Exploración de una solución de recuperación ante desastres y alta disponibilidad de IaaS
Hay muchas combinaciones diferentes de características que se pueden implementar en Azure para IaaS. En esta sección se describen cinco ejemplos comunes de arquitecturas de alta disponibilidad y recuperación ante desastres (HADR) de SQL Server en Azure.
Ejemplo 1 de alta disponibilidad de una sola región: Grupos de disponibilidad Always On
Si solo necesita alta disponibilidad y no recuperación ante desastres, la configuración de un grupo de disponibilidad (GD) es uno de los métodos más extendidos con independencia de dónde se use SQL Server. La imagen siguiente es un ejemplo de un posible GD en una sola región.
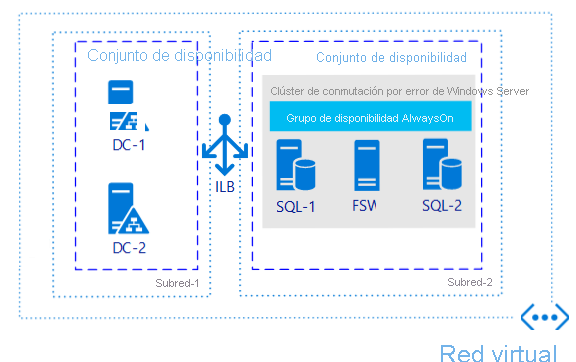
¿Por qué merece la pena tener en cuenta esta arquitectura?
Esta arquitectura protege los datos mediante el uso de más de una copia en diferentes máquinas virtuales (VM).
Esta arquitectura le permite cumplir el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) con una pérdida de datos entre mínima y nula si se implementa de forma correcta.
Esta arquitectura proporciona un método sencillo y estandarizado para que las aplicaciones accedan a las réplicas principales y secundarias (si se van a utilizar elementos como las réplicas de solo lectura).
Esta arquitectura proporciona disponibilidad mejorada durante escenarios de revisión.
Esta arquitectura no necesita almacenamiento compartido, por lo que hay menos complicaciones que cuando se usa una instancia de clúster de conmutación por error (FCI).
Ejemplo 2 de alta disponibilidad de una sola región: instancia de clúster de conmutación por error Always On
Hasta que aparecieron los GD, las FCI eran la forma más popular de implementar la alta disponibilidad de SQL Server. Pero las FCI se diseñaron durante el dominio de las implementaciones físicas. En un mundo virtualizado, las FCI no proporcionan muchas de las mismas protecciones que para el hardware físico, ya que es poco frecuente que una máquina virtual tenga un problema. Las FCI se han diseñado para la protección frente a errores de tarjeta de red o de disco, que probablemente no se produzcan en Azure.
Dicho esto, las FCI tienen su lugar en Azure. Funcionan y, mientras tenga las expectativas adecuadas sobre lo que se proporciona y lo que no, una FCI es una solución absolutamente aceptable. En la imagen siguiente, de la documentación de Microsoft, se muestra una vista general de la apariencia de una implementación de FCI cuando se usan Espacios de almacenamiento directo.
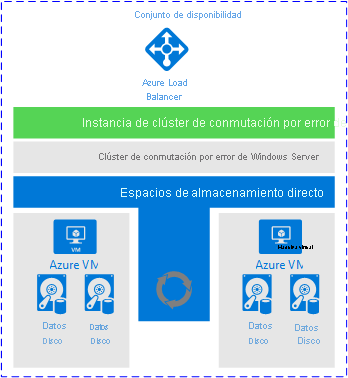
¿Por qué merece la pena tener en cuenta esta arquitectura?
Las FCI siguen siendo una solución de disponibilidad popular.
La historia del almacenamiento compartido mejora con características como los discos compartidos de Azure.
En esta arquitectura se cumple con la mayoría del RTO y el RPO de alta disponibilidad (aunque la recuperación ante desastres no se controla).
Esta arquitectura proporciona un método sencillo y estandarizado para que las aplicaciones accedan a la instancia en clúster de SQL Server.
Esta arquitectura proporciona disponibilidad mejorada durante escenarios de revisión.
