ASP.NET
10 Tips for Writing High-Performance Web Applications
Rob Howard
This article discusses:
|
This article uses the following technologies: ASP.NET, .NET Framework, IIS |
Contents
Performance on the Data Tier
Tip 1—Return Multiple Resultsets
Tip 2—Paged Data Access
Tip 3—Connection Pooling
Tip 4—ASP.NET Cache API
Tip 5—Per-Request Caching
Tip 6—Background Processing
Tip 7—Page Output Caching and Proxy Servers
Tip 8—Run IIS 6.0 (If Only for Kernel Caching)
Tip 9—Use Gzip Compression
Tip 10—Server Control View State
Conclusion
Writing a Web application with ASP.NET is unbelievably easy. So easy, many developers don't take the time to structure their applications for great performance. In this article, I'm going to present 10 tips for writing high-performance Web apps. I'm not limiting my comments to ASP.NET applications because they are just one subset of Web applications. This article won't be the definitive guide for performance-tuning Web applications—an entire book could easily be devoted to that. Instead, think of this as a good place to start.
Before becoming a workaholic, I used to do a lot of rock climbing. Prior to any big climb, I'd review the route in the guidebook and read the recommendations made by people who had visited the site before. But, no matter how good the guidebook, you need actual rock climbing experience before attempting a particularly challenging climb. Similarly, you can only learn how to write high-performance Web applications when you're faced with either fixing performance problems or running a high-throughput site.
My personal experience comes from having been an infrastructure Program Manager on the ASP.NET team at Microsoft, running and managing www.asp.net, and helping architect Community Server, which is the next version of several well-known ASP.NET applications (ASP.NET Forums, .Text, and nGallery combined into one platform). I'm sure that some of the tips that have helped me will help you as well.
You should think about the separation of your application into logical tiers. You might have heard of the term 3-tier (or n-tier) physical architecture. These are usually prescribed architecture patterns that physically divide functionality across processes and/or hardware. As the system needs to scale, more hardware can easily be added. There is, however, a performance hit associated with process and machine hopping, thus it should be avoided. So, whenever possible, run the ASP.NET pages and their associated components together in the same application.
Because of the separation of code and the boundaries between tiers, using Web services or remoting will decrease performance by 20 percent or more.
The data tier is a bit of a different beast since it is usually better to have dedicated hardware for your database. However, the cost of process hopping to the database is still high, thus performance on the data tier is the first place to look when optimizing your code.
Before diving in to fix performance problems in your applications, make sure you profile your applications to see exactly where the problems lie. Key performance counters (such as the one that indicates the percentage of time spent performing garbage collections) are also very useful for finding out where applications are spending the majority of their time. Yet the places where time is spent are often quite unintuitive.
There are two types of performance improvements described in this article: large optimizations, such as using the ASP.NET Cache, and tiny optimizations that repeat themselves. These tiny optimizations are sometimes the most interesting. You make a small change to code that gets called thousands and thousands of times. With a big optimization, you might see overall performance take a large jump. With a small one, you might shave a few milliseconds on a given request, but when compounded across the total requests per day, it can result in an enormous improvement.
Performance on the Data Tier
When it comes to performance-tuning an application, there is a single litmus test you can use to prioritize work: does the code access the database? If so, how often? Note that the same test could be applied for code that uses Web services or remoting, too, but I'm not covering those in this article.
If you have a database request required in a particular code path and you see other areas such as string manipulations that you want to optimize first, stop and perform your litmus test. Unless you have an egregious performance problem, your time would be better utilized trying to optimize the time spent in and connected to the database, the amount of data returned, and how often you make round-trips to and from the database.
With that general information established, let's look at ten tips that can help your application perform better. I'll begin with the changes that can make the biggest difference.
Tip 1—Return Multiple Resultsets
Review your database code to see if you have request paths that go to the database more than once. Each of those round-trips decreases the number of requests per second your application can serve. By returning multiple resultsets in a single database request, you can cut the total time spent communicating with the database. You'll be making your system more scalable, too, as you'll cut down on the work the database server is doing managing requests.
While you can return multiple resultsets using dynamic SQL, I prefer to use stored procedures. It's arguable whether business logic should reside in a stored procedure, but I think that if logic in a stored procedure can constrain the data returned (reduce the size of the dataset, time spent on the network, and not having to filter the data in the logic tier), it's a good thing.
Using a SqlCommand instance and its ExecuteReader method to populate strongly typed business classes, you can move the resultset pointer forward by calling NextResult. Figure 1 shows a sample conversation populating several ArrayLists with typed classes. Returning only the data you need from the database will additionally decrease memory allocations on your server.
