Ejercicio: Creación de un modelo de estado de la aplicación
Contoso Shoes necesita una forma de detectar, diagnosticar y predecir problemas en esta arquitectura. Nuestro objetivo es crear un modelo de estado que sea mensurable a través de un estado de mantenimiento aplicado a los flujos de usuario y del sistema. Queremos identificar posibles puntos de error antes de que puedan provocar una interrupción.
Estado actual y problema
Hasta ahora, ha agregado una API de comprobación de estado y ha creado funcionalidades de varias regiones en la arquitectura. Sin embargo, no hay ninguna manera de obtener información sobre la topología compleja que incluye los flujos de usuario y del sistema. Esta carencia debe subsanarse para que el equipo de SRE pueda identificar y resolver problemas rápidamente.
En un incidente ocurrido hace poco, el equipo fue incapaz de ver el impacto en cascada de un problema originado en un componente de API que afectaba a sus dependencias de la plataforma. Se desperdició mucho tiempo en solucionar el problema porque no había forma de localizar el componente en estado incorrecto. En última instancia, esta ineficiencia llevó a tiempos de inactividad más largos, lo que causó pérdidas financieras a la empresa.
Especificación
Diseñe un modelo de estado que muestre la relación entre todos los componentes de la arquitectura, incluidos los componentes de la aplicación y las dependencias de la plataforma. Tenga en cuenta los elementos que existen en el flujo de solicitud, como la puerta de enlace, el proceso, las bases de datos, el almacenamiento, las memorias caché, etc. Incluya también aquellos componentes que suelan estar fuera del flujo de solicitud, por ejemplo, los artefactos de Open Container Initiative (OCI), los almacenes secretos o los servicios de configuración, entre otros. Todos los servicios de Azure deben estar configurados para enviar datos de diagnóstico.
Agregue un receptor de datos unificado a la arquitectura para recopilar datos de varios orígenes.
Defina un estado de mantenimiento general según las métricas y los registros históricos agregados. Represente el estado en uno de los tres estados de mantenimiento siguientes: incorrecto, degradado y correcto.
Visualice el estado de mantenimiento de todos los componentes de una jerarquía que representa a todos los flujos.
Enfoque recomendado
Para empezar con el diseño, recomendamos hacer lo siguiente:
Importante
El modelado del estado es una tarea exhaustiva. El enfoque de esta sección está pensado para ayudarle a empezar. Sea extenso al aplicar el modelo a todos los flujos funcionales y no funcionales en el diseño crítico para obtener una vista holística del sistema.
1: Inicio del modelado de estado
Este ejercicio es teórico. El modelado de estado en una actividad de diseño de arriba abajo en la que necesitaremos una lista completa de los componentes usados en la arquitectura. Esta lista debe incluir todos los componentes de la aplicación y los servicios de Azure.
Coloque esos componentes en un gráfico de dependencias que muestre una vista jerárquica de la solución. La capa superior tiene los flujos de usuario que realizan un seguimiento de la solicitud del usuario final al sitio web y fluyen en el nivel de API de la aplicación. La capa inferior contiene los flujos del sistema de los servicios de Azure. Asigne dependencias también entre los recursos de Azure.
El gráfico tendrá una apariencia similar a la siguiente:
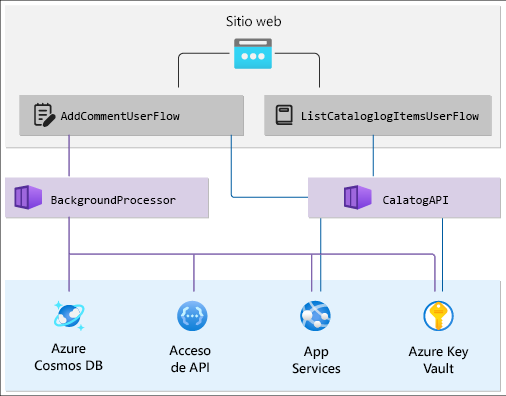
Compruebe su progreso: Estado de la aplicación en capas
2: Definición de las puntuaciones de estado
Recopile métricas y umbrales de métricas de cada componente y, a continuación, decida el valor en el que el componente debe considerarse como correcto, degradado o incorrecto. Esa decisión debe verse afectada por los requisitos empresariales esperados de rendimiento y no funcionales. Clasifique las métricas del siguiente modo:
Métricas de aplicación: Puntos de datos del código de la aplicación, como el recuento de excepciones.
Métricas de servicio: Puntos de datos de los servicios de Azure, como unidades de transacción de base de datos (DTU) en uso.
Métricas de solución: Puntos de datos de nivel de solución, como el tiempo de procesamiento de un extremo a otro de una solicitud.
Este es un ejemplo de Azure App Services:
| Servicios de aplicaciones | Estado de mantenimiento |
|---|---|
| Tiempo de respuesta < 200 ms Errores de servidor HTTP < 2 |
 |
| Tiempo de respuesta < 500 ms Errores de servidor HTTP < 2 |
 |
| Tiempo de respuesta > 500 ms Errores de servidor HTTP > 2 |
 |
3: Definición de un estado de mantenimiento general
Defina un estado general en cada flujo de usuario y del sistema. Deberá agregar el estado de mantenimiento de los componentes individuales que participan en ese flujo.
