Conceptos de alta disponibilidad en Azure Database for MySQL con servidor flexible
SE APLICA A:  Azure Database for MySQL: servidor flexible
Azure Database for MySQL: servidor flexible
Servidor flexible de Azure Database for MySQL permite configurar la alta disponibilidad con conmutación automática por error. La solución de alta disponibilidad está diseñada para garantizar que los datos confirmados nunca se pierdan debido a errores y que la base de datos no sea un único punto de error de la arquitectura de software. Cuando se configura la alta disponibilidad, la opción Servidor flexible aprovisiona y administra automáticamente una réplica en espera. Se le facturará por el proceso y el almacenamiento aprovisionados para la réplica principal y secundaria. Hay dos modelos arquitectónicos de alta disponibilidad:
Alta disponibilidad con redundancia de zona. Esta opción es preferible para el aislamiento completo y la redundancia de la infraestructura en varias zonas de disponibilidad. Proporciona el máximo nivel de disponibilidad, pero exige configurar la redundancia de las aplicaciones entre zonas. La alta disponibilidad con redundancia de zona es preferible cuando se quiere lograr el máximo nivel de disponibilidad frente a cualquier error de infraestructura en la zona de disponibilidad y cuando la latencia entre las zonas de disponibilidad es aceptable. Solo se puede habilitar cuando se crea el servidor. La alta disponibilidad con redundancia de zona está disponible en un subconjunto de regiones de Azure que admiten varias zonas de disponibilidad y donde hay disponibles recursos compartidos de archivos Premium con redundancia de zona.
Alta disponibilidad en la misma zona. Esta opción es preferible para la redundancia de infraestructura con menor latencia de red, ya que el servidor principal y el servidor en espera estarán en la misma zona de disponibilidad. Proporciona alta disponibilidad sin necesidad de configurar la redundancia de las aplicaciones entre zonas. La alta disponibilidad en la misma zona se prefiere cuando se quiere lograr el máximo nivel de disponibilidad dentro de una sola zona de disponibilidad con la mínima latencia de red. La alta disponibilidad en la misma zona está disponible en todas las regiones de Azure donde es posible utilizar el servidor flexible de Azure Database for MySQL.
Arquitectura de alta disponibilidad con redundancia de zona
Al implementar un servidor con alta disponibilidad con redundancia de zona, se crearán dos servidores:
- Un servidor principal en una zona de disponibilidad.
- Un servidor de réplica en espera que tiene la misma configuración que el servidor principal (nivel y tamaño de proceso, tamaño de almacenamiento y configuración de red) en otra zona de disponibilidad de la misma región de Azure.
