Introducción a Azure Synapse Link para Azure SQL Database
En este artículo se proporciona una guía paso a paso para empezar a utilizar Azure Synapse Link para Azure SQL Database. Para obtener información general sobre esta característica, consulte Azure Synapse Link para Azure SQL Database.
Requisitos previos
Para obtener Azure Synapse Link para SQL, consulte Creación de un área de trabajo de Synapse. El tutorial le enseñará a crear Azure Synapse Link para SQL en una red pública. En este artículo se supone que seleccionó Deshabilitar red virtual administrada y Permitir conexiones desde todas las direcciones IP al crear un área de trabajo de Azure Synapse. Si quiere configurar Azure Synapse Link para Azure SQL Database con seguridad de red, consulte también Configuración del vínculo de Synapse para Azure SQL Database con seguridad de red.
En el caso del aprovisionamiento basado en unidad de transacción de base de datos (DTU), asegúrese de que el servicio Azure SQL Database tiene al menos nivel Estándar con un mínimo de 100 DTU. No se admiten los niveles Gratis, Básico o Estándar con menos de 100 DTU aprovisionadas.
Configuración de la base de datos de Azure SQL de origen
Inicie sesión en Azure Portal.
Vaya a un servidor lógico de Azure SQL, seleccione Identidad y, después, en Identidad administrada asignada por el sistema, seleccione Activado.

Vaya a Redes y, después, active la casilla Permitir que los servicios y recursos de Azure accedan a este servidor.

Utilice Microsoft SQL Server Management Studio (SSMS) o Azure Data Studio para conectarse al servidor lógico. Si desea que el área de trabajo de Azure Synapse se conecte a una base de datos de Azure SQL mediante una identidad administrada, establezca los permisos de administrador de Microsoft Entra en el servidor lógico. Para aplicar los privilegios en el paso 6, use el mismo nombre de administrador para conectarse al servidor lógico con privilegios administrativos.
Expanda Bases de datos, haga clic con el botón derecho en la base de datos que ha creado y seleccione Nueva consulta.
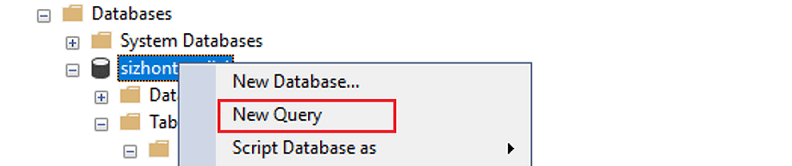
Si quiere que el área de trabajo de Synapse se conecte a la base de datos de Azure SQL de origen mediante una identidad administrada, ejecute el siguiente script para proporcionar el permiso de identidad administrada a la base de datos de origen.
Puede omitir este paso si desea que el área de trabajo de Azure Synapse se conecte a la base de datos de Azure SQL de origen mediante la autenticación de SQL.
CREATE USER <workspace name> FROM EXTERNAL PROVIDER; ALTER ROLE [db_owner] ADD MEMBER <workspace name>;Puede crear una tabla con su propio esquema. El código siguiente es un ejemplo de este tipo de consulta
CREATE TABLE. También puede insertar algunas filas en esta tabla para asegurarse de que hay datos que se van a replicar.CREATE TABLE myTestTable1 (c1 int primary key, c2 int, c3 nvarchar(50))


Creación de un grupo de Azure Synapse SQL de destino
Abra Synapse Studio.
Vaya el centro Administrar, seleccione Grupos de SQL y, después, Nuevo.
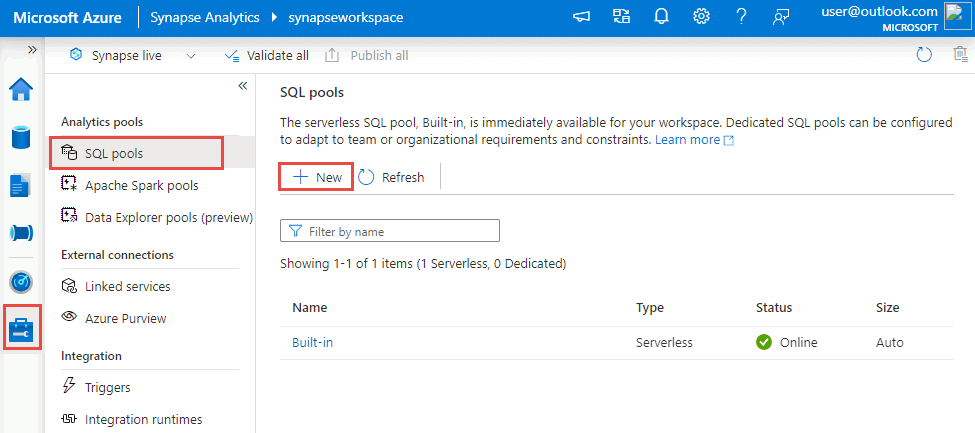
Escriba un nombre de grupo único, use la configuración predeterminada y cree el grupo dedicado.
Debe crear un esquema si el esquema esperado no está disponible en la base de datos de Azure Synapse SQL de destino. Si el esquema es propietario de la base de datos (dbo), puede omitir este paso.