Ejemplo 1 de recuperación ante desastres: Grupo de disponibilidad de Always On híbrido o de varias regiones
Si usa GD, una opción consiste en configurar el GD en varias regiones de Azure, o bien como una posible arquitectura híbrida. Esto significa que todos los nodos que contienen las réplicas participan en el mismo WSFC. En este caso, se asume que la conectividad de red es correcta, especialmente si se trata de una configuración híbrida. Una de las consideraciones más importantes sería el recurso de testigo para el WSFC. Para esta arquitectura sería necesario que AD DS y DNS estuvieran disponibles en todas las regiones y, potencialmente, también en el entorno local si se trata de una solución híbrida. En la imagen siguiente se muestra el aspecto de un solo GD configurado en dos ubicaciones cuando se usa Windows Server.
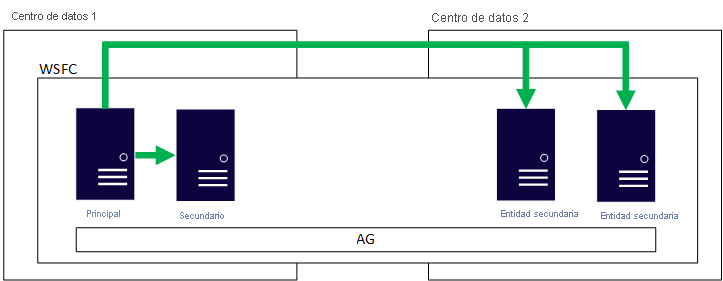
¿Por qué merece la pena tener en cuenta esta arquitectura?
Esta arquitectura es una solución probada; no es diferente a tener dos centros de datos en la actualidad en una topología de GD.
Esta arquitectura funciona con las ediciones Standard y Enterprise de SQL Server.
Los GD proporcionan redundancia de forma natural con copias adicionales de los datos.
En esta arquitectura se usa una característica que proporciona alta disponibilidad y recuperación ante desastres
Ejemplo 2 de recuperación ante desastres: Grupo de disponibilidad distribuido
Un GD distribuido es una característica exclusiva de la edición Enterprise que se presentó en SQL Server 2016. Es diferente de un GD tradicional. En lugar de tener un WSFC subyacente en el que todos los nodos contienen réplicas que participan en un GD como se ha descrito en el ejemplo anterior, un GD distribuido se compone de varios GD. La réplica principal que contiene la base de datos de lectura y escritura se conoce como réplica principal global. La réplica principal del segundo GD se denomina reenviador y mantiene la sincronización de la réplica secundaria de ese GD. Básicamente se trata de un grupo de disponibilidad de grupos de disponibilidad.
Esta arquitectura facilita trabajar con aspectos como el cuórum, ya que cada clúster mantendría el suyo propio, lo que significa que también tiene su propio testigo. Un GD distribuido funcionará si usa Azure para todos los recursos, o bien si utiliza una arquitectura híbrida.
En la imagen siguiente se muestra un ejemplo de configuración de grupo de disponibilidad distribuido. Hay dos WSFC. Imagine que cada uno está en una región de Azure diferente, o bien que uno está en el entorno local y el otro en Azure. Cada WSFC tiene un GD con dos réplicas. La principal global del GD 1 mantiene sincronizada la réplica secundaria de la réplica del GD 1, así como el reenviador, que también es la réplica principal del GD 2. Esa réplica mantiene sincronizada la secundaria del GD 2.
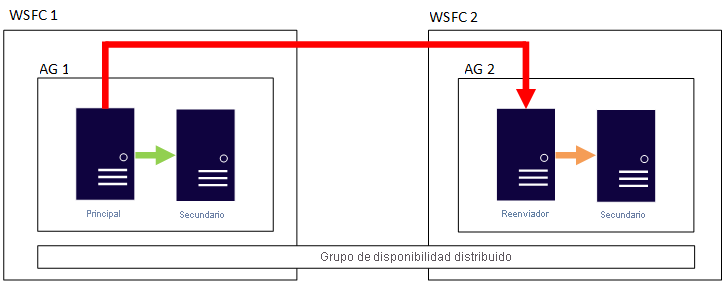
¿Por qué merece la pena tener en cuenta esta arquitectura?
Esta arquitectura separa el WSFC como un único punto de error si todos los nodos pierden la comunicación
En esta arquitectura, una réplica principal no sincroniza todas las réplicas secundarias.
Esta arquitectura puede proporcionar conmutación por recuperación de una ubicación a otra.
