Descripción del proceso de ciencia de datos
Una manera común de extraer información de los datos es visualizarlos. Siempre que tenga conjuntos de datos complejos, es posible que quiera profundizar y tratar de encontrar patrones intrincados en los datos.
Como científico de datos, puede entrenar modelos de aprendizaje automático para buscar patrones en los datos. Puede usar esos patrones para generar nueva información o predicciones. Por ejemplo, puede predecir el número esperado de productos que espera vender en la próxima semana.
Aunque el entrenamiento del modelo es importante, no es la única tarea de un proyecto de ciencia de datos. Antes de explorar un proceso típico de ciencia de datos, vamos a explorar los modelos de aprendizaje automático comunes que puede entrenar.
Exploración de modelos comunes de aprendizaje automático
El objetivo del aprendizaje automático es entrenar modelos que pueden identificar patrones en grandes cantidades de datos. Luego, puede usar los patrones para realizar predicciones que le proporcionen nuevas conclusiones sobre qué acciones puede realizar.
Las posibilidades con el aprendizaje automático pueden parecer infinitas, así que comencemos por comprender los cuatro tipos comunes de modelos de aprendizaje automático:
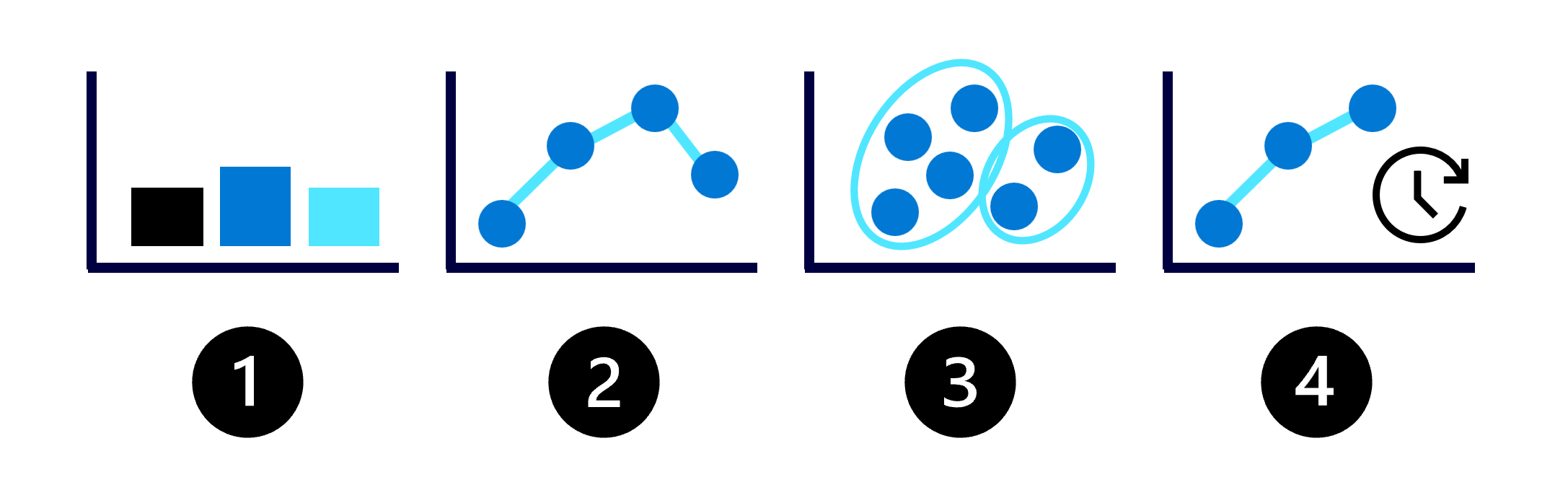
- Clasificación: predicen un valor de categoría, por ejemplo, el abandono de un cliente.
- Regresión: predicen un valor numérico como el precio de un producto.
- Agrupación en clústeres: agrupe puntos de datos similares en clústeres o grupos.
- Previsión: predicen valores numéricos futuros basados en datos de serie temporal, como las ventas esperadas el próximo mes.
Para decidir qué tipo de modelo de aprendizaje automático debe entrenar, primero debe comprender el problema empresarial y los datos disponibles.
Descripción del proceso de ciencia de datos
Para entrenar un modelo de aprendizaje automático, el proceso normalmente implica los pasos siguientes:

- Definir el problema: junto con los usuarios y analistas empresariales, decida qué debe predecir el modelo y cuándo lo hace correctamente.
- Obtener los datos: busque orígenes de datos y obtenga acceso almacenando los datos en un almacén de lago.
- Preparar los datos: explore los datos leyéndolos de un almacén de lago en un cuaderno. Limpie y transforme los datos en función de los requisitos del modelo.
- Entrenar el modelo: elija un algoritmo y valores de hiperparámetros según el método de prueba y error mediante el seguimiento de los experimentos con MLflow.
- Generación de información: use la puntuación por lotes del modelo para generar las predicciones solicitadas.
Como científico de datos, la mayor parte del tiempo se dedica a preparar los datos y a entrenar el modelo. La forma de preparar los datos y el algoritmo que elija para entrenar un modelo puede influir en el éxito de este.
Puede preparar y entrenar un modelo mediante bibliotecas de código abierto disponibles para el lenguaje que prefiera. Por ejemplo, si trabaja con Python, puede preparar los datos con Pandas y Numpy y entrenar el modelo con bibliotecas como Scikit-Learn, PyTorch o SynapseML.
Cuando experimente, le conviene tener una visión general de todos los modelos que haya entrenado. Querrá comprender cómo influyen sus elecciones en el éxito del modelo. Mediante el seguimiento de los experimentos con MLflow en Microsoft Fabric, podrá administrar e implementar fácilmente los modelos que ha entrenado.