Creación de la conexión de Azure Synapse Link
En el panel izquierdo de Azure Portal, seleccione Integrar.
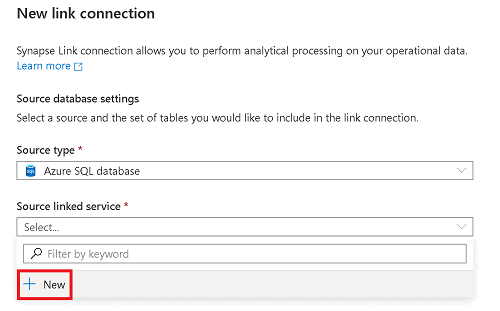
En el panel Integrar, seleccione el signo más (+) y, después, Conexión de vínculo.

En Servicio vinculado de origen, seleccione Nuevo.
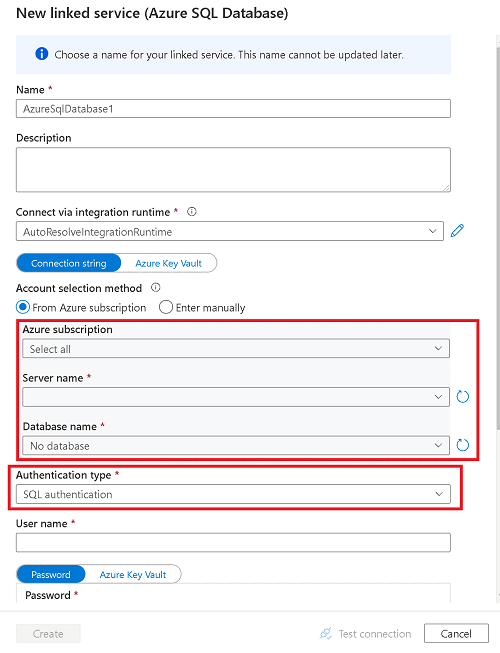
Escriba la información para la base de datos de Azure SQL.
- Seleccione la suscripción, el servidor y la base de datos correspondientes a la base de datos de Azure SQL.
- Realice cualquiera de las siguientes acciones:
- Si desea conectar el área de trabajo de Azure Synapse a la base de datos de origen mediante la identidad administrada del área de trabajo, en Tipo de autenticación, seleccione Identidad administrada.
- Para usar la autenticación SQL en su lugar, si conoce el nombre de usuario y la contraseña que se va a usar, seleccione Autenticación SQL.
Nota:
Solo se admite el servicio vinculado en la versión heredada.
Seleccione Probar conexión para asegurarse de que las reglas de firewall están configuradas correctamente y el área de trabajo puede conectarse correctamente a la base de datos de Azure SQL de origen.
Seleccione Crear.
Nota
El servicio vinculado que cree aquí no está dedicado a Azure Synapse Link para SQL. Se puede usar en cualquier usuario del área de trabajo que tenga los permisos adecuados. Dedique tiempo a comprender el ámbito de los usuarios que pueden tener acceso a este servicio vinculado y sus credenciales. Para más información sobre los permisos de áreas de trabajo de Azure Synapse, consulte Información general sobre el control de acceso al área de trabajo de Azure Synapse: Azure Synapse Analytics.
Seleccione una o varias tablas de origen para replicar en el área de trabajo de Azure Synapse y seleccione Continuar.
Nota
Una tabla de origen especificada no se puede habilitar en más una conexión de vínculo simultáneamente.
Seleccione un grupo y una base de datos de Azure Synapse SQL de destino.
Proporcione un nombre para la conexión de Azure Synapse Link y seleccione el número de núcleos para el proceso de conexión de vínculo. Estos núcleos se usarán para el movimiento de datos del origen al destino.
Nota
- El número de núcleos que seleccione aquí se asigna al servicio de ingesta para procesar la carga de datos y los cambios. No afectan a la configuración de Azure SQL Database de origen ni a la configuración del grupo de SQL dedicado de destino.