Puede elegir la zona de disponibilidad para el servidor principal y la réplica en espera. La colocación de los servidores de bases de datos en espera y las aplicaciones en espera en la misma zona reduce la latencia. También permite prepararse mejor para situaciones de recuperación ante desastres y escenarios de "zona fuera de servicio".
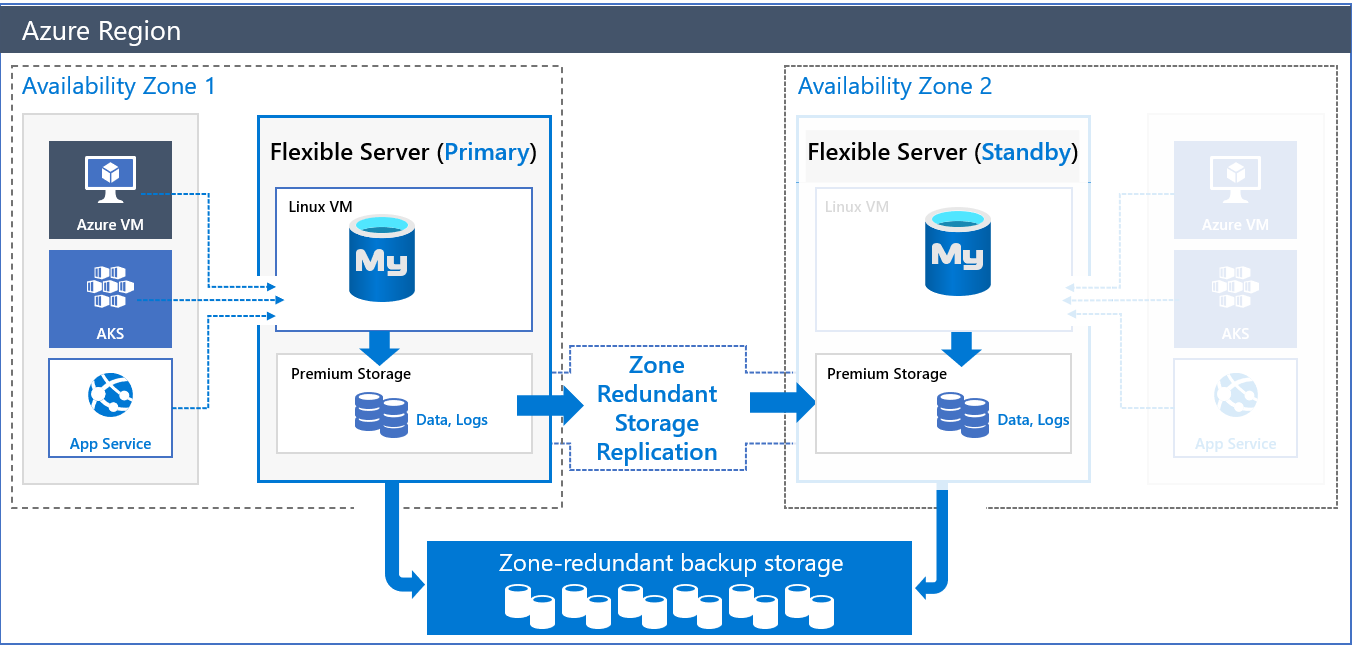
Los datos y los archivos de registro se hospedan en un almacenamiento con redundancia de zona (ZRS). El servidor en espera lee y reproduce los archivos de registro continuamente desde la cuenta de almacenamiento del servidor principal, que está protegida por la replicación de nivel de almacenamiento.
Si se produce una conmutación por error:
- Se activa la réplica en espera.
- Los archivos de registro binarios del servidor principal se siguen aplicando al servidor en espera para conectarlo a la última transacción confirmada en el servidor principal.
En ZRS, los registros son accesibles incluso cuando el servidor principal no está disponible. Esta disponibilidad ayuda a garantizar que no se pierdan datos. Una vez que se activa la réplica en espera y se aplican los registros binarios, el servidor de réplica en espera actual toma el rol del servidor principal. Se actualiza el DNS para que las conexiones del cliente se dirijan a la nueva réplica principal cuando el cliente se vuelva a conectar. La conmutación por error es totalmente transparente desde la aplicación cliente y no requiere ninguna acción por su parte. A continuación, en cuanto es posible, la solución de alta disponibilidad reactiva el servidor principal antiguo y lo coloca como servidor en espera.
Se utiliza el nombre del servidor de bases de datos para conectar las aplicaciones al servidor principal. La información de la réplica en espera no se expone para el acceso directo. Las confirmaciones y escrituras se confirman una vez que los archivos de registro se vacíen en el almacenamiento ZRS del servidor principal. Debido a la tecnología de replicación de sincronización que se usa en el almacenamiento ZRS, las aplicaciones pueden esperar un aumento de entre el 5 % y el 10 % de la latencia en las escrituras y confirmaciones.
Las copias de seguridad automáticas, tanto las de instantáneas como las de registros, se realizan en un almacenamiento con redundancia de zona desde el servidor de bases de datos principal.
Arquitectura de alta disponibilidad en la misma zona
Al implementar un servidor con alta disponibilidad en la misma zona, se crearán dos servidores en la misma zona:
- Un servidor principal
- Un servidor de réplica en espera que tiene la misma configuración que el servidor principal (nivel y tamaño de proceso, tamaño de almacenamiento y configuración de red).
El servidor en espera ofrece redundancia de infraestructura con una máquina virtual independiente (proceso). Esta redundancia reduce el tiempo de conmutación por error y la latencia de red entre la aplicación y el servidor de bases de datos debido a la coubicación.
