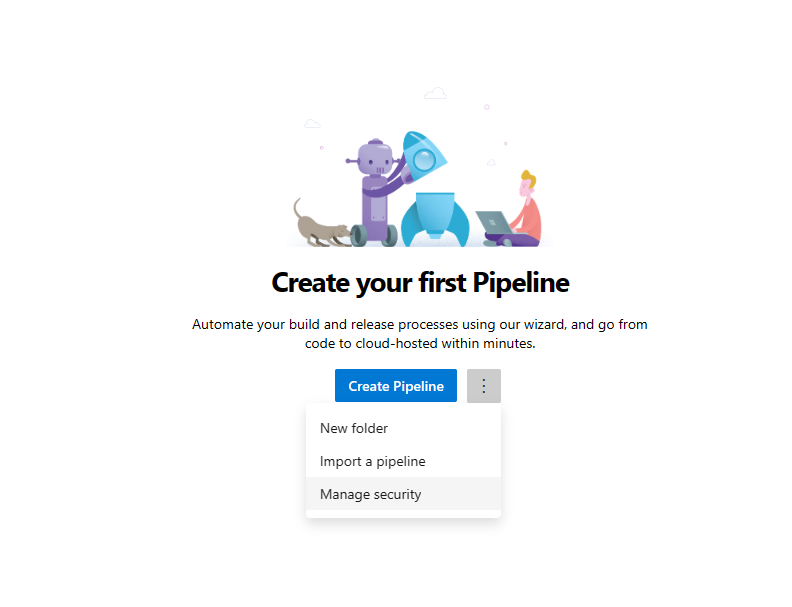
Abra la sección Canalizaciones en el panel de navegación izquierdo y seleccione los 3 puntos verticales situados junto al botón Crear canalizaciones. Vaya a Administrar seguridad
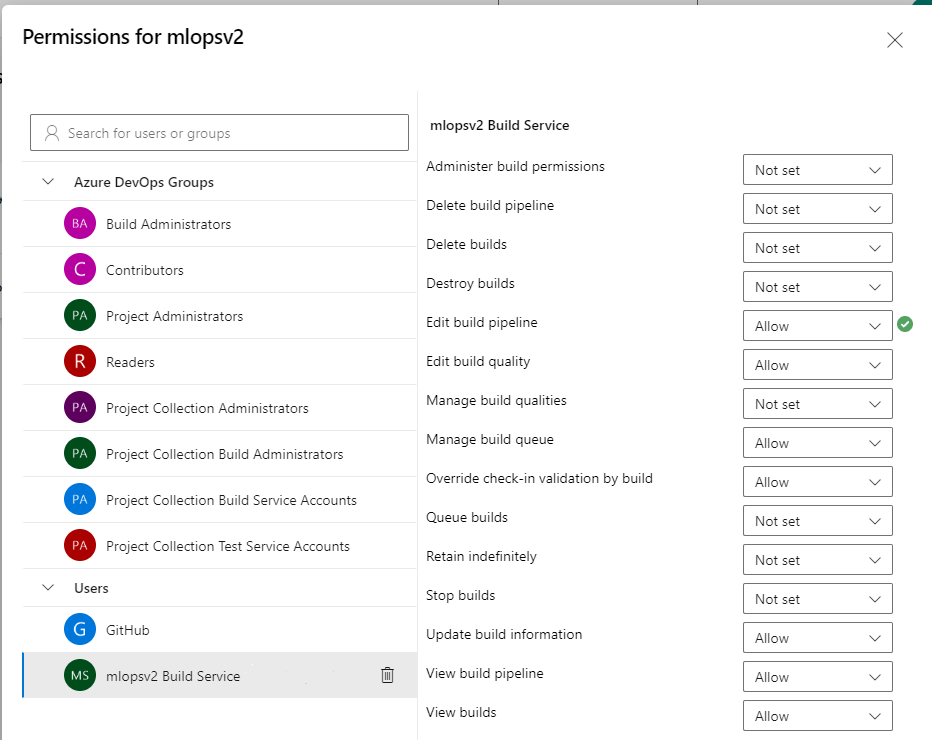
Seleccione la cuenta del servicio de compilación de mlopsv2 para el proyecto en la sección Usuarios. Cambie el permiso Edit build pipeline (Editar canalización de compilación) a Permitir
Nota:
Esto finaliza la sección de requisitos previos y la implementación del acelerador de soluciones puede producirse en consecuencia.