- Se recomienda iniciar con pocos núcleos e ir aumentando su número según sea necesario.
Seleccione Aceptar.
Con la nueva conexión de Azure Synapse Link abierta, puede actualizar el nombre de la tabla de destino, el tipo de distribución y el tipo de estructura.
Nota
- Considere la posibilidad de usar la tabla del montón para el tipo de estructura cuando los datos contengan varchar(max), nvarchar(max) y varbinary(max).
- Asegúrese de que el esquema del grupo dedicado de Azure Synapse SQL ya se ha creado antes de iniciar la conexión de vínculo. Azure Synapse Link para SQL creará tablas automáticamente en el esquema en el grupo de Azure Synapse SQL dedicado.
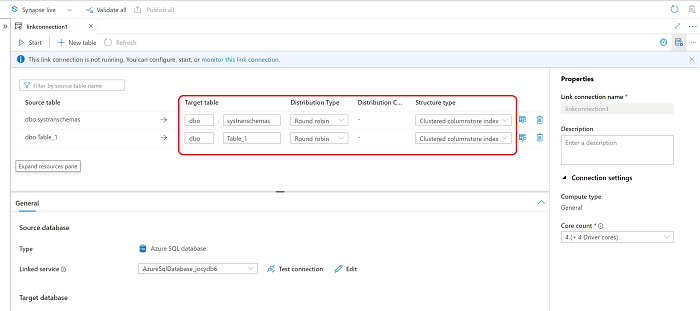
En la lista desplegable Acción sobre tabla de destino existente, elija la opción más apropiada para su escenario si la tabla ya existe en el destino.
- Anular y volver a crear la tabla: la tabla de destino existente se anulará y se volverá a crear.
- Error en tabla no vacía: si la tabla de destino contiene datos, fallará la conexión de vínculo para la tabla dada.
- Combinar con datos existentes: los datos se combinarán en la tabla existente.
Nota:
Si quiere combinar varios orígenes en el mismo destino seleccionando "Combinar con datos existentes", asegúrese de que los orígenes contienen datos diferentes para evitar conflictos y un resultado inesperado.
Especifique si se va a habilitar la coherencia de transacciones entre tablas.
- Cuando esta opción está habilitada, una transacción que abarca varias tablas de la base de datos de origen siempre se replica en la base de datos de destino en una sola transacción. Sin embargo, creará una sobrecarga en el rendimiento general de la replicación.
- Cuando la opción está deshabilitada, cada tabla replicará los cambios en su propio límite de transacción en el destino en conexiones paralelas, lo que mejora el rendimiento general de la replicación.
Nota:
Cuando quiera habilitar la consistencia de las transacciones a través de las tablas, asegúrese también de que los niveles de aislamiento de las transacciones en su pool SQL dedicado a Synapse sea READ COMMITTED SNAPSHOT ISOLATION.
Seleccione Publicar todo para guardar la nueva conexión de vínculo al servicio.