Figure 1 Extracting Multiple Resultsets from a DataReader
// read the first resultset reader = command.ExecuteReader(); // read the data from that resultset while (reader.Read()) { suppliers.Add(PopulateSupplierFromIDataReader( reader )); } // read the next resultset reader.NextResult(); // read the data from that second resultset while (reader.Read()) { products.Add(PopulateProductFromIDataReader( reader )); }
Tip 2—Paged Data Access
The ASP.NET DataGrid exposes a wonderful capability: data paging support. When paging is enabled in the DataGrid, a fixed number of records is shown at a time. Additionally, paging UI is also shown at the bottom of the DataGrid for navigating through the records. The paging UI allows you to navigate backwards and forwards through displayed data, displaying a fixed number of records at a time.
There's one slight wrinkle. Paging with the DataGrid requires all of the data to be bound to the grid. For example, your data layer will need to return all of the data and then the DataGrid will filter all the displayed records based on the current page. If 100,000 records are returned when you're paging through the DataGrid, 99,975 records would be discarded on each request (assuming a page size of 25). As the number of records grows, the performance of the application will suffer as more and more data must be sent on each request.
One good approach to writing better paging code is to use stored procedures. Figure 2 shows a sample stored procedure that pages through the Orders table in the Northwind database. In a nutshell, all you're doing here is passing in the page index and the page size. The appropriate resultset is calculated and then returned.
Figure 2 Paging Through the Orders Table
CREATE PROCEDURE northwind_OrdersPaged ( @PageIndex int, @PageSize int ) AS BEGIN DECLARE @PageLowerBound int DECLARE @PageUpperBound int DECLARE @RowsToReturn int -- First set the rowcount SET @RowsToReturn = @PageSize * (@PageIndex + 1) SET ROWCOUNT @RowsToReturn -- Set the page bounds SET @PageLowerBound = @PageSize * @PageIndex SET @PageUpperBound = @PageLowerBound + @PageSize + 1 -- Create a temp table to store the select results CREATE TABLE #PageIndex ( IndexId int IDENTITY (1, 1) NOT NULL, OrderID int ) -- Insert into the temp table INSERT INTO #PageIndex (OrderID) SELECT OrderID FROM Orders ORDER BY OrderID DESC -- Return total count SELECT COUNT(OrderID) FROM Orders -- Return paged results SELECT O.* FROM Orders O, #PageIndex PageIndex WHERE O.OrderID = PageIndex.OrderID AND PageIndex.IndexID > @PageLowerBound AND PageIndex.IndexID < @PageUpperBound ORDER BY PageIndex.IndexID END
In Community Server, we wrote a paging server control to do all the data paging. You'll see that I am using the ideas discussed in Tip 1, returning two resultsets from one stored procedure: the total number of records and the requested data.
The total number of records returned can vary depending on the query being executed. For example, a WHERE clause can be used to constrain the data returned. The total number of records to be returned must be known in order to calculate the total pages to be displayed in the paging UI. For example, if there are 1,000,000 total records and a WHERE clause is used that filters this to 1,000 records, the paging logic needs to be aware of the total number of records to properly render the paging UI.
Tip 3—Connection Pooling
Setting up the TCP connection between your Web application and SQL Server™ can be an expensive operation. Developers at Microsoft have been able to take advantage of connection pooling for some time now, allowing them to reuse connections to the database. Rather than setting up a new TCP connection on each request, a new connection is set up only when one is not available in the connection pool. When the connection is closed, it is returned to the pool where it remains connected to the database, as opposed to completely tearing down that TCP connection.
Of course you need to watch out for leaking connections. Always close your connections when you're finished with them. I repeat: no matter what anyone says about garbage collection within the Microsoft® .NET Framework, always call Close or Dispose explicitly on your connection when you are finished with it. Do not trust the common language runtime (CLR) to clean up and close your connection for you at a predetermined time. The CLR will eventually destroy the class and force the connection closed, but you have no guarantee when the garbage collection on the object will actually happen.
To use connection pooling optimally, there are a couple of rules to live by. First, open the connection, do the work, and then close the connection. It's okay to open and close the connection multiple times on each request if you have to (optimally you apply Tip 1) rather than keeping the connection open and passing it around through different methods. Second, use the same connection string (and the same thread identity if you're using integrated authentication). If you don't use the same connection string, for example customizing the connection string based on the logged-in user, you won't get the same optimization value provided by connection pooling. And if you use integrated authentication while impersonating a large set of users, your pooling will also be much less effective. The .NET CLR data performance counters can be very useful when attempting to track down any performance issues that are related to connection pooling.