Supongamos que un flujo del sistema consta de un componente de aplicación, un plan de Azure App Service y App Services.
| API | Plan de App Service | Servicios de aplicaciones | Estado de mantenimiento |
|---|---|---|---|
| Latencia máxima < 30 ms | % de CPU < 70 % Longitud de cola HTTP < 5 |
Tiempo de respuesta < 200 ms Errores de servidor HTTP < 2 |
|
| Latencia máxima < 30 ms | % de CPU < 90 % Longitud de cola HTTP < 5 |
Tiempo de respuesta < 500 ms Errores de servidor HTTP < 2 |
|
| Latencia máxima > 30 ms | % de CPU > 90 % Longitud de cola HTTP > 5 |
Tiempo de respuesta > 500 ms errores del servidor HTTP > 2 |
|
La puntuación de estado de un flujo de usuario debe representarse con la puntuación más baja de todos los componentes asignados. En el caso de los flujos del sistema, pondere de manera oportuna en función de la importancia empresarial. Entre ambos flujos, deben tener prioridad los flujos de usuario importantes económicamente u orientados al cliente.
Compruebe su progreso: Ejemplo: Modelo de estado en capas
4: Recopilación de datos de supervisión
Necesitará un receptor de datos unificado en cada región que recopile registros y métricas para todos los servicios de aplicación y plataforma implementados como parte de la marca regional. Necesitaremos otro receptor donde almacenar las métricas emitidas desde recursos globales, como Azure Front Door y Cosmos DB.
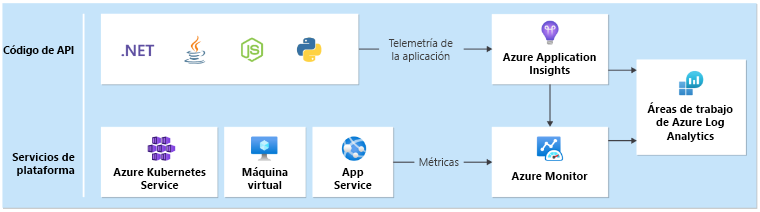
Opciones de tecnología
- Azure Application Insights: Se usa para recopilar toda la telemetría de la aplicación.
- Registros de Azure Monitor: Recopila datos enviados por Application Insights y métricas de plataforma para los servicios de Azure.
- Azure Log Analytics: Se usa como herramienta central para analizar registros y métricas de todos los componentes de la aplicación y de la infraestructura.
Compruebe su progreso: Receptor de datos unificado para realizar análisis correlacionados
5: Configuración de consultas para supervisar datos
El Lenguaje de consulta Kusto (KQL) se integra bien con Log Analytics. Implemente consultas KQL personalizadas como funciones para recuperar datos de Azure Monitor.
Almacene las consultas personalizadas en el repositorio de código para que se importen y apliquen automáticamente como parte de las canalizaciones de integración continua y entrega continua (CI/CD).
6: Visualización del estado de mantenimiento
Puede visualizar el gráfico de dependencias con puntuaciones de estado con una representación de semáforo. Use herramientas como los paneles de Azure, Monitor Workbooks o Grafana. Este es un ejemplo:
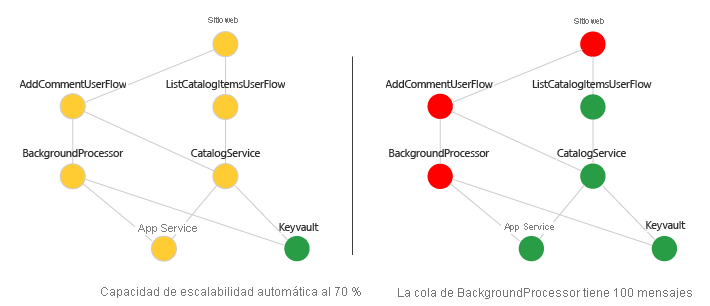
Compruebe su progreso: Visualización
7: Configuración de alertas de los cambios de estado
Debe usar paneles con alertas para prestar atención inmediata a los problemas.
Si el estado de mantenimiento de un componente cambia a degradado o a incorrecto, el operador debe recibir una notificación inmediata. Establezca alertas en el nodo raíz, ya que cualquier cambio en este nodo indica un estado incorrecto en los flujos de usuario o recursos subyacentes.
Compruebe su progreso: Alertas
Comprobar el trabajo
Vea esta demostración sobre la supervisión y el modelado de estado. ¿Cubre el diseño todos los aspectos?
- ¿Tiene un receptor de datos unificado para realizar análisis correlacionados?
- ¿Ha incluido los registros de aplicaciones, las métricas de la plataforma y los puntos de datos de la solución?
- ¿Ha configurado paneles para visualizar el estado de mantenimiento de todos los componentes?
- ¿Ha tenido en cuenta los puntos de error en cada servicio (o parte de ese servicio) que podrían provocar una interrupción o impedirle realizar tareas de escalado, implementación o supervisión?
- ¿Ha tenido en cuenta los paquetes de consulta para capturar consultas clave que ayuden a evaluar los problemas con mayor rapidez?
- ¿Fue útil la API de comprobación de estado en este modelo? ¿Tuvo que modificar esa API para adaptarla mejor al modelo de estado?