Explorar el rendimiento y la seguridad
El ecosistema de Azure ofrece varias opciones de rendimiento y seguridad para la instancia de SQL Server en la máquina virtual de Azure. Cada opción proporciona varias funcionalidades, como diferentes tipos de disco que cumplen los requisitos de capacidad y rendimiento de la carga de trabajo.
Consideraciones sobre el almacenamiento
SQL Server requiere un buen rendimiento del almacenamiento para proporcionar un sólido rendimiento de la aplicación, ya sea una instancia en el entorno local o instalada en una máquina virtual de Azure. Azure proporciona una amplia variedad de soluciones de almacenamiento para satisfacer las necesidades de su carga de trabajo. Aunque Azure ofrece varios tipos de almacenamiento (blobs, archivos, colas y tablas), en la mayoría de los casos, las cargas de trabajo de SQL Server usan Azure Managed Disks. Las excepciones son que se puede crear una instancia de clúster de conmutación por error basada en File Storage y las copias de seguridad usarán Blob Storage. Los discos de Azure Managed Disks actúan como un dispositivo de almacenamiento en bloque que se presenta a la máquina virtual de Azure. Managed Disks ofrece una serie de ventajas, entre las que se incluyen una disponibilidad del 99,999 %, una implementación escalable (puede tener hasta 50 000 discos de máquina virtual por suscripción y región) y la integración con conjuntos y zonas de disponibilidad para ofrecer niveles más altos de resistencia en caso de error.
Los discos administrados por Azure ofrecen dos tipos de cifrado. El servicio de almacenamiento proporciona cifrado del lado servidor de Azure, que actúa como cifrado en reposo. Azure Disk Encryption usa BitLocker en Windows y DM-Crypt en Linux para proporcionar el cifrado de los discos de datos y del sistema operativo en la máquina virtual. Ambas tecnologías se integran con Azure Key Vault y le permiten traer su propia clave de cifrado.
Cada máquina virtual tendrá al menos dos discos asociados:
Disco del sistema operativo: cada máquina virtual necesita un disco del sistema operativo que contenga el volumen de arranque. Este disco sería la unidad C: en el caso de una máquina virtual de la plataforma Windows, o/dev/sda1 en Linux. El sistema operativo se instala automáticamente en el disco del sistema operativo.
Disco temporal: cada máquina virtual incluye un disco que se usa para el almacenamiento temporal. Este almacenamiento está diseñado para datos que no es necesario que sean duraderos, como archivos de paginación o archivos de intercambio. Como el disco es temporal, no debe usarlo para almacenar información crítica, como archivos de base de datos o de registro de transacciones, ya que se perderán durante las tareas de mantenimiento o al reiniciar la máquina virtual. Esta unidad se monta como D:\ en Windows, y/dev/sdb1 en Linux.
Además, puede y debe agregar discos de datos adicionales a las máquinas virtuales de Azure que ejecutan SQL Server.
- Discos de datos: el término disco de datos se usa en Azure Portal, pero, en la práctica, son simplemente discos administrados adicionales que se agregan a una máquina virtual. Estos discos se pueden agrupar para aumentar las operaciones IOPS y la capacidad de almacenamiento disponibles, usando Espacios de almacenamiento en Windows o la gestión de volúmenes lógicos en Linux.
Además, los discos pueden ser de varios tipos:
| Característica | Disco Ultra | SSD Premium | SSD estándar | HDD estándar |
|---|---|---|---|---|
| Tipo de disco | SSD | SSD | SSD | HDD |
| Más adecuado para | Carga de trabajo con un uso intensivo de E/S | Carga de trabajo sensible al rendimiento | Cargas de trabajo ligeras | Cargas de trabajo no críticas y copias de seguridad |
| Tamaño máximo del disco | 65 536 GiB | 32 767 GiB | 32 767 GiB | 32 767 GiB |
| Rendimiento máx. | 2000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| IOPS máx. | 160 000 | 20.000 | 6,000 | 2\.000 |
Los procedimientos recomendados para SQL Server en Azure aconsejan el uso de discos prémium agrupados para aumentar la capacidad de operaciones IOPS y de almacenamiento. Los archivos de datos deben almacenarse en su propio grupo con almacenamiento en caché de lectura en los discos de Azure.