Implementación de la infraestructura mediante Azure DevOps
En este paso se implementa la canalización de entrenamiento en el área de trabajo de Azure Machine Learning creada en los pasos anteriores.
Sugerencia
Asegúrese de comprender los patrones arquitectónicos del acelerador de soluciones antes de desproteger el repositorio de MLOps v2 e implementar la infraestructura. En los ejemplos, usará el tipo de proyecto de ML clásico.
Ejecución de la canalización de infraestructuras de Azure
Vaya al repositorio,
mlops-v2-ado-demo, y seleccione el archivo config-infra-prod.yml.Importante
Asegúrese de que ha seleccionado la rama principal del repositorio.
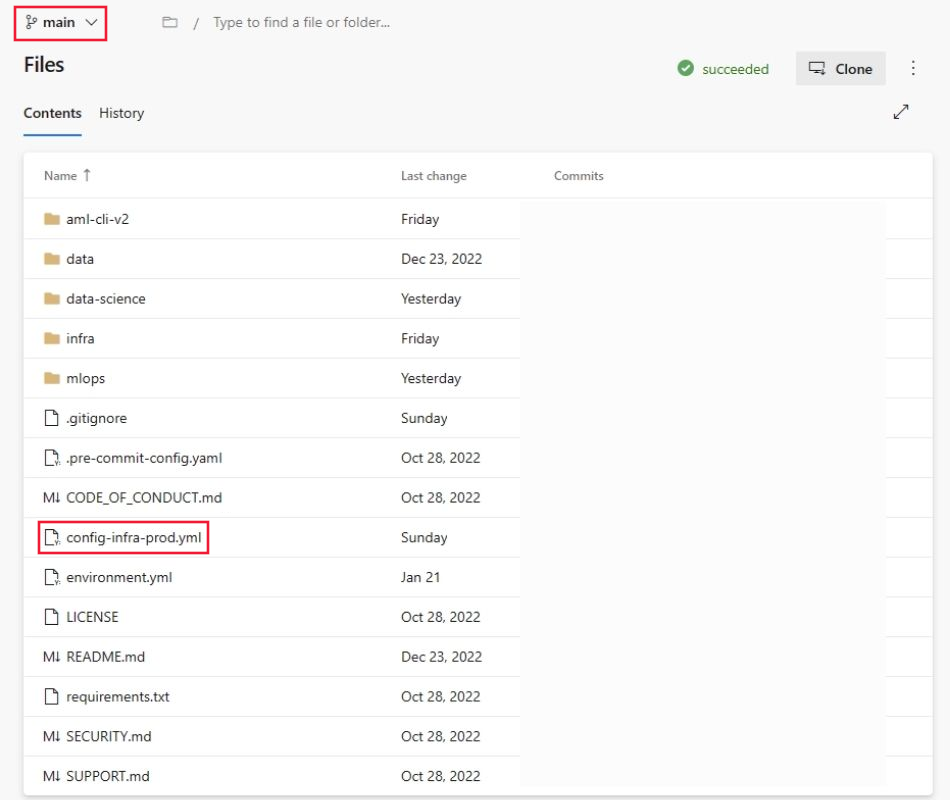
Este archivo de configuración usa el espacio de nombres y los valores de postfijos de los nombres de los artefactos para garantizar la exclusividad. Actualice la sección siguiente de la configuración a su gusto.
namespace: [5 max random new letters] postfix: [4 max random new digits] location: eastusNota:
Si ejecuta una carga de trabajo de aprendizaje profundo, como CV o NLP, asegúrese de que el proceso de GPU esté disponible en la zona de implementación.
Seleccione "Confirmar" e inserte código para introducir estos valores en la canalización.
Vaya a la sección Canalizaciones
Seleccione Crear canalización.
Seleccione Git de Azure Repos.
Seleccione el repositorio que ha clonado en la sección anterior
mlops-v2-ado-demoSeleccione Archivo YAML de Azure Pipelines existente
Seleccione la rama
mainy elijamlops/devops-pipelines/cli-ado-deploy-infra.yml; a continuación, seleccione Continuar.Ejecute la canalización; tardará unos minutos en finalizar. La canalización debe crear los siguientes artefactos:
- Grupo de recursos para el área de trabajo, incluida la cuenta de almacenamiento, Container Registry, Application Insights, Keyvault y el propio área de trabajo de Azure Machine Learning.
