Formato de parquet en Data Factory en Microsoft Fabric
En este artículo se describe cómo configurar el formato Parquet en la canalización de datos de Data Factory en Microsoft Fabric.
Funcionalidades admitidas
El formato Parquet es compatible con las siguientes actividades y conectores como origen y destino.
| Category | Conector/Actividad |
|---|---|
| Conector compatible | Amazon S3 |
| Compatible con Amazon S3 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Archivos de Azure | |
| Sistema de archivos | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Archivos del almacén de lago | |
| Oracle Cloud Storage | |
| SFTP | |
| Actividad compatible | Copiar actividad (origen/destino) |
| Actividad de búsqueda | |
| Actividad GetMetadata | |
| Actividad de eliminación |
Formato Parquet en la actividad de copia
Para configurar el formato de Parquet, elija la conexión en el origen o destino de la actividad de copia de la canalización de datos y, a continuación, seleccione Parquet en la lista desplegable de Formato de archivo . Seleccione Configuración para una configuración adicional de este formato.
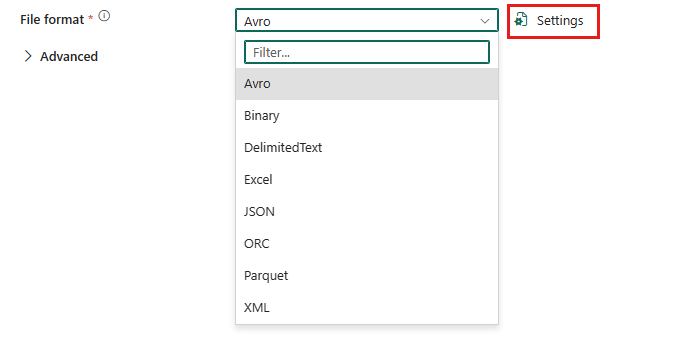
Formato Parquet como origen
Después de seleccionar Configuración en la sección Formato de archivo , se muestran las siguientes propiedades en el cuadro de diálogo emergente Configuración de formato de archivo .
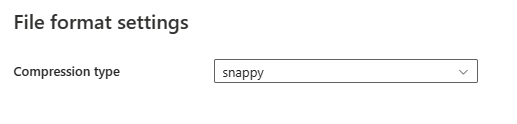
- Tipo de compresión : elija el códec de compresión utilizado para leer los archivos de Parquet en la lista desplegable. Puede elegir entre Ninguno, gzip (.gz), snappy, lzo , Brotli (.br), Zstandard, lz4, lz4frame , bzip2 (.bz2) o lz4hadoop .
Formato Parquet como destino
Después de seleccionar Configuración, se muestran las siguientes propiedades en el cuadro de diálogo emergente Configuración de formato de archivo .
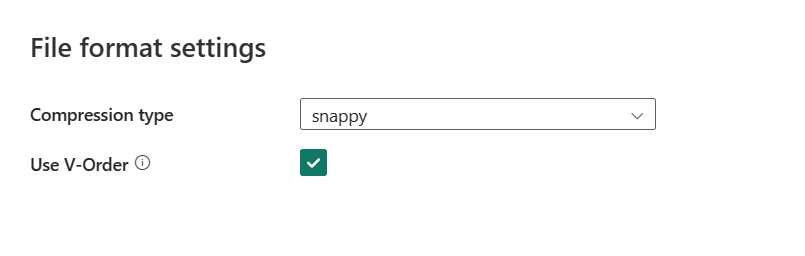
Tipo de compresión : elija el códec de compresión utilizado para escribir los archivos de Parquet en la lista desplegable. Puede elegir entre Ninguno, gzip (.gz), snappy, lzo , Brotli (.br), Zstandard, lz4, lz4frame , bzip2 (.bz2) o lz4hadoop .
Usar V-Order : habilite una optimización del tiempo de escritura en el formato de archivo de parquet. Para obtener más información, consulte Optimización de la tabla de Delta Lake yV-Order . Está habilitada de forma predeterminada.
En la configuración Avanzada de la ficha Destino, se muestran las siguientes propiedades relacionadas con el formato de Parquet.
- Máximo de filas por archivo: al escribir datos en una carpeta, puede elegir escribir en varios archivos y especificar el máximo de filas por archivo. Especifique las filas máximas que desea escribir por archivo.
- Prefijo de nombre de archivo: aplicable cuando se configura Número máximo de filas por archivo. Especifique el prefijo de nombre de archivo al escribir datos en varios archivos, lo que da como resultado este patrón:
<fileNamePrefix>_00000.<fileExtension>. Si no se especifica, el prefijo de nombre de archivo se genera automáticamente. Esta propiedad no se aplica cuando el origen es un almacén basado en archivos o una opción de partición habilitada para el almacén de datos.
Resumen de tabla
Parquet como origen
Las siguientes propiedades se admiten en la sección Origen de la actividad de copia cuando se utiliza el formato Parquet.
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Formato de archivo | El formato de archivo que quiere usar. | Parquet | Sí | tipo (en datasetSettings):Parquet |
| Tipo de compresión | El códec de compresión utilizado para leer los archivos de Parquet. | Elija entre las siguientes opciones: Ninguna gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet como destino
Las siguientes propiedades se admiten en la sección Destino de la actividad de copia cuando se utiliza el formato Parquet.
| Nombre | Descripción | Value | Obligatorio | Propiedad de script JSON |
|---|---|---|---|---|
| Formato de archivo | El formato de archivo que quiere usar. | Parquet | Sí | tipo (en datasetSettings):Parquet |
| Usar V-Order | Optimización del tiempo de escritura en el formato de archivo parquet. | seleccionado o no seleccionado | No | enableVertiParquet |
| Tipo de compresión | El códec de compresión utilizado para escribir archivos Parquet. | Elija entre las siguientes opciones: Ninguna gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Número máximo de filas por archivo | Al escribir datos en una carpeta, puede optar por escribir en varios archivos y especificar el número máximo de filas por archivo. Especifique las filas máximas que desea escribir por archivo. | <las filas máximas por archivo> | No | maxRowsPerFile |
| Prefijo de nombre de archivo | Se aplica cuando Número máximo de filas por archivo está configurado. Especifique el prefijo de nombre de archivo al escribir datos en varios archivos, lo que da como resultado este patrón: <fileNamePrefix>_00000.<fileExtension>. Si no se especifica, el prefijo de nombre de archivo se genera automáticamente. Esta propiedad no se aplica cuando el origen es un almacén basado en archivos o una opción de partición habilitada para el almacén de datos. |
< el prefijo del nombre de archivo > | No | fileNamePrefix |