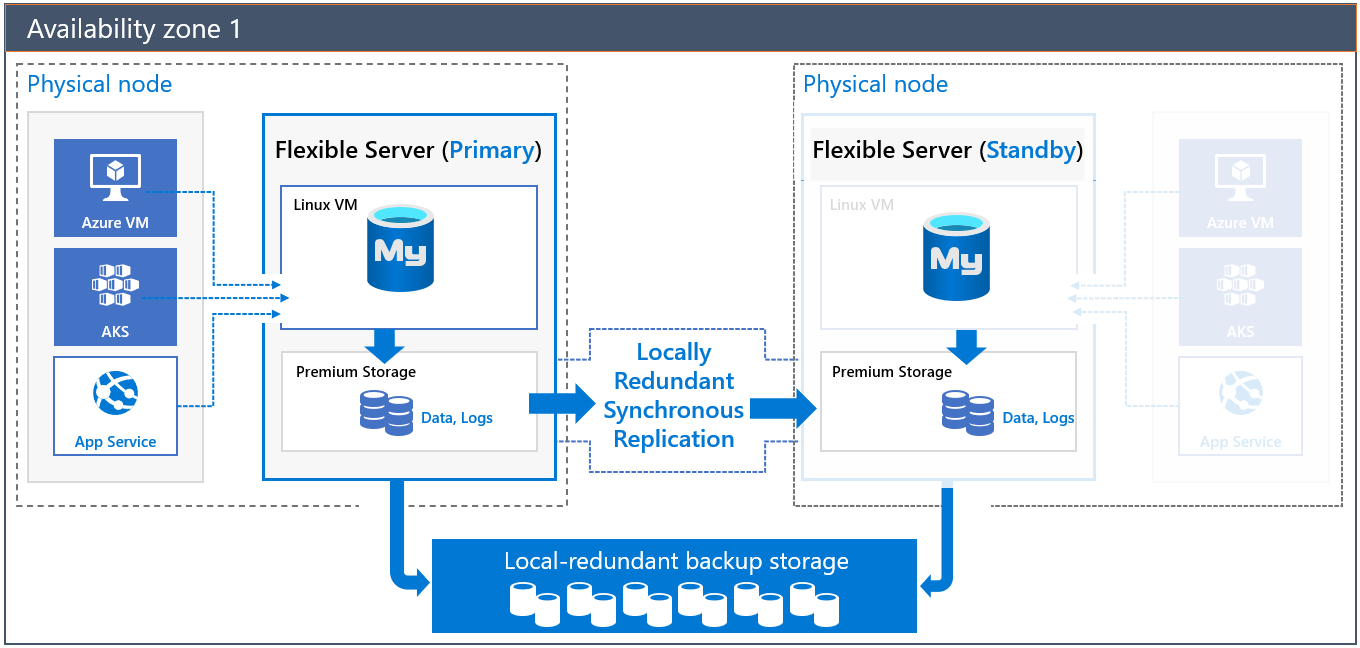
Los datos y los archivos de registro se hospedan en un almacenamiento con redundancia local (LRS). El servidor en espera lee y reproduce los archivos de registro continuamente desde la cuenta de almacenamiento del servidor principal, que está protegida por la replicación de nivel de almacenamiento.
Si se produce una conmutación por error:
- Se activa la réplica en espera.
- Los archivos de registro binarios del servidor principal se siguen aplicando al servidor en espera para conectarlo a la última transacción confirmada en el servidor principal.
En LRS, los registros son accesibles incluso cuando el servidor principal no está disponible. Esta disponibilidad ayuda a garantizar que no se pierdan datos. Una vez que se activa la réplica en espera y se aplican los registros binarios, la réplica en espera actual toma el rol del servidor principal. Se actualiza el DNS para redirigir las conexiones a la nueva réplica principal cuando el cliente se vuelve a conectar. La conmutación por error es totalmente transparente desde la aplicación cliente y no requiere ninguna acción por su parte. A continuación, en cuanto es posible, la solución de alta disponibilidad reactiva el servidor principal antiguo y lo coloca como servidor en espera.
Se utiliza el nombre del servidor de bases de datos para conectar las aplicaciones al servidor principal. La información de la réplica en espera no se expone para el acceso directo. Las confirmaciones y escrituras se confirman una vez que los archivos de registro se vacíen en el almacenamiento LRS del servidor principal. Dado que la réplica principal y la réplica en espera están en la misma zona, hay menos retraso de replicación y menor latencia entre el servidor de aplicaciones y el servidor de bases de datos. La configuración en la misma zona no proporciona alta disponibilidad en el escenario en que las infraestructuras dependientes quedan sin servicio en la zona de disponibilidad en cuestión. Habrá un tiempo de inactividad hasta que todos los servicios dependientes vuelvan a estar en línea en esa zona de disponibilidad.