- En el área de trabajo, también hay un clúster de proceso creado.
Ahora se implementa la infraestructura del proyecto de MLOps.
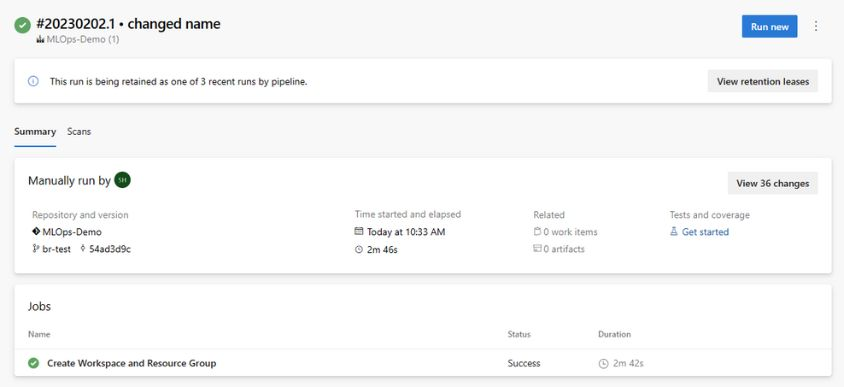
Nota:
Es posible que se ignoren las advertencias de no poder mover y reutilizar el repositorio existente a la ubicación requerida.
Escenario de entrenamiento e implementación de ejemplo
El acelerador de soluciones incluye código y datos para una canalización de aprendizaje automático de un extremo a otro de ejemplo que ejecuta una regresión lineal para predecir tarifas de taxi en Nueva York. La canalización se compone de componentes, cada uno de los cuales atiende diferentes funciones que se pueden registrar con el área de trabajo, el control de versiones y la reutilización con varias entradas y salidas. Las canalizaciones y flujos de trabajo de ejemplo para los escenarios de Computer Vision y NLP tendrán diferentes pasos y pasos de implementación.
Esta canalización de entrenamiento contiene los pasos siguientes:
Preparar los datos
- Este componente toma varios conjuntos de datos de taxi (amarillo y verde) y combina o filtra los datos y prepara los conjuntos de datos de entrenamiento/val y evaluación.
- Entrada: datos locales en ./data/ (varios archivos de .csv)
- Salida: conjunto de datos preparado único (.csv) y conjuntos de datos entrenamiento/val/prueba.
Train Model (entrenar modelo)
- Este componente entrena un regresor lineal con el conjunto de formación.
- Entrada: datos de entrenamiento
- Salida: modelo entrenado (formato pickle)
Evaluación de módulo
- Este componente usa el modelo entrenado para predecir tarifas de taxi en el conjunto de pruebas.
- Entrada: modelo de ML y conjunto de datos de prueba
- Salida: rendimiento del modelo y una marca de implementación para implementar o no.
- Este componente compara el rendimiento del modelo con todos los modelos previamente implementados en el nuevo conjunto de datos de prueba y decide si promover o no el modelo en producción. La promoción del modelo en producción se produce al registrar el modelo en el área de trabajo de AML.
Registro del modelo
- Este componente puntúa el modelo en función de la precisión de las predicciones en el conjunto de pruebas.
- Entrada: modelo entrenado y la marca de implementación.
- Salida: modelo registrado en Azure Machine Learning.
Implementación de la canalización de entrenamiento de modelos
Ir a canalizaciones de ADO
Seleccione Nueva canalización.

Seleccione Git de Azure Repos.
Seleccione el repositorio que ha clonado en la sección anterior
mlopsv2Seleccione Archivo YAML de Azure Pipelines existente
Seleccione
maincomo una rama y elija/mlops/devops-pipelines/deploy-model-training-pipeline.yml; a continuación, seleccione Continuar.Guarde y ejecute la canalización
Nota:
En este punto, se configura la infraestructura y se despliega el bucle de creación de prototipos de la arquitectura de MLOps. Está listo para pasar a nuestro modelo entrenado a producción.
