Migrar la definición de trabajo de Spark desde Azure Synapse Spark a Fabric
Para mover definiciones de trabajos de Spark (SJD) de Azure Synapse a Fabric, existen dos opciones diferentes:
- Opción 1: crear manualmente la definición de trabajo de Spark en Fabric.
- Opción 2: puedes usar un script para exportar definiciones de trabajos de Spark desde Azure Synapse e importarlas en Fabric mediante la API.
Para conocer las consideraciones sobre la definición de trabajos de Spark, consulta Diferencias entre Azure Synapse Spark y Fabric.
Requisitos previos
Si aún no tienes una, crea un área de trabajo de Fabric en el inquilino.
Opción 1: crear manualmente la definición de trabajo de Spark
Para exportar la definición de trabajo de Spark desde Azure Synapse:
- Abrir Synapse Studio: inicia sesión en Azure. Ve al área de trabajo de Azure Synapse y abre el Synapse Studio.
- Buscar el trabajo de Python/Scala/R Spark: busca e identifica la definición de trabajo de Python/Scala/R Spark que deseas migrar.
- Exportar la configuración de definición de trabajo:
- En Synapse Studio, abre la definición de trabajo de Spark.
- Exporta o anota los valores de la configuración, incluida la ubicación del archivo de script, las dependencias, los parámetros y cualquier otro detalle relevante.
Para crear una nueva definición de trabajo de Spark (SJD) basada en la información de SJD exportada en Fabric:
- Acceder al área trabajo de Fabric: inicia sesión en Fabric y accede al área de trabajo.
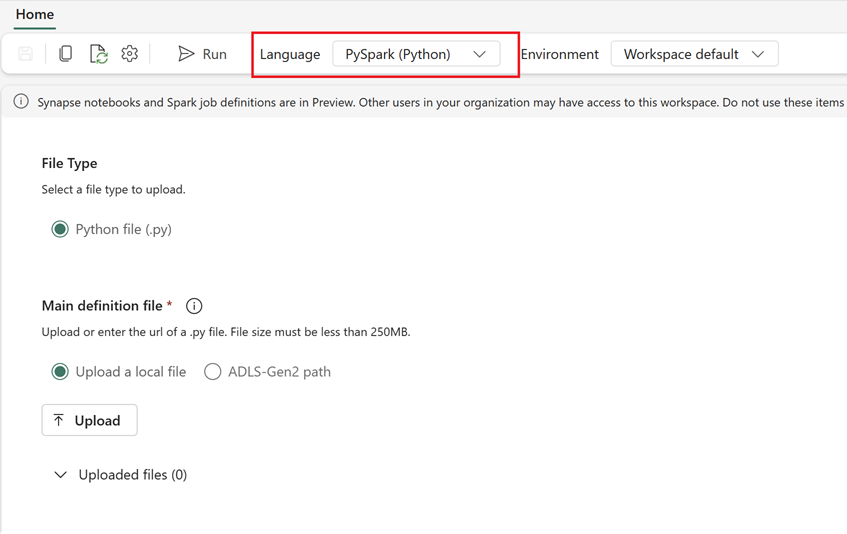
- Crear una nueva definición de trabajo de Spark en Fabric:
- Ve a Página principal de la ingeniería de datos.
- Selecciona Definición de trabajo de Spark.
- Configura el trabajo mediante la información que se exportó desde Synapse, incluida la ubicación del script, las dependencias, los parámetros y la configuración del clúster.
- Adaptar y probar: realiza cualquier adaptación necesaria al script o a la configuración para adaptarse al entorno de Fabric. Prueba el trabajo en Fabric para asegurar que se ejecuta correctamente.
Una vez creada la definición del trabajo de Spark, valida las dependencias:
- Asegúrate de usar la misma versión de Spark.
- Valida la existencia del archivo de definición principal.
- Valida la existencia de los archivos, dependencias y recursos a los que se hace referencia.
- Servicios vinculados, conexiones de origen de datos y puntos de montaje.
Obtén más información sobre cómo crear una definición de trabajo de Apache Spark en Fabric.
Opción 2: Usar la API de Fabric
Siga estos pasos clave para la migración:
- Requisitos previos.
- Paso 1: Exportar la definición de trabajo de Spark desde Azure Synapse Spark a Fabrica OneLake (.json).
- Paso 2: Importar automáticamente la definición del trabajo de Spark en Fabric mediante la API de Fabric.
Requisitos previos
Los requisitos previos incluyen acciones que se deben tener en cuenta antes de iniciar la migración de la definición de trabajos de Spark a Fabric.
- Un área de trabajo de Fabric.
- Si aún no tienes una, crea un almacén de lago de Fabric en el área de trabajo.
Paso 1: Exportar la definición de trabajo de Spark desde el área de trabajo de Azure Synapse
El objetivo del paso 1 es exportar la definición de trabajo de Spark desde el área de trabajo de Azure Synapse a OneLake en formato json. El proceso es el siguiente:
- 1.1) Importa el cuaderno de migración SJD al área de trabajo de Fabric. Este cuaderno exporta todas las definiciones de trabajo de Spark de un área de trabajo de Azure Synapse determinada a un directorio intermedio en OneLake. La API de Synapse se usa para exportar SJD.
- 1.2) Configura los parámetros en el primer comando para exportar la definición de trabajo de Spark a un almacenamiento intermedio (OneLake). Esto solo exporta el archivo de metadatos json. El siguiente fragmento de código se usa para configurar los parámetros de origen y de destino. Asegúrate de reemplazarlos por sus propios valores.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
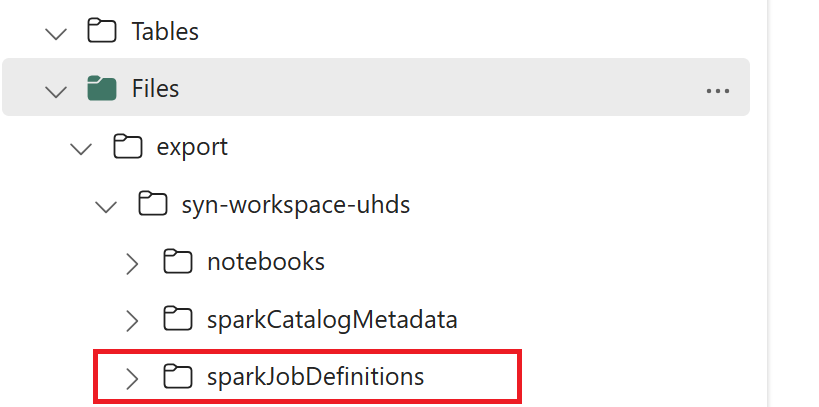
- 1.3) Ejecuta las dos primeras celdas del cuaderno de exportación e importación para exportar metadatos de definición de trabajo de Spark a OneLake. Una vez completadas las celdas, se crea esta estructura de carpetas en el directorio de salida intermedio.
Paso 2: Importar la definición de trabajo de Spark en Fabric
El paso 2 es el momento en el que las definiciones de trabajo de Spark se importan desde el almacenamiento intermedio en el área de trabajo de Fabric. El proceso es el siguiente:
- 2.1) Valida las configuraciones del 1.2 para asegurarte de que el área de trabajo y el prefijo adecuados se indican para importar las definiciones de trabajo de Spark.
- 2.2) Ejecuta la tercera celda del cuaderno export/import para importar todas las definiciones de trabajo de Spark desde la ubicación intermedia.
Nota:
La opción de exportación genera un archivo de metadatos json. Asegúrate de que los archivos ejecutables de definición de trabajo de Spark, los archivos de referencia y los argumentos sean accesibles desde Fabric.