Ejemplo 3 de recuperación ante desastres: Trasvase de registros
El trasvase de registros es uno de los métodos de HADR más antiguos para configurar la recuperación ante desastres para SQL Server. Como se ha descrito antes, la unidad de medida es la copia de seguridad del registro de transacciones. A menos que se planee el cambio a un estado de espera semiactiva para garantizar que los datos no se pierdan, lo más probable es que se produzca pérdida de datos. En lo que respecta a la recuperación ante desastres, siempre es mejor asumir cierta pérdida de datos, aunque sea mínima. En la imagen siguiente, de la documentación de Microsoft, se muestra una topología de trasvase de registros de ejemplo.
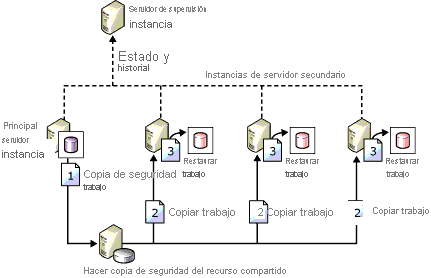
¿Por qué merece la pena tener en cuenta esta arquitectura?
El trasvase de registros es una característica probada y que se usa desde hace más de 20 años.
Es fácil de implementar y administrar, ya que se basa en la copia de seguridad y la restauración.
El trasvase de registros es tolerante a redes que no son sólidas.
Cumple la mayoría de los objetivos de RTO y RPO para la recuperación ante desastres.
El trasvase de registros es una buena manera de proteger las FCI.
Ejemplo 4 de recuperación ante desastres: Azure Site Recovery
Para aquellos que no quieran implementar una solución de recuperación ante desastres basada en SQL Server, Azure Site Recovery es una opción posible. Pero la mayoría de los profesionales de datos prefieren un enfoque centrado en la base de datos, ya que normalmente tendrá un RPO inferior.
En la imagen siguiente, de la documentación de Microsoft, se muestra en qué parte de Azure Portal puede configurar la replicación para Azure Site Recovery.
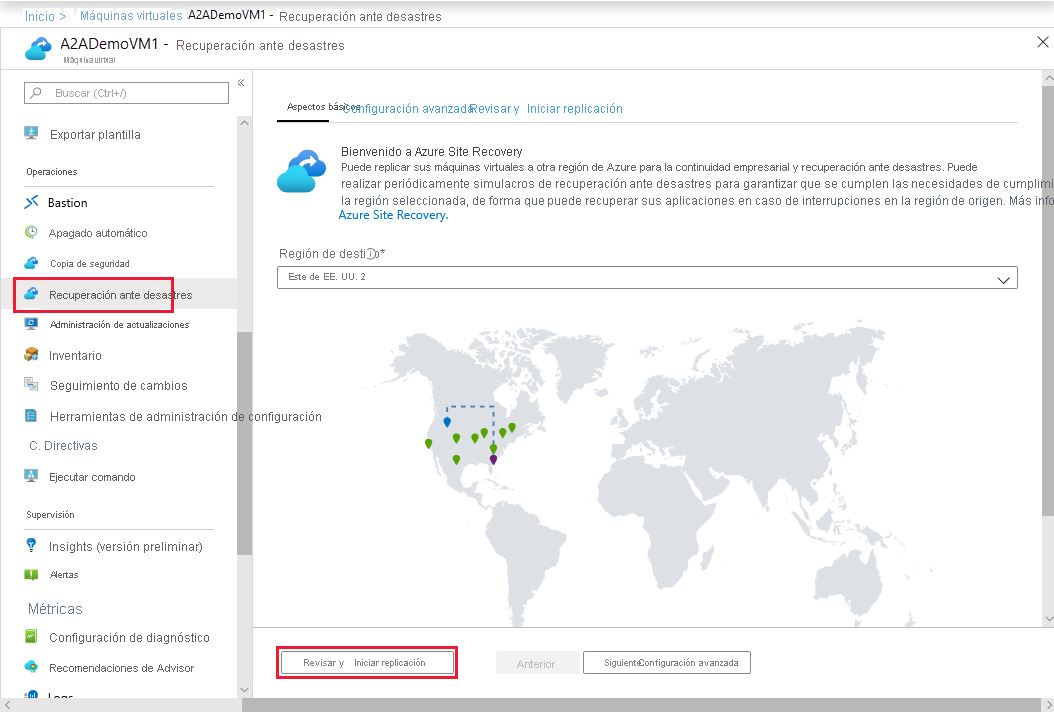
¿Por qué merece la pena tener en cuenta esta arquitectura?
Azure Site Recovery funcionará con algo más que simplemente SQL Server.
Azure Site Recovery puede cumplir el RTO y posiblemente el RPO.
Se proporciona como parte de la plataforma Azure.