Introducción
El lenguaje SQL
SQL es un acrónimo de Lenguaje de consulta estructurado (en inglés, Structured Query Language). SQL se utiliza para comunicarse con bases de datos relacionales. Las instrucciones SQL se usan para realizar tareas como actualizar o recuperar datos de una base de datos. Por ejemplo, la instrucción SELECT de SQL se usa para consultar la base de datos y devolver un conjunto de filas de datos. Algunos sistemas de administración de bases de datos relacionales habituales que utilizan SQL incluyen Microsoft SQL Server, MySQL, PostgreSQL, MariaDB y Oracle.
Hay un estándar del lenguaje SQL definido por el American National Standards Institute (ANSI). Cada proveedor agrega sus propias variaciones y extensiones.
En este módulo, usted aprenderá a:
- Comprender qué es SQL y cómo se usa
- Identificar objetos de base de datos en esquemas
- Identificar tipos de instrucción SQL
- Usar la instrucción SELECT para consultar tablas en una base de datos
- Trabajo con tipos de datos
- Controlar valores NULL
Transact-SQL
Las instrucciones SQL básicas, como SELECT,INSERT,UPDATE y DELETE están disponibles independientemente del sistema de base de datos relacional con el que trabaje. Aunque estas instrucciones SQL son parte del estándar SQL de ANSI, muchos sistemas de administración de bases de datos también tienen sus propias extensiones. Estas extensiones proporcionan una funcionalidad que no se incluye en el estándar de SQL y contienen áreas como la administración de la seguridad y la capacidad de programación. Los sistemas de base de datos de Microsoft, como SQL Server, Azure SQL Database, Microsoft Fabric y otros, usan un dialecto de SQL denominado Transact-SQL o T-SQL. T-SQL incluye extensiones de lenguaje para escribir procedimientos almacenados y funciones, que son código de aplicación almacenado en la base de datos, y administrar cuentas de usuario.
SQL es un lenguaje declarativo
Los lenguajes de programación se pueden clasificar como de procedimientos o declarativos. Los lenguajes de procedimientos permiten definir una secuencia de instrucciones que el equipo sigue para realizar una tarea. Los lenguajes declarativos le permiten describir la salida que desea y dejan los detalles de los pasos necesarios para entregar la salida al motor de ejecución.
SQL admite cierta sintaxis de procedimientos, pero la consulta de datos con SQL suele seguir la semántica declarativa. SQL se usa para describir los resultados que desea y el procesador de consultas del motor de base de datos desarrolla un plan de consulta para recuperarlos. El procesador de consultas usa estadísticas sobre los datos de la base de datos y los índices que se definen en las tablas para elaborar un buen plan de consulta.
Datos relacionales
SQL se suele usar (aunque no siempre) para consultar datos de bases de datos relacionales. Una base de datos relacional es aquella en la que los datos se han organizado en varias tablas (denominadas técnicamente relaciones ), cada una de las cuales representa un tipo determinado de entidad (por ejemplo, un cliente, un producto o un pedido de ventas). Los atributos de estas entidades (por ejemplo, el nombre de un cliente, el precio de un producto o la fecha de pedido de un encargo de ventas) se definen como columnas, o atributos, de la tabla y cada fila de la tabla representa una instancia del tipo de entidad (por ejemplo, un cliente, producto o pedido de ventas específico).
Las tablas de la base de datos están relacionadas entre sí mediante columnas de clave que identifican de forma única la entidad determinada representada. Se define una clave principal para cada tabla y una referencia a esta clave se define como una clave externa en cualquier tabla relacionada. Esto es más fácil de entender con un ejemplo:
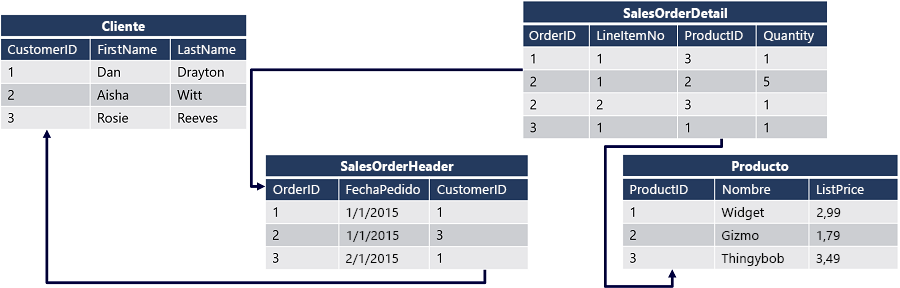
El diagrama muestra una base de datos relacional que contiene cuatro tablas:
- Cliente
- SalesOrderHeader
- SalesOrderDetail
- Producto
Cada cliente se identifica mediante un campo CustomerID único: este campo es la clave principal de la tabla Customer. La tabla SalesOrderHeader tiene una clave principal denominada OrderID para identificar cada pedido y también incluye una clave externa CustomerID que hace referencia a la clave principal de la tabla Customer, por lo que identifica qué cliente está asociado a cada pedido. Los datos sobre los elementos individuales de un pedido se almacenan en la tabla SalesOrderDetail, que tiene una clave principal compuesta que combina OrderID en la tabla SalesOrderHeader con un valor LineItemNo. La combinación de estos valores identifica de forma única un elemento de línea. El campo OrderID también se usa como clave externa para indicar a qué pedido pertenece el elemento de línea, se usa un campo ProductID como clave externa para la clave principal ProductID de la tabla Product para indicar qué producto se encargó.
Procesamiento basado en conjuntos
La teoría de conjuntos es una de las bases matemáticas del modelo relacional de administración de datos y es fundamental para trabajar con bases de datos relacionales. Aunque es posible que pudiera escribir consultas en T-SQL sin un conocimiento exhaustivo de los conjuntos, es posible que tenga dificultades para escribir algunos de los tipos más complejos de instrucciones que pueden ser necesarios para un rendimiento óptimo.
Sin entrar en las matemáticas de la teoría de conjuntos, puede considerar un conjunto como "una colección de objetos definidos y distintos que se consideran como un todo". En términos aplicados a bases de datos de SQL Server, puede considerar un conjunto como una colección de objetos distintos que contienen cero o más miembros del mismo tipo. Por ejemplo, la tabla Customer representa un conjunto: en concreto, el conjunto de todos los clientes. Verá que los resultados de una instrucción SELECT también forman un conjunto.
A medida que adquiera conocimientos sobre las instrucciones de consulta de T-SQL, será importante pensar siempre en todo el conjunto más que en los miembros individuales. Esta mentalidad le preparará mejor para escribir código basado en conjuntos, en lugar de pensar en una fila en cada momento. Trabajar con conjuntos requiere pensar en términos de operaciones que se producen "todas a la vez" en lugar de una en una.
Una característica importante que se debe tener en cuenta sobre la teoría de conjuntos es que no hay ninguna especificación con respecto a ninguna ordenación de los miembros de un conjunto. Esta falta de orden se aplica a las tablas de las bases de datos relacionales. No hay ningún concepto de primera fila, segunda fila o última fila. Se puede acceder a los elementos (y recuperarlos) en cualquier orden. Si necesita devolver resultados en un orden determinado, debe especificarlo explícitamente mediante una cláusula ORDER BY en la consulta SELECT.