Whenever your application is connecting to a resource, such as a database, running in another process, you should optimize by focusing on the time spent connecting to the resource, the time spent sending or retrieving data, and the number of round-trips. Optimizing any kind of process hop in your application is the first place to start to achieve better performance.
The application tier contains the logic that connects to your data layer and transforms data into meaningful class instances and business processes. For example, in Community Server, this is where you populate a Forums or Threads collection, and apply business rules such as permissions; most importantly it is where the Caching logic is performed.
Tip 4—ASP.NET Cache API
One of the very first things you should do before writing a line of application code is architect the application tier to maximize and exploit the ASP.NET Cache feature.
If your components are running within an ASP.NET application, you simply need to include a reference to System.Web.dll in your application project. When you need access to the Cache, use the HttpRuntime.Cache property (the same object is also accessible through Page.Cache and HttpContext.Cache).
There are several rules for caching data. First, if data can be used more than once it's a good candidate for caching. Second, if data is general rather than specific to a given request or user, it's a great candidate for the cache. If the data is user- or request-specific, but is long lived, it can still be cached, but may not be used as frequently. Third, an often overlooked rule is that sometimes you can cache too much. Generally on an x86 machine, you want to run a process with no higher than 800MB of private bytes in order to reduce the chance of an out-of-memory error. Therefore, caching should be bounded. In other words, you may be able to reuse a result of a computation, but if that computation takes 10 parameters, you might attempt to cache on 10 permutations, which will likely get you into trouble. One of the most common support calls for ASP.NET is out-of-memory errors caused by overcaching, especially of large datasets.Common Performance Myths
One of the most common myths is that C# code is faster than Visual Basic code. There is a grain of truth in this, as it is possible to take several performance-hindering actions in Visual Basic that are not possible to accomplish in C#, such as not explicitly declaring types. But if good programming practices are followed, there is no reason why Visual Basic and C# code cannot execute with nearly identical performance. To put it more succinctly, similar code produces similar results.
Another myth is that codebehind is faster than inline, which is absolutely false. It doesn't matter where your code for your ASP.NET application lives, whether in a codebehind file or inline with the ASP.NET page. Sometimes I prefer to use inline code as changes don't incur the same update costs as codebehind. For example, with codebehind you have to update the entire codebehind DLL, which can be a scary proposition.
Myth number three is that components are faster than pages. This was true in Classic ASP when compiled COM servers were much faster than VBScript. With ASP.NET, however, both pages and components are classes. Whether your code is inline in a page, within a codebehind, or in a separate component makes little performance difference. Organizationally, it is better to group functionality logically this way, but again it makes no difference with regard to performance.
The final myth I want to dispel is that every functionality that you want to occur between two apps should be implemented as a Web service. Web services should be used to connect disparate systems or to provide remote access to system functionality or behaviors. They should not be used internally to connect two similar systems. While easy to use, there are much better alternatives. The worst thing you can do is use Web services for communicating between ASP and ASP.NET applications running on the same server, which I've witnessed all too frequently.
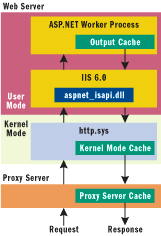
Figure 3** ASP.NET Cache **
There are a several great features of the Cache that you need to know. The first is that the Cache implements a least-recently-used algorithm, allowing ASP.NET to force a Cache purge—automatically removing unused items from the Cache—if memory is running low. Secondly, the Cache supports expiration dependencies that can force invalidation. These include time, key, and file. Time is often used, but with ASP.NET 2.0 a new and more powerful invalidation type is being introduced: database cache invalidation. This refers to the automatic removal of entries in the cache when data in the database changes. For more information on database cache invalidation, see Dino Esposito's Cutting Edge column in the July 2004 issue of MSDN®Magazine. For a look at the architecture of the cache, see Figure 3.
Tip 5—Per-Request Caching
Earlier in the article, I mentioned that small improvements to frequently traversed code paths can lead to big, overall performance gains. One of my absolute favorites of these is something I've termed per-request caching.
Whereas the Cache API is designed to cache data for a long period or until some condition is met, per-request caching simply means caching the data for the duration of the request. A particular code path is accessed frequently on each request but the data only needs to be fetched, applied, modified, or updated once. This sounds fairly theoretical, so let's consider a concrete example.