Las copias de seguridad automáticas, tanto las de instantáneas como las de registros, se realizan en un almacenamiento con redundancia local desde el servidor de bases de datos principal.
Nota
Para la alta disponibilidad, tanto con redundancia de zona como en la misma zona:
- Si se produce un error, el tiempo necesario para que la réplica en espera asuma el rol principal depende del tiempo necesario que se tarda en reproducir el registro binario desde la cuenta de almacenamiento principal al servidor en espera. Por lo tanto, se recomienda usar claves principales en todas las tablas para reducir el tiempo de conmutación por error. Los tiempos de conmutación por error suelen oscilar entre 60 y 120 segundos.
- El servidor en espera no está disponible para operaciones de lectura o escritura. Es un modo de espera pasivo para permitir una conmutación por error rápida.
- Use siempre un nombre de dominio completo (FQDN) para conectarse al servidor principal. Evite usar una dirección IP para conectarse. Si se produce una conmutación por error, después de intercambiar los roles del servidor principal y en espera, podría cambiar el registro A de DNS. Ese cambio impedirá que la aplicación se conecte al nuevo servidor principal si se usa la dirección IP en la cadena de conexión.
Proceso de conmutación por error
Planeado: conmutación por error forzada
La conmutación por error forzada del servidor flexible de Azure Database for MySQL permite forzar manualmente una conmutación por error. Esto le permite probar la funcionalidad con los escenarios de la aplicación y le ayuda a prepararse para las interrupciones.
La conmutación por error forzada desencadena una conmutación por error que activa la réplica en espera para que se convierta en el servidor principal con el mismo nombre de servidor de bases de datos al actualizar el registro de DNS. El servidor principal original se reinicia y se cambia a réplica en espera. Las conexiones de cliente se desconectan y deben volver a conectarse para reanudar sus operaciones.
El tiempo total de la conmutación por error depende de la carga de trabajo actual y del último punto de control. En general, se espera que tarde entre 60 y 120 segundos.
Nota:
El evento de Azure Resource Health se genera en caso de conmutación por error planeada, que representa el tiempo de conmutación por error durante el cual el servidor no estaba disponible. Los eventos desencadenados se pueden ver al hacer clic en "Resource Health" en el panel izquierdo. La conmutación por error manual/ iniciada por el usuario se representa mediante el estado "No disponible" y se etiqueta como "Planeada". Ejemplo: "Un usuario autorizado (planeado) desencadenó una operación de conmutación por error". Si el recurso permanece en este estado durante un período de tiempo prolongado, abra una incidencia de soporte técnico y le ayudaremos.
No planeado: conmutación automática por error
El tiempo de inactividad no planeado del servicio puede deberse a errores de software o errores de infraestructura, como errores de proceso, red o almacenamiento, o a interrupciones de energía que afectan a la disponibilidad de la base de datos. Si la base de datos deja de estar disponible, la replicación en la réplica en espera se anula y la réplica en espera se activa para ser la base de datos principal. Se actualiza el DNS y los clientes se vuelven a conectar al servidor de bases de datos y reanudan sus operaciones.
Se espera que el tiempo total de la conmutación por error esté entre 60 y 120 segundos. Pero en función de la actividad del servidor de bases de datos principal en el momento de la conmutación por error (como las transacciones de gran tamaño y el tiempo de recuperación), la conmutación por error puede tardar más.
Nota:
El evento de Azure Resource Health se genera en caso de conmutación por error no planeada, que representa el tiempo de conmutación por error durante el cual el servidor no estaba disponible. Los eventos desencadenados se pueden ver al hacer clic en "Resource Health" en el panel izquierdo. La conmutación automática por error se representa mediante el estado "No disponible" y se etiqueta como "No planeada". Ejemplo: "No disponible: se desencadenó automáticamente una operación de conmutación por error (no planeada)". Si el recurso permanece en este estado durante un período de tiempo prolongado, abra una incidencia de soporte técnico y le ayudaremos.
Funcionamiento de la detección de conmutación automática por error en servidores habilitados para alta disponibilidad
El servidor principal y el servidor secundario tienen dos puntos de conexión de red:
- Punto de conexión de cliente: el cliente conecta y ejecuta la consulta en la instancia mediante este punto de conexión.
- Punto de conexión de administración: se usa internamente para las comunicaciones de servicio a los componentes de administración y para conectarse al almacenamiento de back-end.