Los archivos de registro de transacciones no se benefician de este almacenamiento en caché, por lo que esos archivos deben incluirse en su propio grupo sin almacenamiento en caché. La base de datos tempdb puede estar en su propio grupo o usar el disco temporal de la máquina virtual, que ofrece una baja latencia, ya que está conectado físicamente al servidor físico donde se ejecutan las máquinas virtuales. Los discos SSD prémium bien configurados ofrecen una latencia inferior a 10 milisegundos. Para las cargas de trabajo críticas que requieren una latencia inferior a esta, debe considerar el uso de discos SSD Ultra.
Consideraciones sobre la seguridad
Hay varias regulaciones y estándares del sector que Azure cumple, lo que permite crear una solución compatible con SQL Server que se ejecuta en una máquina virtual.
Microsoft Defender para SQL
Microsoft Defender para SQL proporciona las características de seguridad de Azure Security Center, como las evaluaciones de vulnerabilidades y las alertas de seguridad.
Azure Defender para SQL se puede usar para identificar y mitigar posibles vulnerabilidades en la instancia y la base de datos de SQL Server. La característica de evaluación de vulnerabilidades puede detectar posibles riesgos en el entorno de SQL Server y ayudarle a corregirlos. También ofrece información sobre el estado de la seguridad y los pasos necesarios para resolver problemas de seguridad.
Azure Security Center
Azure Security Center es un sistema de administración de seguridad unificado que evalúa y ofrece oportunidades para mejorar varios aspectos de seguridad del entorno de datos. Azure Security Center proporciona una visión completa del estado de seguridad de todos los recursos de la nube híbrida.
Consideraciones de rendimiento
La mayoría de las características de rendimiento locales de SQL Server existentes también están disponibles en máquinas virtuales (VM) de Azure. Entre las opciones que se ofrecen se incluye la compresión de datos, que puede mejorar el rendimiento de las cargas de trabajo intensivas de E/S, a la vez que disminuye el tamaño de la base de datos. De forma similar, las particiones de tabla e índice pueden mejorar el rendimiento de las consultas de tablas grandes a la vez que mejoran el rendimiento y la escalabilidad.
Partición de tablas
La creación de particiones de tablas ofrece muchas ventajas, pero a menudo esta estrategia solo se considera cuando la tabla es lo suficientemente grande como para empezar a poner en peligro el rendimiento de las consultas. Identificar qué tablas son buenas candidatas para la creación de particiones es un procedimiento recomendado que puede disminuir las interrupciones e intervenciones. Al filtrar los datos mediante la columna de partición, solo se tiene acceso a un subconjunto de los datos, no a toda la tabla. De forma similar, las operaciones de mantenimiento en una tabla con particiones reducirán la duración del mantenimiento, por ejemplo, puede comprimir datos específicos en una partición determinada o recompilar particiones concretas de un índice.
Hay cuatro pasos principales que se deben seguir al definir una partición de tabla:
- Creación de grupos de archivos, que define los archivos implicados cuando se crean las particiones.
- Creación de la función de partición, que define las reglas de partición basadas en la columna especificada.
- Creación del esquema de partición, que define el grupo de archivos de cada partición.
- Selección de la tabla en la que se va a realizar la partición.