In the Forums application of Community Server, each server control used on a page requires personalization data to determine which skin to use, the style sheet to use, as well as other personalization data. Some of this data can be cached for a long period of time, but some data, such as the skin to use for the controls, is fetched once on each request and reused multiple times during the execution of the request.
To accomplish per-request caching, use the ASP.NET HttpContext. An instance of HttpContext is created with every request and is accessible anywhere during that request from the HttpContext.Current property. The HttpContext class has a special Items collection property; objects and data added to this Items collection are cached only for the duration of the request. Just as you can use the Cache to store frequently accessed data, you can use HttpContext.Items to store data that you'll use only on a per-request basis. The logic behind this is simple: data is added to the HttpContext.Items collection when it doesn't exist, and on subsequent lookups the data found in HttpContext.Items is simply returned.
Tip 6—Background Processing
The path through your code should be as fast as possible, right? There may be times when you find yourself performing expensive tasks on each request or once every n requests. Sending out e-mails or parsing and validation of incoming data are just a few examples.
When tearing apart ASP.NET Forums 1.0 and rebuilding what became Community Server, we found that the code path for adding a new post was pretty slow. Each time a post was added, the application first needed to ensure that there were no duplicate posts, then it had to parse the post using a "badword" filter, parse the post for emoticons, tokenize and index the post, add the post to the moderation queue when required, validate attachments, and finally, once posted, send e-mail notifications out to any subscribers. Clearly, that's a lot of work.
It turns out that most of the time was spent in the indexing logic and sending e-mails. Indexing a post was a time-consuming operation, and it turned out that the built-in System.Web.Mail functionality would connect to an SMTP server and send the e-mails serially. As the number of subscribers to a particular post or topic area increased, it would take longer and longer to perform the AddPost function.
Indexing e-mail didn't need to happen on each request. Ideally, we wanted to batch this work together and index 25 posts at a time or send all the e-mails every five minutes. We decided to use the same code I had used to prototype database cache invalidation for what eventually got baked into Visual Studio® 2005.
The Timer class, found in the System.Threading namespace, is a wonderfully useful, but less well-known class in the .NET Framework, at least for Web developers. Once created, the Timer will invoke the specified callback on a thread from the ThreadPool at a configurable interval. This means you can set up code to execute without an incoming request to your ASP.NET application, an ideal situation for background processing. You can do work such as indexing or sending e-mail in this background process too.
There are a couple of problems with this technique, though. If your application domain unloads, the timer instance will stop firing its events. In addition, since the CLR has a hard gate on the number of threads per process, you can get into a situation on a heavily loaded server where timers may not have threads to complete on and can be somewhat delayed. ASP.NET tries to minimize the chances of this happening by reserving a certain number of free threads in the process and only using a portion of the total threads for request processing. However, if you have lots of asynchronous work, this can be an issue.
There is not enough room to go into the code here, but you can download a digestible sample at www.rob-howard.net. Just grab the slides and demos from the Blackbelt TechEd 2004 presentation.
Tip 7—Page Output Caching and Proxy Servers
ASP.NET is your presentation layer (or should be); it consists of pages, user controls, server controls (HttpHandlers and HttpModules), and the content that they generate. If you have an ASP.NET page that generates output, whether HTML, XML, images, or any other data, and you run this code on each request and it generates the same output, you have a great candidate for page output caching.
By simply adding this line to the top of your page
<%@ Page OutputCache VaryByParams="none" Duration="60" %>
you can effectively generate the output for this page once and reuse it multiple times for up to 60 seconds, at which point the page will re-execute and the output will once be again added to the ASP.NET Cache. This behavior can also be accomplished using some lower-level programmatic APIs, too. There are several configurable settings for output caching, such as the VaryByParams attribute just described. VaryByParams just happens to be required, but allows you to specify the HTTP GET or HTTP POST parameters to vary the cache entries. For example, default.aspx?Report=1 or default.aspx?Report=2 could be output-cached by simply setting VaryByParam="Report". Additional parameters can be named by specifying a semicolon-separated list.
Many people don't realize that when the Output Cache is used, the ASP.NET page also generates a set of HTTP headers that downstream caching servers, such as those used by the Microsoft Internet Security and Acceleration Server or by Akamai. When HTTP Cache headers are set, the documents can be cached on these network resources, and client requests can be satisfied without having to go back to the origin server.
Using page output caching, then, does not make your application more efficient, but it can potentially reduce the load on your server as downstream caching technology caches documents. Of course, this can only be anonymous content; once it's downstream, you won't see the requests anymore and can't perform authentication to prevent access to it.