El componente monitor de estado realiza continuamente las siguientes comprobaciones:
- El monitor hace ping a los nodos de punto de conexión de la red de administración. Si se produce un error en esta comprobación dos veces consecutivas, se desencadena la operación de conmutación automática por error. Los escenarios en los que el nodo no está disponible o no responde debido a un problema del sistema operativo, en los que hay problemas de red entre los componentes de administración y los nodos, etc., se solucionarán mediante esta comprobación de estado.
- El monitor también ejecuta una consulta sencilla en la instancia. Si las consultas no se ejecutan, se desencadenará la conmutación automática por error. Esta comprobación de estado solucionará los escenarios en los que el demonio de MySQL se bloquea o se detiene, en los que hay problemas de almacenamiento de back-end, etc.
Nota
Si hay algún problema de red entre la aplicación y el punto de conexión de red del cliente (acceso privado o público), ya sea en la ruta de acceso de red, en el punto de conexión o problemas de DNS en el lado cliente, la comprobación de estado no supervisa este escenario. Si usa acceso privado, asegúrese de que las reglas del grupo de seguridad de red de la red virtual no bloquean la comunicación con el punto de conexión de red del cliente de la instancia en el puerto 3306. Para el acceso público, asegúrese de que las reglas de firewall estén establecidas y que se permita el tráfico de red en el puerto 3306 (si la ruta de acceso de red tiene otros firewalls). También debe prestarse atención a la resolución DNS del lado de la aplicación cliente.
Supervisión de la alta disponibilidad
El Estado de alta disponibilidad ubicado en el panel Alta disponibilidad del servidor en el portal se puede usar para determinar el estado de configuración de alta disponibilidad del servidor.
| Estado | Descripción |
|---|---|
| NotEnabled | La alta disponibilidad no está habilitada. |
| ReplicatingData | El servidor en espera está en proceso de sincronizarse con el servidor principal en el momento del aprovisionamiento del servidor de alta disponibilidad o cuando la opción de alta disponibilidad está habilitada. |
| FailingOver | El servidor de bases de datos está en proceso de conmutar por error desde el principal al de espera. |
| Healthy | La opción de alta disponibilidad está habilitada. |
| RemovingStandby | Cuando la opción de alta disponibilidad está deshabilitada y el proceso de eliminación está en curso. |
También puede usar las métricas siguientes para supervisar el estado del servidor de alta disponibilidad.
| Nombre para mostrar de la métrica | Métrica | Unidad | Descripción |
|---|---|---|---|
| Estado de E/S de alta disponibilidad | ha_io_running | State | Estado de E/S de alta disponibilidad indica el estado de replicación de alta disponibilidad. El valor de métrica es 1 si el subproceso de E/S se está ejecutando y 0 si no lo está. |
| Estado de SQL de alta disponibilidad | ha_sql_running | State | El estado de SQL de alta disponibilidad indica el estado de replicación de alta disponibilidad. El valor de métrica es 1 si el subproceso de SQL se está ejecutando y 0 si no lo está. |
| Intervalo de replicación de alta disponibilidad | replication_lag | Segundos | El retraso de replicación es el número de segundos en que el modo de espera está detrás de la reproducción de las transacciones recibidas en el servidor principal. |
Limitaciones
Estas son algunas consideraciones que se deben tener en cuenta al usar la alta disponibilidad:
- La alta disponibilidad con redundancia de zona solo se puede establecer cuando se crea el servidor flexible.
- La alta disponibilidad no se admite en el nivel de proceso ampliable.
- Al reiniciar el servidor de bases de datos principal para elegir los cambios de los parámetros estáticos también se reinicia la réplica en espera.
- Se activará el modo GTID, ya que la solución de alta disponibilidad usa GTID. Compruebe si la carga de trabajo tiene restricciones o limitaciones en cuanto a la replicación con GTID.
Nota:
Si va a habilitar la alta disponibilidad en la misma zona para publicar la creación del servidor, debe asegurarse de que los parámetros del servidor "enforce_gtid_consistency" y "gtid_mode" estén activados antes de habilitar la alta disponibilidad.
Nota:
El crecimiento automático de almacenamiento está habilitado de forma predeterminada para un servidor configurado de alta disponibilidad y no se puede deshabilitar.
Preguntas más frecuentes
¿Cuáles son los Acuerdos de Nivel de Servicio para el servidor flexible habilitado para alta disponibilidad en la misma zona o con redundancia de zona?
