Cómo acelerar la preparación de datos con Data Wrangler en Microsoft Fabric
La herramienta Data Wrangler es un recurso basado en cuadernos que proporciona una interfaz inmersiva para realizar análisis exploratorios de datos. Combina una presentación de datos similar a una cuadrícula con estadísticas de resumen dinámico, visualizaciones integradas y una biblioteca de operaciones comunes de limpieza de datos. Puede aplicar cada operación con unos pocos pasos. Puede actualizar los datos que se muestran en tiempo real y generar código en Pandas o PySpark que puede guardar de nuevo en el cuaderno como una función reutilizable. Este artículo se centra en la exploración y transformación de DataFrames de Pandas. Para obtener más información sobre el uso de Data Wrangler en DataFrames de Spark, visite este recurso.
Requisitos previos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
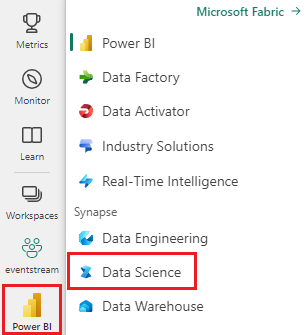
Cambie a la experiencia de ciencia de datos de Synapse mediante el conmutador de experiencia en el lado izquierdo de la página principal.
Limitaciones
- Actualmente, las operaciones de código personalizado solo se admiten para DataFrames de Pandas.
- La pantalla de Data Wrangler funciona mejor en monitores grandes, aunque se pueden minimizar u ocultar diferentes partes de la interfaz para acomodar pantallas más pequeñas.
Inicio de Data Wrangler
Puede iniciar Data Wrangler directamente desde un cuaderno de Microsoft Fabric para explorar y transformar cualquier DataFrame de Pandas o Spark. Para obtener más información sobre el uso de Data Wrangler con DataFrames de Spark, visite este artículo complementario. Este fragmento de código muestra cómo leer datos de ejemplo en un DataFrame de Pandas:
import pandas as pd
# Read a CSV into a Pandas DataFrame
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv")
display(df)
En la pestaña "Inicio" de la cinta de cuadernos, use el símbolo del menú desplegable de Data Wrangler para examinar los DataFrames activos disponibles para su edición. Seleccione el que desea abrir en Data Wrangler.
Sugerencia
El Wrangler de datos no se puede abrir mientras el kernel del cuaderno está ocupado. Una celda en ejecución debe finalizar su ejecución antes de que se pueda iniciar Data Wrangler, tal y como se muestra en esta captura de pantalla:

Elección de ejemplos personalizados
Para abrir un ejemplo personalizado de cualquier DataFrame activo, seleccione "Elegir ejemplo personalizado" en la lista desplegable, como se muestra en esta captura de pantalla:

Esto inicia un elemento emergente con opciones para especificar el tamaño del ejemplo deseado (número de filas) y el método de muestreo (primeros registros, últimos registros o un conjunto aleatorio). Las primeras 5000 filas del DataFrame sirven como tamaño de ejemplo predeterminado, como se muestra en esta captura de pantalla:

Visualización de estadísticas de resumen
Cuando se carga Data Wrangler, muestra una descripción general descriptiva del DataFrame elegido en el panel "Resumen". Esta información general incluye información sobre las dimensiones del DataFrame, los valores que faltan y mucho más. Al seleccionar cualquier columna de la cuadrícula Wrangler de datos, se solicita al panel "Resumen" que actualice y muestre estadísticas descriptivas sobre esa columna específica. También hay información rápida sobre cada columna disponible en su encabezado.
Sugerencia
Las estadísticas y los objetos visuales específicos de columna (tanto en el panel "Resumen" como en los encabezados de columna) dependen del tipo de datos de columna. Por ejemplo, un histograma binned de una columna numérica aparece en el encabezado de columna solo si la columna se convierte como un tipo numérico, como se muestra en esta captura de pantalla:

Exploración de operaciones de limpieza de datos
Puede encontrar una lista de pasos de limpieza de datos en el panel "Operaciones". En el panel "Operaciones", al seleccionar un paso de limpieza de datos se le pide que proporcione una columna o columnas de destino, junto con los parámetros necesarios para completar el paso. Por ejemplo, la solicitud para escalar una columna numéricamente requiere un nuevo intervalo de valores, como se muestra en esta captura de pantalla:

Sugerencia
Puede aplicar una selección más pequeña de operaciones en el menú de cada encabezado de columna, como se muestra en esta captura de pantalla:

Vista previa y aplicación de operaciones
La cuadrícula de visualización de Data Wrangler previsualiza automáticamente los resultados de una operación seleccionada, y el código correspondiente aparece automáticamente en el panel debajo de la cuadrícula. Para confirmar el código previsualizado, seleccione "Aplicar" en cualquiera de los dos lugares. Para eliminar el código en versión preliminar e intentar una nueva operación, seleccione "Descartar" como se muestra en esta captura de pantalla:

Una vez aplicada una operación, la cuadrícula de visualización de Data Wrangler y las estadísticas de resumen se actualizan para reflejar los resultados. El código aparece en la lista en ejecución de operaciones confirmadas, que se encuentra en el panel "Pasos de limpieza", como se muestra en esta captura de pantalla:

Sugerencia
Siempre puede deshacer el paso aplicado más recientemente. En el panel "Pasos de limpieza", aparecerá un icono de papelera si mantiene el cursor sobre ese paso aplicado más recientemente, como se muestra en esta captura de pantalla:

En esta tabla se resumen las operaciones que admite actualmente Data Wrangler:
| Operación | Descripción |
|---|---|
| Sort | Ordenar una columna en orden ascendente o descendente |
| Filter | Filtrar filas en función de una o varias condiciones |
| Codificación de acceso único | Cree nuevas columnas para cada valor único de una columna existente, lo que indica la presencia o ausencia de esos valores por fila |
| Codificación de un solo uso con delimitador | Dividir y codificar datos categóricos con un delimitador |
| Cambiar el tipo de columna | Para cambiar el tipo de datos de una columna |
| Columna desplegable | Seleccione una o más columnas |
| Seleccionar columna | Elija una o varias columnas para mantener y elimine el resto |
| Renombrar columna | Cambio del nombre de una columna |
| Excluir valores omitidos | Quitar filas con valores que faltan |
| Excluir filas duplicadas | Quitar todas las filas que tienen valores duplicados en una o varias columnas |
| Rellenar los valores que faltan | Reemplazar celdas por valores que faltan por un nuevo valor |
| Buscar y reemplazar | Reemplazar celdas por un patrón de coincidencia exacto |
| Agrupar por columna y agregado | Agrupar por valores de columna y agregar resultados |
| Eliminar espacio en blanco | Quitar espacios en blanco del principio y el final del texto |
| Dividir texto | Dividir una columna en varias columnas basadas en un delimitador definido por el usuario |
| Convertir texto en minúsculas | Convertir texto en mayúsculas |
| Convertir texto en mayúsculas | Convertir texto en MAYÚSCULAS |
| Escalar valores mínimos o máximos | Escalado de una columna numérica entre un valor mínimo y máximo |
| Relleno rápido | Crear automáticamente una nueva columna basada en ejemplos derivados de una columna existente |
Modificar la pantalla
En cualquier momento, puede personalizar la interfaz con la pestaña "Vistas" de la barra de herramientas situada encima de la cuadrícula de visualización de Data Wrangler. Esto puede ocultar o mostrar diferentes paneles en función de sus preferencias y tamaño de pantalla, como se muestra en esta captura de pantalla:

Guardar y exportar código
La barra de herramientas situada encima de la cuadrícula de visualización de Data Wrangler proporciona opciones para guardar el código generado. Puede copiar el código en el Portapapeles o exportarlo al cuaderno como una función. Al exportar el código, se cierra Data Wrangler y se agrega la nueva función a una celda de código del cuaderno. También puede descargar el DataFrame limpio como un archivo CSV.
Sugerencia
Data Wrangler genera código que se aplica solo cuando ejecuta manualmente la nueva celda y no sobrescribirá el DataFrame original, como se muestra en esta captura de pantalla:

A continuación, puede ejecutar ese código exportado, como se muestra en esta captura de pantalla:

Contenido relacionado
- Para probar Data Wrangler en DataFrames de Spark, visite este artículo complementario
- Para ver una demostración en vivo de Data Wrangler en Fabric, consulte este vídeo de nuestros amigos en Guy in a Cube
- Para probar Data Wrangler en Visual Studio Code, consulte Data Wrangler en VS Code
- ¿Falta una característica que necesita? ¡Envíenosla! Ponga una sugerencia en el foro de Ideas de Fabric