Implementación del modelo entrenado
Este escenario incluye flujos de trabajo precompilados para dos enfoques para implementar un modelo entrenado, una puntuación por lotes o una implementación de un modelo en un punto de conexión para la puntuación en tiempo real. Puede ejecutar uno o ambos flujos de trabajo para probar el rendimiento del modelo en el área de trabajo de Azure Machine Learning. En este ejemplo, usaremos la puntuación en tiempo real.
Implementación del punto de conexión del modelo de Machine Learning
Ir a canalizaciones de ADO
Seleccione Nueva canalización.
Seleccione Git de Azure Repos.
Seleccione el repositorio que ha clonado en la sección anterior
mlopsv2Seleccione Archivo YAML de Azure Pipelines existente
Seleccione la rama
mainy elija el punto de conexión en línea administrado/mlops/devops-pipelines/deploy-online-endpoint-pipeline.yml; luego, seleccione Continuar.Los nombres de punto de conexión en línea deben ser únicos, por lo que debe cambiar
taxi-online-$(namespace)$(postfix)$(environment)por otro nombre exclusivo y, luego, seleccionar Ejecutar. No es necesario cambiar el valor predeterminado si no se produce un error.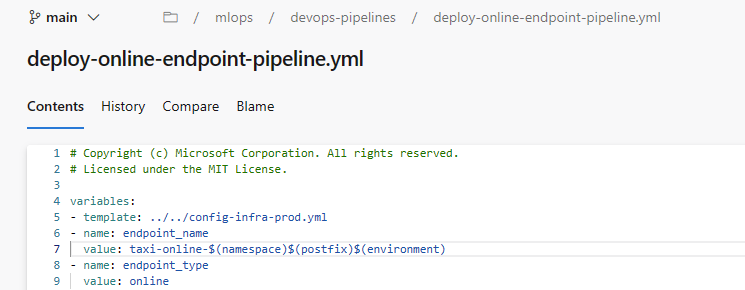
Importante
Si se produce un error en la ejecución debido a un nombre de punto de conexión en línea existente, vuelva a crear la canalización como se ha descrito anteriormente y cambie [el nombre del punto de conexión] a [el nombre del punto de conexión (número aleatorio)]
Cuando se complete la ejecución, verá una salida similar a la siguiente imagen:
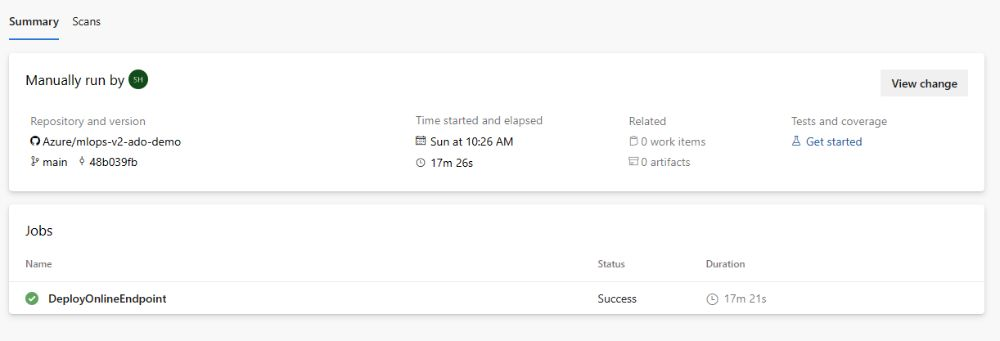
Para probar esta implementación, vaya a la pestaña Puntos de conexión del área de trabajo de Azure Machine Learning, seleccione el punto de conexión y haga clic en la pestaña Prueba. Puede usar los datos de entrada de ejemplo ubicados en el repositorio clonado en
/data/taxi-request.jsonpara probar el punto de conexión.
Limpieza de recursos
- Si no va a seguir usando la canalización, elimine el proyecto de Azure DevOps.
- En Azure Portal, elimine el grupo de recursos y la instancia de Azure Machine Learning.
Pasos siguientes
- Instalación y configuración del SDK v2 de Python
- Instalación y configuración del Python CLI v2
- Acelerador de soluciones de Azure MLOps (v2) en GitHub
- Curso de aprendizaje sobre MLOps con Machine Learning
- Más información sobre Azure Pipelines con Azure Machine Learning
- Más información sobre Acciones de GitHub con Azure Machine Learning
- Implementación de MLOps en Azure en menos de una hora: vídeo de Community MLOps V2 Accelerator