La información del Acuerdo de Nivel de Servicio para el servidor flexible de Azure Database for MySQL se puede encontrar en Acuerdo de Nivel de Servicio para Azure Database for MySQL.
¿Cómo se facturan los servidores de alta disponibilidad? Los servidores habilitados con alta disponibilidad tienen una réplica principal y secundaria. La réplica secundaria puede estar en la misma zona o tener redundancia de zona. Se le facturará por el proceso y el almacenamiento aprovisionados para la réplica principal y secundaria. Por ejemplo, si tiene una réplica principal con 4 núcleos virtuales de proceso y 512 GB de almacenamiento aprovisionado, la réplica secundaria también tendrá 4 núcleos virtuales y 512 GB de almacenamiento aprovisionado. El servidor de alta disponibilidad con redundancia de zona se facturará por 8 núcleos virtuales y 1024 GB de almacenamiento. Dependiendo del volumen de almacenamiento de copia de seguridad, también se le puede facturar por el almacenamiento de copia de seguridad.
¿Puedo usar la réplica en espera para operaciones de lectura o escritura?
El servidor en espera no está disponible para operaciones de lectura o escritura. Es un modo de espera pasivo para permitir una conmutación por error rápida.¿Se produce alguna pérdida de datos en caso de conmutación por error?
En ZRS, los registros son accesibles incluso cuando el servidor principal no está disponible. Esta disponibilidad ayuda a garantizar que no se pierdan datos. Una vez que se activa la réplica en espera y se aplican los registros binarios, esta adopta los roles del servidor principal.¿Es necesario realizar alguna acción después de una conmutación por error?
Las conmutaciones por error son totalmente transparentes desde la aplicación cliente. No tiene que realizar ninguna acción. La aplicación solo debe utilizar una lógica de reintento para sus conexiones.¿Qué ocurre cuando no elijo una zona específica para mi réplica en espera? ¿Puedo cambiar la zona más adelante?
Si no elige una zona, se seleccionará una aleatoriamente. Será la que se usa para el servidor principal. Para cambiar la zona más adelante, puede establecer Alta disponibilidad en Deshabilitado en el panel Alta disponibilidad y luego volver a establecerlo en Redundancia de zona y seleccionar una zona.¿La replicación entre la réplica principal y la réplica en espera es sincrónica?
La replicación entre las réplicas principal y en espera es similar al modo semisincrónico de MySQL. Cuando se confirma una transacción, no se confirma necesariamente en la réplica en espera. Pero cuando la principal no está disponible, la réplica en espera replica todos los cambios de datos de la principal para asegurarse de que no haya pérdida de datos.¿Se conmuta por error en la réplica en espera en caso de errores no planeados?
Si hay un bloqueo en la base de datos o un error del nodo, la máquina virtual del servidor flexible se reinicia en el mismo nodo. Al mismo tiempo, se desencadena una conmutación automática por error. Si el reinicio de la máquina virtual del servidor flexible se realiza correctamente antes de que finalice la conmutación por error, se cancelará la operación de conmutación por error. La determinación del servidor que se usará como réplica principal depende del proceso que finalice primero.¿Hay un impacto en el rendimiento cuando se usa la alta disponibilidad?
En el caso de una alta disponibilidad con redundancia de zona, aunque no hay ningún impacto destacado en el rendimiento de las cargas de trabajo de lectura en las zonas de disponibilidad, puede haber una reducción de hasta el 40 % en la latencia de escritura de consultas. El aumento de la latencia de escritura se debe a la replicación sincrónica en toda la zona de disponibilidad. El impacto en la latencia de escritura suele ser el doble en una alta disponibilidad con redundancia de zona en comparación con una alta disponibilidad en la misma zona. En el caso de una alta disponibilidad en la misma zona, dado que la réplica principal y la réplica en espera están en la misma zona, la latencia de replicación y, por tanto, la latencia de escritura sincrónica son menores. En resumen, si la latencia de escritura es más importante para usted que la disponibilidad, elija una alta disponibilidad en la misma zona, pero si la disponibilidad y la resistencia de los datos le resulta más importante, aunque se reduzca la latencia de escritura, debe elegir una alta disponibilidad con redundancia de zona. Para medir el impacto preciso del descenso de la latencia en la configuración de alta disponibilidad, se recomienda realizar pruebas de rendimiento de la carga de trabajo para tomar una decisión fundamentada.¿Cómo se lleva a cabo el mantenimiento de mi servidor de alta disponibilidad?