Tip 8—Run IIS 6.0 (If Only for Kernel Caching)
If you're not running IIS 6.0 (Windows Server™ 2003), you're missing out on some great performance enhancements in the Microsoft Web server. In Tip 7, I talked about output caching. In IIS 5.0, a request comes through IIS and then to ASP.NET. When caching is involved, an HttpModule in ASP.NET receives the request, and returns the contents from the Cache.
If you're using IIS 6.0, there is a nice little feature called kernel caching that doesn't require any code changes to ASP.NET. When a request is output-cached by ASP.NET, the IIS kernel cache receives a copy of the cached data. When a request comes from the network driver, a kernel-level driver (no context switch to user mode) receives the request, and if cached, flushes the cached data to the response, and completes execution. This means that when you use kernel-mode caching with IIS and ASP.NET output caching, you'll see unbelievable performance results. At one point during the Visual Studio 2005 development of ASP.NET, I was the program manager responsible for ASP.NET performance. The developers did the magic, but I saw all the reports on a daily basis. The kernel mode caching results were always the most interesting. The common characteristic was network saturation by requests/responses and IIS running at about five percent CPU utilization. It was amazing! There are certainly other reasons for using IIS 6.0, but kernel mode caching is an obvious one.
Tip 9—Use Gzip Compression
While not necessarily a server performance tip (since you might see CPU utilization go up), using gzip compression can decrease the number of bytes sent by your server. This gives the perception of faster pages and also cuts down on bandwidth usage. Depending on the data sent, how well it can be compressed, and whether the client browsers support it (IIS will only send gzip compressed content to clients that support gzip compression, such as Internet Explorer 6.0 and Firefox), your server can serve more requests per second. In fact, just about any time you can decrease the amount of data returned, you will increase requests per second.
The good news is that gzip compression is built into IIS 6.0 and is much better than the gzip compression used in IIS 5.0. Unfortunately, when attempting to turn on gzip compression in IIS 6.0, you may not be able to locate the setting on the properties dialog in IIS. The IIS team built awesome gzip capabilities into the server, but neglected to include an administrative UI for enabling it. To enable gzip compression, you have to spelunk into the innards of the XML configuration settings of IIS 6.0 (which isn't for the faint of heart). By the way, the credit goes to Scott Forsyth of OrcsWeb who helped me figure this out for the www.asp.net severs hosted by OrcsWeb.
Rather than include the procedure in this article, just read the article by Brad Wilson at IIS6 Compression. There's also a Knowledge Base article on enabling compression for ASPX, available at Enable ASPX Compression in IIS. It should be noted, however, that dynamic compression and kernel caching are mutually exclusive on IIS 6.0 due to some implementation details.
Tip 10—Server Control View State
View state is a fancy name for ASP.NET storing some state data in a hidden input field inside the generated page. When the page is posted back to the server, the server can parse, validate, and apply this view state data back to the page's tree of controls. View state is a very powerful capability since it allows state to be persisted with the client and it requires no cookies or server memory to save this state. Many ASP.NET server controls use view state to persist settings made during interactions with elements on the page, for example, saving the current page that is being displayed when paging through data.
There are a number of drawbacks to the use of view state, however. First of all, it increases the total payload of the page both when served and when requested. There is also an additional overhead incurred when serializing or deserializing view state data that is posted back to the server. Lastly, view state increases the memory allocations on the server.
Several server controls, the most well known of which is the DataGrid, tend to make excessive use of view state, even in cases where it is not needed. The default behavior of the ViewState property is enabled, but if you don't need it, you can turn it off at the control or page level. Within a control, you simply set the EnableViewState property to false, or you can set it globally within the page using this setting:
<%@ Page EnableViewState="false" %>
If you are not doing postbacks in a page or are always regenerating the controls on a page on each request, you should disable view state at the page level.
Conclusion
I've offered you some tips that I've found useful for writing high-performance ASP.NET applications. As I mentioned at the beginning of this article, this is more a preliminary guide than the last word on ASP.NET performance. (More information on improving the performance of ASP.NET apps can be found at Improving ASP.NET Performance.) Only through your own experience can you find the best way to solve your unique performance problems. However, during your journey, these tips should provide you with good guidance. In software development, there are very few absolutes; every application is unique.
See the sidebar "Common Performance Myths".
Rob Howard is the founder of Telligent Systems, specializing in high-performance Web apps and knowledge management and collaboration systems. Previously, Rob was employed by Microsoft where he helped design the infrastructure features of ASP.NET 1.0, 1.1, and 2.0. You can contact Rob at rhoward@telligentsystems.com.