En el ejemplo siguiente se muestra cómo crear una función de partición para el 1 de enero de 2021 hasta el 1 de diciembre de 2021 y distribuir las particiones entre diferentes grupos de archivos.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Compresión de datos
SQL Server ofrece diferentes opciones para comprimir datos. Si bien SQL Server todavía almacena los datos comprimidos en páginas de 8 KB, cuando los datos están comprimidos, se pueden almacenar más filas de datos en una página determinada, lo que permite que la consulta lea menos páginas. Leer menos páginas supone una ventaja doble: permite realizar menos operaciones físicas de E/S y almacenar más filas en el grupo de búferes, lo que hace un uso más eficiente de la memoria. Se recomienda habilitar la compresión de página de base de datos cuando corresponda.
El inconveniente de la compresión es que requiere una pequeña cantidad de sobrecarga de la CPU; sin embargo, en la mayoría de los casos, las ventajas de E/S del almacenamiento superan con creces cualquier uso adicional del procesador.
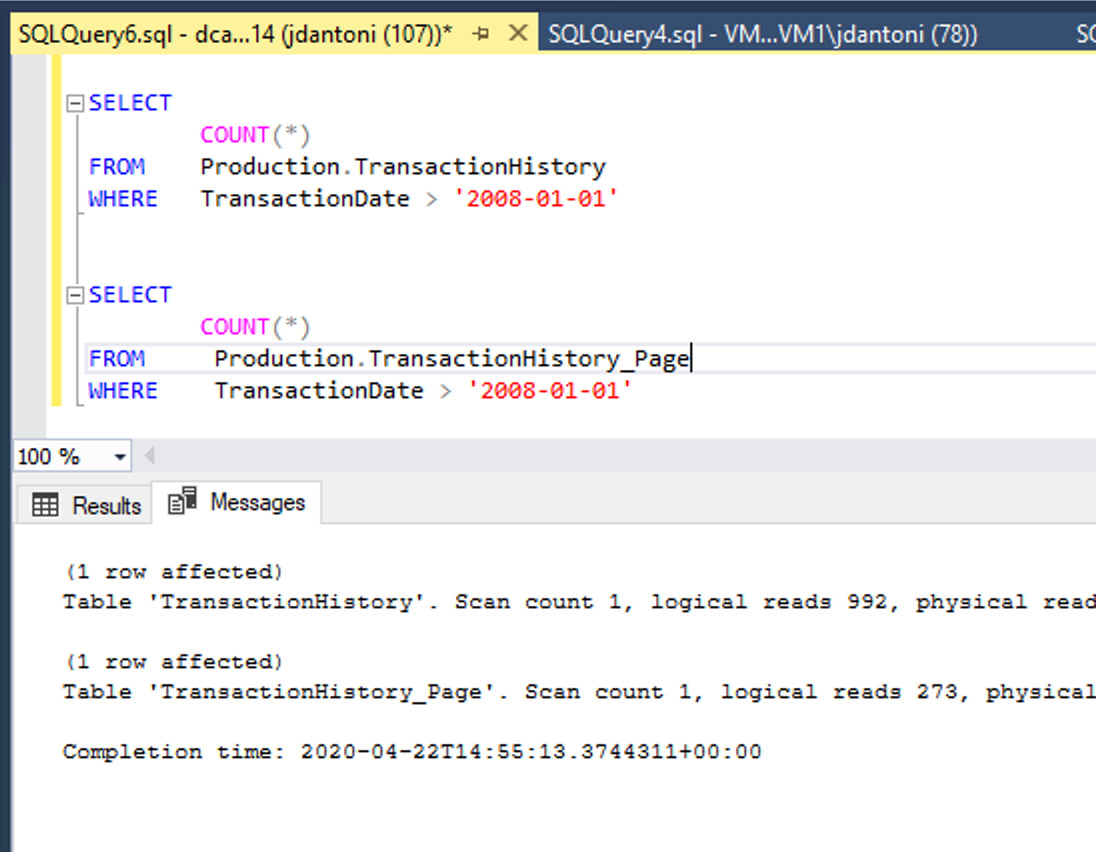
En la imagen anterior, se muestra esta ventaja con respecto al rendimiento. Estas tablas tienen los mismos índices subyacentes; la única diferencia es que los índices agrupados y no agrupados de la tabla Production.TransactionHistory_Page presentan compresión de página. La consulta en el objeto con compresión de página realiza un 72 % menos de lecturas lógicas que la consulta que utiliza los objetos sin comprimir.