Inicio de la conexión de Azure Synapse Link
Seleccione Iniciar y espere unos minutos para que se repliquen los datos.
Nota:
Una conexión de vínculo comenzará desde una carga inicial completa desde la base de datos de origen seguida de fuentes de cambios incrementales a través de la característica de fuente de cambios de Azure SQL Database. Para más información, consulte Azure Synapse Link para fuente de cambios de SQL.
Supervisión del estado de la conexión de vínculo de Azure Synapse
Puede supervisar el estado de la conexión de Azure Synapse Link, ver qué tablas se copian inicialmente (creación de instantáneas) y ver qué tablas están en modo de replicación continua (replicación).
Vaya al centro Supervisión y seleccione Vincular conexiones.
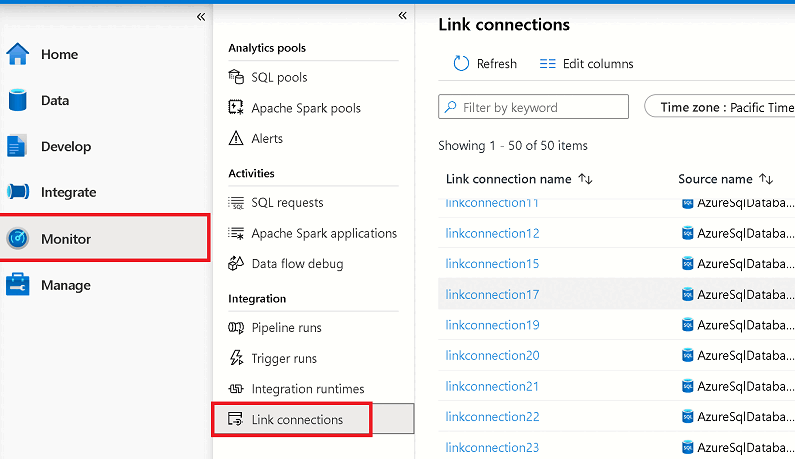
Abra la conexión de Azure Synapse Link que inició y vea el estado de cada tabla.
Seleccione Actualizar en la vista de supervisión de la conexión para observar las actualizaciones del estado.
Consulta de los datos replicados
Espere unos minutos y compruebe para asegurarse de que la base de datos de destino tiene la tabla y los datos esperados. Ahora también puede explorar las tablas replicadas en el grupo dedicado de Azure Synapse SQL de destino.
En el centro de datos, en Área de trabajo, abra la base de datos de destino.
En Tablas, haga clic con el botón derecho en una de las tablas de destino.
Seleccione Nuevo SQL script y después Seleccionar las 100 primeras filas.
Ejecute esta consulta para ver los datos replicados en el grupo de dedicado de Azure Synapse SQL de destino.
También puede consultar la base de datos de destino mediante SSMS u otras herramientas. Use el punto de conexión de SQL dedicado para el área de trabajo como nombre del servidor. El nombre suele ser
<workspacename>.sql.azuresynapse.net. AgregueDatabase=databasename@poolnamecomo parámetro de cadena de conexión adicional al conectarse a través de SSMS u otras herramientas.
Incorporación o eliminación de una tabla en una conexión de Azure Synapse Link existente
Para agregar o quitar tablas en Synapse Studio, haga lo siguiente:
Abra el centro Integrar.
Seleccione la conexión de vínculo que desee editar y ábrala.
Realice cualquiera de las siguientes acciones:
- Para agregar una tabla, seleccione Nueva tabla.
- Para quitar una tabla, seleccione el icono de papelera junto a ella.

Nota:
Puede agregar o quitar tablas directamente cuando se ejecute una conexión de vínculo.

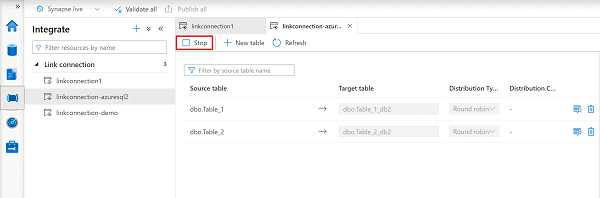
Detención de la conexión de Azure Synapse Link
Para detener la conexión de Azure Synapse Link en Synapse Studio, haga lo siguiente:
En el área de trabajo de Azure Synapse, abra el centro de integración.
En Conexión de vínculo, seleccione la conexión que desee editar y ábrala.
Seleccione Detener para detener la conexión de vínculo y dejará de replicar los datos.
Nota:
- Si reinicia una conexión de vínculo después de detenerla, comenzará a partir de una carga inicial completa desde la base de datos de origen y las fuentes de cambios incrementales ocurrirán a continuación.
- Si elige "Combinar con datos existentes" como acción en la tabla de destino existente, cuando detenga la conexión de vínculo y la reinicie, los registros eliminados en el origen durante ese periodo no se eliminarán en el destino. En tal caso, para asegurar la coherencia de los datos, considere usar pausar/reanudar en lugar de parar/iniciar, o limpie las tablas de destino antes de reiniciar la conexión del vínculo.
Contenido relacionado
- Obtención o establecimiento de una identidad administrada para un servidor lógico o una instancia administrada de Azure SQL Database
- Preguntas frecuentes sobre Azure Synapse Link para SQL
- Configuración de Azure Synapse Link para Azure Cosmos DB
- Configuración de Azure Synapse Link para Dataverse
- Introducción a Azure Synapse Link para SQL Server 2022