Los eventos planeados, como el escalado de las actualizaciones de la versión secundaria y de proceso, operan primero en la instancia en espera original, después desencadenan una operación de conmutación por error planeada y, después, operan en la instancia principal original. La ventana de mantenimiento programado de los servidores de alta disponibilidad se puede establecer igual que para los servidores flexibles. El tiempo de inactividad será el mismo que en la instancia de servidor flexible de Azure Database for MySQL cuando la alta disponibilidad está deshabilitada.¿Puedo realizar una restauración a un momento dado (PITR) de mi servidor de alta disponibilidad?
Puede hacer una PITR de una instancia de servidor flexible de Azure Database for MySQL con la alta disponibilidad habilitada en una nueva instancia de servidor flexible de Azure Database for MySQL con la alta disponibilidad deshabilitada. Si el servidor de origen se ha creado con alta disponibilidad con redundancia de zona, puede habilitar la alta disponibilidad con redundancia de zona o en la misma zona en el servidor restaurado más adelante. Si el servidor de origen se ha creado con alta disponibilidad en la misma zona, solo puede habilitar la alta disponibilidad en la misma zona en el servidor restaurado.¿Puedo habilitar la alta disponibilidad en un servidor después de crear el servidor?
La alta disponibilidad con redundancia de zona se debe habilitar cuando se crea el servidor. Después de crear el servidor, puede habilitar la alta disponibilidad en la misma zona. Antes de habilitar la alta disponibilidad en la misma zona, asegúrese de que los parámetros del servidor enforce_gtid_consistency" y “gtid_mode” están establecidos en ON.¿Puedo deshabilitar la alta disponibilidad en un servidor después de crearlo?
Puede deshabilitar la alta disponibilidad en un servidor después de crearlo. La facturación se detiene inmediatamente.¿Cómo puedo mitigar el tiempo de inactividad?
Aunque no use la alta disponibilidad, debe poder mitigar el tiempo de inactividad de la aplicación. El tiempo de inactividad del servicio, como las revisiones programadas, las actualizaciones de versiones secundarias o las operaciones iniciadas por el cliente, como el escalado de proceso, se pueden realizar durante las ventanas de mantenimiento programado. Para mitigar el impacto en la aplicación de las tareas de mantenimiento iniciadas por Azure, puede optar por programarlas durante el día de la semana y la hora que menos afecten a la aplicación.¿Puedo usar una réplica de lectura para un servidor habilitado para la alta disponibilidad?
Sí, se admiten réplicas de lectura para los servidores de alta disponibilidad.¿Puedo usar la replicación de datos de entrada para los servidores de alta disponibilidad?
La compatibilidad con la replicación de datos de entrada para el servidor habilitado para alta disponibilidad (HA) solo está disponible a través de la replicación basada en GTID. El procedimiento almacenado para la replicación mediante GTID está disponible en todos los servidores habilitados para la alta disponibilidad con el nombremysql.az_replication_with_gtid.¿Puedo realizar la conmutación por error al servidor en espera durante los reinicios del servidor o al escalar o reducir verticalmente para reducir el tiempo de inactividad?
Actualmente, el servidor flexible de Azure Database for MySQL tiene conmutación por error planeada para optimizar las operaciones de alta disponibilidad, incluyendo el escalado o reducción vertical, y el mantenimiento planeado para ayudar a reducir el tiempo de inactividad. Cuando se inicien estas operaciones, operaría primero en la instancia en espera original, después desencadenaría una operación de conmutación por error planeada y, después, operaría en la instancia principal original.Puede cambiar el modo de disponibilidad (alta disponibilidad con redundancia de zona/misma zona) del servidor
Si crea el servidor con el modo de alta disponibilidad con redundancia de zona habilitado, puede cambiar de alta disponibilidad con redundancia de zona a la misma zona y viceversa. Para cambiar el modo de disponibilidad, puede establecer Alta disponibilidad en Deshabilitado en el panel Alta disponibilidad y luego volver a establecerlo en Redundancia de zona o en la misma zona y seleccionar Modo de alta disponibilidad.
Pasos siguientes
- Más información sobre la continuidad empresarial.
- Más información sobre la alta disponibilidad con redundancia de zona.
- Más información sobre la copia de seguridad y recuperación.