La compresión se implementa en SQL Server en el nivel de objeto. Cada índice o tabla se puede comprimir individualmente. Además, tiene la opción de comprimir las particiones de una tabla o índice con particiones. Puede evaluar la cantidad de espacio que se ahorrará mediante el procedimiento almacenado del sistema sp_estimate_data_compression_savings. En las versiones anteriores a SQL Server 2019, este procedimiento no admitía índices de almacén de columnas ni compresión de archivo del almacén de columnas.
Compresión de fila: la compresión de fila es bastante básica y no provoca mucha sobrecarga, pero no ofrece la misma cantidad de compresión (medida mediante el porcentaje de reducción del espacio de almacenamiento necesario) que puede ofrecer la compresión de página. La compresión de fila básicamente almacena cada valor de cada columna en una fila en la cantidad mínima de espacio necesaria para almacenar ese valor. Usa un formato de almacenamiento de longitud variable para los tipos de datos numéricos, como los enteros, los float y los decimales, y almacena cadenas de caracteres de longitud fija con el formato de longitud variable.
Compresión de página: la compresión de página es un supraconjunto de la compresión de fila, ya que todas las páginas se comprimirán inicialmente en filas antes de aplicar la compresión de página. A continuación, se aplican a los datos una combinación de técnicas denominada "compresión de prefijo y diccionario". La compresión de prefijo elimina los datos redundantes de una sola columna y almacena los punteros de nuevo en el encabezado de página. Después de ese paso, la compresión de diccionario busca valores repetidos en una página y los reemplaza por punteros, lo que reduce aún más el almacenamiento. Cuanto mayor sea la redundancia de los datos, mayor será el ahorro de espacio al comprimir los datos.
Compresión de archivo del almacén de columnas: los objetos del almacén de columnas siempre están comprimidos; sin embargo, se pueden comprimir aún más mediante la compresión de archivo, que usa el algoritmo de compresión XPRESS de Microsoft en los datos. Es mejor usar este tipo de compresión para los datos que se leen con poca frecuencia, pero que deben conservarse por motivos legales o empresariales, ya que, aunque estos datos puedan comprimirse aún más, el costo de la CPU que implica la descompresión tiende a ser mayor que las ventajas de rendimiento derivadas de la reducción de E/S.
Opciones adicionales
A continuación se muestra una lista de características y acciones adicionales de SQL Server que se deben tener en cuenta para las cargas de trabajo de producción:
- Habilite la compresión de copias de seguridad.
- Habilite la inicialización instantánea de archivos para archivos de datos.
- Limite el crecimiento automático de la base de datos.
- Deshabilitar autohrink/autoclose para las bases de datos
- Mueva todas las bases de datos a discos de datos, incluidas bases de datos del sistema
- Mueva los directorios de archivos de seguimiento y registros de errores de SQL Server a discos de datos
- Establecer límites máximos de memoria de SQL Server
- Habilite el bloqueo de las páginas en la memoria.
- Habilitar la optimización para cargas de trabajo ad hoc para entornos pesados de OLTP
- Habilite el Almacén de consultas.
- Programar trabajos del Agente SQL Server para ejecutar DBCC CHECKDB, reorganizar índices, recompilar índices y actualizar estadísticas
- Supervisar y administrar el estado y el tamaño de los archivos de registro de transacciones
Para obtener más información sobre los procedimientos recomendados de rendimiento, consulte Best practices for SQL Server on Azure VMs (Procedimientos recomendados para SQL Server en máquinas virtuales de Azure).